Document Intelligence カスタム モデル
重要
- Document Intelligence パブリック プレビュー リリースは、開発中の機能への早期アクセスを提供します。
- 機能、アプローチ、およびプロセスは、一般提供 (GA) の前に、ユーザーからのフィードバックに基づいて変更される可能性があります。
- Document Intelligence クライアント ライブラリのパブリック プレビュー バージョンは、REST API バージョン2024-02-29-preview にデフォルトで設定されます。
- パブリック プレビュー バージョン 2024-02-29-preview は、現在、次の Azure リージョンでのみ使用できます。
- 米国東部
- 米国西部 2
- "西ヨーロッパ"
このコンテンツの適用対象:![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
このコンテンツの対象:![]() v3.1 (GA) | 最新バージョン:
v3.1 (GA) | 最新バージョン:![]() v4.0 (プレビュー) | 以前のバージョン:
v4.0 (プレビュー) | 以前のバージョン:![]() v3.0
v3.0![]() v2.1
v2.1
このコンテンツの対象:![]() v3.0 (GA) | 最新バージョン:
v3.0 (GA) | 最新バージョン:![]() v4.0 (プレビュー)
v4.0 (プレビュー)![]() v3.1 | 以前のバージョン:
v3.1 | 以前のバージョン:![]() v2.1
v2.1
このコンテンツの適用対象:![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン:![]() v4.0 (プレビュー)
v4.0 (プレビュー)
Document Intelligence では、高度な機械学習テクノロジを使用してドキュメントを識別し、フォームとドキュメントから情報を検出および抽出し、抽出したデータを構造化 JSON 出力で返します。 Document Intelligence では、ドキュメント分析モデル、事前構築/事前トレーニング済み、またはトレーニング済みのスタンドアロン カスタム モデルを使用できます。
カスタム モデルには、抽出モデルを呼び出す前にドキュメントの種類を識別する必要があるシナリオ用のカスタム分類モデルが含まれるようになりました。 分類子モデルは、2023-07-31 (GA) API 以降で使用できます。 分類モデルをカスタム抽出モデルと組み合わせて、ビジネスに固有のフォームやドキュメントからフィールドを分析および抽出し、ドキュメント処理ソリューションを作成できます。 スタンドアロンのカスタム抽出モデルを組み合わせて、作成済みモデルを作成できます。
カスタム ドキュメント モデルの種類
カスタム ドキュメント モデルには、カスタム テンプレートまたはカスタム フォームと、カスタム ニューラルまたはカスタム ドキュメント モデルの 2 種類があります。 両方のモデルのラベル付けとトレーニングのプロセスは同じですが、モデルは次のように異なります。
カスタム抽出モデル
カスタム抽出モデルを作成するには、抽出する値を持つドキュメントのデータセットにラベルを付け、ラベル付けされたデータセットに対してモデルをトレーニングします。 始めるために必要な同じフォームまたはドキュメントの種類の例は 5 つのみです。
カスタム ニューラル モデル
重要
バージョン 4.0 (2024-02-29-preview API) 以降、カスタム ニューラル モデルでは、重複するフィールドとテーブル、行、およびセル レベルの信頼度がサポートされるようになりました。
カスタム ニューラル (カスタム ドキュメント) モデルでは、ディープ ラーニング モデルと、ドキュメントの大規模なコレクションでトレーニングされたベース モデルを使用します。 このモデルは、ラベル付けされたデータセットを使用してモデルをトレーニングするときに、データに合わせて微調整または調整されます。 カスタム ニューラル モデルでは、構造化、半構造化、および非構造化ドキュメントをサポートして、フィールドを抽出します。 カスタム ニューラル モデルでは、現在、英語のドキュメントをサポートしています。 2 つのモデルの種類から選択する場合は、まずニューラル モデルで、それが機能的なニーズを満たすかどうかを判断してください。 カスタム ドキュメント モデルの詳細については、ニューラル モデルに関するページを参照してください。
カスタム テンプレート モデル
カスタム テンプレート モデルまたはカスタム フォーム モデルは、ラベル付けされたデータを抽出するために一貫性のあるビジュアル テンプレートに依存します。 ドキュメントの視覚的構造の差異は、モデルの正確性に影響します。 アンケートやアプリケーションなどの構造化されたフォームは、一貫したビジュアル テンプレートの例です。
トレーニング セットは、書式設定とレイアウトが静的で、1 つのドキュメント インスタンスから次のインスタンスに固定されている構造化ドキュメントで構成されます。 カスタム テンプレート モデルでは、キーと値のペア、選択マーク、テーブル、署名フィールド、リージョンがサポートされます。 テンプレート モデルは、いずれかのサポートされている言語のドキュメントでトレーニングできます。 詳細については、カスタム テンプレート モデルに関するページを参照してください。
ドキュメントと抽出シナリオの言語がカスタム ニューラル モデルをサポートしている場合は、テンプレート モデルに対してカスタム ニューラル モデルを使用して精度を向上することをお勧めしています。
ヒント
トレーニング ドキュメントによって一貫性のあるビジュアル テンプレートが表示されることを確認するには、セット内の各フォームからユーザーが入力したデータをすべて削除します。 空白のフォームの外観が同じである場合は、一貫性のあるビジュアル テンプレートを表します。
詳細については、「カスタム モデルの正確性スコアと信頼度スコアの解釈と改善」を参照してください。
入力の要件
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
サポートされているファイル形式:
モデル PDF 画像:
jpeg/jpg、png、bmp、tiff、heifMicrosoft Office:
Word (docx)、Excel (xlsx)、PowerPoint (pptx)読み込み ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview、2023-10-31-preview、およびそれ以降) 一般的なドキュメント ✔ ✔ 事前構築済み ✔ ✔ カスタム抽出 ✔ ✔ カスタム分類 ✔ ✔ ✔ ✱ 現在、Microsoft Office ファイルは他のモデルやバージョンではサポートされません。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは 4 MB です。
画像のディメンションは、50 x 50 ピクセルから 10,000 x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、1 インチあたり 150 ドットで約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は 1GB です。
カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GBで、最大 10,000 ページです。
ビルド モード
カスタム モデルのビルド操作を行うと、テンプレートと、ニューラル カスタム モデルのサポートが追加されます。 以前のバージョンの REST API とクライアント ライブラリでは、"テンプレート" モードと呼ばれる 1 つのビルド モードのみがサポートされていました。
テンプレート モデルでは、同じ基本ページ構造を持つ (一貫した外観の) ドキュメント、またはドキュメント内の要素の相対的位置が同じドキュメントのみが受け入れられました。
ニューラル モデルでは、同じ情報を含んでいても、ページ構造が異なるドキュメントがサポートされます。 これらのドキュメントの例には、同じ情報を共有する米国の W2 フォームが含まれますが、外観は会社によって異なります。 現在、ニューラル モデルは英語のテキストのみをサポートしています。
次の表に、GitHub のビルド モード プログラミング言語 SDK リファレンスとコード サンプルへのリンクを示します。
| プログラミング言語 | SDK リファレンス | コード サンプル |
|---|---|---|
| C#/.NET | DocumentBuildMode 構造体 | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode クラス | BuildModel.java |
| JavaScript | DocumentBuildMode タイプ | buildModel.js |
| Python | DocumentBuildMode 列挙型 | sample_build_model.py |
モデルの特徴を比較する
次の表では、カスタム テンプレートとカスタム ニューラル機能を比較しています。
| 機能 | カスタム テンプレート (フォーム) | カスタム ニューラル (ドキュメント) |
|---|---|---|
| ドキュメントの構造 | テンプレート、フォーム、構造化 | 構造化、半構造化、非構造化 |
| トレーニング時間 | 1 分から 5 分 | 20 分から 1 時間 |
| データの抽出 | キーと値のペア、テーブル、選択マーク、座標、署名 | キーと値のペア、選択マーク、テーブル |
| 重複するフィールド | サポートされていません | サポートされています |
| ドキュメントのバリエーション | バリエーションごとにモデルが必要 | すべてのバリエーションで 1 つのモデルを使用する |
| 言語のサポート | 複数の言語サポート | 英語の言語サポート (スペイン語、フランス語、ドイツ語、イタリア語、オランダ語のプレビュー サポートを含む) |
カスタム分類モデル
ドキュメント分類は、2023-07-31 (v3.1 GA) API の Document Intelligence によってサポートされる新しいシナリオです。 ドキュメント分類子 API では、分類と分割のシナリオがサポートされています。 分類モデルをトレーニングして、アプリケーションでサポートされているさまざまな種類のドキュメントを識別します。 分類モデルの入力ファイルには、複数のドキュメントを含め、関連付けられているページ範囲内の各ドキュメントを分類できます。 詳細については、「カスタム分類モデル」を "参照してください"。
Note
2024-02-29-preview API バージョンのドキュメント分類以降、分類用に Office ドキュメントの種類がサポートされるようになりました。 この API バージョンでは、分類モデルの増分トレーニングも導入されています。
カスタム モデル ツール
ドキュメント インテリジェンス v3.1 以降のモデルでは、次のツール、アプリケーション、ライブラリ、プログラム、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| カスタム モデル | • ドキュメントインテリジェンススタジオ • REST API • C# SDK • Python SDK |
custom-model-id |
ドキュメント インテリジェンス v2.1 では、次のツール、アプリケーション、およびライブラリがサポートされています:
Note
カスタム ニューラルとカスタム テンプレートのカスタム モデルの種類は、Document Intelligence バージョン v3.1 および v3.0 API で使用できます。
| 機能 | リソース |
|---|---|
| カスタム モデル | • ドキュメント インテリジェンスラベル付けツール • REST API • クライアント ライブラリ SDK •ドキュメント インテリジェンス Docker コンテナー |
カスタム モデルの構築
カスタム モデルを使用して、特定のドキュメントまたは一意のドキュメントからデータを抽出します。 以下のリソースが必要です。
Azure サブスクリプション。 無料で作成できます。
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。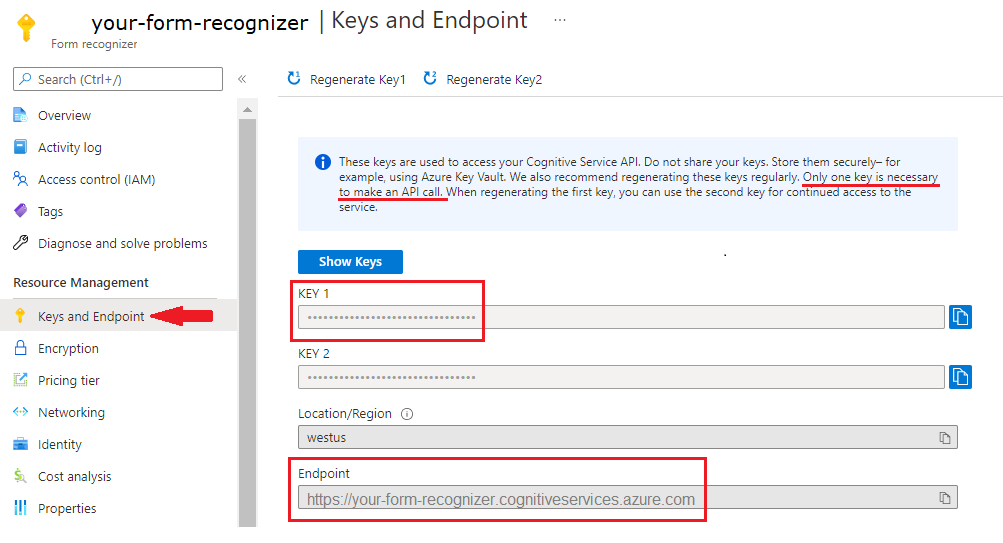
サンプル ラベル付けツール
ヒント
- 強化されたエクスペリエンスと高度なモデル品質のためには、Document Intelligence v3.0 Studio をお試しください。
- v3.0 Studio では、v2.1 ラベル付きデータでトレーニングされたすべてのモデルがサポートされます。
- v2.1 から v3.0 への移行の詳細については、API 移行ガイドを参照してください。
- v3.0 バージョンで作業開始するには、REST API または、C#、Java、JavaScript、Python の SDK クイックスタートを "参照" してください。
Document Intelligence サンプル ラベル付けツールは Document Intelligence および光学式文字認識 (OCR) 機能の最新の機能をテストできるようにするオープンソース ツールです。
カスタム モデルの構築と使用を開始するには、サンプル ラベル付けツールのクイックスタートを試してください。
Document Intelligence Studio
Note
Document Intelligence Studio は、v3.1 と v3.0 の API で使用できます。
Document Intelligence Studio ホーム ページで、[Custom extraction models] (カスタム抽出モデル) を選択します。
[マイ プロジェクト] で、[Create a project](プロジェクトの作成) を選択します。
プロジェクトの詳細を指定するフィールドに値を入力します。
[Connect your training data source](トレーニング データ ソースを接続) に、Storage アカウントと BLOB コンテナーを追加して、サービス リソースを構成します。
プロジェクトを確認して作成します。
サンプル ドキュメントを追加して、カスタム モデルにラベルを付け、ビルドし、テストします。
最初のカスタム抽出モデルを作成する詳細なチュートリアルについては、「カスタム抽出モデルを作成する方法」を "参照してください"。
カスタム モデル抽出の概要
次の表は、サポートされているデータ抽出領域を比較しています。
| モデル | フォーム フィールド | 選択マーク | 構造化フィールド (テーブル) | 署名 | 領域のラベル付け | 重複するフィールド |
|---|---|---|---|---|---|---|
| カスタム テンプレート | ✔ | ✔ | ✔ | ✔ | ✔ | 該当なし |
| カスタム ニューラル | ✔ | ✔ | ✔ | 該当なし | * | ✔ (2024-02-29-preview) |
表の記号:
✔ — サポート対象
**n/a — 現在は利用不可。
* — モデルによって動作が異なる。 テンプレート モデルでは、トレーニング時に合成データが生成されます。 ニューラル モデルでは、リージョンで認識される終了テキストが選択されます。
ヒント
2 つのモデルの種類から選択する場合、それが機能的なニーズを満たす場合は、カスタム ニューラル モデルから開始します。 カスタム ニューラル モデルの詳細については、カスタム ニューラルに関するページを参照してください。
カスタム モデル開発オプション
次の表では、関連付けられているツールとクライアント ライブラリで使用できる機能について説明します。 ベスト プラクティスとして、ここに記載されている互換性のあるツールを使用することをお勧めします。
| ドキュメントの種類 | REST API | SDK | モデルのラベル付けとテスト |
|---|---|---|---|
| カスタム テンプレート v 4.0 v3.1 v3.0 | Document Intelligence 3.1 | ドキュメント インテリジェンス SDK | Document Intelligence Studio |
| カスタム ニューラル v4.0 v3.1 v3.0 | Document Intelligence 3.1 | ドキュメント インテリジェンス SDK | Document Intelligence Studio |
| カスタム フォーム v2.1 | Document Intelligence 2.1 GA API | ドキュメント インテリジェンス SDK | サンプル ラベル付けツール |
Note
3.0 API でトレーニングされたカスタム テンプレート モデルでは、OCR エンジンの機能強化による 2.1 API のいくつかの改善点があります。 2.1 API を使用してカスタム テンプレート モデルをトレーニングするために使用されるデータセットは、3.0 API を使用して新しいモデルをトレーニングするために引き続き使用できます。
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
サポートされているファイル形式は、JPEG/JPG、PNG、BMP、TIFF、および PDF (テキスト埋め込みまたはスキャン済み) です。 文字の抽出と位置に関するエラーが発生する可能性を排除するには、テキストが埋め込まれている PDF が最適です。
PDF ファイルと TIFF ファイルの場合は、最大 2,000 ページを処理できます。 Free レベルのサブスクリプションでは、最初の 2 ページだけが処理されます。
ファイル サイズは、有料 (S0) レベルでは 500 MB 未満、Free (F0) レベルでは 4 MB 未満である必要があります。
画像の寸法は、50 x 50 ピクセルから 10,000 x 10,000 ピクセルの間である必要があります。
PDF の寸法は、17 x 17 インチまでで、Legal または A3 サイズ以下の用紙に対応します。
トレーニング データの合計サイズは、500 ページ以下です。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
ヒント
トレーニング データ:
- 可能であれば、画像ベースのドキュメントではなく、テキストベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として処理されます。
- 文書ごとにフォームのインスタンスを 1 つだけ指定してください。
- 入力フォームの場合は、すべてのフィールドに入力されている例を使用します。
- 各フィールドに異なる値が含まれたフォームを使用します。
- フォーム イメージの品質が低い場合は、より大きなデータセットを使用します。 たとえば、10 ~ 15 のイメージを使用します。
サポートされている言語とロケール
サポートされている言語の完全なリストについては、以下を 参照してください。 言語サポート—のカスタム モデル ページ。
次のステップ
Document Intelligence サンプル ラベル付けツールを使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。
Document Intelligence Studio を使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。