ソリューションのアイデア
このアーティクルはソリューションのアイデアです。 このコンテンツにさらに多くの情報 (想定されるユース ケース、代替サービス、実装に関する考慮事項、価格ガイダンスなど) の掲載をご希望の方は、 GitHub のフィードバックでお知らせください。
この記事は、 「カスタム音声テキスト変換を実装する」で説明されているソリューションのサンプル デプロイを提供する実装ガイドとシナリオ例です。
Architecture
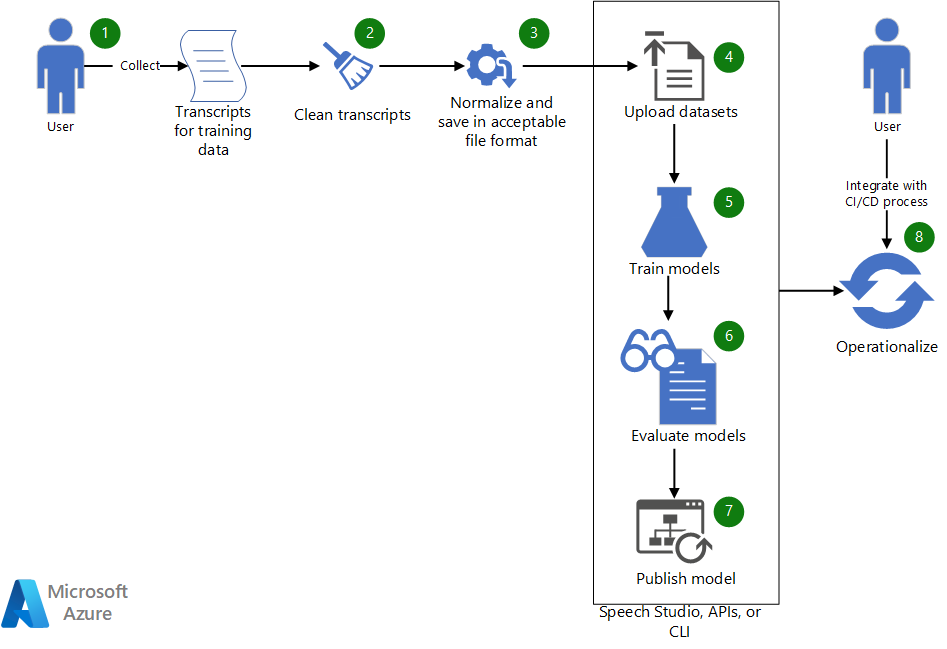
このアーキテクチャの Visio ファイル をダウンロードします。
ワークフロー
- カスタム音声モデルのトレーニングに使用する既存のトランスクリプトを収集します。
- トランスクリプトが WebVTT または SRT 形式の場合は、トランスクリプトのテキスト部分のみが含まれるようにファイルをクリーンアップします。
- 句読点を削除し、繰り返された単語を分離し、大きな数値をスペル アウトすることで、テキストを正規化します。 複数のクリーンアップされたトランスクリプトを 1 つに結合して、1 つのデータセットを作成できます。 同様に、テスト用のデータセットを作成します。
- データセットの準備ができたら、Speech Studio を使用してデータセットをアップロードします。 または、データセットが BLOB ストア内にある場合は、Azure Speech-to-text API と Speech CLI を使用できます。 この API と CLI では、データセットの URI を入力として渡して、モデルのトレーニングおよびテスト用のデータセットを作成できます。
- Speech Studio で、またはこの API または CLI を介して、新しいデータセットを使用してカスタム音声モデルをトレーニングします。
- 新しくトレーニングされたモデルをテスト データセットに対して評価します。
- カスタム モデルのパフォーマンスが期待される品質を満たしている場合は、音声文字起こしで使用するために公開します。 それ以外の場合は、Speech Studio を使用してワード エラー率 (WER) と特定のエラーの詳細を確認し、トレーニングに必要な追加データを決定します。
- API と CLI を使用して、モデルの構築、評価、デプロイのプロセスを運用化するのに役立てます。
コンポーネント
- Azure Machine Learning は、エンドツーエンドの機械学習ライフサイクルに向けた、エンタープライズ グレードのサービスです。
- Azure AI サービス は、よりインテリジェントで魅力的、かつ発見可能性を高めたアプリケーションを開発するのに役立つ、Microsoft Azure で使用できる API、SDK、サービスをセットにしたものです。
- Speech Studio は、アプリケーションで Azure AI 音声の機能を構築および統合するための UI ベースのツールのセットです。 ここでは、それはデータセットをトレーニングするための代替手段の 1 つです。 トレーニング結果の確認にも使用されます。
- Speech to text REST API は、独自データのアップロード、カスタム モデルのテストとトレーニング、モデル間の正確性の比較、カスタム エンドポイントへのモデルのデプロイを行うために使用できる API です。 これを使用して、モデルの作成、評価、デプロイを運用化することもできます。
- Speech CLI は、コードを記述せずに Speech サービスを使用するためのコマンドライン ツールです。 これは、データセットを作成およびトレーニングしたり、プロセスを運用化したりするための別の代替手段になります。
シナリオの詳細
この記事は、次の架空のシナリオに基づいています。
Contoso, Ltd. は、オリンピック イベントの番組や実況放送を提供する放送メディア会社です。 Contoso は、放送契約の一環として、アクセシビリティとデータ マイニングのためにイベントの文字起こしを提供しています。
Contoso は、Azure Speech サービスを使用して、オリンピック イベントのライブ字幕と音声の文字起こしを提供することを考えています。 Contoso は、さまざまなアクセントで話す世界中の女性と男性の解説者を採用しています。 さらに、それぞれのスポーツには独特の用語があるため、文字起こしが困難になることがあります。 この記事では、このシナリオに対するアプリケーション開発プロセスについて説明します。正確なイベント文字起こしを提供する必要があるアプリケーションに字幕を提供します。
Contoso は、次の必須の前提条件コンポーネントを既に用意しました。
- 過去のオリンピック イベントで人間が作成したトランスクリプト。 さまざまなスポーツのさまざまな解説者による実況解説を表すトランスクリプト。
- Azure Cognitive Service のリソース。 これは、 Azure portal で作成することができます。
カスタムの音声ベースのアプリケーションを開発する
音声ベースのアプリケーションでは、Azure Speech SDK を使用して Azure Speech サービスに接続し、テキスト ベースの音声文字起こしを生成します。 音声サービスでは、 さまざまな言語 と 2 つの流暢性モード (会話とディクテーション) がサポートされています。 カスタムの音声ベースのアプリケーションを開発するには、通常、次の手順を完了する必要があります。
- Speech Studio、Azure Speech SDK、Speech CLI、または REST API を使用して、話された文と発話のトランスクリプトを生成します。
- 生成されたトランスクリプトと人間が作成したトランスクリプトを比較します。
- 特定の分野に固有の単語が正しく文字起こしされない場合は、その特定の分野のカスタム音声モデルを作成することを検討します。
- カスタム モデルを作成するためのさまざまなオプションを確認します。 1 つまたは多数のカスタム モデルがより適切に機能するかどうかを判別します。
- トレーニングおよびテストのデータを収集します。
- データが許容範囲内の形式であることを確認します。
- モデルをトレーニング、テスト、評価して、デプロイします。
- 文字起こしにカスタム モデルを使用します。
- モデルの構築、評価、デプロイのプロセスを運用化します。
これらの手順について詳しく見ていきましょう。
1. Speech Studio、Azure Speech SDK、Speech CLI、または REST API を使用して、話された文と発話のトランスクリプトを生成する
Azure Speech には、オーディオ ファイルから、またはマイク入力から直接トランスクリプトを生成するための SDK、 CLI インターフェイス、 REST API が用意されています。 コンテンツがオーディオ ファイルに入っている場合は、 サポートされている形式である必要があります。 このシナリオでは、Contoso は以前のイベントの記録 (オーディオとビデオ) を .avi ファイルで保有しています。 Contoso は、 FFmpeg などのツールを使用してビデオ ファイルからオーディオを抽出し、Azure Speech SDK でサポートされている形式 (.wav など) で保存することができます。
次のコードでは、標準の PCM オーディオ コーデック pcm_s16le を使用して、サンプリング レートが 8 キロヘルツ (Khz) の 1 つのチャネル (モノラル) でオーディオを抽出します。
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. 生成されたトランスクリプトと人間が作成したトランスクリプトを比較する
比較を実行するために、Contoso は複数のスポーツからの解説オーディオをサンプリングし、 Speech Studio を使用して、人間が作成したトランスクリプトと Azure 音声サービスによって書き起こされた結果を比較します。 人間が作成した Contoso のトランスクリプトは、WebVTT 形式です。 これらのトランスクリプトを使用するために、Contoso はそれらをクリーンアップし、タイムスタンプ情報なしでテキストを正規化した単純な .txt ファイルを生成します。
Speech Studio を使用してデータセットを作成および評価する方法については、「トレーニングおよびテストのデータセット」をご覧ください。
Speech Studio では、人間が作成したトランスクリプトと、比較のために選択したモデルから生成されたトランスクリプトを横に並べて比較できます。 次に示すように、テスト結果にはモデルの WER が含まれています。
| モデル | エラー率 | 挿入 | 代入 | 削除 |
|---|---|---|---|---|
| モデル 1: 20211030 | 14.69% | 6 (2.84%) | 22 (10.43%) | 3 (1.42%) |
| モデル 2: Olympics_Skiing_v6 | 6.16% | 3 (1.42%) | 8 (3.79%) | 2 (0.95%) |
WER の詳細については、「ワード エラー率を評価する」をご覧ください。
これらの結果に基づくと、データセットのカスタム モデル (Olympics_Skiing_v6) は基本モデル (20211030) よりも優れています。
挿入 と 削除 のレートに注目すると、オーディオ ファイルが比較的クリーンで、バックグラウンド ノイズが低いことを示しています。
3. 特定の分野に固有の単語が正しく文字起こしされない場合は、その特定の分野のカスタム音声モデルを作成することを検討する
前の表の結果によると、基本モデル モデル 1: 20211030 では、単語の約 10% が置き換えられています。 Speech Studio で詳細な比較機能を使用して、その分野に固有の間違えた単語を特定します。 次の表は、比較の 1 つのセクションを示しています。
| 人間が作成したトランスクリプト | モデル 1 | モデル 2 |
|---|---|---|
| 滑降のオリンピック チャンピオンを 1998 年までさかのぼるとドイツの偉大な katja seizinger が 94 年と 98 年です | 滑降のオリンピック チャンピオンを 1998 年までさかのぼるとドイツの偉大な catch a sizing are が 94 年と 98 年です | 滑降のオリンピック チャンピオンを 1998 年までさかのぼるとドイツの偉大な katja seizinger が 94 年と 98 年です |
| 彼女はオリンピックチャンピオン goggia から王座を奪いました | 彼女はオリンピック チャンピオン ジョージアから王座を奪いました | 彼女はオリンピック チャンピオン goggia から王座を奪いました |
モデル 1 は、アスリートの名前 "Katia Seizinger" や "Goggia" のような分野固有の単語を認識しません。ただし、カスタム モデルを、選手の名前や分野固有のその他の単語やフレーズを含むデータを使用してトレーニングすると、それらを学習して認識できます。
4. カスタム モデルを作成するためのさまざまなオプションを確認する。 1 つまたは多数のカスタム モデルがより適切に機能するかどうかを判別します
カスタム モデルを構築するさまざまな方法を試すことにより、Contoso は言語と発音のモデルをカスタマイズして使用することで正確性を向上できることを発見しました。 (このガイドの最初の記事をご覧ください)。Contoso は、カスタム モデルを構築するために音響 (元のオーディオ) データを含めた場合に少しの改善が見られることにも注目しました。 ただし、カスタム音響モデルの保守とトレーニングを行うだけの十分なメリットはありませんでした。
Contoso は、スポーツごとに個別のカスタム言語モデル (アルペン スキー用に 1 つのモデル、リュージュ用に 1 つのモデル、スノーボード用に 1 つのモデルなど) を作成すると、より良い認識結果が得られることを見いだしました。 また、言語モデルを補強するためにスポーツの種類に基づいて個別の音響モデルを作成する必要はないことも指摘しました。
5. トレーニングおよびテストのデータを収集する
「トレーニングおよびテストのデータセット」という記事で、カスタム モデルのトレーニングに必要なデータの収集について詳しく説明しています。 Contoso は、さまざまな解説者によるさまざまなオリンピック スポーツのトランスクリプトを収集し、言語モデル適応を使用して、スポーツの種類ごとに 1 つのモデルを構築しました。 ただし、すべてのカスタム モデルに 1 つの発音ファイル (スポーツごとに 1 つ) を使用しました。 テスト データとトレーニング データは別々に保持されるため、カスタム モデルを構築した後は、Contoso はトレーニング データセットにトランスクリプトが含まれていないイベント オーディオをモデル評価のために使用しました。
6. データが許容範囲内の形式であることを確認する
「トレーニングおよびテストのデータセット」で説明されているように、カスタム モデルの作成やモデルのテストに使用されるデータセットは、特定の形式である必要があります。 Contoso のデータは WebVTT ファイルに入っています。 Contoso は、言語モデル適応のための正規化されたテキストを含むテキスト ファイルを生成するために簡単なツールをいくつか作成しました。
7. モデルをトレーニング、テスト、評価して、デプロイする
トレーニングしたモデルをさらにテストおよび評価するために、新しいイベント記録が使用されます。 モデルを微調整するには、テストと評価を 2、3 回繰り返すことが必要になる場合があります。 最後に、許容されるエラー率を持つトランスクリプトがモデルによって生成されるようになると、SDK から使用できるようにモデルがデプロイ (公開) されます。
8. 文字起こしにカスタム モデルを使用する
カスタム モデルをデプロイしたら、次の C# コードを使用して、SDK でそのモデルを文字起こしのために使用できます。
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
コードに関するメモ:
endpointは、手順 7 でデプロイされたカスタム モデルのエンドポイント ID です。subscriptionKeyとregionは、Azure AI サービスのサブスクリプション キーとリージョンです。 これらの値を Azure ポータル から取得するには、Azure AI サービス リソースが作成されたリソース グループに移動し、そのキーを確認します。
9. モデルの構築、評価、デプロイのプロセスを運用化する
カスタム モデルを発行した後は、定期的に評価し、新しいボキャブラリが追加された場合は更新する必要があります。 ビジネスの発展に応じて、より多くの分野をカバーするために、より多くのカスタム モデルが必要になる場合があります。 Azure Speech チームは、より多くのデータでトレーニングした新しい基本モデルを、使用可能になり次第リリースします。 自動化は、これらの変更についていくのに役立ちます。 この記事の次のセクションでは、上記の手順の自動化について詳しく説明します。
このシナリオのデプロイ
スクリプトを使用して、トレーニングとテスト用のデータセットの作成、モデルの構築と評価、必要に応じて新しいモデルを発行するプロセス全体を合理化および自動化する方法については、 GitHub の Custom-speech-STTを参照してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Pratyush Mishra |プリンシパル エンジニアリング マネージャー
その他の共同作成者:
- Mick Alberts | テクニカル ライター
- Rania Bayoumy | シニア テクニカル プログラム マネージャー
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
- Custom Speech とは
- テキスト読み上げの概要
- Custom Speech モデルをトレーニングする
- カスタム音声テキスト変換を実装する
- GitHub の Azure/custom-speech-STT