このチュートリアルでは、FastAPI、Azure OpenAI、Azure AI Searchを使用してPython取得拡張生成 (RAG) アプリケーションを作成し、Azure App Serviceにデプロイします。 このアプリケーションは、独自のドキュメントから情報を取得し、Azureで AI サービスを活用して、適切な引用で正確でコンテキストに対応した回答を提供するチャット インターフェイスを実装する方法を示します。 このソリューションでは、サービス間のパスワードレス認証にマネージド ID を使用します。

このチュートリアルでは、以下の内容を学習します。
- AZUREの AI サービスで RAG パターンを使用する FastAPI アプリケーションをデプロイします。
- ハイブリッド検索Azure OpenAI とAzure AI Searchを構成します。
- AI を利用したアプリケーションで使用するドキュメントをアップロードしてインデックスを作成します。
- セキュリティで保護されたサービス間通信にはマネージド ID を使用します。
- 運用サービスを使用して、RAG 実装をローカルでテストします。
アーキテクチャの概要
デプロイを開始する前に、ビルドするアプリケーションのアーキテクチャを理解しておくと役立ちます。 次の図は、Azure AI Searchの
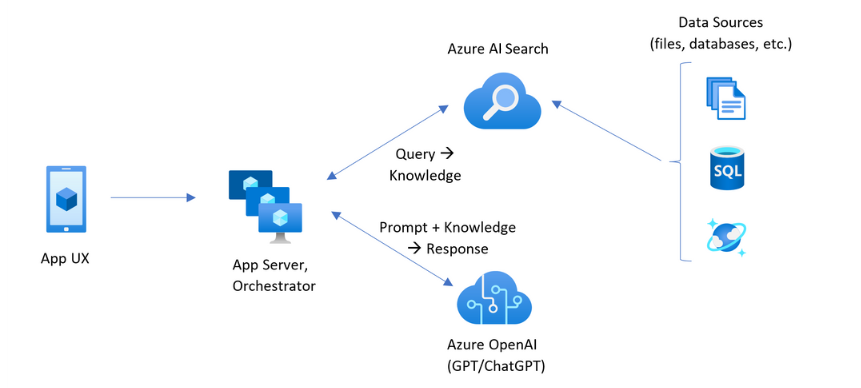
このチュートリアルでは、App Service のブレイザー アプリケーションがアプリ UX とアプリ サーバーの両方を処理します。 ただし、Azure AI Searchでは、ナレッジクエリは個別に行われません。 代わりに、Azure AI Searchをデータ ソースとして指定してナレッジ クエリを実行するように OpenAI Azureに指示します。 このアーキテクチャには、いくつかの主な利点があります。
- Integrated Vectorization: Azure AI Searchの統合されたベクター化機能により、埋め込みを生成するためのコードを追加しなくても、すべてのドキュメントを簡単かつ迅速に検索に取り込めます。
- Simplified API Access: Azure OpenAI On Your Data パターンを使用して、Azure OpenAI 補完のデータ ソースとしてAzure AI Searchを使用することで、複雑なベクター検索や埋め込み生成を実装する必要はありません。 単に API 呼び出し 1 つで、Azure OpenAI がプロンプト エンジニアリングやクエリの最適化を含めてすべてを処理します。
- 高度な検索機能: 統合されたベクター化は、高度なハイブリッド検索に必要なすべてのものをセマンティック 再ランク付けと共に提供します。これは、キーワード マッチング、ベクター類似性、AI を利用したランク付けの長所を組み合わせたものです。
- 引用文献の完全なサポート: 応答には、ソース ドキュメントへの引用文献が自動的に含まれ、情報が検証可能で追跡可能になります。
[前提条件]
- アクティブなサブスクリプションを持つAzure アカウント - 無料のアカウントを作成。
- GitHubのアカウントを使用してGitHub Codespacesを利用する - GitHub Codespacesの詳細をご覧ください。
1. Codespaces を使用してサンプルを開く
開始する最も簡単な方法は、GitHub Codespaces を使用することです。Codespaces は、必要なすべてのツールがプレインストールされた完全な開発環境を提供します。
https://github.com/Azure-Samples/app-service-rag-openai-ai-search-python にあるGitHub リポジトリに移動します。
[ コード ] ボタンを選択し、[ Codespaces ] タブを選択し、[ メインでコードスペースの作成] をクリックします。
Codespace が初期化されるまでしばらく待ちます。 準備ができたら、ブラウザーに完全に構成された VS Code 環境が表示されます。
2. サンプル アーキテクチャをデプロイする
ターミナルで、Azure Developer CLI を使用してAzureにログインします。
azd auth login手順に従って認証プロセスを完了します。
AZD テンプレートを使用してAzure リソースをプロビジョニングします。
azd provisionメッセージが表示されたら、次の回答を入力します。
質問 答え 新しい環境名を入力します。 一意の名前を入力します。 使用するAzure サブスクリプションを選択します。 サブスクリプションを選択します。 使用するリソース グループを選択します。 [Create a new resource group]\(新しいリソース グループの作成\) を選択します。 リソース グループを作成する場所を選択します。 任意のリージョンを選択します。 リソースは実際には 米国東部 2 に作成されます。 新しいリソース グループの名前を入力します。 「Enter」と入力します。 デプロイが完了するまで待ちます。 このプロセスでは、次の処理が行われます。
- 必要なすべてのAzure リソースを作成します。
- アプリケーションを Azure App Service にデプロイします。
- マネージド ID を使用してセキュリティで保護されたサービス間認証を構成します。
- サービス間のセキュリティで保護されたアクセスに必要なロールの割り当てを設定します。
注
マネージド ID のしくみの詳細については、「Azure リソースのマネージド ID とは何ですか?>」および「 App Service でマネージド ID を使用する方法を参照してください。
デプロイが成功すると、デプロイされたアプリケーションの URL が表示されます。 この URL は書き留めておきますが、検索インデックスを設定する必要があるため、まだアクセスしないでください。
3. ドキュメントをアップロードして検索インデックスを作成する
インフラストラクチャがデプロイされたので、ドキュメントをアップロードし、アプリケーションで使用する検索インデックスを作成する必要があります。
Azure ポータルで、デプロイによって作成されたストレージ アカウントに移動します。 この名前は、前に指定した環境名で始まります。
左側のナビゲーション メニューから [データ ストレージ>Containers ] を選択し、 ドキュメント コンテナーを開きます。
[アップロード] をクリックしてサンプル ドキュメントを アップロードします。 リポジトリ内の
sample-docsフォルダーのサンプル ドキュメント、または独自の PDF、Word、またはテキスト ファイルを使用できます。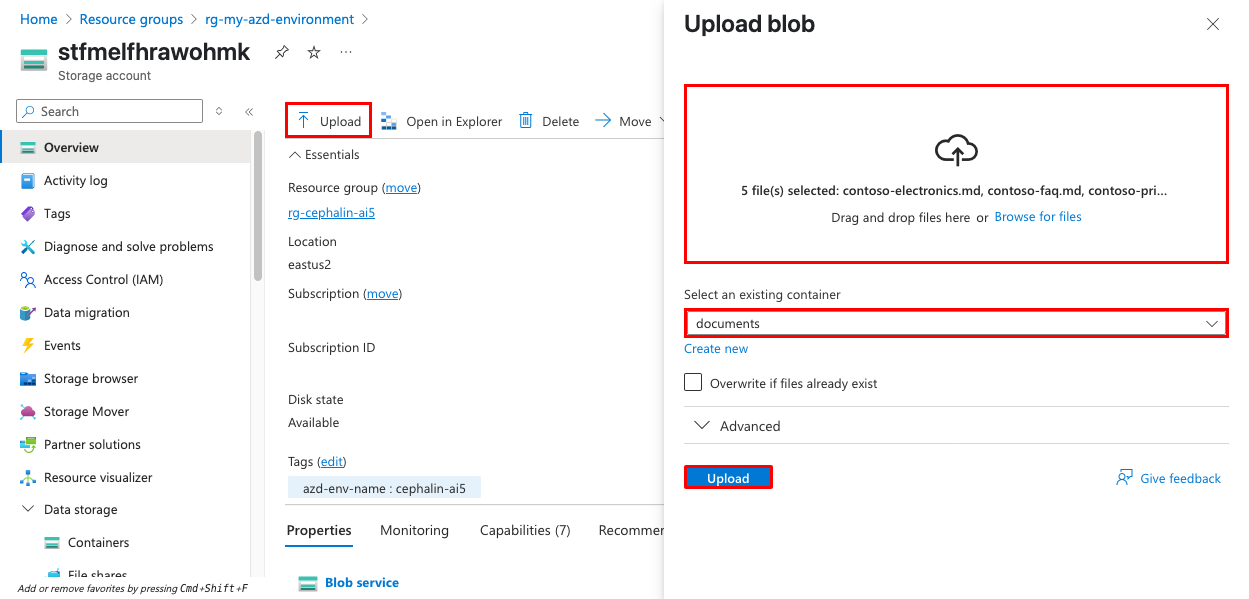
Azure ポータルでAzure AI Search サービスに移動します。
[ データのインポート ](新規) を選択して、検索インデックスの作成プロセスを開始します。
![Azure AI Search の [データのインポートとベクター化] ボタンを示すスクリーンショット](media/tutorial-ai-openai-search-dotnet/ai-search-import-vectorize.png)
[ データへの接続] ステップで、次の操作を行います 。
- データ ソースとして Azure Blob Storage を選択します。
- RAG を選択します。
- ストレージ アカウントと ドキュメント コンテナーを選択します。
- [ マネージド ID を使用した認証] を選択します。
- 次へを選択します。
テキストのベクター化ステップで、 次の操作を行います 。
- Azure OpenAI サービスを選択します。
- 埋め込みモデルとして text-embedding-ada-002 を選択します。 AZD テンプレートでは、このモデルが既にデプロイされています。
- 認証に システム割り当て ID を 選択します。
- 追加コストの確認チェック ボックスをオンにします。
- 次へを選択します。
ヒント
Azure AI Search Azure OpenAI でのテキスト埋め込みの詳細について説明します。[Vectorize and enrich your images]\(イメージのベクター化とエンリッチメント\) ステップで、次の操作を行います。
- 既定の設定のままにします。
- 次へを選択します。
[詳細設定] ステップで、次の操作を行います。
- [セマンティック ランカーを有効にする] が選択されていることを確認します。
- (省略可能)インデックス作成スケジュールを選択します。 これは、最新のファイル変更でインデックスを定期的に更新する場合に便利です。
- 次へを選択します。
[ 確認と作成 ] 手順で、次の手順を実行します。
- オブジェクト名のプレフィックス値をコピーします。 検索インデックス名です。
- [ 作成] を選択してインデックス作成プロセスを開始します。
インデックス作成プロセスが完了するまで待ちます。 ドキュメントのサイズと数によっては、数分かかる場合があります。
データのインポートをテストするには、[検索を開始] を選択し、"会社について教えてください" などの検索クエリを試します。
Codespace ターミナルに戻り、検索インデックス名を AZD 環境変数として設定します。
azd env set SEARCH_INDEX_NAME <your-search-index-name><your-search-index-name>は、前にコピーしたインデックス名に置き換えます。 AZD は、後続のデプロイでこの変数を使用して App Service アプリ設定を設定します。
4.アプリケーションをテストしてデプロイする
デプロイ前またはデプロイ後にアプリケーションをローカルでテストする場合は、Codespace から直接実行できます。
Codespace ターミナルで、AZD 環境の値を取得します。
azd env get-values.envを開きます。 ターミナル出力を使用して、それぞれのプレースホルダー<input-manually-for-local-testing>で、次の値を更新します。AZURE_OPENAI_ENDPOINTAZURE_SEARCH_SERVICE_URLAZURE_SEARCH_INDEX_NAME
Azure CLIを使用してAzureにサインインします。
az loginこれにより、サンプル コードのAzure ID クライアント ライブラリは、ログインしているユーザーの認証トークンを受け取ることができます。
アプリケーションをローカルで実行します。
pip install -r requirements.txt uvicorn main:appポート 8000 で実行されているアプリケーションの出力が表示されたら、[ブラウザーで開く] を選択します。
チャット インターフェイスでいくつかの質問をしてみてください。 応答が返された場合、アプリケーションは Azure OpenAI リソースに正常に接続しています。
Ctrl + C キーを押して開発サーバーを停止します。
Azureで新しい
SEARCH_INDEX_NAME構成を適用し、サンプル アプリケーション コードをデプロイします。azd up
5. デプロイされた RAG アプリケーションをテストする
アプリケーションが完全にデプロイされ、構成されたので、RAG 機能をテストできるようになりました。
デプロイの最後に指定されたアプリケーション URL を開きます。
アップロードしたドキュメントの内容に関する質問を入力できるチャット インターフェイスが表示されます。
ドキュメントの内容に固有の質問をしてみてください。 たとえば、 sample-docs フォルダーにドキュメントをアップロードした場合は、次の質問を試すことができます。
- Contoso は個人データをどのように使用しますか?
- 保証請求はどのように行いますか?
応答に、ソース ドキュメントを参照する引用文献が含まれていることがわかります。 これらの引用は、ユーザーが情報の正確性を確認し、ソース資料の詳細を見つけるのに役立ちます。
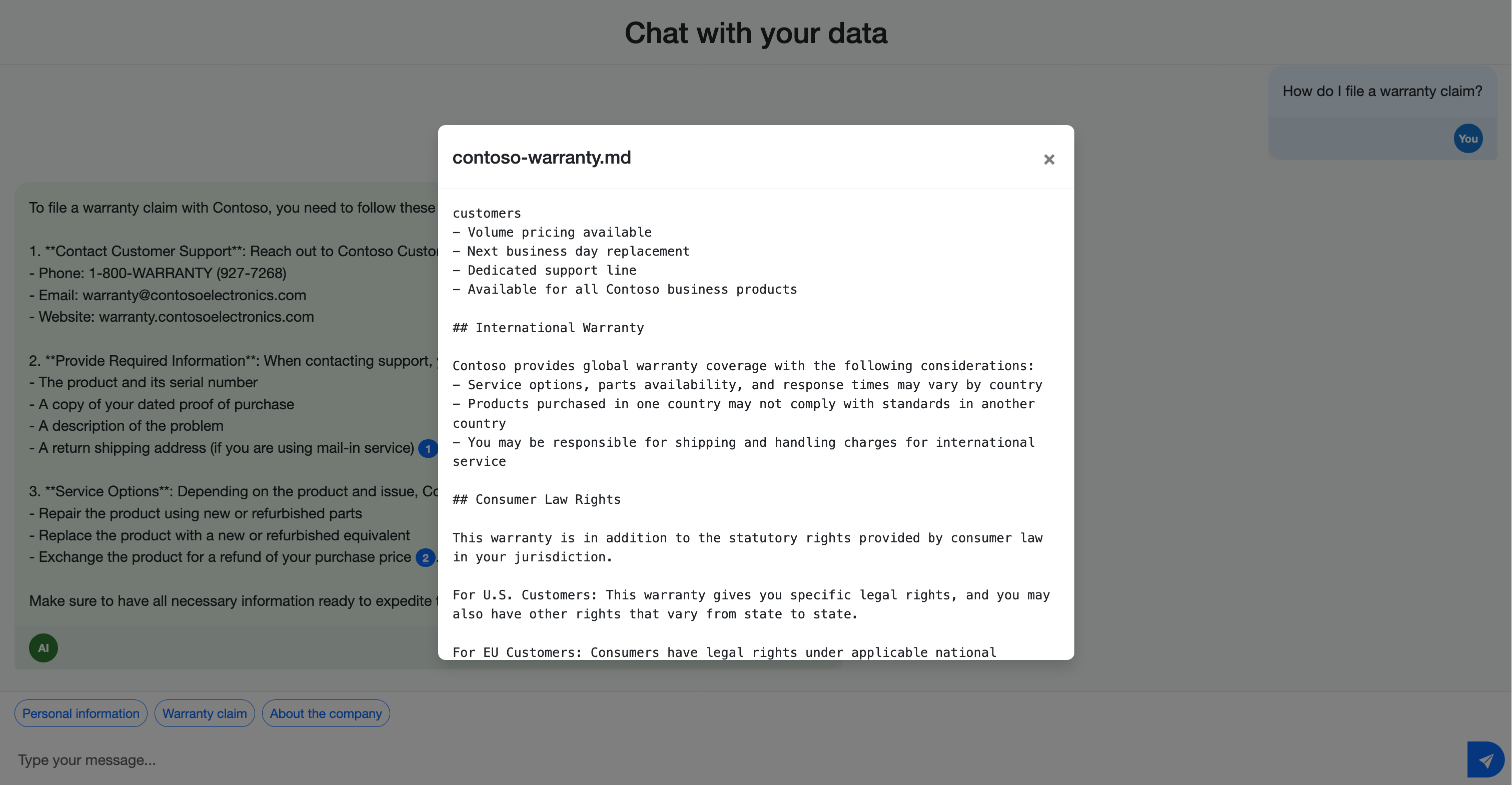
さまざまな検索方法のメリットを得られる可能性のある質問をして、ハイブリッド検索機能をテストします。
- 特定の用語を含む質問 (キーワード検索に適しています)。
- 異なる用語を使用して記述される可能性のある概念に関する質問 (ベクター検索に適しています)。
- コンテキストを理解する必要がある複雑な質問 (セマンティック ランク付けに適しています)。
リソースをクリーンアップする
アプリケーションの使用が完了したら、すべてのリソースを削除して、追加のコストが発生しないようにすることができます。
azd down --purge
このコマンドは、アプリケーションに関連付けられているすべてのリソースを削除します。
よく寄せられる質問
- サンプルコードでAzure OpenAIチャットの完了から引用文献を取得する方法
- このソリューションでマネージド ID を使用する利点は何ですか?
- このアーキテクチャとサンプル アプリケーションでは、システム割り当てマネージド ID はどのように使用されますか?
- サンプル アプリケーションでセマンティック ランカーを使用したハイブリッド検索はどのように実装されますか?
- すべてのリソースが米国東部 2 で作成される理由
- Azureによって提供されるモデルではなく、独自の OpenAI モデルを使用できますか?
- 応答の品質を向上させるにはどうすればよいですか?
サンプルコードは、Azure OpenAIのチャット生成結果から引用文献を取得する方法を説明しています。
このサンプルでは、チャット クライアントのAzure AI Searchを含むデータ ソースを使用して引用文献を取得します。 チャットの完了が要求されると、応答にはメッセージ コンテキスト内に citations オブジェクトが含まれます。 サンプル アプリケーションは、応答オブジェクトをクライアント コードに渡し、次のように引用文献を抽出します。
fetch('/api/chat/completion', {
// ...
})
// ...
.then(data => {
// ...
const message = choice.message;
const content = message.content;
// Extract citations from context
const citations = message.context?.citations || [];
// ...
})
応答メッセージでは、コンテンツは [doc#] 表記を使用してリスト内の対応する引用文献を参照し、ユーザーは元のソース ドキュメントに情報をトレースできます。 詳細については、以下を参照してください。
このソリューションでマネージド ID を使用する利点は何ですか?
マネージド ID を使用すると、コードまたは構成に資格情報を格納する必要がなくなります。 マネージド ID を使用することで、アプリケーションはシークレットを管理することなく、Azure OpenAI や Azure AI Search などのAzure サービスに安全にアクセスできます。 この方法はZero Trustセキュリティ原則に従い、資格情報の公開のリスクを軽減します。
このアーキテクチャとサンプル アプリケーションでは、システム割り当てマネージド ID はどのように使用されますか?
AZD デプロイでは、Azure App Service、Azure OpenAI、およびAzure AI Searchのシステム割り当てマネージド ID が作成されます。 また、それぞれのロールの割り当てを行います ( main.bicep ファイルを参照)。 必要なロールの割り当ての詳細については、「データ上の OpenAI Azureのネットワーク構成とアクセス構成を参照してください。
サンプル FastAPI アプリケーションでは、Azure SDKsはセキュリティで保護された認証にこのマネージド ID を使用するため、資格情報やシークレットをどこにも格納する必要はありません。 たとえば、AsyncAzureOpenAI クライアントは DefaultAzureCredential で初期化され、Azureで実行するときにマネージド ID が自動的に使用されます。
self.credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
self.credential,
"https://cognitiveservices.azure.com/.default"
)
self.openai_client = AsyncAzureOpenAI(
azure_endpoint=self.openai_endpoint,
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
同様に、Azure AI Search用にデータ ソースを構成する場合、マネージド ID は認証用に指定されます。
data_source = {
"type": "azure_search",
"parameters": {
"endpoint": self.search_url,
"index_name": self.search_index_name,
"authentication": {
"type": "system_assigned_managed_identity"
},
# ...
}
}
response = await self.openai_client.chat.completions.create(
model=self.gpt_deployment,
messages=messages,
extra_body={
"data_sources": [data_source]
},
stream=False
)
このセットアップにより、fastAPI アプリとAzure サービス間の安全でパスワードなしの通信が可能になり、Zero Trustセキュリティのベスト プラクティスに従います。 DefaultAzureCredential と Azure Identity client library for Python について説明します。
サンプル アプリケーションでセマンティック ランカーを使用したハイブリッド検索はどのように実装されますか?
サンプル アプリケーションでは、Azure OpenAI SDK を使用して、セマンティック ランク付けを使用してハイブリッド検索を構成します。 バックエンドでは、データ ソースは次のように設定されます。
data_source = {
"type": "azure_search",
"parameters": {
# ...
"query_type": "vector_semantic_hybrid",
"semantic_configuration": f"{self.search_index_name}-semantic-configuration",
"embedding_dependency": {
"type": "deployment_name",
"deployment_name": self.embedding_deployment
}
}
}
この構成により、アプリケーションはベクター検索 (セマンティック類似性)、キーワード マッチング、セマンティック ランク付けを 1 つのクエリで組み合わせることができます。 セマンティック ランカーは結果を並べ替えて、最も関連性が高くコンテキストに応じて適切な回答を返します。これは、Azure OpenAI によって応答を生成するために使用されます。
セマンティック構成名は、統合ベクター化プロセスによって自動的に定義されます。 検索インデックス名をプレフィックスとして使用し、サフィックスとして -semantic-configuration を追加します。 これにより、セマンティック構成が対応するインデックスに一意に関連付けられることが保証され、一貫した名前付け規則に従います。
すべてのリソースが米国東部 2 で作成される理由
このサンプルでは 、gpt-4o-mini モデルと text-embedding-ada-002 モデルを 使用します。どちらも米国東部 2 の Standard デプロイ タイプで使用できます。 これらのモデルは、すぐには退役させる予定がないため、サンプルデプロイの安定性を確保するために選ばれています。 モデルの可用性とデプロイの種類はリージョンによって異なることがあるため、サンプルがすぐに動作するように、米国東部 2 が選ばれています。 別のリージョンまたはモデルを使用する場合は、同じリージョン内の同じデプロイの種類で使用できるモデルを選択してください。 独自のモデルを選択する場合は、中断を回避するために、可用性と提供終了日の両方を確認します。
- モデルの可用性: Azure OpenAI Service モデル
- モデルの提供終了日: Azure OpenAI Service モデルの廃止と提供終了。
Azureが提供するモデルではなく、独自の OpenAI モデルを使用できますか?
このソリューションは、Azure OpenAI Serviceを使用するように設計されています。 他の OpenAI モデルを使用するようにコードを変更することもできますが、統合されたセキュリティ機能、マネージド ID のサポート、およびこのソリューションが提供するAzure AI Searchとのシームレスな統合は失われます。
応答の品質を向上させるにはどうすればよいですか?
次の方法で応答品質を向上させることができます。
- より高品質で関連性の高いドキュメントをアップロードする。
- Azure AI Searchインデックス作成パイプラインでのチャンク戦略の調整。 ただし、このチュートリアルで示す統合ベクター化を使用してチャンクをカスタマイズすることはできません。
- アプリケーション コードでさまざまなプロンプト テンプレートを試す。
-
type: "azure_searchデータ ソース内の他のプロパティを使用して検索を微調整します。 - 特定のドメインに対してより特殊な Azure OpenAI モデルを使用する。
その他のリソース
- Azure AI Search のハイブリッド検索機能を探る
- Azure OpenAI をデータで使用する
- Python用のOpenAIクライアントライブラリ
Python Web アプリを Azure App Service