小売業者とコンシューマー ブランドは、コンシューマーがマーケットプレース内で購入しようとしている適切な製品とサービスを確保することに重点を置いています。 また、売上を最大限にすることを検討するときに、ショッピング体験の主要な部分は製品 (または製品の組み合わせ) です。 提供の可能性 (在庫) は、常にコンシューマー ブランドにとっての関心事です。
製品の在庫 (SKU の品揃えとも呼ばれます) は、サプライと物流のバリュー チェーンにまたがる複雑な問題です。 この記事では、消費財の観点から、SKU の品揃えを最適化して収益を最大化することの問題について具体的に説明します
SKU の品揃えの最適化のパズルは、次の質問に回答するアルゴリズムを開発することで解決できます。
- 特定の市場またはストアで最適に実行されているのはどの SKU か。
- そのパフォーマンスに基づいて特定の市場またはストアに割り当てるべき SKU はどれか。
- より高いパフォーマンスの SKU に置き換える必要があるパフォーマンスが低い SKU はどれか。
- コンシューマーおよび市場区分について引き出せるその他の分析情報は何か。
意思決定の自動化
これまで、コンシューマー ブランドでは、SKU ポートフォリオ内の SKU の数を増やすことでコンシューマーの需要の問題に対処していました。 SKU の数が増え、競合が増加すると、収益の 90% が、ポートフォリオ内の製品 SKU の 10% のみで構成されていると推定されます。 通常は、収益の 80% が SKU の 20% からもたらされます。 この比率は、収益性を向上させるための候補です。
従来の静的なレポート作成方法では、履歴データを使用していますが、これでは分析情報が制限されます。 よくても、意思決定と実装は手動で行われています。 これは人が介入し、処理時間がかかることを意味します。 AI とクラウド コンピューティングの進化により、さまざまな選択肢と予測を提供する高度な分析を使用できるようになりました。 この種の自動化により、結果と顧客への対応速度が改善されます。
SKU の品揃えの最適化
SKU の品揃えソリューションでは、売上データを意味のある詳細な比較に分割することで、何百万もの SKU を処理する必要があります。 ソリューションの目標は、高度な分析を使用して製品の品揃えを調整することで、すべての直販店やストアで売上を最大化することです。 2 つ目の目標は、在庫切れをなくし、品揃えを改善することです。 財政上の目標は、売上を 5 から 10% 増やすことです。 その目標を達成するため、分析情報は次のことを可能にします。
- SKU ポートフォリオのパフォーマンスを理解して、パフォーマンスの低い SKU を管理する。
- 在庫切れを減らすために SKU の配布を最適化する。
- 新しい SKU が短期戦略および長期戦略をどのようにサポートしているかを理解する。
- 既存のデータから反復可能でスケーラブル、かつ実用的な分析情報を作成する。
記述的分析
記述的モデルでは、データ ポイントを集計し、製品の売上に影響を及ぼす可能性がある要因間のリレーションシップを調べます。 この情報は、場所、天気、国勢調査のデータなど、いくつかの外部データ ポイントを使用して拡張できます。 視覚化は、人々がデータを解釈して分析情報を得るのに役立ちます。 ただし、データの更新頻度にもよりますが、この方法では、前の販売サイクルで何が起こったか、または現期間で何が起こっているかを理解することしかできません。
たとえば、ある期間でパフォーマンスが最も高かった SKU と最も低かった SKU を把握するこのケースでは、従来のデータ ウェアハウスとレポートのアプローチで十分です。
次の図は、売上の履歴データの一般的なレポートを示しています。 これには、条件を選択して結果をフィルターするためのチェック ボックスを備えた複数のブロックが使用されています。 中央には、時間の経過と共に売上を表示する 2 つの棒グラフが示されています。 最初のグラフは、週別の平均売上を示しています。 2 つ目は、週別の数量を示しています。

予測的分析
履歴レポートは、何が起こったかを理解するのに役立ちます。 最終的な目的は、何が起こる可能性があるかを予測することです。 過去の情報は、そうした目的に役立つ場合があります。 たとえば、季節的傾向を特定できます。 ただし、新製品の導入をモデル化するための What-if シナリオなどには役立ちません。 これを行うには、顧客の行動のモデル化に焦点を移す必要があります。顧客の行動が売上を左右する最終的な要因であるためです。
問題の詳細: モデルの選択
まず、探しているものと持っているデータを定義することから始めます。
品揃えの最適化とは、予想収益を最大化する、販売製品のサブセットを見つけることです。 これが探しているものです。
トランザクション データは、財務目的で定期的に収集されます。
品揃えデータには、SKU に関連するすべてのものを含めることができます。必要なものの例を次に示します。
- SKU の数
- SKU の説明
- 割り当てられた数量
- SKU と購入した数量
- イベント (購入など) のタイム スタンプ
- SKU 価格
- POS の SKU 価格
- 任意の時点でのすべての SKU の在庫レベル
残念ながら、こうしたデータはトランザクション データほど確実に収集されません。
この記事では、わかりやすくするため、外部要因は考慮せず、トランザクション データと SKU データのみを考慮します。
その場合でも、n 個の製品がある場合、2n の考えられる品揃えがあることに注意してください。 これにより、最適化の問題がコンピューターに高い負荷のかかるプロセスになります。 製品数が多い場合には、考えられるすべての組み合わせを評価することは実用的ではありません。 そのため、通常は、品揃えをカテゴリ (穀物など)、場所、その他の条件で分割して、変数の数を減らします。 最適化モデルは、実行可能なサブセットにするために順列の数を削ることを試みます。
問題の最も重要な点は、効果的にコンシューマーの行動をモデリングできるかどうかです。 コンシューマーに提示される製品が、コンシューマーが購入したいものと一致するのが理想です。
コンシューマーの選択を予測する数学的モデルは、数十年にわたって開発されています。 最適な実装テクノロジを最終的に決定するのは、モデルの選択です。 そのため、ここではその概要を説明し、いくつかの考慮事項を提供します。
パラメトリック モデル
パラメトリック モデルは、関数と有限のパラメーターを使用して顧客の行動を見積もります。 データに最適なパラメーターのセットを自由に見積もります。 最も古く最もよく知られているものの 1 つが、多項ロジスティック回帰 (MNL、多クラス ロジット、ソフトマックス回帰とも呼ばれます) です。 これは分類の問題で考えられる複数の結果の確率の計算に使用されます。 このケースでは、MNL を使用して計算できます。
品揃え (a) 内のそのカテゴリの品目のセットが顧客 (v) にとって既知の有用性を持つ場合、コンシューマー (c) が特定の時点 (t) で品目 (i) を選ぶ確率。
品目の有用性がその機能の関数であることをも想定しています。 有用性の測定には外部情報も含めることができます (雨が降ると傘の有用性が高まるなど)。
パラメーターの見積もりと結果の評価における MNL の取り扱いやすさにより、Microsoft ではその他のモデルのベンチマークとして MNL をしばしば使用しています。 つまり、MNL よりも悪い場合は、そのアルゴリズムは役に立たないということです。
いくつかのモデルは MNL から派生されていますが、それらについてはこのドキュメントでは取り扱いません。
R および Python プログラミング言語用のライブラリがあります。 R には、glm (および派生物) を使用できます。 Python には、scikit-learn、biogeme、larch があります。 これらのライブラリでは、MNL の問題を指定するツールと、さまざまなプラットフォームでソリューションを検索する並列ソルバーが提供されています。
最近では、別の方法では解決困難になる可能性がある多くのパラメーターを持つ複雑なモデルを計算するため、GPU に MNL モデルを実装することが提案されています。
大きな多クラスの問題では、ソフトマックス出力層を持つニューラル ネットワークが効果的に使用されています。 これらのネットワークでは、多くの異なる結果の確率分布を表す出力のベクターが生成されます。 これらは他の実装と比べるとトレーニングに時間がかかりますが、多くのクラスとパラメーターを処理できます。
ノンパラメトリック モデル
MNL は、広く普及していますが、いくつかの重要な想定をその有用性を制限する可能性のある人間の行動に置いています。 具体的には、ある人が 2 つの選択肢から選択する相対的な確率が、その後のセットで導入された追加の代替策とは独立していることを想定しています。 多くの場合、これは実用的ではありません。
たとえば、製品 A と B を同じくらい気に入っている場合、一方を選択する確率は 50% です。 ここで、製品 C を混ぜてみましょう。 製品 A を選択する確率はまだ 50% かもしれませんが、優先順位が製品 B と製品 C で分割され、確率が 25% ずつになります。相対的確率が変更されました。
また、MNL やそこから派生したものに、在庫切れによる代替品や品揃えの多様性を考慮する簡単な方法はありません (つまり、明確なアイデアがない場合は、在庫の中からランダムに品目を選択します)。
ノンパラメトリック モデルは、代替品を考慮し、顧客の行動に課される制約を減らすために設計されています。
モデルには、コンシューマーが品揃え内の製品に対して厳密な優先順位を表す "順位付け" の概念が導入されています。 したがって、コンシューマーの購買行動は、製品を優先順位の降順で並べ替えることでモデル化できます。
品揃えの最適化の問題は、収益の最大化として表現できます。
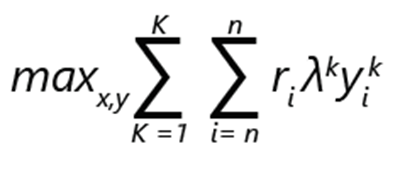
- ri は、製品 i の収益を表します。
- 製品 i が順位付け k で選択される場合、yik は 1 です。 それ以外の場合は 0 です。
- λk は、顧客が順位付け k に従って選択する確率です。
- 製品が品揃えに含まれる場合、xi は 1 です。 それ以外の場合は 0 です。
- K は順位付けの数です。
- n は製品の数です。
注意
制約の対象:
- 各順位付けに対して 1 つだけ選択できる。
- 順位付け k の下では、製品 i を選択できるのは、それが品揃えに含まれている場合のみ。
- 製品 i が品揃えに含まれている場合、順位付け k でそれより優先順位が低い選択肢を選択することはできない。
- 購入なしは選択肢の 1 つであるため、順位付けで優先順位が低い選択肢を選択することはできない。
このような公式化では、問題は混合整数最適化と見なすことができます。
n 個の製品がある場合、選択しないという選択肢を含めた考えられる順位付けの最大数は、階乗 (n+1)! であることについて考えてみましょう。
公式化における制約により、考えられる選択肢の比較的効率的な排除が可能になります。 たとえば、最も優先順位の高い選択肢が選択されて、1 に設定されます。 残りは 0 に設定されます。 選択可能な代替品の数を考えると、実装のスケーラビリティが重要になることが想像できます。
データの重要度
売上データがすぐに使用できることは既に説明しました。 これを使用して、品揃えの最適化モデルに情報を提供します。 具体的には、確率分布 λ を見つけます。
POS システムからの売上データは、タイムスタンプ付きのトランザクションと、その時と場所で顧客に表示される製品のセットで構成されます。 これらから、実際の売上のベクターを構築できます。この要素は vi で、m は既定の品揃え Sm で品目 i の顧客への販売確率を表します
マトリックスを構築することもできます。
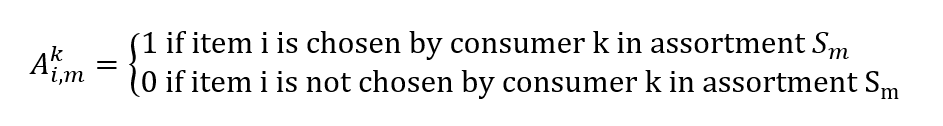
売上データを仮定して確率分布 λ を見つけることは、別の最適化の問題になります。 売上の予測ミスを最小限に抑えるため、ベクター λ を見つけます。
minλ |Λλ - v|
計算は回帰として表現することもできるため、多変量のデシジョン ツリーのようなモデルを使用できます。
実装の詳細
前記の公式化から差し引くことができるため、最適化モデルはデータドリブンと数値計算の両方になります。
Neal Analytics などの Microsoft パートナーは、これらの条件を満たす堅牢なアーキテクチャを開発しています。 SKU の品揃えの最適化 をご覧ください。 例としてこれらのアーキテクチャを使用し、いくつかの考慮事項を提供します。
- まず、これらのアーキテクチャは、モデルをフィードするための堅牢でスケーラブルなデータ パイプラインと、それらを実行するための堅牢でスケーラブルな実行インフラストラクチャに依存しています。
- 次に、ダッシュボードを使用してプランナーが簡単に結果を利用できます。
図 2 は、サンプル アーキテクチャを示しています。 これには、4 つの主要なブロック (キャプチャ、プロセス、モデル化、運用化) が含まれています。 各ブロックには、主要なプロセスが含まれています。 キャプチャにはデータの前処理が含まれ、プロセスにはデータの格納機能が含まれ、モデル化には機械学習モデルのトレーニング機能が含まれ、運用化にはデータの格納とレポート オプション (ダッシュボードなど) が含まれています。

図 2: SKU 最適化のためのアーキテクチャ (Neal Analytics 提供)
データ パイプライン
このアーキテクチャでは、モデルのトレーニングと操作のためにデータ パイプラインを確立することの重要性が強調されています。 統合ワークフローを設計して実行できるマネージド ETL (抽出、変換、読み込み) サービスの Azure Data Factory を使用して、パイプライン内のアクティビティを調整します。
Azure Data Factory は、データセットを使用または生成する (またはその両方を行う) "アクティビティ" と呼ばれるコンポーネントを持つマネージド サービスです。
アクティビティは以下に分割できます。
- データ移動 (たとえば、移動元から移動先にコピーする)
- データ変換 (たとえば、SQL クエリを使用した集計や、ストアド プロシージャの実行など)
アクティビティのセットをリンクするワークフローは、データ ファクトリ サービスによってスケジュール、監視、管理できます。 完全なワークフローは、"パイプライン" と呼ばれています。
キャプチャ フェーズでは、Data Factory のコピー アクティビティを使用して、さまざまなソース (オンプレミスとクラウドの両方) からデータを Azure SQL Data Warehouse に転送できます。 そのやり方の例については、次のドキュメントに記載されています。
次の図は、パイプラインの定義を示しています。 これは同じサイズの連続する 3 つのブロックで構成されています。 最初の 2 つはデータセットとアクティビティで、データ フローを示す矢印で接続されています。 3 つ目は、パイプラインというラベルが付いており、カプセル化を示すため、最初の 2 つをポイントしています。

図 3: Azure Data Factory の基本的な概念
Neal Analytics のソリューションで使用されているデータ形式の例は、Microsoft のコマーシャル マーケットプレース ページで確認できます。 このソリューションには、次のデータセットが含まれています。
- ストアと SKU の組み合わせごとの売上履歴データ
- ストアとコンシューマーのレコード
- SKU コードと説明
- 製品の機能をキャプチャする SKU の属性 (サイズ、素材など)。 これらは通常、製品のバリアントを区別するためにパラメトリック モデルで使用されます。
データ ソースが特定の形式で表されない場合、Data Factory によって一連の変換アクティビティが提供されます。
プロセスのフェーズでは、SQL Data Warehouse がメイン ストレージ エンジンです。 このような変換アクティビティを、パイプラインの一部として自動的に呼び出すことができる SQL ストアド プロシージャとして表すこともできます。 詳細な手順は、次のドキュメントに記載されています。
Data Factory により、SQL Data Warehouse および SQL ストアド プロシージャに制限されることはありません。 実際には、さまざまなプラットフォームと統合します。 たとえば、変換の代わりに、Databricks を使用し、Python スクリプトを実行できます。 1 つのプラットフォームをストレージと変換、および次のモデル ステージで機械学習アルゴリズムのトレーニングに使用できるため、これは利点です。
ML アルゴリズムのトレーニング
パラメトリック モデルおよびノンパラメトリック モデルを実装するのに役立ついくつかのツールがあります。 スケーラビリティとパフォーマンスの要件に応じて選択します。
Azure ML Studio は、プロトタイプ作成に最適なツールです。 これにより、コード モジュール (R または Python) を使用して、あるいはグラフィック環境で定義済みの ML コンポーネント (多クラス分類子、ブースト デシジョン ツリー回帰など) を使用して、トレーニング ワークフローを構築して実行するための簡単な方法が提供されます。 また、REST インターフェイスを生成して、さらに使用するための Web サービスとしてトレーニング済みモデルを公開することも簡単になります。
ただし、処理できるデータ サイズは、現時点では 10 GB に制限されており、各コンポーネントで使用できるコアの数も 2 個に制限されています。
さらにスケーリングする必要があるが、Microsoft の一般的な機械学習アルゴリズム (多項ロジスティック回帰など) の高速な並列実装の一部を引き続き使用したい場合は、Azure Data Science Virtual Machine で実行される Microsoft ML Server を検討できます。
非常に大きなデータ サイズ (TB) の場合、ストレージと計算要素が次のことができるプラットフォームを選択することをお勧めします。
- モデルをトレーニングしていないときにコストを制限するために個別にスケールできる。
- 複数のコアに計算を分散できる。
- データ移動を制限するために、ストレージの近くで計算を実行できる。
Azure HDInsight と Databricks はどちらもこれらの要件を満たしています。 また、どちらも Azure Data Factory エディター内でサポートされている実行プラットフォームです。 ワークフローにいずれかを統合するのは比較的簡単です。
ML Server とそのライブラリは、HDInsight の一番上に配置できますが、プラットフォーム機能を最大限に活用するために、SparkML、Python の Microsoft ML Spark ライブラリ、または TFoCS、Spark-LP、SolveDF などのその他の専門的なリニア プログラミング ソルバーを使用して、最適な ML アルゴリズムを実装できます。
トレーニング プロセスの開始すると、Data Factory ワークフローから適切な pySpark スクリプトやノートブックを呼び出せるかが問題になります。 これは、グラフィカル エディターで完全にサポートされます。 詳細については、「Azure Data Factory で Databricks Notebook アクティビティを使用して Databricks ノートブックを実行する」を参照してください。
次の図は、Azure portal からアクセスしたときの Data Factory ユーザー インターフェイスを示しています。 これには、ワークフロー内のさまざまなプロセスのブロックが含まれています。

図 4: Databricks Notebook アクティビティを使用した Data Factory パイプラインの例
また、Microsoft のインベントリの最適化ソリューションでは、Azure Batch を通じてスケーリングされるソルバーのコンテナーベースの実装を提案しています。 pyomo などのスペシャリスト最適化ライブラリでは、最適化の問題を Python プログラミング言語で表現し、bonmin (オープン ソース) や gurobi (商用) などの独立したソルバーを呼び出して、ソリューションを見つけることができます。
在庫最適化のドキュメントでは、品揃えの最適化とは異なる問題 (注文数量) を取り上げていますが、Azure でのソルバーの実装は同じように適用することができます。
この手法はこれまで提案されていたものよりも複雑になりますが、最大限のスケーラビリティが可能になります (主に使用できるコアの数で制限されます)。
モデルの実行 (運用化)
モデルをトレーニングした後、そのモデルを実行するには、デプロイに使用したのとは異なるインフラストラクチャが通常は必要になります。 簡単に使用できるようにするため、REST インターフェイスを持つ Web サービスとしてデプロイすることもできます。 Azure ML Studio と ML Server はどちらも、このようなサービスの作成プロセスを自動化します。 ML Server の場合、Microsoft では、サポート インフラストラクチャをデプロイするためのテンプレートを提供しています。 関連するドキュメントを参照してください。
次の図は、このデプロイのアーキテクチャを示しています。 これには、R 言語と Python を実行するサーバーの表現が含まれています。 どちらのサーバーも、計算を実行する Web ノードのサブセクションと通信します。 大規模なデータ ストアが計算ブロックに接続されています。

図 5: ML Server のデプロイの例
HDInsight または Databricks で作成されるモデルは、Spark 環境 (ライブラリ、並列機能など) に依存します。 これらをクラスターで実行することを検討できます。 ガイダンスについては、こちらを参照してください。 これを行うと、スコアリングのために Data Factory パイプラインのアクティビティを通じて、運用モデルそのものを呼び出せるという利点があります。
コンテナーを使用するには、モデルをパッケージ化し、それを Azure Kubernetes Service 上にデプロイします。 プロトタイプでは、Azure Data Science VM を使用する必要があります。 VM に Azure ML コマンド ライン ツールをインストールする必要もあります。
データの出力とレポート
デプロイ後、モデルで金融取引のワークフローや在庫の読み取りを処理して、最適な品揃えの予測を生成できます。 そのため、生成されたデータをさらに詳しく分析するために、Azure SQL Data Warehouse に戻して格納することができます。 具体的には、最大の収入源と損失源を識別することで、さまざまな SKU のパフォーマンスの履歴を調査できます。 その後、これらをモデルから提案された品揃えと比較して、パフォーマンスと再トレーニングの必要性を評価できます。
Power BI では、プロセスで生成されたデータを分析して表示する方法が提供されます。
次の図は、一般的な Power BI ダッシュボードを示しています。 SKU の在庫情報を表示する 2 つのグラフが含まれています。
セキュリティに関する考慮事項
機密データを処理するソリューションには、財務記録、在庫レベル、価格情報が含まれています。 このような機密データは保護する必要があります。 次の方法で、データのセキュリティとプライバシーに関する懸念を緩和できます。
- Azure Integration Runtime を使用して、Azure Data Factory パイプラインの一部をオンプレミスで実行できます。 ランタイムにより、オンプレミス ソースとの間でデータ移動アクティビティが実行されます。 また、オンプレミスで実行するためのアクティビティがディスパッチされます。
- カスタム アクティビティを開発して、Azure に転送するデータを匿名化し、オンプレミスで実行できます。
- ここで言及したすべてのサービスが、送信および保存時の暗号化をサポートしています。 Azure Data Lake を使用してデータを格納する場合、暗号化は既定で有効になります。 Azure SQL Data Warehouse を使用する場合は、Transparent Data Encryption (TDE) を有効にできます。
- 言及されているすべてのサービス (ML スタジオを除く) が、認証と認可のために Microsoft Entra ID との統合をサポートしています。 独自のコードを記述する場合、その統合をアプリケーションに組み込む必要があります。
欧州連合のデータ保護とプライバシーに関する規則である一般データ保護規則 (GDPR) について詳しくは、コンプライアンスに関するページを参照してください。
コンポーネント
この記事では、次のテクノロジを利用しました。
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory
- HDInsight
- Databricks
- データ サイエンス仮想マシン
- Azure Kubernetes Service
- Microsoft Power BI
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Scott Seely 氏 | ソフトウェア アーキテクト
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- Azure Data Factory とは
- Azure Data Factory の統合ランタイム
- Azure Synapse Analytics の専用 SQL プール (以前の SQL DW) とは
- Microsoft Machine Learning Studio (クラシック)
- Machine Learning Server とは
- Pyomo 最適化モデリング言語
- Bonmin ソルバー
- Spark 用 TFoCS ソルバー
関連リソース
関連する小売ガイダンス:
関連アーキテクチャ