オンプレミスで要約 Docker コンテナーを使用する
コンテナーを使用すると、独自のインフラストラクチャで要約 API をホストできます。 要約をリモートで呼び出すことでは満たすことができないセキュリティまたはデータ ガバナンスの要件がある場合は、コンテナーが適している可能性があります。
前提条件
- Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
- ホスト コンピューターに Docker がインストールされていること。 コンテナーが Azure に接続して課金データを送信できるように、Docker を構成する必要があります。
- Windows では、Linux コンテナーをサポートするように Docker を構成することも必要です。
- Docker の概念に関する基本的な知識が必要です。
- Free (F0) または Standard (S) 価格レベルの言語リソース。 切断されたコンテナーの場合、DC0 レベルが必要です。
必須パラメーターの収集
すべての Azure AI コンテナーに対して 3 つの主要なパラメーターが必須です。 Microsoft ソフトウェア ライセンス条項について、値 accept が示される必要があります。 エンドポイント URI と API キーも必要です。
エンドポイント URL
{ENDPOINT_URI} の値は、Azure portal の対応する Azure AI サービス リソースの [概要] ページで入手できます。 [概要] ページに移動し、エンドポイントの上にマウスを合わせると、[クリップボードにコピー] アイコンが表示されます。 必要に応じて、エンドポイントをコピーして使用します。
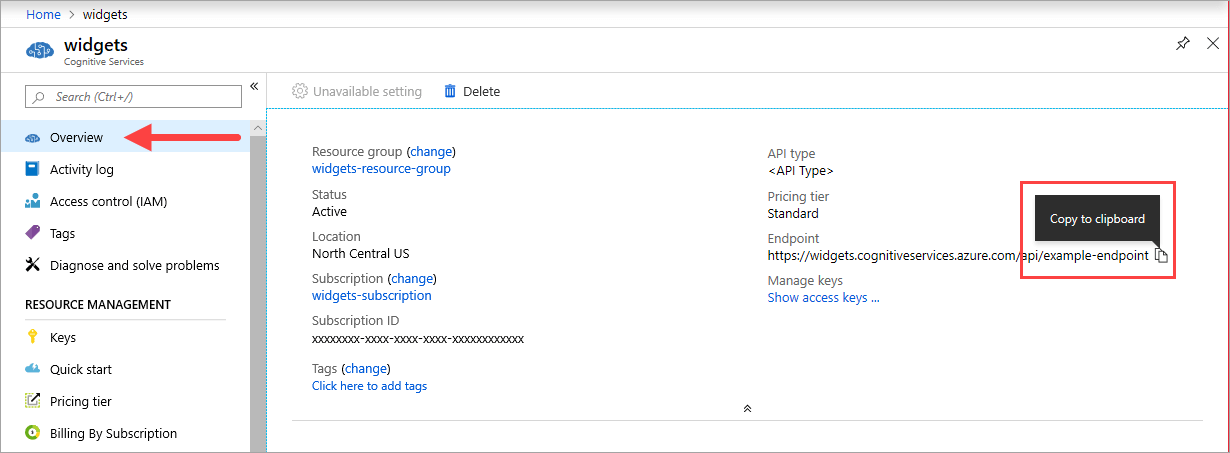
キー
{API_KEY} の値はコンテナーを起動するために使用され、Azure portal で、対応する Azure AI サービス リソースの [キー] ページで入手できます。 [キー] ページに移動し、[クリップボードにコピー] アイコンを選択します。
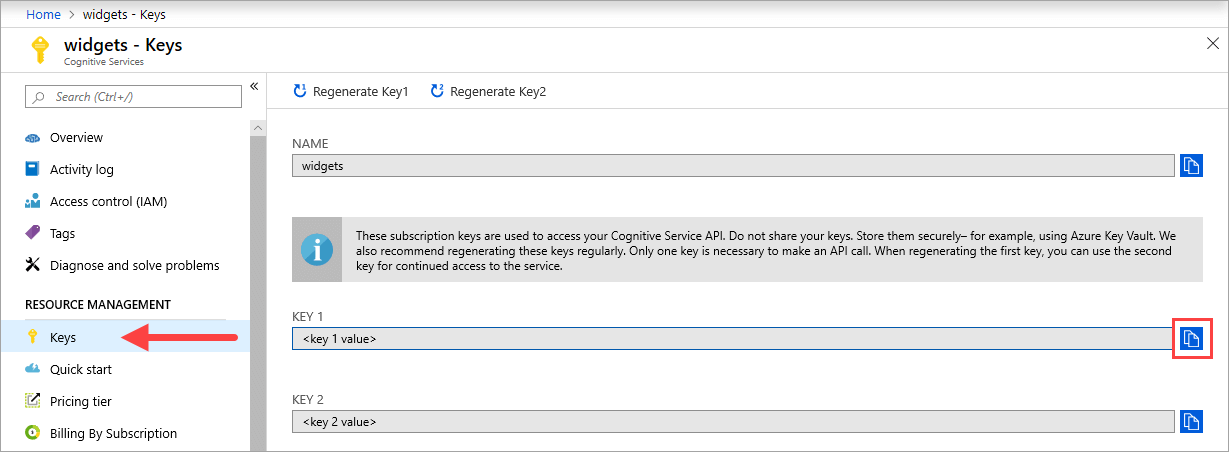
重要
これらのサブスクリプション キーは、Azure AI サービス API にアクセスするために使用されます。 キーを共有しないでください。 安全に保管してください。 たとえば、Azure Key Vault を使用します。 また、これらのキーを定期的に再生成することをお勧めします。 API 呼び出しを行うために必要なキーは 1 つだけです。 最初のキーを再生成するときに、2 番目のキーを使用してサービスに継続的にアクセスすることができます。
ホスト コンピューターの要件と推奨事項
ホストとは、Docker コンテナーを実行する x64 ベースのコンピューターのことです。 お客様のオンプレミス上のコンピューターを使用できるほか、次のような Azure 内の Docker ホスティング サービスを使用することもできます。
- Azure Kubernetes Service。
- Azure Container Instances。
- Azure Stack にデプロイされた Kubernetes クラスター。 詳しくは、「Kubernetes を Azure Stack にデプロイする」をご覧ください。
次の表では、要約コンテナー スキルの最小仕様と推奨仕様を説明します。 一覧にある CPU とメモリの組み合わせは 4000 トークン入力向けです (同じ要求内のすべての側面に会話消費があります)。
| コンテナーの種類 | CPU コアの推奨数 | 推奨されるメモリ | メモ |
|---|---|---|---|
| 要約 CPU コンテナー | 16 | 48 GB | |
| 要約 GPU コンテナー | 2 | 24 GB | Cuda 11.8 と 16 GB VRAM をサポートする Nvidia GPU が必要です。 |
CPU コアとメモリは、docker run コマンドの一部として使用される --cpus と --memory の設定に対応します。
docker pull によるコンテナー イメージの取得
要約コンテナー イメージは mcr.microsoft.com コンテナー レジストリ シンジケートにあります。 azure-cognitive-services/textanalytics/ リポジトリ内にあり、summarization という名前が付いています。 完全修飾コンテナー イメージ名は mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization です
最新バージョンのコンテナーを使用するには、latest タグを使用できます。 また、MCR でタグの完全な一覧を確認することもできます。
Microsoft Container Registry からコンテナー イメージをダウンロードするには、docker pull コマンドを使います。
docker pull mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu
CPU コンテナーの場合、
docker pull mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:gpu
GPU コンテナーの場合。
ヒント
docker images コマンドを使用して、ダウンロードしたコンテナー イメージを一覧表示できます。 たとえば、次のコマンドは、ダウンロードした各コンテナー イメージの ID、リポジトリ、およびタグが表として書式設定されて表示されます。
docker images --format "table {{.ID}}\t{{.Repository}}\t{{.Tag}}"
IMAGE ID REPOSITORY TAG
<image-id> <repository-path/name> <tag-name>
要約コンテナー モデルをダウンロードする
要約コンテナーを実行するための前提条件は、まずモデルをダウンロードすることです。 これを行うには、次のいずれかのコマンドを実行します。ここでは、例として CPU コンテナー イメージを使用しています。
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ExtractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=AbstractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ConversationSummarization billing={ENDPOINT_URI} apikey={API_KEY}
コンテナーは HOST_MODELS_PATH 内のすべてのモデルを読み込むため、同じ HOST_MODELS_PATH 内のすべてのスキルを対象にモデルをダウンロードすることは推奨されません。 それを行うと大量のメモリが使用されることがあります。 特定の HOST_MODELS_PATH に必要なスキルのみを対象にモデルをダウンロードすることが推奨されます。
モデルとコンテナーの間の互換性を確保するには、新しいイメージ バージョンを利用してコンテナーを作成するときは必ず、使用されているモデルを再ダウンロードします。 切断されたコンテナーを使用するとき、モデルをダウンロードした後、ライセンスをもう一度ダウンロードしてください。
docker run によるコンテナーの実行
"要約" コンテナーをホスト コンピューター上に準備できたら、次の docker run コマンドを使用してコンテナーを実行します。 コンテナーは一度実行すると、お客様が停止するまで動作し続けます。 次のプレースホルダーを実際の値に置き換えてください。
| プレースホルダー | 値 | 形式または例 |
|---|---|---|
| {HOST_MODELS_PATH} | ホスト コンピューターのボリューム マウント。Docker では、これを使用してモデルを保持します。 | たとえば、c:\SummarizationModel です。c:\ ドライブはホスト マシン上にあります。 |
| {ENDPOINT_URI} | 要約 API にアクセスするためのエンドポイント。 それは、Azure portal で、お使いのリソースの [キーとエンドポイント] ページで見つけることができます。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
| {API_KEY} | 言語リソースのキー。 それは、Azure portal で、お使いのリソースの [キーとエンドポイント] ページで見つけることができます。 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
docker run -p 5000:5000 -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu eula=accept rai_terms=accept billing={ENDPOINT_URI} apikey={API_KEY}
あるいは、GPU コンテナーを実行している場合、代わりにこのコマンドを使用します。
docker run -p 5000:5000 --gpus all -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:gpu eula=accept rai_terms=accept billing={ENDPOINT_URI} apikey={API_KEY}
マシン上に複数の GPU がある場合、--gpus all を --gpus device={DEVICE_ID} に置換します。
重要
- 以降のセクションの Docker コマンドには、行連結文字としてバック スラッシュ (
\) が使用されています。 お客様のホスト オペレーティング システムの要件に応じて、置換または削除してください。 - コンテナーを実行するには、
Eula、Billing、rai_terms、ApiKeyの各オプションを指定する必要があります。そうしないと、コンテナーが起動しません。 詳細については、「課金」を参照してください。
このコマンドは、次の操作を行います。
- コンテナー イメージから "要約" コンテナーを実行します
- 1 つの CPU コアと 4 ギガバイト (GB) のメモリを割り当てます
- TCP ポート 5000 を公開し、コンテナーに pseudo-TTY を割り当てます
- コンテナーの終了後にそれを自動的に削除します。 ホスト コンピューター上のコンテナー イメージは引き続き利用できます。
同じホスト上で複数のコンテナーを実行する
公開されているポートを使って複数のコンテナーを実行する予定の場合、必ず各コンテナーを別の公開されているポートで実行してください。 たとえば、最初のコンテナーをポート 5000 上で、2 番目のコンテナーを 5001 上で実行します。
このコンテナーと、別の Azure AI サービス コンテナーを HOST 上で同時に実行することができます。 同じ Azure AI サービス コンテナーの複数のコンテナーを実行することもできます。
コンテナーの予測エンドポイントに対するクエリの実行
コンテナーには、REST ベースのクエリ予測エンドポイント API が用意されています。
コンテナー API には、ホストの http://localhost:5000 を使用します。
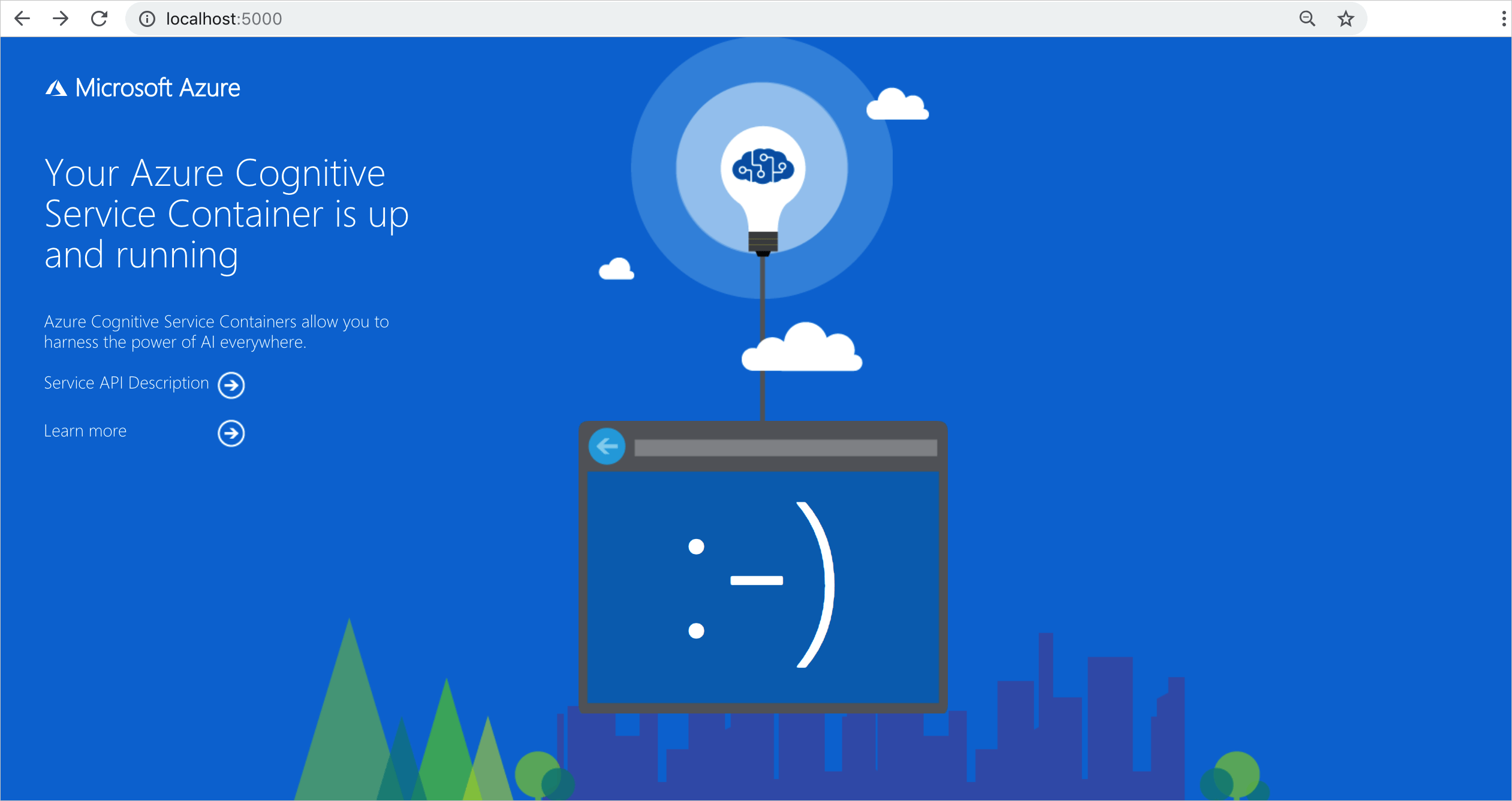
コンテナーが実行されていることを検証する
コンテナーが実行されていることを検証する方法は複数あります。 問題になっているコンテナーの "外部 IP" アドレスと公開ポートを特定し、任意の Web ブラウザーを開きます。 次の各種の要求 URL を使用して、コンテナーが実行中であることを確認します。 ここに示す要求例の URL は http://localhost:5000 ですが、実際のコンテナーは異なる可能性があります。 使用するコンテナーの外部 IP アドレスと公開ポートを基にしてください。
| 要求 URL | 目的 |
|---|---|
http://localhost:5000/ |
コンテナーには、ホーム ページが用意されています。 |
http://localhost:5000/ready |
GET で要求することで、この URL により、コンテナーがモデルに対するクエリを受け取る準備ができていることを確認できます。 この要求は Kubernetes の liveness probe と readiness probe に対して使用できます。 |
http://localhost:5000/status |
これも GET で要求することで、この URL により、コンテナーを起動するために使用された API キーが有効であるかどうかを、エンドポイント クエリを発生させずに確認できます。 この要求は Kubernetes の liveness probe と readiness probe に対して使用できます。 |
http://localhost:5000/swagger |
コンテナーには、エンドポイントの完全なドキュメント一式と、 [Try it out](試してみる) の機能が用意されています。 この機能を使用すると、コードを一切記述することなく、お客様の設定を Web ベースの HTML フォームに入力したりクエリを実行したりできます。 クエリから戻った後、HTTP ヘッダーと HTTP 本文の必要な形式を示すサンプル CURL コマンドが得られます。 |
インターネットから切断されたコンテナーを実行する
インターネットから切断されたこのコンテナーを使用するには、まずアプリケーションに入力し、コミットメント プランを購入してアクセスを要求する必要があります。 詳細については、「切断された環境での Docker コンテナーの使用」を参照してください。
インターネットから切断されたコンテナーの実行が承認されている場合は、次の例に使用する docker run コマンドの形式と、プレースホルダーの値を示しています。 これらのプレースホルダーの値は、実際の値に置き換えます。
docker run コマンドで DownloadLicense=True パラメーターを使用して、インターネットに接続されていないときに Docker コンテナーを実行できるようにするライセンス ファイルをダウンロードします。 有効期限も含まれており、それを過ぎると、そのライセンス ファイルを使用してコンテナーを実行できなくなります。 ライセンス ファイルは、お客様が承認されている対象の適切なコンテナーでのみ使用できます。 たとえば、音声テキスト変換コンテナーのライセンス ファイルを言語サービス コンテナーで使用することはできません。
要約切断コンテナー モデルをダウンロードする
要約コンテナーを実行するための前提条件は、まずモデルをダウンロードすることです。 これを行うには、次のいずれかのコマンドを実行します。ここでは、例として CPU コンテナー イメージを使用しています。
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ExtractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=AbstractiveSummarization billing={ENDPOINT_URI} apikey={API_KEY}
docker run -v {HOST_MODELS_PATH}:/models mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu downloadModels=ConversationSummarization billing={ENDPOINT_URI} apikey={API_KEY}
コンテナーは HOST_MODELS_PATH 内のすべてのモデルを読み込むため、同じ HOST_MODELS_PATH 内のすべてのスキルを対象にモデルをダウンロードすることは推奨されません。 それを行うと大量のメモリが使用されることがあります。 特定の HOST_MODELS_PATH に必要なスキルのみを対象にモデルをダウンロードすることが推奨されます。
モデルとコンテナーの間の互換性を確保するには、新しいイメージ バージョンを利用してコンテナーを作成するときは必ず、使用されているモデルを再ダウンロードします。 切断されたコンテナーを使用するとき、モデルをダウンロードした後、ライセンスをもう一度ダウンロードしてください。
docker run を使用して切断されたコンテナーを実行する
| プレースホルダー | 値 | 形式または例 |
|---|---|---|
{IMAGE} |
使用するコンテナー イメージ。 | mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu |
{LICENSE_MOUNT} |
ライセンスがダウンロードされ、マウントされるパス。 | /host/license:/path/to/license/directory |
{HOST_MODELS_PATH} |
モデルがダウンロードされ、マウントされたパス。 | /host/models:/models |
{ENDPOINT_URI} |
サービス要求を認証するためのエンドポイント。 それは、Azure portal で、お使いのリソースの [キーとエンドポイント] ページで見つけることができます。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API_KEY} |
自分の Text Analytics リソースのキー。 それは、Azure portal で、お使いのリソースの [キーとエンドポイント] ページで見つけることができます。 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
{CONTAINER_LICENSE_DIRECTORY} |
コンテナーのローカル ファイル システム上のライセンス フォルダーの場所。 | /path/to/license/directory |
docker run --rm -it -p 5000:5000 \
-v {LICENSE_MOUNT} \
-v {HOST_MODELS_PATH} \
{IMAGE} \
eula=accept \
rai_terms=accept \
billing={ENDPOINT_URI} \
apikey={API_KEY} \
DownloadLicense=True \
Mounts:License={CONTAINER_LICENSE_DIRECTORY}
ライセンス ファイルがダウンロードされたら、切断された環境でコンテナーを実行できます。 次の例では、使用する docker run コマンドの形式と、プレースホルダーの値を示します。 これらのプレースホルダーの値は、実際の値に置き換えます。
コンテナーを実行する場所では必ず、ライセンス ファイルをコンテナーにマウントする必要があり、コンテナーのローカル ファイルシステム上のライセンス フォルダーの場所を Mounts:License= で指定する必要があります。 課金用の使用状況レコードを書き込むことができるように、出力マウントも指定する必要があります。
| プレースホルダー | 値 | 形式または例 |
|---|---|---|
{IMAGE} |
使用するコンテナー イメージ。 | mcr.microsoft.com/azure-cognitive-services/textanalytics/summarization:cpu |
{MEMORY_SIZE} |
コンテナーに割り当てるメモリの適切なサイズ。 | 4g |
{NUMBER_CPUS} |
コンテナーに割り当てる CPU の適切な数。 | 4 |
{LICENSE_MOUNT} |
ライセンスが配置され、マウントされるパス。 | /host/license:/path/to/license/directory |
{HOST_MODELS_PATH} |
モデルがダウンロードされ、マウントされたパス。 | /host/models:/models |
{OUTPUT_PATH} |
使用状況レコードを記録するための出力パス。 | /host/output:/path/to/output/directory |
{CONTAINER_LICENSE_DIRECTORY} |
コンテナーのローカル ファイル システム上のライセンス フォルダーの場所。 | /path/to/license/directory |
{CONTAINER_OUTPUT_DIRECTORY} |
コンテナーのローカル ファイル システム上の出力フォルダーの場所。 | /path/to/output/directory |
docker run --rm -it -p 5000:5000 --memory {MEMORY_SIZE} --cpus {NUMBER_CPUS} \
-v {LICENSE_MOUNT} \
-v {HOST_MODELS_PATH} \
-v {OUTPUT_PATH} \
{IMAGE} \
eula=accept \
rai_terms=accept \
Mounts:License={CONTAINER_LICENSE_DIRECTORY}
Mounts:Output={CONTAINER_OUTPUT_DIRECTORY}
コンテナーの停止
コンテナーをシャットダウンするには、コンテナーが実行されているコマンドライン環境で、Ctrl + C キーを押します。
トラブルシューティング
出力マウントとログを有効にした状態でコンテナーを実行すると、コンテナーによってログ ファイルが生成されます。これらはコンテナーの起動時または実行時に発生した問題のトラブルシューティングに役立ちます。
ヒント
トラブルシューティング情報とガイダンスの詳細については、Azure AI コンテナーについてよくあるご質問 (FAQ) に関するページを参照してください。
請求
要約コンテナーにより、Azure アカウントの "言語" リソースを使用して Azure に課金情報が送信されます。
コンテナーへのクエリは、 ApiKeyパラメーターに使用される Azure リソースの価格レベルで課金 されます。
Azure AI サービス コンテナーは、計測または課金エンドポイントに接続していないと、実行のライセンスが許可されません。 お客様は、コンテナーが常に課金エンドポイントに課金情報を伝えられるようにする必要があります。 Azure AI サービス コンテナーによって、お客様のデータ (解析対象の画像やテキストなど) が Microsoft に送信されることはありません。
Azure に接続する
コンテナーには、実行する課金引数の値が必要です。 これらの値により、コンテナーは課金エンドポイントに接続することができます。 コンテナーから、約 10 ~ 15 分ごとに使用状況が報告されます。 許可された時間枠内でコンテナーが Azure に接続しなかった場合、コンテナーは引き続き実行されますが、課金エンドポイントが復元されるまでクエリには対応しません。 接続は、10 ~15 分の同じ時間間隔で、10 回試行されます。 10 回以内に課金エンドポイントに接続できなかった場合、コンテナーによる要求の処理は停止されます。 課金のために Microsoft に送信される情報の例については、Azure AI サービス コンテナーについてよく寄せられる質問を参照してください。
課金引数
docker run コマンドは、次の 3 つのオプションのすべてに有効な値が指定された場合にコンテナーを起動します。
| オプション | 説明 |
|---|---|
ApiKey |
課金情報を追跡するために使用される Azure AI サービス リソースの API キー。 このオプションの値には、 Billing に指定されたプロビジョニング済みのリソースの API キーが設定されている必要があります。 |
Billing |
課金情報を追跡するために使用される Azure AI サービス リソースのエンドポイント。 このオプションの値には、プロビジョニング済みの Azure リソースのエンドポイント URI が設定されている必要があります。 |
Eula |
お客様がコンテナーのライセンスに同意したことを示します。 このオプションの値は accept に設定する必要があります。 |
これらのオプションの詳細については、「コンテナーの構成」を参照してください。
まとめ
この記事では、要約コンテナーの概念とそのダウンロード、インストール、実行のワークフローについて説明しました。 要約すると:
- 要約では、Docker 用の Linux コンテナーを提供します。
- コンテナー イメージは Microsoft Container Registry (MCR) からダウンロードされます。
- コンテナー イメージを Docker で実行します。
- コンテナーをインスタンス化するときは、課金情報を指定する必要があります。
重要
このコンテナーは、計測のために Azure に接続していないと、実行のライセンスが許可されません。 お客様は、コンテナーが常に計測サービスに課金情報を伝えられるようにする必要があります。 お客様のデータ (解析対象のテキストなど) が Azure AI コンテナーによって Microsoft に送信されることはありません。
次のステップ
- 構成設定については、コンテナーの構成に関するページを参照してください。