キーワード認識とは
キーワード認識では、オーディオのストリーム内の単語や短いフレーズが検出されます。 この手法は、キーワード スポッティングとも呼ばれます。
キーワード認識の最も一般的なユース ケースは、仮想アシスタントの音声による有効化です。 たとえば、"コルタナさん" は、Cortana アシスタントのキーワードです。 キーワードを認識すると、シナリオ固有のアクションが実行されます。仮想アシスタントのシナリオでは、一般的なアクションとして、キーワードの後に続くオーディオの音声認識が挙げられます。
通常、仮想アシスタントは常にリッスンしています。 キーワード認識は、ユーザーのプライバシー境界として機能します。 キーワード要件はゲートとして機能します。これにより、関連のないユーザー オーディオがローカル デバイスを通過してクラウドに到達しないようにします。
精度、待機時間、計算の複雑さのバランスを取るために、キーワード認識はマルチステージ システムとして実装されます。 最初のステージ以降のすべてのステージでは、その前のステージで対象のキーワードが認識された場合にのみオーディオが処理されます。
現在のシステムは、次のように、エッジとクラウドに広がる複数のステージで設計されています。
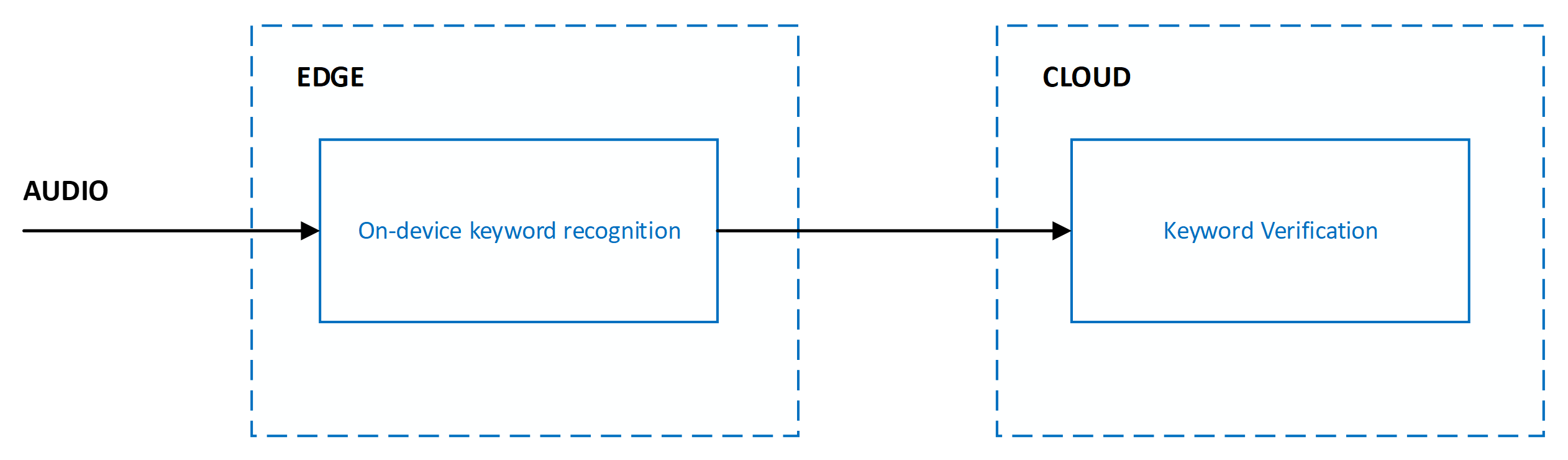
キーワード認識の精度は、次のメトリックによって測定されます。
- 正解受理率: ユーザーが読み上げたキーワードをシステムが認識する能力を測定します。 認識受理率は、真陽性率とも呼ばれます。
- 認識拒否率: エンドユーザーが読み上げた、キーワードでない音声をシステムがフィルタリングする能力を測定します。 認識拒否率は、偽陽性率とも呼ばれます。
目標は、他人受入率を最小限に抑えながら、本人受入率を最大化することです。 現在のシステムは、短期間の無音に続くキーワードまたは語句を検出するように設計されています。 文または発話の途中でキーワードを検出することはできません。
オンデバイス モデルのカスタム キーワード
Speech Studio の Custom Keyword ポータルを使用すると、単語または短い語句を指定することによって、エッジで実行されるキーワード認識モデルを生成できます。 適切な発音を選択してキーワード モデルをさらにパーソナライズすることができます。
価格
Basic モデルと Advanced モデルの両方を含め、モデルを生成するための Custom Keyword の使用は無料です。 音声テキスト変換などの他の Speech Service 機能と組み合わせて使用する場合、Speech SDK を使ってモデルをオンデバイスで実行してもコストは発生しません。
モデルの種類
カスタム キーワードを使用して、任意のキーワードに対して 2 種類のオンデバイス モデルを生成することができます。
| モデルの種類 | 説明 |
|---|---|
| Basic | デモまたは迅速なプロトタイプ作成に最適です。 モデルは一般的なベース モデルで生成され、準備が整うのに最大 15 分かかる場合があります。 モデルの精度特性は、最適ではない場合があります。 |
| 上級 | 成果物統合に最適です。 モデルは、精度特性を高めるために、シミュレートされたトレーニング データを使用して、一般的なベース モデルを調整して生成されます。 モデルが使用できるようになるまで、最大で 48 時間かかる可能性があります。 |
Note
キーワード認識リージョンのサポートに関するドキュメントで、Advanced モデルの種類をサポートするリージョンの一覧を確認できます。
どちらの種類のモデルでも、トレーニング データをアップロードする必要はありません。 カスタム キーワードによって、データ生成とモデル トレーニングが完全に処理されます。
発音
新しいモデルが作成されると、提供されたキーワードの発音候補がカスタム キーワードによって自動的に生成されます。 それぞれの発音を聞き、エンドユーザーによるキーワードの発音に近いと思われる、すべてのバリエーションを選択します。 その以外の発音は選択しないでください。
最高の精度特性を確保するためには、発音を慎重に選択することが重要です。 たとえば、必要以上に多くの発音を選択した場合は、認識拒否率が高くなる可能性があります。 選択した発音が少なすぎて、想定されたバリエーションが含まれない場合は、認識受理率が低くなる可能性があります。
テスト モデル
カスタム キーワードでオンデバイス モデルが生成されたら、それらのモデルをポータルで直接テストできます。 ポータルを使用すると、ブラウザーに直接発話し、キーワード認識の結果を取得することができます。
キーワード検証
キーワード検証は、Azure で実行されている堅牢なモデルを使用して、オンデバイス モデルでの他人受入の影響を軽減するクラウド サービスです。 キーワード検証には、キーワードを使用するためのチューニングやトレーニングは必要ありません。 増分モデルの更新がサービスに継続的にデプロイされて、精度が向上し、待機時間が短縮されます。また、この更新は、クライアント アプリケーションに対して透過的です。
価格
キーワード検証は、常に音声テキスト変換と組み合わせて使用されます。 音声テキスト変換のコストを除いて、キーワード検証は無料です。
キーワード検証と音声テキスト変換
キーワード検証は、常に音声テキスト変換と組み合わせて使用されます。 両方のサービスは並行して実行されます。つまり、両方のサービスに音声が送信され、同時に処理されます。
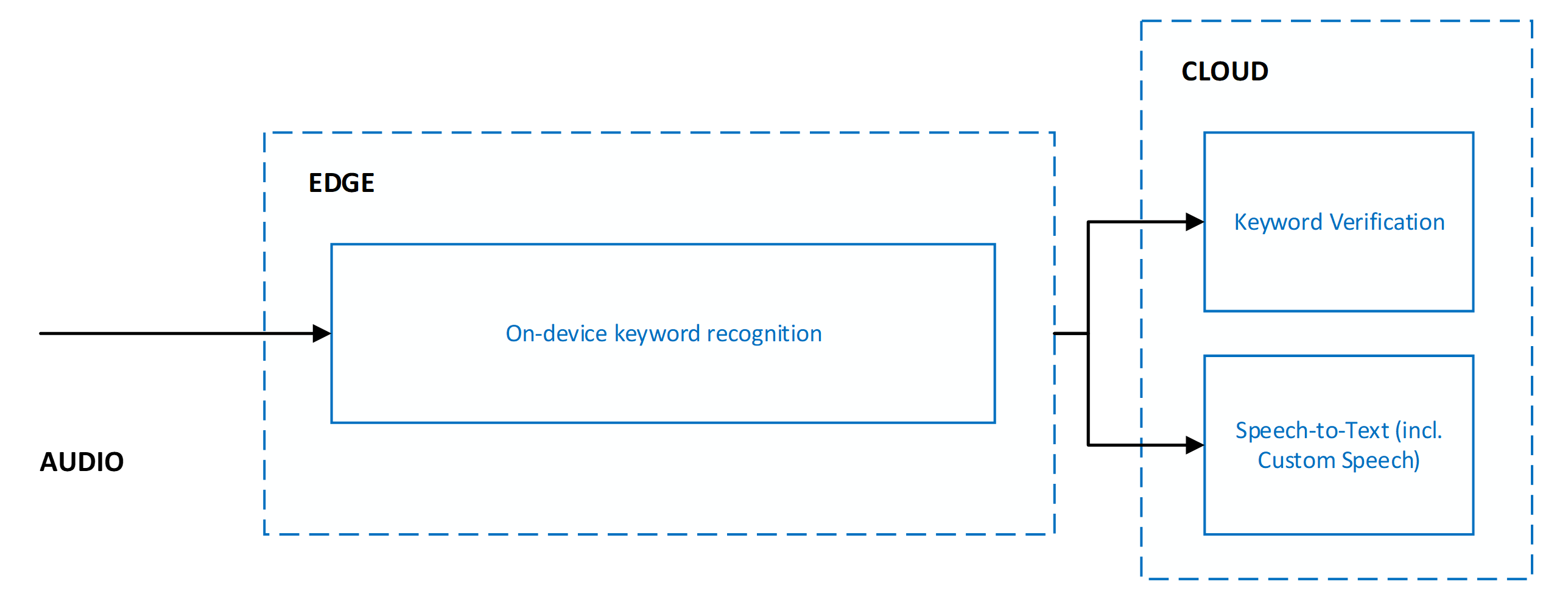
キーワード検証と音声テキスト変換を並行して実行することには、次のような利点があります。
- 音声テキスト変換の結果に関するその他の待機時間: 並列実行は、キーワード検証によって待機時間が増加しないことを意味します。 クライアントは、音声テキスト変換の結果を短時間で受信します。 キーワード検証によって、音声内にキーワードが存在しないと判断された場合は、音声テキスト変換の処理が終了します。 このアクションにより、不要な音声テキスト変換処理が防止されます。 ネットワークおよびクラウド モデルの処理では、ユーザーに認識される、音声による有効化の待機時間が長くなります。 詳細については、推奨事項とガイドラインのページを参照してください。
- 音声テキスト変換の結果内の強制キーワード プレフィックス: 音声テキスト変換処理により、クライアントに送信される結果の先頭に必ずキーワードが付けられます。 この動作により、キーワードに続く音声に対する音声テキスト変換結果の精度が向上します。
- 音声テキスト変換のタイムアウトの延長: 音声の先頭にキーワードがあると想定されているため、音声テキスト変換では、キーワードの後に最大 5 秒の中断が見込まれています。この中断後に、音声が終了したと判断され、音声テキスト変換処理が終了します。 この動作により、ステージングされたコマンド (<keyword><pause><command>) と、チェーンされたコマンド (<keyword><command>) でエンドユーザー エクスペリエンスが確実に正しく処理されます。
キーワード検証の応答と待機時間に関する考慮事項
キーワード検証では、サービスへの要求ごとに、2 つの応答 (受理または拒否) のいずれかが返されます。 処理の待機時間は、キーワードの長さと、キーワードを含むと期待されるオーディオ セグメントの長さによって異なります。 処理の待機時間には、クライアントと音声サービスの間のネットワーク コストは含まれません。
| キーワード検証の応答 | 説明 |
|---|---|
| 同意 | サービスによって、要求の一部として提供されたオーディオ ストリームにキーワードが存在すると判断されたことを示します。 |
| 拒否 | サービスによって、要求の一部として提供されたオーディオ ストリームにキーワードが存在しないと判断されたことを示します。 |
拒否されたケースでは、サービスによって受け入れられるケースよりも多くのオーディオが処理されるため、待機時間が長くなります。 既定では、キーワード検証で、キーワードを検索するために最大 2 秒の音声が処理されます。 2 秒以内にキーワードが見つからない場合、サービスはタイムアウトになり、拒否の応答がクライアントに送信されます。
カスタム キーワードからオンデバイス モデルでキーワード検証を使用する
Speech SDK により、キーワード検証および音声テキスト変換と共にカスタム キーワードを使用して生成されたオンデバイス モデルをシームレスに使用することができます。 次の処理が透過的に行われます。
- オンデバイス モデルの結果に基づく、キーワード検証と音声認識へのオーディオ ゲーティング。
- キーワード検証サービスへのキーワードの伝達。
- エンドツーエンドのシナリオの調整を目的とした、追加のメタデータのクラウドへの伝達。
構成パラメーターを明示的に指定する必要はありません。 必要なすべての情報は、カスタム キーワードによって生成されたオンデバイス モデルから自動的に抽出されます。
以下にリンクされているサンプルとチュートリアルには、Speech SDK の使用方法が示されています。
Speech SDK の統合とシナリオ
Speech SDK を使用すると、カスタム キーワードとキーワード検証サービスで生成された、パーソナライズされたオンデバイス キーワード認識モデルを簡単に使用できます。 製品のニーズを確実に満たすために、この SDK では、次の 2 つのシナリオがサポートされています。
| シナリオ | 説明 | サンプル |
|---|---|---|
| 音声テキスト変換を使用したエンドツーエンドのキーワード認識 | これは、キーワード検証と音声テキスト変換で、カスタム キーワードからカスタマイズされたオンデバイス キーワード モデルを使用する製品に最適です。 このシナリオが最も一般的です。 | |
| オフラインのキーワード認識 | これは、カスタム キーワードからカスタマイズされたオンデバイス キーワード モデルを使用する、ネットワーク接続がない製品に最適です。 |