Custom Speech モデルの認識品質をテストする
Custom Speech モデルの認識品質は、Speech Studio で調べることができます。 アップロードされたオーディオを再生し、提供された認識結果が正しいかどうかを判断できます。 テストが正常に作成されたら、モデルによって、オーディオ データセットがどのように書き起こされたかを確認したり、2 つのモデルの結果を並べて比較したりできます。
モデルを並べたテストは、アプリケーションに最適な音声認識モデルを検証するのに役立ちます。 文字起こしデータセットの入力が必要な正確性の客観的なメジャーついては、「モデルを定量的にテストする」を参照してください。
重要
テスト時には、システムによって文字起こしが行われます。 価格はサービス オファリングやサブスクリプション レベルによって異なるため、この点に留意することが重要です。 最新の詳細情報については、Azure AI サービスの価格に関する公式ページを常に参照してください。
テストを作成する
テストを作成するには、以下の手順を実行します。
Speech Studio にサインインします。
Speech Studio>Custom Speech の順に移動し、リストから使用するプロジェクト名を選択します。
[Test models](テスト用モデル)>[Create new test](新しいテストの作成) の順に選択します。
[Inspect quality (Audio-only data)](品質の検査 (オーディオのみのデータ))>[次へ] の順に選択します。
テストに使用するオーディオ データセットを選択し、[次へ] を選択します。 使用可能なデータセットがない場合は、セットアップをキャンセルし、[Speech datasets] (音声データセット) メニューに移動して、データセットをアップロードします。
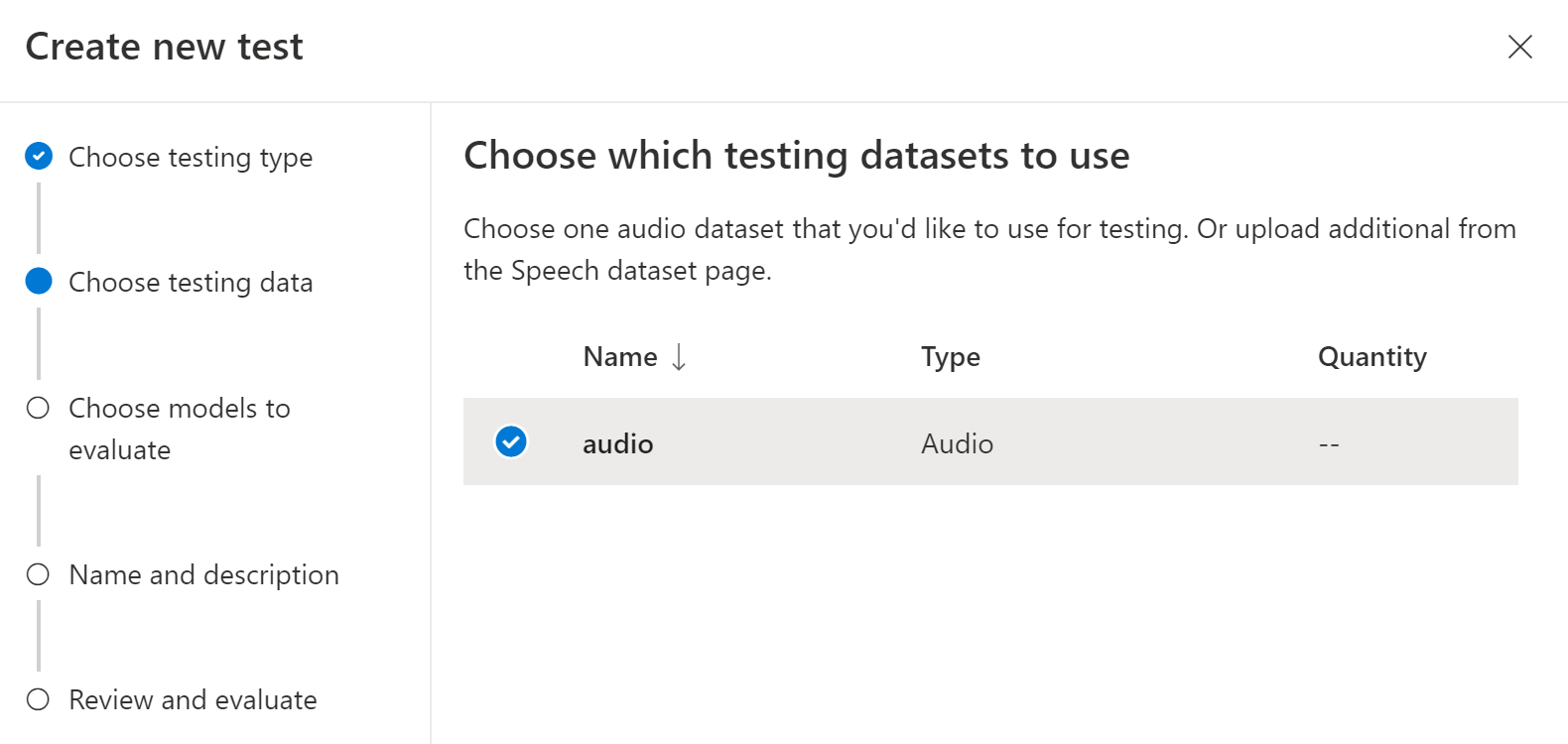
精度を評価し、比較するために 1 つまたは 2 つのモデルを選択します。
テストの名前と説明を入力し、[次へ] を選択します。
設定を確認し、[保存して閉じる] を選択します。
テストを作成するには、spx csr evaluation create コマンドを使用します。 次の手順に従って要求パラメーターを作成します。
projectパラメーターを既存のプロジェクトの ID に設定します。 このパラメーターは、Speech Studio でテストを表示できるようにするためにも推奨されます。spx csr project listコマンドを実行すると、使用できるプロジェクトを取得できます。- 必須の
model1パラメーターを、テストするモデルの ID に設定します。 - 必須の
model2パラメーターを、テストする別のモデルの ID に設定します。 2 つのモデルを比較しない場合は、model1とmodel2の両方に同じモデルを使用します。 - 必須の
datasetパラメーターを、テストに使用するデータセットの ID に設定します。 languageパラメーターを設定しない場合、Speech CLI では既定で "en-US" が設定されます。 このパラメーターは、データセットのコンテンツのロケールである必要があります。 ロケールを後から変更することはできません。 Speech CLIlanguageパラメーターは、JSON 要求と応答のlocaleプロパティに対応します。- 必須の
nameパラメーターを設定します。 このパラメーターは、Speech Studio に表示される名前です。 Speech CLInameパラメーターは、JSON 要求と応答のdisplayNameプロパティに対応します。
テストを作成する 音声 CLI コマンドの例を次に示します:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
次の形式で応答本文を受け取る必要があります。
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
応答本文の最上位の self プロパティは評価の URI です。 この URI を使用して、プロジェクトとテスト結果の詳細を取得します。 また、評価の更新と削除にもこの URI を使用します。
評価に関する 音声 CLI ヘルプを表示するには、次のコマンドを実行します:
spx help csr evaluation
テストを作成するには、Speech to text REST API の Evaluations_Create 操作を使用します。 次の手順に従って要求本文を作成します。
projectプロパティを既存のプロジェクトの URI に設定します。 このプロパティは、Speech Studio でテストを表示できるようにするためにも推奨されます。 Projects_List 要求を行うと、使用できるプロジェクトを取得できます。- 必須の
model1プロパティを、テストするモデルの URI にセットします。 - 必須の
model2プロパティを、テストする別のモデルの URI にセットします。 2 つのモデルを比較しない場合は、model1とmodel2の両方に同じモデルを使用します。 - 必須の
datasetプロパティを、テストに使用するデータセットの URI にセットします。 - 必須の
localeプロパティを設定します。 このプロパティは、データセットのコンテンツのロケールである必要があります。 ロケールを後から変更することはできません。 - 必須の
displayNameプロパティを設定します。 このプロパティは、Speech Studio に表示される名前です。
HTTP POST 要求は、次の例に示すように URI を使用して行います。 YourSubscriptionKey は実際の Speech リソース キーに、YourServiceRegion は実際の Speech リソース リージョンに置き換えたうえで、前述のように要求本文のプロパティを設定してください。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
次の形式で応答本文を受け取る必要があります。
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
応答本文の最上位の self プロパティは評価の URI です。 この URI を使用して、評価のプロジェクトとテスト結果の詳細を取得します。 また、評価の更新か削除にもこの URI を使用します。
テスト結果の取得
各モデルの文字起こし結果と比較して、テスト結果を取得し、オーディオ データセットを 検査 する必要があります。
テスト結果を取得するには、次の手順に従います:
- Speech Studio にサインインします。
- [Custom Speech]> プロジェクト名 >[モデルをテストする] を選択します。
- テスト名でリンクを選択します。
- テストが完了したら、状態が [成功] にセットされていれば、テスト対象の各モデルの WER の数値を含む結果が表示されます。
このページには、データセット内のすべての発話と、送信されたデータセットからの文字起こしと共に、認識結果が一覧表示されます。 挿入、削除、置換を含むさまざまなエラーの種類を切り替えることができます。 音声を聞きながら各列の認識結果を比較すると、どちらのモデルがニーズに合うか決定し、どのような追加のトレーニングと改善が必要かを判断できます。
テスト結果を取得するには、spx csr evaluation status コマンドを使用します。 次の手順に従って要求パラメーターを作成します。
- 必須の
evaluationパラメーターを、テスト結果を取得する評価の ID にセットします。
テスト結果を取得する 音声 CLI コマンドの例を次に示します:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
モデル、オーディオ データセット、文字起こし、その他の詳細は、応答本文で返されます。
次の形式で応答本文を受け取る必要があります:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
評価に関する 音声 CLI ヘルプを表示するには、次のコマンドを実行します:
spx help csr evaluation
テスト結果を取得するには、まず Speech to text REST API の Evaluations_Get 操作を使用します。
HTTP GET 要求は、次の例に示すように URI を使用して行います。 YourEvaluationId を評価 ID に置き換え、YourSubscriptionKey を 音声 リソース キーに置き換えて、YourServiceRegion を 音声 リソース リージョンに置き換えます。
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
モデル、オーディオ データセット、文字起こし、その他の詳細は、応答本文で返されます。
次の形式で応答本文を受け取る必要があります:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
文字起こしとオーディオを比較する
テストされた各モデルによって、オーディオ入力データセットに対して文字起こし出力を検査できます。 テストに 2 つのモデルを含める場合は、文字起こしの品質を並べて比較できます。
文字起こしの品質を確認するには:
- Speech Studio にサインインします。
- [Custom Speech]> プロジェクト名 >[モデルをテストする] を選択します。
- テスト名でリンクを選択します。
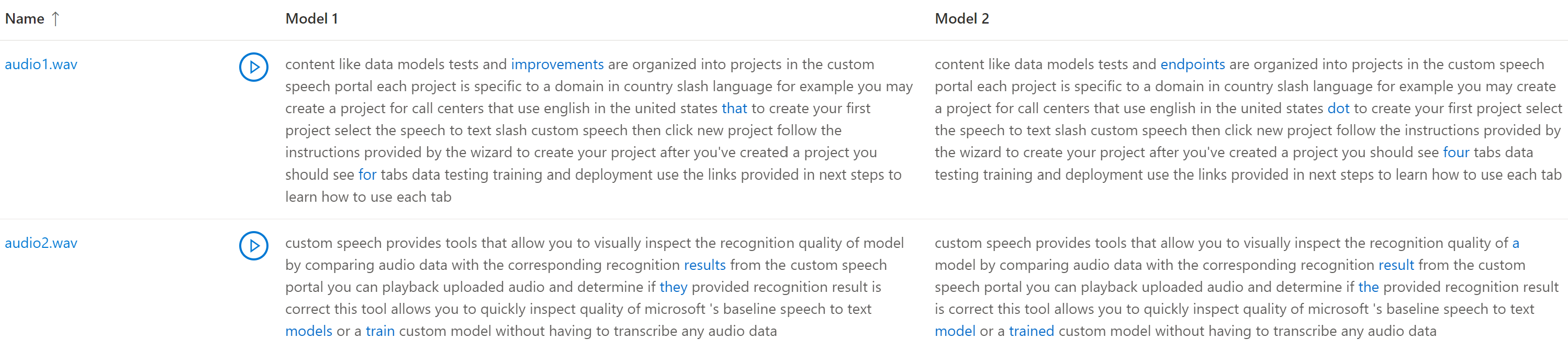
- モデルによる対応する文字起こしの読み取り中に、オーディオ ファイルを再生します。
テスト データセットに複数のオーディオ ファイルが含まれている場合は、表に複数の行が表示されます。 テストに 2 つのモデルを含める場合は、文字起こしが横並びの列に表示されます。 モデル間の文字起こしの違いは、青色のテキスト フォントで表示されます。
テスト結果には、テストされたオーディオ テスト データセット、文字起こし、およびモデルが返されます。 テストされたモデルが 1 つだけの場合、model1 値は model2 に 一致 し、transcription1 値は transcription2 に一致します。
文字起こしの品質を確認するには:
- 既にコピーがない限り、オーディオ テスト データセットをダウンロードします。
- 出力文字起こしをダウンロードします。
- モデルによる対応する文字起こしの読み取り中に、オーディオ ファイルを再生します。
2 つのモデル間で品質を比較する場合は、各モデルの文字起こしの違いに特に注意してください。
テスト結果には、テストされたオーディオ テスト データセット、文字起こし、およびモデルが返されます。 テストされたモデルが 1 つだけの場合、model1 値は model2 に 一致 し、transcription1 値は transcription2 に一致します。
文字起こしの品質を確認するには:
- 既にコピーがない限り、オーディオ テスト データセットをダウンロードします。
- 出力文字起こしをダウンロードします。
- モデルによる対応する文字起こしの読み取り中に、オーディオ ファイルを再生します。
2 つのモデル間で品質を比較する場合は、各モデルの文字起こしの違いに特に注意してください。