ビッグ データ アーキテクチャは、従来のデータベース システムには多すぎる、または複雑すぎるデータのインジェスト、処理、分析を扱うために設計されています。 組織がビッグ データ領域に入るしきい値は、ユーザーとそのツールの機能によって変わります。 数百 GB のデータを意味する場合もあれば、数百 TB のデータを意味する場合もあります。 ビッグ データ セットを使用するためのツールが進歩するにつれて、ビッグ データの意味も進歩します。 この用語は、厳密にはデータのサイズではなく、高度な分析を介してデータ セットから抽出できる値に関連していますが、このような場合、データはかなり大きくなる傾向にあります。
長年にわたって、データのランドスケープは変化してきました。 データで実行できること、実行できると期待されることは変化しています。 ストレージのコストは大幅に下がりましたが、データを収集する手段は増え続けています。 一部のデータは速いペースで到達しますが、常に収集し、観察する必要があります。 他のデータはより遅く到達しますが、非常に大きなチャンクであり、多くの場合、何十年もの履歴データの形式です。 高度な分析の問題や、機械学習が必要な問題に直面する場合があります。 これらは、ビッグ データ アーキテクチャで解決方法を探る課題です。
ビッグ データ ソリューションには、通常は、次の種類のワークロードが 1 つ以上関係しています。
- 保存されているビッグ データ ソースのバッチ処理。
- 動作中のビッグ データのリアルタイム処理。
- ビッグ データの対話型探索。
- 予測分析と機械学習。
以下が必要になった場合に、ビッグ データ アーキテクチャを検討してください。
- 従来のデータベースには多すぎる、大量のデータを保存および処理する。
- 分析とレポートのために非構造化データを変換する。
- リアルタイムで、または短い待機時間で、バインドされていないデータ ストリームを取得、処理、分析する。
ビッグ データ アーキテクチャのコンポーネント
次のダイアグラムは、ビッグ データ アーキテクチャに適している論理コンポーネントを示しています。 個々のソリューションには、このダイアグラムのすべての項目が含まれているわけではありません。
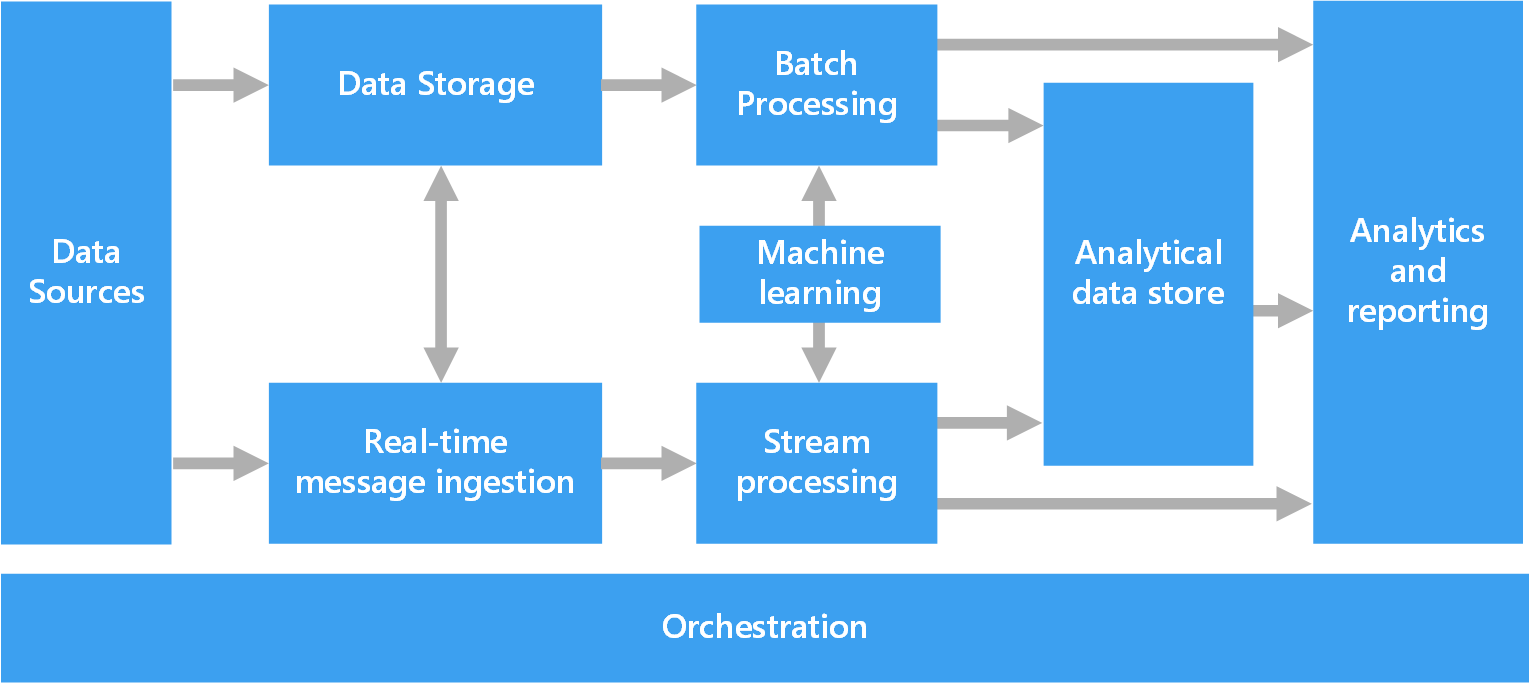
大部分のビッグ データ アーキテクチャには、次のコンポーネントの一部またはすべてが含まれています。
データ ソース。 すべてのビッグ データ ソリューションは、1 つ以上のデータ ソースから始まります。 たとえば、次のようになります。
- リレーショナル データベースなど、アプリケーション データ ストア。
- Web サーバー ログ ファイルなど、アプリケーションによって生成された静的ファイル。
- IoT デバイスなど、リアルタイムのデータ ソース。
データ ストレージ。 バッチ処理操作のためのデータは、通常は、さまざまな形式の大きなファイルを大量に保持できる分散ファイル ストアに保存されます。 この種のストアは、Data Lake とも呼ばれます。 このストレージを実装するための選択肢としては、Azure Data Lake Store、または Azure Storage 内の BLOB コンテナーなどがあります。
バッチ処理。 データ セットは非常に大きいため、多くの場合、ビッグ データ ソリューションでは、実行時間の長いバッチ ジョブの使用によってデータ ファイルを処理し、フィルター処理や集計を行うなどして分析用のデータを準備する必要があります。 通常、これらのジョブには、ソース ファイルの読み取り、ソース ファイルの処理、新しいファイルへの出力の書き込みが含まれます。 選択肢には、Azure Data Lake Analytics での U-SQL ジョブの実行、HDInsight Hadoop クラスターでの Hive、Pig、またはカスタム Map/Reduce ジョブの使用、あるいは HDInsight Spark クラスターでの Java、Scala、または Python プログラムの使用などがあります。
リアルタイム メッセージ インジェスト。 ソリューションにリアルタイム ソースが含まれている場合は、アーキテクチャに、ストリーム処理のためにリアルタイム メッセージを取得して保存する方法が含まれている必要があります。 これは、受信メッセージを処理用のフォルダーにドロップするような、単純なデータ ストアにすることもできます。 ただし、多くのソリューションには、メッセージのためのバッファーとして機能し、スケールアウト処理、信頼性の高い配信、その他のメッセージ キューのセマンティクスをサポートするメッセージ インジェスト ストアが必要です。 ストリーミング アーキテクチャのこの部分は、ストリーム バッファリングとも呼ばれます。 オプションとして、Azure Event Hubs、Azure IoT Hub、Kafka などがあります。
ストリーム処理。 このソリューションでは、リアルタイム メッセージを取得した後、分析用にデータをフィルターしたり、集計したり、その他の準備を行ったりして、それらのメッセージを処理する必要があります。 処理されたストリーム データは、その後、出力シンクに書き込まれます。 Azure Stream Analytics では、バインドされていないストリームを操作する SQL クエリの絶え間ない実行に基づいて、管理されたストリーム処理サービスが提供されます。 HDInsight クラスターで、Spark Streaming など、オープン ソースの Apache ストリーミング テクノロジを使用することもできます。
機械学習。 (バッチ処理またはストリーム処理から) 分析用に準備されたデータを読み取ると、機械学習アルゴリズムを使用して、結果を予測したりデータを分類したりできるモデルを構築できます。 これらのモデルは大規模なデータセットでトレーニングさせることができ、得られたモデルを使用して新しいデータの分析や予測を行うことができます。 これは、Azure Machine Learning を使用して実現できます
分析データ ストア。 多くのビッグ データ ソリューションでは、分析用にデータが準備されてから、処理されたデータが提供されます。このデータは分析ツールを使用して照会可能な、構造化された形式になります。 これらのクエリの処理に使用する分析データ ストアは、従来のほとんどのビジネス インテリジェンス (BI) ソリューションに見られるように、Kimball スタイルのリレーショナル データ ウェアハウスにすることができます。 別の方法としては、HBase などの待機時間の短い NoSQL テクノロジや、分散データ ストア内のデータ ファイル上のメタデータ抽象化を提供する対話型 Hive データベースを通じて、データを利用できます。 Azure Synapse Analytics を使用すると、クラウドベースの大規模なデータ ウェアハウス向けの管理されたサービスが提供されます。 HDInsight では対話型の Hive、HBase、Spark SQL をサポートしており、これらを使用して分析用のデータを処理することもできます。
分析とレポート。 ほとんどのビッグ データ ソリューションの目的は、分析とレポートによってデータに関する実用的な情報を提供することにあります。 ユーザーによるデータ分析を支援するために、Azure Analysis Services での多次元 OLAP キューブまたは表形式データ モデルなどのデータ モデリング レイヤーをアーキテクチャに組み込むことができます。 Microsoft Power BI または Microsoft Excel 内のモデリング テクノロジおよび視覚化テクノロジを使用して、セルフサービス BI をサポートすることもできます。 分析とレポートは、データ サイエンティストやデータ アナリストによる対話型のデータ探索の形で行うこともできます。 これらのシナリオでは、多くの Azure サービスで Jupyter などの分析ノートブックがサポートされており、そのユーザーは Python や R に関する既存のスキルを活用できます。大規模なデータ探索の場合は、Microsoft R Server をスタンドアロンでも、Spark と組み合わせても使用できます。
オーケストレーション。 ほとんどのビッグ データ ソリューションはデータの反復処理操作で構成されており、ワークフロー内でカプセル化されています。この処理操作では、ソース データの変換や複数のソースとシンクとの間でのデータ移動、処理されたデータの分析データ ストアへの読み込み、レポートまたはダッシュボードへのダイレクトな結果のプッシュが行われます。 これらのワークフローを自動化するために、Azure Data Factory や Apache Oozie および Sqoop などのオーケストレーション テクノロジを使用できます。
ラムダ アーキテクチャ
非常に大規模なデータ セットを使用する場合、クライアントに必要な種類のクエリを実行するために時間がかかることがあります。 これらのクエリをリアルタイムで実行することはできません。また多くの場合、データ セット全体で並列に動作する MapReduce などのアルゴリズムが必要です。 結果は生データとは別に保存され、クエリに使用されます。
このアプローチの 1 つの欠点は待機時間が生じることです。処理に数時間かかると、クエリが数時間前の結果を返す可能性があります。 理想的には、リアルタイムでは一部の結果を取得し (精度がある程度低下する可能性があります)、これらの結果をバッチ分析の結果と組み合わせることをお勧めします。
Nathan Marz によって最初に提案されたラムダ アーキテクチャは、データ フロー用に 2 つのパスを作成することでこの問題に対処しています。 システムに送信されるすべてのデータは、次の 2 つのパスを経由します。
バッチ レイヤー (コールド パス) は、すべての受信データを未加工の形式で保存し、データに対してバッチ処理を実行します。 この処理の結果は、バッチ ビューとして保存されます。
速度レイヤー (ホット パス) では、リアルタイムでデータを分析します。 このレイヤーは、精度と引き換えに待機時間が短くなるように設計されています。
バッチ レイヤーは、効率的なクエリのためにバッチ ビューにインデックスを付けるサービス レイヤーにフィードされます。 速度レイヤーは、最新のデータに基づく増分更新でサービス レイヤーを更新します。
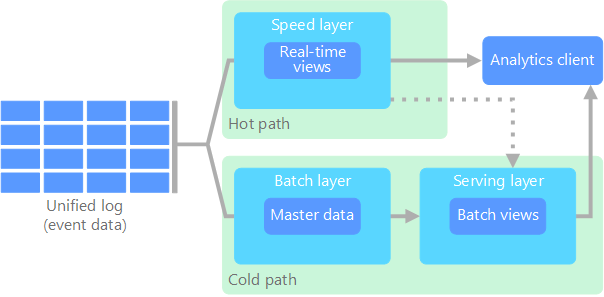
ホット パスに流入するデータは、速度レイヤーに課せられる待機時間の要件によって制約されるため、可能な限り短時間で処理できます。 多くの場合、できるだけ早く準備ができているデータが優先されるので、ある程度の精度のトレードオフが必要です。 たとえば、多数の温度センサーがテレメトリ データを送信している IoT シナリオを考えてみましょう。 速度レイヤーは、受信データのスライド時間枠を処理するために使用することができます。
一方、コールド パスに流入するデータは、同じ短い待機時間要件の対象ではありません。 そのため、大規模なデータ セット全体で高精度の計算が可能になりますが、非常に時間がかかることがあります。
最終的に、ホット パスとコールド パスは分析クライアント アプリケーションに収束します。 クライアントで、精度の低い可能性があるデータを適時にリアルタイムで表示する必要がある場合は、ホット パスから結果を取得します。 それ以外の場合は、コールド パスの結果を選択して、適時ではありませんが正確なデータを表示します。 言い換えると、ホット パスは、比較的短い時間枠のデータを持ちます。その後、コールド パスのより正確なデータで結果を更新することができます。
バッチ レイヤーに格納されている生データは不変です。 受信データは常に既存のデータに付加され、前のデータが上書きされることはありません。 特定のデータの値に対する変更は、新しいタイムスタンプのイベント レコードとして保存されます。 そのため、収集されたデータの履歴全体について、任意の時点で再計算できます。 システムが進化するにつれて新しいビューを作成できるようになるため、元の生データからバッチ ビューを再計算できることが重要です。
カッパ アーキテクチャ
ラムダ アーキテクチャの欠点は、その複雑さです。 処理ロジックは、異なるフレームワークを使用して 2 つの異なる場所 (コールド パスとホット パス) に出現します。 その結果、計算ロジックが重複し、両方のパスのアーキテクチャ管理が複雑になります。
カッパ アーキテクチャは、Jay Kreps によってラムダ アーキテクチャの代替として提案されました。 ラムダ アーキテクチャと基本的な目標は同じですが、ストリーム処理システムを使用して、すべてのデータが単一のパスを経由する、という重要な違いがあります。
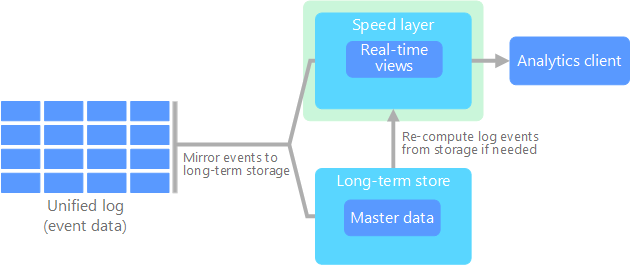
ラムダ アーキテクチャのバッチレイヤーにはいくつかの類似点があります。イベント データは不変であり、サブセットではなくすべてが収集されます。 データは、分散したフォールト トレラントな統一ログにイベントのストリームとして取り込まれます。 これらのイベントには順序が付けられ、イベントの現在の状態は、新しいイベントが追加されることでのみ変更されます。 ラムダ アーキテクチャの速度レイヤーと同様に、すべてのイベント処理は入力ストリームに対して実行され、リアルタイム ビューとして保持されます。
データ セット全体 (ラムダでのバッチ レイヤーの機能と同じ) を再計算する必要がある場合、通常は並列処理を使用してストリームを再生し、適時に計算を完了させるだけです。
モノのインターネット(IoT)
実用的な観点から言うと、モノのインターネット (IoT) はインターネットに接続された任意のデバイスを表します。 たとえば、PC、携帯電話、スマート ウォッチ、スマート サーモスタット、スマート冷蔵庫、接続されている自動車、心臓モニターのインプラント、インターネットに接続してデータを送受信するその他のものが含まれます。 接続されているデバイスの数が毎日増えるにつれて、そこから収集されるデータ量も増えます。 多くの場合、このデータは高度に制約された、時には待機時間の長い環境で収集されています。 他の場合には、短い待機時間環境から数千または数百万のデバイスによってデータが送信されるので、データを迅速に取り込み、それに応じて処理する能力が求められます。 そのため、このような制約と固有の要件を処理するには、適切な計画が必要です。
イベント ドリブン アーキテクチャは、IoT ソリューションにとって重要です。 次の図は、IoT で考えられる論理アーキテクチャを示しています。 この図では、アーキテクチャのイベント ストリーミング コンポーネントが強調されています。
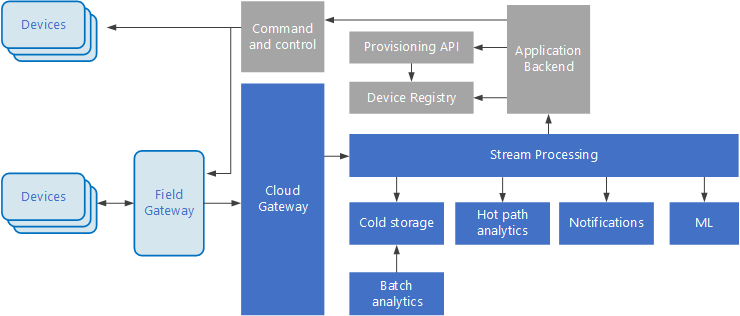
クラウド ゲートウェイが、信頼性の高い低待機時間のメッセージング システムを使用して、クラウドの境界でデバイスのイベントを取り込みます。
デバイスは、クラウド ゲートウェイに直接イベントを送信するか、フィールド ゲートウェイを介して送信します。 フィールド ゲートウェイは特殊なデバイスまたはソフトウェアで、通常はデバイスと共に配置され、イベントを受信してクラウド ゲートウェイに転送します。 フィールド ゲートウェイは、フィルター処理、集計、またはプロトコルの変換などの関数を実行する、ロウ デバイス イベントの前処理を行うこともあります。
取り込み後、イベントは 1 つ以上のストリーム プロセッサを経由します。それらのプロセッサは、データをルーティングしたり (ストレージへのルーティングなど)、分析やその他の処理を実行したりできます。
一般的な処理の種類を次に示します。 (このリストは全てを網羅しているわけではありません。)
アーカイブまたはバッチ分析のための、コールド ストレージへのイベント データの書き込み。
イベント ストリームを (ほぼ) リアルタイムで分析するホット パス分析で異常を検出し、ローリング時間枠でパターンを認識し、ストリームで特定の条件が発生した場合にアラートをトリガーする。
通知やアラームなど、デバイスからの特殊な非テレメトリ メッセージを処理。
機械学習。
網掛けのグレーのボックスに、IoT システムのコンポーネントが表示されています。これらのコンポーネントはイベント ストリーミングに直接関連はありませんが、ここでは完全を期すために盛り込んでいます。
デバイス レジストリはプロビジョニングされたデバイスのデータベースで、デバイス ID と、通常は位置情報などのデバイスのメタデータを含みます。
プロビジョニング API は新しいデバイスをプロビジョニングし登録するための一般的な外部インターフェイスです。
一部の IoT ソリューションでは、コマンドやコントロール メッセージをデバイスに送信できます。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Zoiner Tejada | CEO 兼アーキテクト
次のステップ
次の関連 Azure サービスを参照してください。