Team Data Science Process ライフサイクルのモデリング ステージ
この記事では、Team Data Science Process (TDSP) のモデリング ステージに関連付けられている目標、タスク、成果物のアウトラインを示します。 このプロセスは、チームがデータサイエンスプロジェクトを構築するために使用できる推奨ライフサイクルを提供します。 ライフサイクルは、チームが (多くの場合、反復的に) 実行する主要なステージの概要を示します。
- ビジネスの把握
- データの取得と理解
- モデリング
- デプロイ
- 顧客による受け入れ
TDSPライフサイクルの視覚的な表現を次に示します。
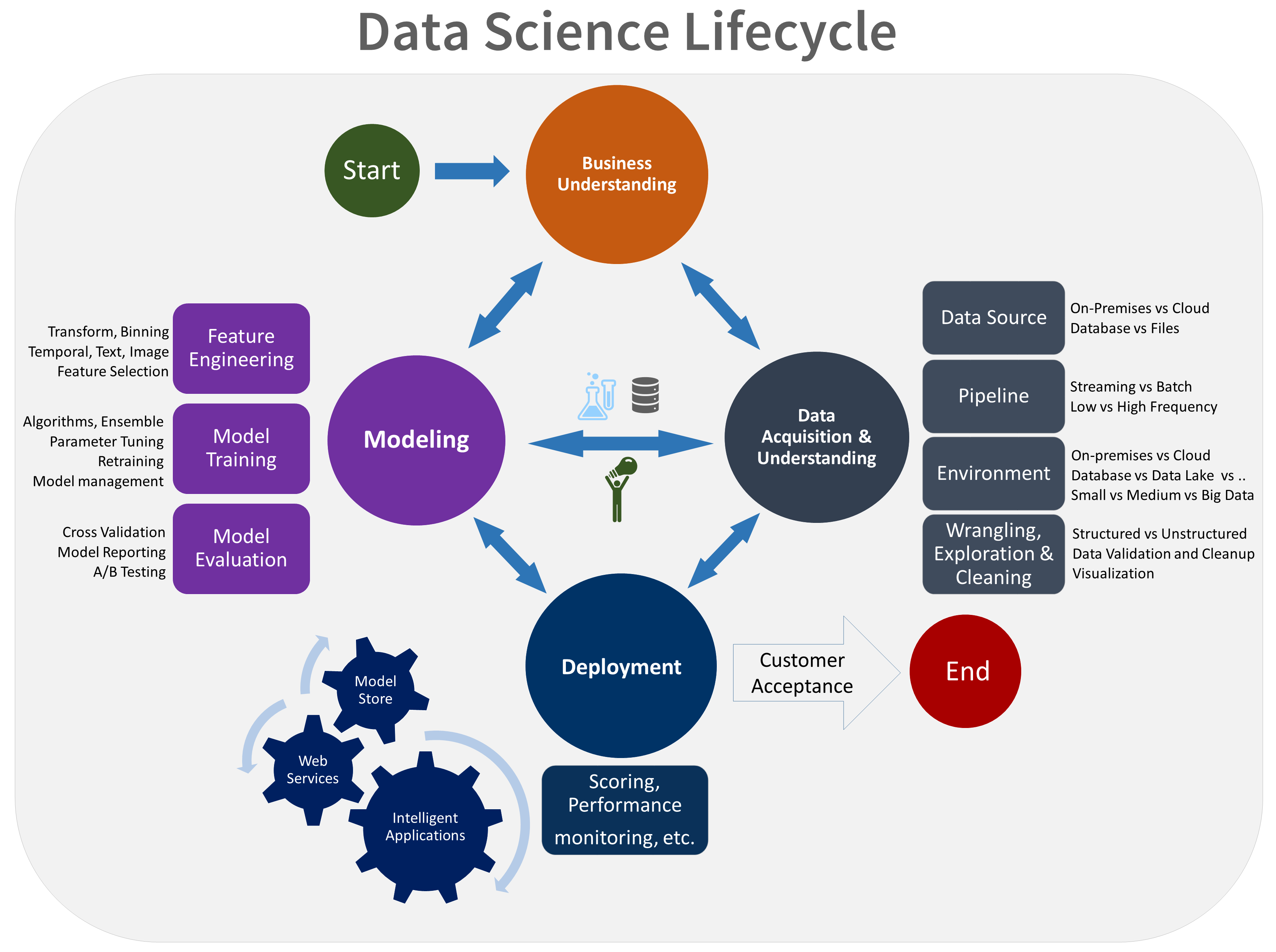
目標
モデリングステージの目標は次のとおりです。
機械学習モデルに最適なデータ特徴を決定します。
ターゲットを最も正確に予測する有益な機械学習モデルを作成します。
運用環境に適した機械学習モデルを作成します。
タスクを完了する方法
モデリングステージには、3つの主要なタスクがあります。
特徴エンジニアリング:モデルをトレーニングしやすくするために生データからデータの特徴を作成します。
モデルトレーニング: モデルの成功メトリックを比較して、質問に最も正確に答えるモデルを見つけます。
モデル評価: モデルが運用環境に適しているかどうかを判断します。
機能エンジニアリング
特徴エンジニアリングでは、分析に使用する特徴を作成するために、未加工の変数の追加、集計、変換を行います。 モデルの構築方法に関する洞察が必要な場合は、モデルの基になる特徴を調べる必要があります。
このステップでは、特定分野の専門知識とデータの調査ステップから得られた知見とを創造的に組み合わせる必要があります。 特徴エンジニアリングとは、情報を提供する変数を見つけて含めると同時に、関連のない変数が多すぎないようにすることです。 情報を提供する変数によって結果が向上します。 関連のない変数は、モデルに不要なノイズをもたらします。 また、これらの特徴は、スコア付け中に取得した新しいデータがあれば、そのデータに対して生成する必要もあります。 その結果、これらの特徴の生成は、スコア付け時に使用できるデータのみに基づいて行われます。
モデル トレーニング
回答しようとしている質問の種類に応じて、多くのモデリングアルゴリズムを使用できます。 事前構築済みアルゴリズムの選択に関するガイダンスについては、Azure Machine LearningデザイナーのMachine Learningアルゴリズムチートシートに関するページを参照してください。 その他のアルゴリズムは、RまたはPythonのオープンソースパッケージから入手できます。 この記事ではAzure Machine Learningに焦点を当てていますが、提供されるガイダンスは多くの機械学習プロジェクトに役立ちます。
モデル トレーニングのプロセスには、以下のステップが含まれます。
モデリング用のトレーニング データセットとテスト データセットにランダムに入力データを分割する。
トレーニング データ セットを使用してモデルを構築する。
トレーニング セットとテスト データ セットを評価する。 一連の競合する機械学習アルゴリズムを使用します。 現在のデータを使用して問題に答えることを目的とした、関連するさまざまなチューニングパラメーター (パラメータースイープと呼ばれます) を使用します。
別の方法の成功メトリックを比較して、問題に答えるための最適なソリューションを決定します。
詳細については、 「Machine Learningを使用したモデルのトレーニング」 を参照してください。
Note
リークの回避: モデルまたは機械学習アルゴリズムによる非現実的な予測を可能にするトレーニングデータセット外のデータを含めると、データリークが発生する可能性があります。 信じられないほど良好な予測結果が得られた場合に、データ サイエンティストが不安を感じる理由として代表的なのが、この漏えいです。 これらの依存関係は検出が困難な場合があります。 多くの場合、リークを回避するには、分析データセットの構築、モデルの作成、結果の精度の評価を繰り返す必要があります。
モデルの評価
モデルのトレーニング後、チームのデータサイエンティストはモデルの評価に集中します。
次のことを決定: モデルが運用環境で十分に機能するかどうかを評価します。 主な考慮事項の一部を以下に示します。
テスト データから判断して、質問に対するモデルの回答に十分な確実性があるか。
別の方法を試す必要があるか。
より多くのデータを収集したり、より多くの特徴エンジニアリングを行ったり、他のアルゴリズムを試したりする必要がありますか。
モデルを解釈: Machine Learning Python SDKを使用して、次のタスクを実行します。
個人用コンピューターでローカルに実行されるモデルの動作全体または個々の予測について説明します。
エンジニアリング済みの特徴量のための解釈可能性テクニックを有効にします。
Azure でのモデル全体と個々の予測の動作について説明します。
Machine Learningの実行履歴に説明をアップロードします。
視覚化ダッシュボードを使用して、Jupyter NotebookとMachine Learningワークスペースの両方でモデルの説明を操作します。
モデルと共にスコアリング Explainer をデプロイして、推論中の説明を観察します。
公平性の評価: Machine LearningでfairlearnオープンソースPythonパッケージを使用して、次のタスクを実行します。
モデルの予測の公平性を評価します。 このプロセスは、チームが機械学習の公平性についてさらに学習するのに役立ちます。
Machine Learning Studioとの間で公平性評価の分析情報をアップロード、一覧表示、ダウンロードします。
モデルの公平性の分析情報を操作するには、Machine Learning Studioの公平性評価ダッシュボードを参照してください。
MLflowとの統合
Machine LearningはMLflowと統合され、モデリングライフサイクルをサポートします。 MLflow の追跡を使用して、実験、プロジェクトのデプロイ、モデル管理、モデル レジストリを行います。 この統合により、シームレスで効率的な機械学習ワークフローが保証されます。 Machine Learningの次の機能は、このモデリングライフサイクル要素をサポートするのに役立ちます。
実験の追跡: MLflowのコア機能は、さまざまな実験、パラメーター、メトリック、および成果物を追跡するために、モデリング段階で広く使用されています。
プロジェクトのデプロイ: MLflowプロジェクトを使用してコードをパッケージ化すると、チームメンバー間で一貫した実行と簡単な共有が保証されます。これは、反復的なモデル開発に不可欠です。
モデルの管理: このフェーズでは、さまざまなモデルが構築、評価、および調整されるため、モデルの管理とバージョン管理が重要です。
モデルの登録: モデルレジストリは、ライフサイクル全体にわたってモデルのバージョン管理と管理に使用されます。
ピアレビューされた文献
研究者は、査読済み文献でTDSPに関する研究を発表しています。 引用により、他のアプリケーション、または TDSP に似たアイデア (モデリング関するライフサイクル ステージなど) を調査する機会が生まれます。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Mark Tabladillo | シニア クラウド ソリューション アーキテクト
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
関連リソース
これらの記事では、TDSPライフサイクルの他のステージについて説明しています。