音声認識の正確性をテストする場合、またはカスタム モデルをトレーニングする場合は、オーディオまたはテキストのデータが必要です。 モデルのテストまたはトレーニングでサポートされるデータ型の詳細については、「データセットのトレーニングとテスト」を参照してください。
ヒント
オンライン文字起こしエディターを使用して、ラベル付けされたオーディオ データセットを作成および調整することもできます。
データセットをアップロードする
カスタム音声モデルをトレーニング (微調整) するためのデータセットをアップロードするには、次の手順に従います。
重要
後でテストを作成するときに必要なテスト データセット (オーディオのみなど) をアップロードする手順を繰り返します。 トレーニングとテストのために複数のデータセットをアップロードできます。
Microsoft Foundry ポータルにサインインします。
左側のウィンドウから [微調整 ] を選択し、[ AI サービスの微調整] を選択します。
カスタム音声の微調整 の開始方法に関する記事の説明に従って、開始したカスタム音声微調整タスク (モデル名別) を選択します。
[ データの管理>データセットの追加] を選択します。
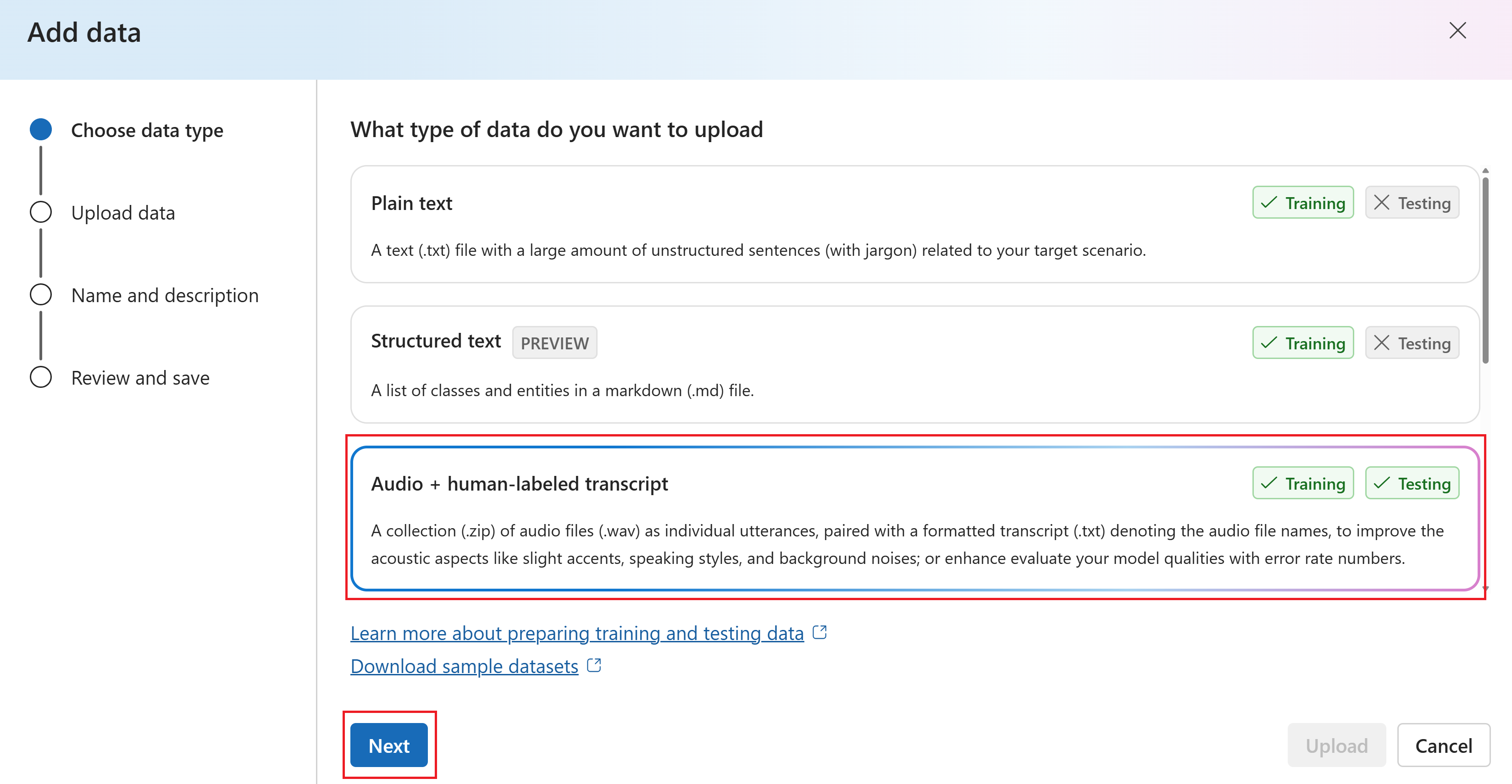
データの追加ウィザードで、追加するトレーニング データの種類を選択します。 この例では、[音声と人間がラベル付けしたトランスクリプト] を選択します。 次に、[次へ] を選択します。
[データのアップロード] ページで、ローカル ファイル、Azure Blob Storage、またはその他の共有 Web の場所を選択します。 次に、[次へ] を選択します。
リモートの場所を選択し、信頼できる Azure サービスのセキュリティ メカニズムを使用しない場合、リモートの場所は、単純な匿名 GET 要求で取得できる URL である必要があります。 たとえば、SAS URL やパブリックにアクセス可能な URL などです。 追加の承認が必要な URL、またはユーザーの操作が必要な URL はサポートされていません。
注
Azure BLOB URL を使用する場合は、信頼された Azure サービスのセキュリティ メカニズムを使用することで、データセット ファイルの最高のセキュリティを確保できます。 データセット ファイルのバッチ文字起こしとプレーンストレージ アカウント URL と同じ手法を使用します。 詳細については、こちらを参照してください。
データの名前と説明を入力します。 次に、[次へ] を選択します。
データを確認し、[アップロード] を選択します。 [データの管理] ページに戻ります。 データの状態は、[処理中] です。
後でテストを作成するときに必要なテスト データセット (オーディオのみなど) をアップロードする手順を繰り返します。 トレーニングとテストのために複数のデータセットをアップロードできます。
前の手順を繰り返して、 後でテストに使用するオーディオ データをアップロードします。 データの 追加 ウィザードで、追加するデータの種類として [オーディオ ] を選択します。



Speech Studio で独自のデータセットをアップロードするには、次の手順を実行します。
Speech Studio にサインインします。
[Custom Speech]> [プロジェクト名] >[音声データセット]>[データのアップロード] を選択します。
[トレーニング データ]または [テスト データ] タブを選択します。
データセットの種類を選択し、[次へ] を選択します。
データセットの場所を指定し、[次へ] を選択します。 ローカル ファイルを選択するか、Azure BLOB URL などのリモートの場所を入力できます。 リモートの場所を選択し、信頼できる Azure サービスのセキュリティ メカニズムを使用しない場合、リモートの場所は、単純な匿名 GET 要求で取得できる URL である必要があります。 たとえば、SAS URL やパブリックにアクセス可能な URL などです。 追加の承認が必要な URL、またはユーザーの操作が必要な URL はサポートされていません。
注
Azure BLOB URL を使用する場合は、信頼された Azure サービスのセキュリティ メカニズムを使用することで、データセット ファイルの最高のセキュリティを確保できます。 データセット ファイルの Batch 文字起こしとプレーンストレージ アカウント URL と同じ手法を使用します。 詳細については、こちらを参照してください。
データセットの名前と説明を入力し、[次へ] を選択します。
設定を確認し、[保存して閉じる] を選択します。
データセットがアップロードされたら、[カスタム モデルのトレーニング] ページに移動して、カスタム モデルをトレーニングします
続行する前に、 Speech CLI がインストールされ、構成されていることを確認します。
Speech CLI と Speech to Text REST API では、Microsoft Foundry ポータルや Speech Studio とは異なり、アップロード時にデータセットがテスト用かトレーニング用かを選択しません。 モデルのトレーニング、テストの実行のときにデータセットをどのように使うかを指定します。
テスト用かトレーニング用かを示す必要はありませんが、データセットの種類を指定する必要があります。 データセットの種類は、作成するデータセットの種類を決定するために使われます。 場合によっては、データセットの種類はテスト用またはトレーニング用にのみ使われることもありますが、それに依存しないようにしてください。 Speech CLI と REST API の kind 値は、次の表に示すように 、Microsoft Foundry ポータル と Speech Studio のオプションに対応します。
| CLI と API の種類 | ポータル のオプション |
|---|---|
| 音響 | トレーニング データ: 音声 + 人間がラベル付けしたトランスクリプト テスト データ: トランスクリプト (自動音声合成) テスト データ: 音声 + 人間がラベル付けしたトランスクリプト |
| AudioFiles | テスト データ: 音声 |
| Language | トレーニング データ: プレーン テキスト |
| LanguageMarkdown | トレーニング データ: マークダウン形式の構造化テキスト |
| 発音 | トレーニング データ: 発音 |
| 出力フォーマット | トレーニング データ: 出力形式 |
重要
Speech CLI または REST API を使用してデータ ファイルを直接アップロードすることはありません。 まず、Speech CLI または REST API がアクセスできる URL にトレーニングまたはテスト データセット ファイルを保存します。 データ ファイルをアップロードしたら、Speech CLI または REST API を使用して、カスタム音声テストまたはトレーニング用のデータセットを作成できます。
データセットを作成し、既存のプロジェクトに接続するには、spx csr dataset create コマンドを使います。 次の手順に従って要求パラメーターを作成します。
projectプロパティを既存のプロジェクトの ID に設定します。projectでカスタム音声の微調整を管理できるように、 プロパティをお勧めします。 プロジェクト ID を取得するには、 REST API ドキュメントのプロジェクト ID を取得するを 参照してください。必須の
kindプロパティを設定します。 トレーニング データセットの種類に使用できる値のセットは、Acoustic、AudioFiles、Language、LanguageMarkdown、Pronunciation です。必須の
contentUrlプロパティを設定します。 このパラメーターは、データセットの場所です。 信頼された Azure サービスのセキュリティ メカニズム (次の注を参照) を使用しない場合、contentUrlプロパティは、単純な匿名 GET 要求で取得できる URL である必要があります。 たとえば、SAS URL やパブリックにアクセス可能な URL などです。 追加の承認が必要な URL、またはユーザー操作が必要な URL はサポートされていません。注
Azure BLOB URL を使用する場合は、信頼された Azure サービスのセキュリティ メカニズムを使用することで、データセット ファイルの最高のセキュリティを確保できます。 データセット ファイルの Batch 文字起こしとプレーンストレージ アカウント URL と同じ手法を使用します。 詳細については、こちらを参照してください。
必須の
languageプロパティを設定します。 データセットのロケールは、プロジェクトのロケールと一致する必要があります。 ロケールを後から変更することはできません。 Speech CLIlanguageプロパティは、JSON 要求と応答のlocaleプロパティに対応します。必須の
nameプロパティを設定します。 このパラメーターは、 Microsoft Foundry ポータルに表示される名前です。 Speech CLInameプロパティは、JSON 要求と応答のdisplayNameプロパティに対応します。
データセットを作成し、既存のプロジェクトに接続する Speech CLI コマンドの例を次に示します。
spx csr dataset create --api-version v3.2 --kind "Acoustic" --name "My Acoustic Dataset" --description "My Acoustic Dataset Description" --project YourProjectId --content YourContentUrl --language "en-US"
重要
--api-version v3.2を設定する必要があります。 Speech CLI では REST API が使用されますが、 v3.2以降のバージョンはまだサポートされていません。
次の形式で応答本文を受け取る必要があります。
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/aaaabbbb-0000-cccc-1111-dddd2222eeee",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
応答本文の最上位の self プロパティはデータセットの URI です。 この URI を使って、データセットのプロジェクトとファイルに関する詳細を取得します。 また、この URI は、データセットの更新または削除にも使います。
データセットに関する Speech CLI ヘルプを表示するには、次のコマンドを実行します。
spx help csr dataset
Speech CLI と Speech to Text REST API では、Microsoft Foundry ポータルや Speech Studio とは異なり、アップロード時にデータセットがテスト用かトレーニング用かを選択しません。 モデルのトレーニング、テストの実行のときにデータセットをどのように使うかを指定します。
テスト用かトレーニング用かを示す必要はありませんが、データセットの種類を指定する必要があります。 データセットの種類は、作成するデータセットの種類を決定するために使われます。 場合によっては、データセットの種類はテスト用またはトレーニング用にのみ使われることもありますが、それに依存しないようにしてください。 Speech CLI と REST API の kind 値は、次の表に示すように 、Microsoft Foundry ポータル と Speech Studio のオプションに対応します。
| CLI と API の種類 | ポータル のオプション |
|---|---|
| 音響 | トレーニング データ: 音声 + 人間がラベル付けしたトランスクリプト テスト データ: トランスクリプト (自動音声合成) テスト データ: 音声 + 人間がラベル付けしたトランスクリプト |
| AudioFiles | テスト データ: 音声 |
| Language | トレーニング データ: プレーン テキスト |
| LanguageMarkdown | トレーニング データ: マークダウン形式の構造化テキスト |
| 発音 | トレーニング データ: 発音 |
| 出力フォーマット | トレーニング データ: 出力形式 |
重要
Speech CLI または REST API を使用してデータ ファイルを直接アップロードすることはありません。 まず、Speech CLI または REST API がアクセスできる URL にトレーニングまたはテスト データセット ファイルを保存します。 データ ファイルをアップロードしたら、Speech CLI または REST API を使用して、カスタム音声テストまたはトレーニング用のデータセットを作成できます。
データセットを作成して既存のプロジェクトに接続するには、Speech to text REST API の Datasets_Create 操作を使います。 次の手順に従って要求本文を作成します。
projectプロパティを既存のプロジェクトの ID に設定します。projectでカスタム音声の微調整を管理できるように、 プロパティをお勧めします。 プロジェクト ID を取得するには、 REST API ドキュメントのプロジェクト ID を取得するを 参照してください。必須の
kindプロパティを設定します。 トレーニング データセットの種類に使用できる値のセットは、Acoustic、AudioFiles、Language、LanguageMarkdown、Pronunciation です。必須の
contentUrlプロパティを設定します。 このプロパティは、データセットの場所です。 信頼された Azure サービスのセキュリティ メカニズム (次の注を参照) を使用しない場合、contentUrlプロパティは、単純な匿名 GET 要求で取得できる URL である必要があります。 たとえば、SAS URL やパブリックにアクセス可能な URL などです。 追加の承認が必要な URL、またはユーザー操作が必要な URL はサポートされていません。注
Azure BLOB URL を使用する場合は、信頼された Azure サービスのセキュリティ メカニズムを使用することで、データセット ファイルの最高のセキュリティを確保できます。 データセット ファイルの Batch 文字起こしとプレーンストレージ アカウント URL と同じ手法を使用します。 詳細については、こちらを参照してください。
必須の
localeプロパティを設定します。 データセットのロケールは、プロジェクトのロケールと一致する必要があります。 ロケールを後から変更することはできません。必須の
displayNameプロパティを設定します。 このプロパティは、 Microsoft Foundry ポータルに表示される名前です。
HTTP POST 要求は、次の例に示すように URI を使用して行います。
YourSpeechResoureKeyを音声 リソース キーに置き換え、YourServiceRegionを音声 リソース リージョンに置き換え、前述のように要求本文のプロパティをセットします。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"kind": "Acoustic",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"contentUrl": "https://contoso.com/mydatasetlocation",
"locale": "en-US",
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/datasets"
次の形式で応答本文を受け取る必要があります。
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/aaaabbbb-0000-cccc-1111-dddd2222eeee",
"kind": "Acoustic",
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"properties": {
"textNormalizationKind": "Default",
"acceptedLineCount": 2,
"rejectedLineCount": 0,
"duration": "PT59S"
},
"lastActionDateTime": "2024-07-14T17:36:30Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T17:36:14Z",
"locale": "en-US",
"displayName": "My Acoustic Dataset",
"description": "My Acoustic Dataset Description",
"customProperties": {
"PortalAPIVersion": "3"
}
}
応答本文の最上位の self プロパティはデータセットの URI です。 この URI を使って、データセットのプロジェクトとファイルに関する詳細を取得します。 また、データセットの更新または削除にもこの URI を使用します。
重要
REST API または Speech CLI を使用してカスタム モデルをトレーニングおよびテストするために、データセットを Custom Speech プロジェクトに接続する必要はありません。 ただし、データセットがプロジェクトに接続されていない場合は、 Microsoft Foundry ポータルでトレーニングまたはテスト用にデータセットを選択することはできません。