多くの大規模なソリューションでは、個別に管理およびアクセスできる複数の "パーティション" にデータが分割されています。 パーティション分割により、スケーラビリティの向上、競合の低減、パフォーマンスの最適化を実現できます。 また、使用パターンに基づいてデータを分割するメカニズムも提供できます。 たとえば、古いデータを廉価なデータ ストレージにアーカイブできます。
ただし、悪影響を最小限に抑え、メリットを最大限に活かすには、パーティション分割戦略を慎重に選択する必要があります。
注意
この記事で使用されている パーティション分割 という用語は、データを異なるデータ ストアに物理的に分割するプロセスを指します。 これは SQL Server テーブルのパーティション分割とは異なります。
データをパーティション分割する理由
拡張性の向上。 単一のデータベース システムをスケールアップすると、最終的には物理的なハードウェア限界に到達します。 データを複数のパーティションに分割し、各パーティションを個別のサーバー上でホストすると、システムをほぼ無制限にスケールアウトできます。
パフォーマンスの向上。 各パーティションでのデータ アクセス操作は、より少量のデータに対して実行されます。 パーティション分割を適切に行うことで、システムの効率を高めることができます。 複数のパーティションに影響する操作は、並列に実行できます。
セキュリティの向上。 場合によっては、機密データとそれ以外のデータを異なるパーティションに分け、機密データにさまざまなセキュリティ制御を適用できます。
運用上の柔軟性の向上。 パーティション分割は、運用の微調整、管理効率の最大化、およびコストの最小化を達成するための多くの機会を提供します。 たとえば、各パーティションのデータの重要性に基づいて、管理、監視、バックアップと復元、および他の管理タスクについて、異なる戦略を定義することができます。
データ ストアと使用パターンの一致。 パーティション分割では、コストとデータ ストアが提供する組み込み機能に基づいて、各パーティションを異なるタイプのデータ ストアにデプロイできます。 たとえば、大量のバイナリ データを Blob Storage に格納し、構造化されたデータをドキュメント データベースに保持することができます。 「適切なデータ ストアの選択」をご覧ください。
可用性の向上。 データを複数のサーバーにまたがって分割することで、単一障害点を避けることができます。 1 つのインスタンスで障害が発生した場合、使用できなくなるのは、そのパーティションのデータだけです。 その他のパーティションでの操作は、続行できます。 マネージドのサービスとしてのプラットフォーム (PaaS) データ ストアの場合、この考慮事項はあまり関係がありません。これらのサービスでは、設計に冗長性が組み込まれているためです。
パーティションの設計
データをパーティション分割する際の一般的な 3 つの戦略を次に示します。
水平的パーティション分割 (しばしば "シャーディング" と呼ばれます)。 この戦略では、各パーティションは個別のデータ ストアですが、すべてのパーティションが同じスキーマを持ちます。 各パーティションは "シャード" と呼ばれ、データの特定のサブセット (特定の顧客セットのすべての注文など) を保持します。
列方向のパーティション分割。 この戦略では、各パーティションはデータ ストアに含まれる項目のフィールドのサブセットを含みます。 フィールドは、それらの使用パターンに従って分割されます。 たとえば、頻繁にアクセスされるフィールドを 1 つの垂直的パーティションに、使用頻度の少ないフィールドをまとめて別の垂直的パーティションに配置します。
機能的パーティション分割。 この戦略では、システム内の区分可能な各コンテキストによって使用される方法に従って、データは集約されます。 たとえば、e コマース システムでは、請求書データと製品在庫データを、それぞれ異なるパーティションに格納できます。
これらの戦略は組み合わせることができます。パーティション分割構成を設計するときには、これらをすべて検討することをお勧めします。 たとえば、データをシャードに分割し、次に垂直的パーティション分割を使用して、各シャード内のデータをさら分割することができます。
水平的パーティション分割 (シャーディング)
図 1 は、水平的パーティション分割 (シャーディング) を示しています。 この例では、製品在庫データが製品キーに基づいてシャードに分割されます。 各シャードは、シャード キーの連続する範囲 (A ~ G および H ~ Z) のデータを保持し、アルファベット順に編成されます。 シャーディングによって、より多くのコンピューターに負荷を分散することで、競合が減り、パフォーマンスが向上します。
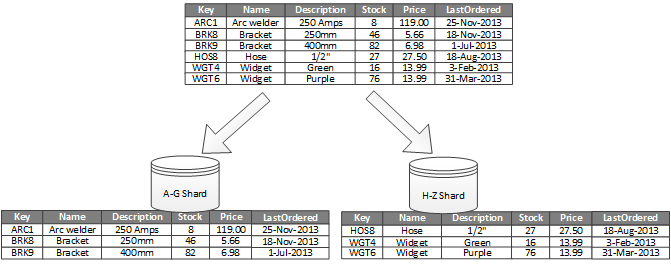
図 1 - パーティション キーに基づく水平的パーティション分割 (シャーディング) データ。
最も重要な要素は、シャーディング キーの選択です。 システムが運用状態に移行した後にキーを変更することは、非常に困難になる可能性があります。 キーは、ワークロードをシャード間でできるだけ均等に分散するようにデータがパーティション分割されるものである必要があります。
シャードは同じサイズである必要はありません。 要求の数のバランスを取ることの方が重要です。 シャードのサイズが非常に大きくても、各項目へのアクセス操作が少ないものや、 項目数は少なくても各項目へのアクセスは非常に頻繁に発生するものがあります。 また、1 つのシャードが (容量と処理リソースの観点で) データ ストアのスケールの上限を超えないようにすることも重要です。
パフォーマンスと可用性に影響する可能性のある "ホット" パーティションが発生しないようにします。 たとえば、顧客名の最初の文字を使用すると、分散が不均等になります。他の文字よりもよく使用される文字があるためです。 代わりに、顧客識別子のハッシュを使用して、パーティション間でデータをより均等に分散させます。
大きなシャードの分割、小さなシャードの結合による大きなパーティションの構築、スキーマの変更などの将来の要件を最小限にするシャーディング キーを選択します。 これらの操作は非常に時間がかかる可能性があり、実行時に 1 つ以上のシャードをオフラインにすることが必要になる場合があります。
シャードをレプリケートすると、他のシャードの分割、マージ、または再構成を行うときに、一部のレプリカをオンラインにしておくことができる場合があります。 ただし、システムでは、再構成中に実行できる操作を制限する必要があります。 たとえば、レプリカのデータを読み取り専用としてマークしてデータの不整合を防ぎます。
行方向のパーティション分割の詳細については、「シャーディング パターン」を参照してください。
垂直的パーティション分割
垂直的パーティション分割を使用する最も一般的な目的は、頻繁にアクセスされる項目の取り込みに関連する I/O とパフォーマンスのコストを削減することです。 図 2 は、垂直的パーティション分割の例です。 この例では、項目のさまざまなプロパティが異なるパーティションに格納されています。 一方のパーティションには、製品の名前、説明、価格など、アクセス頻度の高いデータが保持されています。 もう 1 つのパーティションには、在庫データ (在庫数と最終注文日) が保持されています。
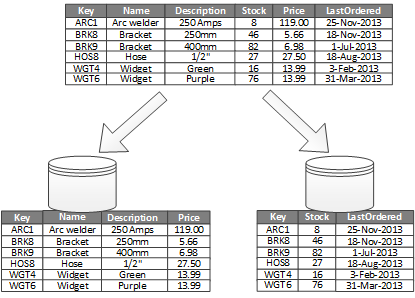
図 2 - 使用パターンによるデータの垂直的パーティション分割。
この例では、アプリケーションは、製品の詳細を顧客に表示する際は常に、製品の名前、説明、および価格をクエリします。 通常、在庫数と最終注文日の 2 つの項目は一緒に使用されるので、別のパーティションに保持されています。
垂直的パーティション分割のその他の利点は次のとおりです。
変動が比較的少ないデータ (製品の名前、説明、価格) を、より動的なデータ (在庫レベルと最終注文日) から分離できます。 変動の少ないデータは、アプリケーションがメモリにキャッシュするのに適しています。
機密データは、セキュリティ制御が強化された別のパーティションに格納できます。
垂直的パーティション分割では、必要な同時アクセスの数を減らすことができます。
垂直的パーティション分割は、データ ストア内のエンティティ レベルで動作します。エンティティを部分的に正規化して、"多数の" 項目で構成されるエンティティを "少数の" 項目で構成される複数のエンティティに分割します。 垂直的パーティション分割は、HBase や Cassandra など、列指向のデータ ストアに理想的に適しています。 変化する可能性が低い列コレクションのデータの場合は、SQL Server の列ストアを使用することも検討してください。
機能的パーティション分割
アプリケーションで各ビジネス 領域の区分のあるコンテキストを識別できる場合は、機能的パーティション分割によって、分離性とデータ アクセスのパフォーマンスを向上させることができます。 機能的パーティション分割のもう 1 つの一般的な用途は、読み書き可能なデータを読み取り専用データから分離することです。 図 3 は、機能的パーティション分割の概要を示しており、在庫データが顧客データから分離されています。
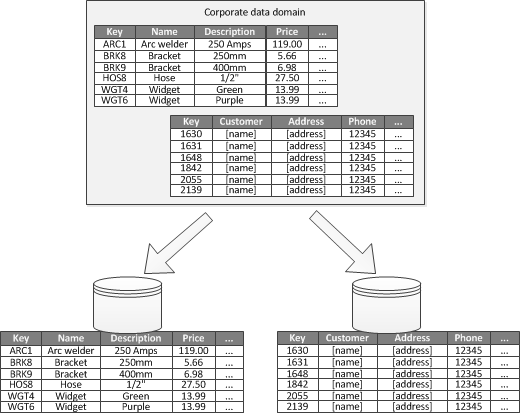
図 3 - 区分のあるコンテキストまたはサブドメインによりデータが分割された機能的パーティション分割。
このパーティション分割戦略は、システムのさまざまな部分にまたがるデータ アクセスの競合を少なくするのに役立ちます。
拡張性の観点でのパーティション分割の設計
各パーティションのサイズとワークロードを考慮して、それらを均等に分散することにより、最大の拡張性を達成することが重要です。 ただし、データのパーティションが単一のパーティション ストアの拡張制限を超えないようにすることも必要です。
拡張性の観点でパーティション分割を設計する際には、次の手順に従います。
- アプリケーションを分析して、各クエリで返される結果セットのサイズ、アクセス頻度、固有の遅延時間、サーバー側のコンピューティング処理要件など、データ アクセス パターンを理解します。 多くの場合、少数の主要なエンティティが最大の処理リソースを要求します。
- この分析を使用して、データ サイズやワークロードなどの現在および将来の拡張性目標を決定します。 そして、拡張性目標を満たすようにパーティション全体にデータを分散します。 水平的パーティション分割では、均等に分散するために適切なシャード キーを選択することが重要となります。 詳細については、「シャーディング パターン」を参照してください。
- データ サイズとスループットの観点から、スケーラビリティの要件に対処できる十分なリソースが各パーティションにあることを確認します。 データ ストアによっては、パーティションあたりのストレージ領域、処理能力、またはネットワーク帯域幅が制限されていることがあります。 要件がこれらの制限を超える可能性がある場合は、パーティション分割戦略を再調整するか、データをさらに分割することが必要になったり、複数の戦略を組み合わせることが必要になる場合があります。
- システムを監視して、データが想定どおりに分散されており、各パーティションで負荷が処理されていることを確認します。 実際の使用状況は、分析で予測されたものと必ずしも一致するとは限りません。 その場合、パーティションを再調整できます。また、必要なバランスを取るために、システムの一部を再設計することも可能です。
クラウド環境によっては、インフラストラクチャ境界の観点でリソースが割り当てられます。 選択した境界の制限が、データ ストレージ、処理能力、および帯域幅の観点で、データ量の想定される成長を収容できることを確認する必要があります。
たとえば、Azure Table Storage を使用する場合、一定期間内に単一パーティションで処理できる要求の量に制限があります (詳細については、「Azure Storage のスケーラビリティとパフォーマンスのターゲット」を参照してください)。ビジー状態のシャードでは、1 つのパーティションで処理できるよりも多くのリソースが必要になる場合があります。 その場合、負荷を分散するために、シャードを再パーティション分割する必要があります。 これらのテーブルの合計サイズまたはスループットがストレージ アカウントの容量を超える場合は、追加のストレージ アカウントを作成して、それらのアカウントにテーブルを分散する必要があります。
クエリ パフォーマンスの観点でのパーティション分割の設計
クエリのパフォーマンスは、多くの場合、小さなデータ セットを使用し、並列クエリを実行することで、格段に向上できます。 各パーティションには、データ セット全体の小さな割合を収容する必要があります。 そうすると、容量が小さくなるので、クエリのパフォーマンスが向上します。 ただし、パーティション分割は、データベースを適切に設計および構成することの代替にはなりません。 たとえば、必要なインデックスが構成されていることを確認します。
クエリ パフォーマンスの観点でパーティション分割を設計する際には、次の手順に従います。
アプリケーションの要件とパフォーマンスを検証します。
- ビジネス要件を使用して、常に高速で実行する必要のある重要なクエリを決定します。
- システムを監視して、低速で実行するクエリを識別します。
- 最も頻繁に実行されるクエリを見つけます。 単一のクエリのコストが最小限であっても、累積されたリソース消費量が多大になる可能性があります。
パフォーマンスの低下を引き起こしているデータをパーティション分割します。
- クエリの応答時間がターゲット時間内になるように各パーティションのサイズを制限します。
- 水平的パーティション分割を使用する場合は、アプリケーションが適切なパーティションを簡単に選択できるようにシャード キーを設計します。 これにより、クエリがすべてのパーティションを通してスキャンする必要がなくなります。
- パーティションの場所を検討してください。 可能な限り、パーティションのデータを、それにアクセスするアプリケーションやユーザーに地理的に近い場所に維持します。
エンティティにスループットとクエリ パフォーマンスの要件がある場合、そのエンティティに基づく機能的パーティション分割を使用します。 それでも要件が満たされない場合は、水平的パーティション分割も適用します。 ほとんどの場合、単一のパーティション分割戦略で十分ですが、両方の戦略を組み合わせて使用することが効果的な場合があります。
パフォーマンスを向上させるために、複数のパーティションでクエリを並列実行することを検討します。
可用性の観点でのパーティション分割の設計
データをパーティション分割すると、データセット全体が単一障害点となることはなく、またデータセットの個々のサブセットを個別に管理できるので、アプリケーションの可用性が向上します。
可用性に影響する次の要素を考慮してください。
業務に対するデータの重要度。 重要なビジネス情報であるデータ (トランザクションなど) と、重要度の低い運用データ (ログ ファイルなど) を特定します。
適切なバックアップ計画を使用して、重要なデータを可用性の高いパーティションに格納することを検討します。
データセットごとに個別の管理および監視手順を確立します。
同じレベルの重要度を持つデータを同じパーティションに配置して、適切な頻度で一緒にバックアップできるようにします。 たとえば、トランザクション データを保持するパーティションは、ログ情報やトレース情報を保持するパーティションよりも頻繁にバックアップする必要があります。
個々のパーティションを管理する方法。 個別に管理および保守ができるようにパーティションを設計すると、いくつかのメリットが生じます。 次に例を示します。
1 つのパーティションで障害が発生した場合、他のパーティションのデータにアクセスするアプリケーションに影響を及ぼすことなく、そのパーティションを個別に復旧できます。
地理的な場所に基づいてデータをパーティション分割すると、各場所のオフピーク時間に保守タスクが実行されるようにスケジュールできます。 計画された保守タスクがこの期間内に完了するように、パーティションのサイズが大きすぎないことを確認します。
機密データをパーティション全体でレプリケートすることの必要性。 この戦略では、可用性とパフォーマンスを向上させることができますが、整合性の問題が発生することもあります。 変更をすべてのレプリカと同期するには時間がかかります。 この期間は、さまざまなパーティションが異なるデータ値を持つ可能性があります。
アプリケーション設計に関する考慮事項
パーティション分割を使用すると、システムの設計と開発の複雑さが増大します。 初期においてシステムが単一のパーティションのみを含んでいる場合でも、パーティション分割をシステム設計の基盤として考慮する必要があります。 後からの思い付きでパーティション分割に対処しようとすると、維持する必要があるライブ システムが既に存在するので難しくなります。
- データ アクセス ロジックを変更する必要があります。
- 既存の大量のデータを複数のパーティションに分散するために、それらのデータを移行することが必要になる場合があります。
- ユーザーは、移行中もシステムを引き続き使用できることを求めています。
場合によっては、初期のデータ セットが小さく、単一サーバーで容易に処理できるので、パーティション分割は重要ではないと見なされます。 これは一部のワークロードには当てはまるかもしれませんが、多くの商用システムはユーザー数の増加に伴って拡張する必要があります。
さらに、パーティション分割によってメリットがもたらされるのは大規模なデータ ストアだけではありません。 たとえば、小さなデータ ストアが数百の同時クライアントによって過度にアクセスされることがあります。 このような状況でデータをパーティション分割すると、競合を少なくし、スループットを向上させることができます。
データパーティション分割構成を設計する際には、次の点を考慮する必要があります。
パーティションをまたがるデータ アクセス操作を最小限に抑える: 可能であれば、パーティションごとに、最も一般的なデータベース操作の対象となるデータをまとめ、パーティションをまたがるデータ アクセス操作を最小限に抑えます。 パーティションをまたがるクエリは、単一パーティション内でのクエリよりも時間がかかる可能性がありますが、あるクエリ セットにパーティションを最適化すると、他のクエリ セットが悪影響を受けることがあります。 パーティションをまたがるクエリを実行する必要がある場合は、並列クエリを実行し、アプリケーション内で結果を集計することによって、クエリ時間を最小限に抑えます (クエリの結果を次のクエリで使用する場合など、この方法を使用できない場合もあります)。
静的参照データのレプリケーションを検討する: クエリで比較的静的な参照データ (郵便番号テーブルや製品リストなど) を使用する場合は、すべてのパーティションでこのデータをレプリケートして、パーティションごとの個別の検索操作を減らすことを検討します。 この方法を使用すると、システム全体からの大量のトラフィックによって、参照データが "ホット" データセットになる可能性を低減することもできます。 ただし、参照データに対する変更の同期に関連する追加コストが発生します。
パーティション間結合を最小限に抑える: 可能であれば、垂直的パーティション間および機能的パーティション間での参照整合性の要件を最小限に抑えます。 これらの構成では、アプリケーションが、パーティション間での参照整合性を維持する役割を担います。 複数のパーティション間でデータを結合するクエリは非効率的です。通常、アプリケーションがキーに基づいてクエリを実行し、続いて外部キーに基づいてクエリを実行する必要があるためです。 このような状況では、パーティション分割の代わりに、関連するデータのレプリケートまたは非正規化を検討します。 パーティション間結合が必要な場合は、パーティションに対して並列クエリを実行し、アプリケーション内でデータを結合します。
最終的な整合性の受容。 強力な整合性が実際に要件であるかどうかを評価します。 分散システムでの一般的な方法として、最終的な整合性を実装します。 各パーティションのデータは個別に更新され、アプリケーションのロジックはすべての更新が正常に完了したことを確認します。 また、結果整合性の操作が実行している間、データをクエリすることにより発生する可能性のある不整合を処理することができます。
クエリが正しいパーティションを見つける方法を考慮します。 必要なデータを見つけるためにクエリがすべてのパーティションをスキャンする必要がある場合、複数の並列クエリが実行中である場合でも、パフォーマンスに非常に大きな影響を及ぼします。 垂直的パーティション分割と機能的パーティション分割では、クエリでパーティションを自然に指定できます。 一方、水平的パーティション分割では、すべてのシャードが同じスキーマを持つので、項目を見つけることが困難になる可能性があります。 一般的な解決策は、特定の項目のシャードの場所を検索する際に使用するマップを維持することです。 このマップは、アプリケーションのシャーディング ロジックに実装することも、データ ストアが透過的シャーディングをサポートする場合にはデータ ストアにより維持されるようにすることもできます。
シャードを定期的に再調整することを検討する: 水平的パーティション分割では、シャードの再調整により、サイズとワークロードに基づいてデータを均等に分散することで、ホットスポットを最小限に抑え、クエリ パフォーマンスを最大化し、ストレージの物理的な制限に対処できます。 ただし、これは複雑なタスクで、多くの場合、カスタム ツールまたはカスタム プロセスの使用が必要になります。
パーティションをレプリケートする: 各パーティションをレプリケートすると、障害からの保護を強化できます。 単一のレプリカで障害が発生しても、動作しているコピーにクエリを振り向けることができます。
パーティション分割戦略の物理制限に到達した場合、拡張性を別のレベルに拡張することが必要な場合があります。 たとえば、パーティション分割がデータベース レベルで行われる場合、パーティションを複数のデータベースで配置したりレプリケートしたりすることが必要になる場合があります。 パーティション分割が既にデータベース レベルで行われており、物理制限が問題になっている場合、パーティションを複数のホスティング アカウントで配置したりレプリケートしたりすることが必要な可能性があります。
トランザクションでは、複数のパーティションのデータにアクセスしないようにします。 一部のデータ ストアには、データを変更する操作に対してトランザクション レベルの一貫性と整合性を保つ機能を実装していますが、これが有効になるのは、データが単一のパーティションに配置されている場合だけです。 複数のパーティションにまたがってトランザクション レベルのサポートを必要とする場合、ほとんどのパーティション分割システムでこの機能はネイティブにサポートされていないので、アプリケーション ロジックの一部として実装することが必要になる可能性があります。
すべてのデータ ストアで運用の管理および監視のアクティビティが必要です。 これらのタスクには、データのロード、データのバックアップおよび復元、データの再編成、システムが正しく効率よく動作していることの確認などがあります。
運用管理に影響する次の要因を考慮してください。
データをパーティション分割するとき、適切な管理と運用のタスクを実装する方法。 バックアップと復元、データのアーカイブ、システムの監視、その他の管理タスクなどです。 たとえば、バックアップと復元の操作では論理的な一貫性を維持することが課題になります。
データを複数のパーティションにロードする方法と、他のソースから到着する新しいデータを追加する方法。 一部のツールおよびユーティリティでは、データを正しいパーティションにロードするなど、シャード化されているデータの操作がサポートされていないことがあります。
定期的にデータをアーカイブして削除する方法。 パーティションの過度な成長を防止するために、定期的に (月単位など) データをアーカイブして削除する必要があります。 異なるアーカイブ スキーマに一致するように、データを変換することが必要な場合があります。
データ整合性の問題を見つける方法。 あるパーティションのデータが別のパーティションの存在しない情報を参照しているなど、データ整合性の問題を見つけるプロセスを定期的に実行することを検討します。 このプロセスでは、これらの問題の自動修正を試みるか、手動でのレビュー用にレポートを生成できます。
パーティションの再調整
システムが成熟するにつれて、パーティション分割構成を調整することが必要になる場合があります。 たとえば、パーティション間でトラフィック量に不均衡が生じ始め、特定のパーティションがホットスポットになり、過度の競合が発生することがあります。 また、一部のパーティションでデータ量が過少に見積もられており、これらのパーティションが容量の上限に近づいていることもあります。
Azure Cosmos DB などの一部のデータ ストアでは、パーティションを自動的に再調整できます。 それ以外の場合、再調整は次の 2 段階で構成される管理タスクとなります。
新しいパーティション分割戦略を決定します。
- どのパーティションを分割する (場合によっては結合する) 必要があるか。
- 新しいパーティション キーは何か。
データを古いパーティション分割構成から新しいパーティション セットに移行します。
データ ストアによっては、パーティションの使用中にパーティション間でデータを移行できる場合もあります。 これは "オンライン移行" と呼ばれます。 これが不可能な場合は、データを再配置する間、パーティションを使用できないようにする必要があります ("オフライン移行")。
オフライン移行
通常はオフライン移行の方が、競合が発生する可能性が低減されるので簡単です。 概念的には、オフライン移行は次のように動作します。
- パーティションをオフラインにします。
- データを分割/マージし、新しいパーティションに移動します。
- データを検証します。
- 新しいパーティションをオンラインにします。
- 古いパーティションを削除します。
必要に応じて、手順 1. でパーティションを読み取り専用としてマークすることもできます。これにより、アプリケーションはデータの移動中も、データを読み取ることができます。
オンライン移行
オンライン移行は実行が複雑になりますが、中断は少なくなります。 プロセスはオフライン移行と似ていますが、元のパーティションがオフラインになることはありません。 移行プロセスの粒度 (たとえば、項目単位か、シャード単位か) に応じて、クライアント アプリケーションのデータ アクセス コードでは、2 つの場所 (元のパーティションと新しいパーティション) に保持されるデータの読み書きを処理することが必要になる場合があります。
次のステップ
- 特定の Azure サービスのパーティション分割戦略の詳細を確認します。 「データのパーティション分割戦略」をご覧ください。
- Azure Storage のスケーラビリティおよびパフォーマンスのターゲット
関連リソース
次の設計パターンがシナリオに関連することがあります。
シャーディング パターンは、データのシャーディングのための一般的な戦略を示します。
インデックス テーブル パターンは、データに対してセカンダリ インデックスを作成する方法を示します。 この手法を使用すると、アプリケーションは、コレクションのプライマリ キーを参照しないクエリで、データをすばやく取得できます。
具体化されたビュー パターンは、データを要約して高速のクエリ操作をサポートする、事前設定されたビューを生成する方法を示します。 この手法は、要約対象のデータを含むパーティションが複数のサイトにまたがって分散されている場合に、パーティション分割されたデータ ストアで役立つ可能性があります。