複雑な処理を実行するタスクを、再利用できる一連の独立した要素に分解します。 これを行うと、プロセスを実行するタスク要素をデプロイし、個別にスケールすることで、パフォーマンス、スケーラビリティ、初期手順の再利用性を向上できます。 パイプとフィルター パターンは、高レベルのモジュール性をサポートします。
コンテキストと問題
処理する必要があるシーケンシャル タスクのパイプラインがあります。 その処理をモノシリック モジュールとして実行するのが、柔軟性は低いもののアプリケーションの実装方法としては簡単です。 しかしそのアプリケーション内のどこか他の箇所で同じ処理の一部分が必要になったとき、この方法では、コードのリファクタリングや最適化、再利用の可能性が制限されます。
次の図は、モノリシック アプローチを使用してデータを処理する際の問題の 1 つを示しています。この方法では、複数のパイプライン間でコードを再利用できません。 こちらの例では、アプリケーションが 2 つのソースからデータを受け取って処理します。 データを変換する一連のタスクを実行してからその結果をアプリケーションのビジネス ロジックに渡すことで、各ソースのデータが個別のモジュールによって処理されます。
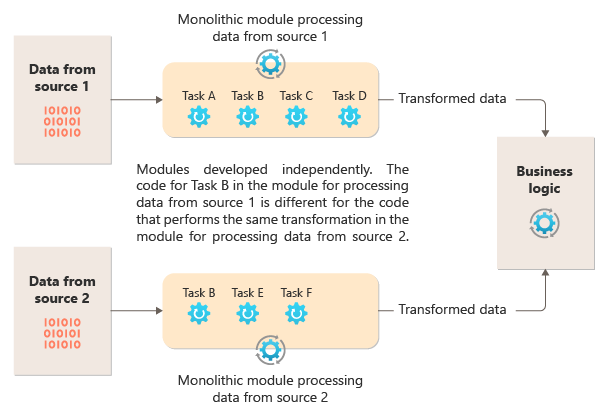
モノリシック モジュールで実行されるタスクの一部は機能的に似ていますが、両方のモジュールでコードを繰り返す必要があり、そのモジュール内で密結合されている可能性があります。 この方法では、ロジックを再利用できないことに加えて、要件が変更されたときにリスクが発生します。 両方の場所でコードを忘れずに更新する必要があります。
複数のパイプラインや再利用とは無関係のモノリシック実装には他にも課題があります。 モノリスを使用すると、異なる環境で特定のタスクを実行したり、個別にスケーリングしたりすることはできません。 一部のタスクはコンピューティング集中型であり、強力なハードウェアで実行したり、複数のインスタンスを並列で実行したりできるメリットがあります。 他のタスクには同じ要件がない場合があります。 さらに、モノリスでは、タスクを並べ替えたり、パイプラインに新しいタスクを挿入したりすることが困難です。 これらの変更を行った場合にはパイプライン全体を再テストする必要があります。
解決策
各ストリームで必要な処理を、一連の独立したコンポーネント (またはフィルター) に分解し、各コンポーネントでそれぞれ 1 つのタスクを実行します。 複合タスクでは、1 つではなく複数のフィルターを使用する必要があります。 フィルターは、フィルターとパイプを接続することによってパイプラインに構成されます。 フィルターは独立しており、自己完結型であり、通常はステートレスです。 フィルターは受信パイプからメッセージを受信し、別の送信パイプにメッセージを発行します。 フィルターは、メッセージを変換したり、1 つ以上の条件に対してテストしたりして、条件付きロジックを含めることができます。 パイプはルーティングやその他のロジックを実行しません。 フィルターのみを接続し、1 つのフィルターからの出力メッセージを入力として次のフィルターに渡します。
フィルターは独立して動作し、他のフィルターを認識しません。 入力スキーマと出力スキーマのみが認識されます。 そのため、フィルターの入力スキーマが前のフィルターの出力スキーマと一致する限り、フィルターの適用順序を好きなように設定できます。 すべてのフィルターに標準化されたスキーマを使用すると、フィルターを並べ替えやすくなります。 パイプとフィルターのアーキテクチャでは、構成の再利用が促進されます。
フィルターの疎結合により、次の操作を簡単に行うことができます。
- 既存のフィルターで構成される新しいパイプラインを作成する
- 個々のフィルターのロジックを更新または置換する
- 必要に応じてフィルターを並べ替える
- 必要に応じて異なるハードウェアでフィルターを実行する
- フィルターを並列で実行する
この図は、パイプとフィルターを使用して実装されるソリューションを示しています。
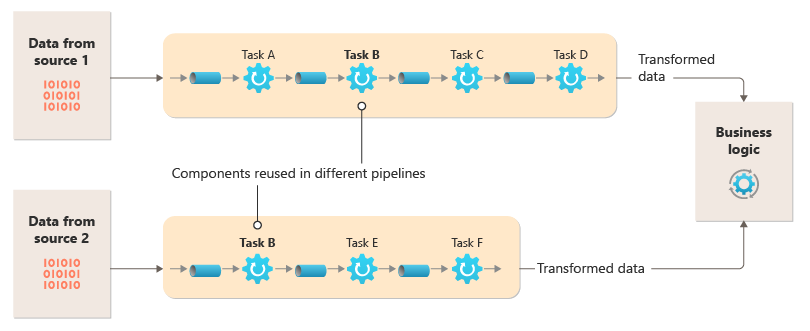
1 つの要求を処理するのにかかる時間は、パイプライン内で最も低速なフィルターの速度によって決まります。 特定のデータ ソースからのストリーム内に多数の要求が含まれている場合は特に、1 つまたは複数のフィルターがボトルネックになるおそれがあります。 低速フィルターのインスタンスを並列実行する機能により、システムの負荷を分散し、スループットを向上させることができます。
フィルターは別々のコンピューティング インスタンスで実行できるため、フィルターを個別にスケーリングしたり、多くのクラウド環境で提供されている弾力性を活用したりできます。 計算負荷の高いフィルターは高性能のハードウェアで実行し、その他の必要条件が少ないフィルターは低価格の汎用的なハードウェアで実行できます。 フィルターは同じデータ センターまたは地理的な場所に配置される必要もないため、パイプライン内の各要素は、それが必要とするリソースに近い環境で実行できます。 これらの作業には、各パイプまたはフィルターの弾力性を最大化するために、メッセージング、マルチスレッドなどの特定の設計手法が必要です。 この図は、ソース 1 からのデータに対するパイプラインの適用例を示しています。
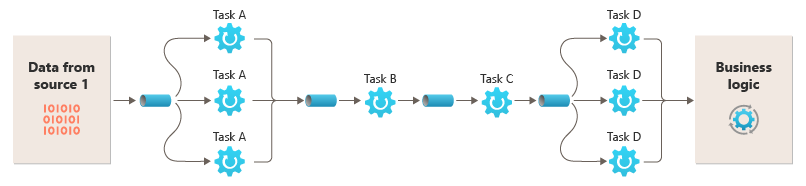
フィルターの入出力をストリームとして構成した場合は、各フィルターの処理を並列に実行できます。 パイプライン内の最初のフィルターが作業を開始し、結果を出力すると、最初のフィルターの作業が完了する前に、シーケンス内の次のフィルターに結果が直接渡されます。
分散トランザクションを実装するための別のアプローチとして、パイプとフィルターのパターンを補正トランザクション パターンと一緒に使用する方法があります。 分散トランザクションを補正可能な個別のタスクに分けることができ、それぞれを、補正トランザクション パターンも実装しているフィルターを使用して実装できます。 パイプライン内のフィルターは、それらが管理しているデータの近くで実行される、個別のホストされたタスクとして実装できます。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
モノリシックの性質。 通常、このパターンはモノリシック パイプラインとして実装されるため、変更の場合は、フィルター チェーン全体をエンド ツー エンドでテストする必要があります。 また、プロセス全体のフォールト トレランスを考慮する必要があります。フィルターまたはパイプが失敗した場合、パイプライン全体が失敗する可能性があります。
複雑さ。 パイプライン内のフィルターをさまざまなサーバー間で分散する場合は特に、このパターンによって柔軟性が向上する一方で、複雑性が増大します。
信頼性。 パイプ内のフィルター間を流れるデータが失われないことを保証したインフラストラクチャを使用します。
べき等性。 メッセージを受信した後にパイプライン内のフィルターが失敗し、作業のスケジュールがフィルターの別のインスタンスで実行されるように変更された場合、作業の一部が既に完了している可能性があります。 この作業によって、グローバル状態の一部 (データベースに格納されている情報など) が更新されている場合、1 つの更新が繰り返される可能性があります。 フィルターで、次のフィルターに結果を送信してから自身の作業が正常に完了したことを表明するまでの間に障害が発生した場合にも、同様の問題が発生することがあります。 このような場合は、フィルターの別のインスタンスでも同じ作業が繰り返され、同じ作業を 2 回ポストすることになる可能性があります。 このシナリオでは、パイプライン内の後続のフィルターで同じデータが 2 回処理される可能性があります。 したがって、パイプライン内のフィルターは、べき等になるように設計する必要があります。 詳細については、べき等パターンに関する Jonathan Oliver のブログを参照してください。
メッセージの繰り返し。 パイプライン内のフィルターが、パイプラインの次のステージにメッセージをポストした後でエラーになった場合は、フィルターの別のインスタンスが実行される可能性があり、それがパイプラインに同じメッセージのコピーをポストすることになります。 このシナリオでは、同じメッセージの 2 つのインスタンスが次のフィルターに渡される可能性があります。 この問題を回避するには、パイプラインで、重複するメッセージを検出して削除する必要があります。
注意
メッセージ キュー (Microsoft Azure Service Bus キューなど) を使用してパイプラインを実装した場合、メッセージ キュー インフラストラクチャでは、重複するメッセージを自動検出して削除できます。
コンテキストと状態。 パイプライン内の各フィルターは、基本的に分離して実行され、自身がどのように呼び出されたかについて推測する必要はありません。 そのため、各フィルターには、作業を実行するためのコンテキストが十分に提供される必要があります。 このコンテキストとして、大量の状態情報などが考えられます。 フィルターでデータベース内や外部ストレージのデータなどの外部状態を使用する場合は、パフォーマンスへの影響を考慮する必要があります。 すべてのフィルターで、その状態を読み込み、操作し、保持する必要があります。そのため、外部状態を 1 回読み込むソリューションのオーバーヘッドが増えます。
メッセージの許容範囲。 フィルターは、操作しない受信メッセージ内のデータに対してトレラントである必要があります。 データに関連する操作を行い、他のデータを無視し、出力メッセージで変更せずにデータを渡します。
エラー処理 - すべてのフィルターで、重大なエラーが発生した場合の対処方法を判断する必要があります。 フィルターでは、パイプラインに失敗したか例外を伝達するかを判断する必要があります。
このパターンを使用する状況
このパターンは次の状況で使用します。
アプリケーションで必要な処理を一連の独立した手順に容易に分割することができる。
アプリケーションによって実行される処理手順に、さまざまなスケーラビリティ要件がある。
注意
スケーリングが必要なフィルターを同じプロセスにグループ化できます。 詳細については、「Compute Resource Consolidation pattern」 (Compute Resource Consolidation パターン) を参照してください。
アプリケーションによって実行される処理手順の並び替えを可能にする、または手順を追加および削除できるようにする柔軟性が必要です。
手順の処理をさまざまなサーバーに分散することでシステムに利点がある。
データの処理中に手順に発生したエラーの影響を最小限に抑えることができる信頼性の高いソリューションが必要である。
このパターンが適さない状況
アプリケーションは要求 - 応答パターンに従います。
タスク処理は、要求/応答シナリオなどの初期要求の一部として完了する必要があります。
アプリケーションによって実行される処理手順が独立していない。すなわち、それらを 1 つのトランザクションの一部としてまとめて実行する必要がある。
手順で必要とされるコンテキストまたは状態情報の量が、このアプローチを使用するには不十分である。 状態情報をデータベースに保存できる場合がありますが、データベース上での負荷の増加が過剰な競合を引き起こす場合、この手法は使用しないでください。
ワークロード設計
設計者は、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、ワークロードの設計でどのようにパイプとフィルター パターンを使用できるかを評価する必要があります。 次に例を示します。
| 重要な要素 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して 復元力 を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | ステージごとの責任は単一であるため、その 1 点に注意を集中することができ、さまざまなデータ処理に労力が分散されるのを回避できます。 - RE:01 簡素化 - Re: 07バックグラウンドジョブ |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
メッセージ キューのシーケンスを使用して、パイプラインの実装に必要なインフラストラクチャを実現することができます。 最初のメッセージキューは、パイプとフィルターパターンの実装の開始となる未処理のメッセージを受信します。 フィルター タスクとして実装されたコンポーネントは、このキューでメッセージをリッスンし、作業を実行し、新規メッセージまたは変換したメッセージをシーケンス内の次のキューにポストします。 別のフィルタータスクは、パイプとフィルター処理を終了する最後の手順まで、このキューでメッセージをリッスンし、それらを処理し、結果を別のキューにポストすることができます。 この図は、メッセージ キューを使用するパイプラインを示しています。

このパターンを使用して、画像処理パイプラインを実装できます。 ワークロードがイメージを取得する場合、イメージは一連の独立した並べ替え可能なフィルタを通過して、次のようなアクションを実行できます。
- コンテンツ モデレーション
- サイズ変更中
- 透かし
- 再配向
- Exifメタデータの削除
- コンテンツ配信ネットワーク (CDN) 文書
この例では、フィルターは、個別にデプロイされたAzure Functionsとして実装することも、分離されたデプロイとして各フィルターを含む単一のAzure Functionアプリとして実装することもできます。 Azure関数トリガー、入力バインド、および出力バインドを使用すると、フィルターコードが簡略化され、処理するイメージに対する要求チェックを使用してキューベースのパイプで自動的に機能します。

Azure関数として実装された1つのフィルターが、イメージに対する要求チェックを含むQueue Storageパイプからトリガーされ、別のQueue Storageパイプに新しい要求チェックが書き込まれる例を次に示します。 簡潔にするために、コメント内の実装を擬似コードに置き換えました。 このようなコードは、GitHubで入手できるPipes and Filtersパターンのデモにあります。
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Note
Spring Integration Framework には、パイプとフィルター パターンの実装があります。
次のステップ
このパターンを実装する場合、次のリソースが役立つ場合があります。
- 画像処理シナリオを使用したPipes and Filtersパターンのデモは、GitHubで入手できます。
- Jonathan Oliver のブログの Idempotency パターン。
関連リソース
このパターンを実装する場合は、次のパターンも関連している可能性があります。
- クレーム チェック パターン。 キューを使用して実装されたパイプラインは、フィルターを介して送信される実際の項目を保持するのではなく、処理する必要があるデータへのポインターを保持する場合があります。 この例では、Azure Blob Storageに格納されているイメージに対してAzure Queue Storageの要求チェックを使用します。
- 競合コンシューマー パターン。 パイプラインには、1 つまたは複数のフィルターの複数のインスタンスを含めることができます。 このアプローチは、低速フィルターのインスタンスを並列実行する場合に役立ちます。 これにより、システムでは負荷を分散し、スループットを向上できます。 フィルターの各インスタンスは、互いに入力で競合しますが、フィルターの 2 つのインスタンスで同じデータを処理できません。 この記事では、このアプローチについて説明します。
- Compute Resource Consolidation パターン。 スケーリングする必要があるフィルターを 1 つのプロセスにグループ化できる場合があります。 この記事では、この方法の利点とトレードオフの詳細について説明します。
- Compensating Transaction パターン。 フィルターは、取り消し可能な操作として、または障害が発生した場合に状態を前のバージョンに復元する補正操作を備えた操作として実装できます。 この記事では、最終的な整合性を維持または達成するためにこのパターンを実装する方法について説明します。
- パイプとフィルター - エンタープライズ統合パターン。