Azure
アプリケーションのインスタンス、個々のテナント、またはサービス全体によって使用されるリソースの使用量を制御します。 これにより、需要の増加によってリソースに極端な負荷が発生した場合でも、システムは引き続き機能し、サービス レベルの目標 (SLO) を満たすことができます。
コンテキストと問題
通常、クラウド アプリケーションにかかる負荷は、アクティブ ユーザー数、またはアクティブ ユーザーが実行しているアクティビティの種類に応じて、時間の経過と共に変化します。 たとえば、より多くのユーザーが業務時間中にアクティブになる可能性がある、あるいはシステム上で計算コストの高い分析を毎月月末に実行しなければならない可能性がある、などの場合です。 突然、予期せずアクティビティが急増することもあります。 システムの処理要件が使用可能なリソースの容量を超えると、パフォーマンスが低下し、失敗する可能性があります。 そのシステムにおいて、契約したサービス レベルに準拠する必要がある場合は、そのような障害は許容できません。
クラウドには、アプリケーションのビジネス目標に応じて、変化する負荷に対応するための戦略が数多くあります。 戦略の 1 つは、自動スケールを使用して、プロビジョニング済みのリソースを特定の時点のユーザーのニーズに合わせることです。 これにより、ランニング コストを最適化しつつ、一貫してユーザーの要求に応えていくことが可能になります。 ただし、自動スケールでは追加リソースのプロビジョニングをトリガーできますが、このプロビジョニングは即時ではありません。 要求が急激に増加した場合、リソースが不足する期間が発生する可能性があります。
解決策
自動スケールに代わる戦略として、アプリケーションに上限までのリソースの使用を許可し、この上限に達したときに調整を行う方法があります。 使用量がしきい値を超えたときに 1 人または複数のユーザーの要求を制限できるよう、システムがリソースの使用状況を監視します。 これにより、システムは引き続き機能し、適切なサービス レベル目標 (SLO) を満たできるようになります。 リソース使用状況の監視の詳細については、「Instrumentation and Telemetry Guidance (インストルメンテーションとテレメトリに関するガイダンス)」をご覧ください。
システムには次のような複数の調整戦略を実装できます。
システムの API に指定した期間に 1 秒あたり n 回よりも多くアクセスした個人ユーザーからの要求を拒絶する。 これには、システムで各テナントのリソース使用量、またはアプリケーションを実行するユーザー数を測定することが必要です。 詳細については、「Service Metering Guidance (サービスの測定に関するガイダンス)」をご覧ください。
重要なサービスを十分なリソースで滞りなく実行できるよう、選択した重要でないサービスの機能を無効にする、または品質を下げる。 たとえば、アプリケーションでビデオ出力をストリーミングしている場合、低解像度に切り替えることができます。
負荷平準化によってアクティビティのボリュームを平準化する (このアプローチの詳細については、「Queue-based Load Leveling pattern (キュー ベースの負荷平準化パターン)」をご覧ください)。 マルチテナント環境では、このアプローチですべてのテナントのパフォーマンスを縮小します。 SLA の異なるテナントが混在している状態がシステムによってサポートされている必要があれば、高価値のテナントの作業を即時に実行することがあります。 その他のテナントの要求処理は差し止められ、バックログが収まった時点で処理されます。 さまざまなサービス レベルや優先順位に対して異なるエンドポイントを公開するのと同様に、優先順位キュー パターンを使用すると、このアプローチを実装しやすくなります。
優先度の低いアプリケーションまたはテナントの代わりとして実行される操作を延期する。 システムがビジー状態であることと、その操作をあとで再試行すべきであることをテナントに知らせるために例外を生成して、操作を一時停止または制限できます。
一部のサードパーティ サービスとの統合では、利用できなくなったりエラーが返されたりする可能性があるため、注意が必要です。 ログが不必要にエラーでいっぱいにならないよう、同時に処理される要求の数を減らします。 また、サードパーティ サービスが原因で失敗した要求の処理を不必要に再試行することに伴うコストも回避できます。 その後、要求が正常に処理されたら、通常のスロットルされていない要求処理に戻ります。 この機能を実装しているライブラリの 1 つが NServiceBus です。
次の図では、3 つの機能を使用しているアプリケーションの、リソース使用量 (メモリ、CPU、帯域幅などの要素の組み合わせ) の領域グラフを時系列で示しています。 1 つの機能は、特定のタスク セットを実行するコンポーネント、複雑な計算を実行する 1 つのコード、またはメモリ内キャッシュなどのサービスを提供する要素など、1 つの機能領域を示しています。 これらの機能に A、B、C という名前が付けられています。
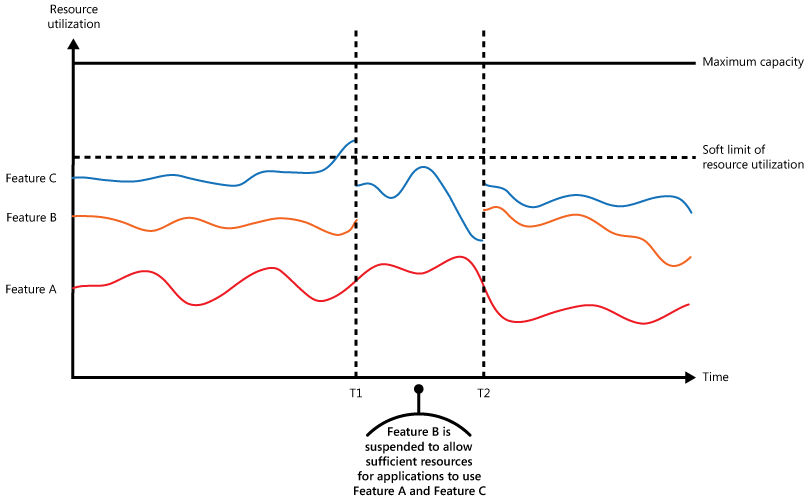
機能の線のすぐ下の領域は、その機能が呼び出されたときにアプリケーションが使用するリソースを示しています。 たとえば、機能 A の線の下の領域は、機能 A を使用しているアプリケーションが使用するリソースを示しており、機能 A と機能 B の線の間にある領域は、機能 B を呼び出すアプリケーションが使用するリソースを示しています。各機能の領域の合計が、そのシステムが使用するリソースの総計です。
前の図は、遅延操作の影響を示しています。 時刻 T1 の直前に、これらの機能を使用するすべてのアプリケーションに割り当てられたリソースの合計がしきい値に達します。 このしきい値は、リソース使用の制限を表します。 この時点で、アプリケーションが使用可能なリソースを使い果たす危険性が生じます。 このシステムでは、機能 B は 機能 A や機能 C よりも重要ではないため一時的に無効化され、機能 B が使用していたリソースが解放されます。 時間 T1 と T2 の間では、機能 A と機能 C を使用しているアプリケーションが引き続き通常どおり実行されています。 最終的には、これら 2 つの機能のリソース使用量が機能 B をもう一度有効にするための十分な容量が確保される時点 (時間 T2) まで減少します。
自動スケールと調整のアプローチは、アプリケーションの応答性を保ち SLA に準拠させるために、組み合わせることも可能です。 需要が高いままになると予想される場合は、システムがスケールアウトしている間に、調整によって一時的な解決がなされます。この時点で、システムのすべての機能を復元できます。
次の図は、システムで実行しているすべてのアプリケーションが使用する全体的なリソース使用量の領域グラフを時系列で示しており、調整と自動スケールをどのように組み合わせることができるかを説明しています。
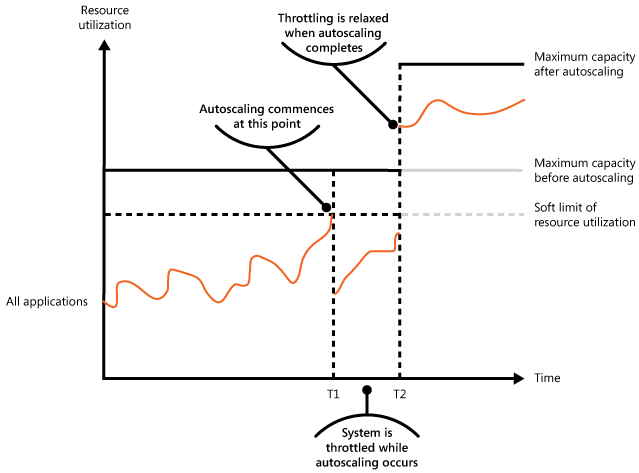
時間 T1 の時点で、リソース使用のソフト制限を指定するしきい値に達しています。 この時点で、システムはスケールアウトを開始できます。ただし、新しいリソースが使用できる状態になるのが間に合わなければ、既存のリソースを使い果たすか、システムに障害が発生するおそれがあります。 この問題の発生を防ぐために、前述のとおりにシステムは一時的に調整されます。 自動スケールが完了して追加のリソースが使用可能になると、調整が緩和されます。
問題と注意事項
このパターンの実装方法を決めるときには、以下の点に注意してください。
アプリケーションの調整と使用する戦略は、システムの設計全体に影響を与えるアーキテクチャ上の決定です。 システムが実装された後にスロットル制御を追加することは容易ではないため、アプリケーション設計の早い段階でスロットル制御について検討する必要があります。
調整は迅速に実行する必要があります。 システムは、アクティビティの増加を検出して、それに対応できる必要があります。 システムは、負荷が緩和されたらすぐ元の状態に戻ることができる必要もあります。 そのためには、適切なパフォーマンス データが継続的にキャプチャされ、監視されていることが必要です。
サービスがユーザー要求を一時的に拒否する必要がある場合は、拒否の理由がスロットリングによるものであることをクライアント アプリケーションが理解できるように、429 ("要求が多すぎます") や 503 ("サーバーがビジー") などの特定のエラー コードを返す必要があります。
- HTTP 429 は、呼び出し元アプリケーションが時間枠内で送信した要求が多すぎて、事前に定義された制限を超えたことを示します。
- HTTP 503 は、サービスが要求を処理する準備ができていないことを示します。 一般的な原因は、サービスで一時的な負荷スパイクが予想よりも多く発生していることです。
クライアント アプリケーションは、要求を再試行するまでの間、待機することができます。 クライアントが再試行戦略を選択するのをサポートするために、Retry-After HTTP ヘッダーを含める必要があります。
システムが自動スケールしている間、一時的な措置としてスロットリングを使用することができます。 場合によっては、アクティビティのバーストが突然発生し、実行コストが大幅に増加する可能性があるため、アクティビティのバーストが続くと予想されない場合は、スケーリングではなくスロットルすることをお勧めします。
システムが自動スケールしている間に一時的な措置として調整を使用する場合、また、リソースの需要が急激に増加する場合は、調整モードで運用されていたとしても、システムの正常な動作を継続できない場合があります。 これを許容できない場合は、より大きな予備容量を維持することと、よりアグレッシブな自動スケールを構成することを検討してください。
通常、操作が異なると実行コストも異なるため、さまざまな操作のリソース コストを正規化します。 たとえば、読み取り操作の場合はスロットリングの制限が低く、書き込み操作の場合は高くなる場合があります。 操作のコストを考慮しないと、容量が使い果たされ、潜在的な攻撃ベクトルが明らかになる可能性があります。
実行時にスロットリング動作の構成を動的に変更することが望ましいです。 適用された構成で処理できない異常な負荷にシステムが直面した場合、システムを安定させ、現在のトラフィックに追いつくために、スロットリングの制限を増減する必要がある場合があります。 この時点では、コストが高く、リスクが高く、低速のデプロイは望ましくありません。 外部構成ストア パターンスロットリング構成の使用は外部化されており、デプロイなしで変更および適用できます。
このパターンを使用する状況
このパターンは次の目的で使用します。
システムがサービス レベルの目標 (SLO) を満たし続けられるようにするため。
単一のテナントが、アプリケーションによって提供されるリソースを占有することを防止する。
アクティビティの急増に対応する。
システムの正常な動作を継続するのに必要な、リソースの最大レベルを制限することで、システムのコスト最適化に役立てる。
エネルギー グリッド内の高炭素強度の期間中に低価値のコンピューティング処理を減らす。
ワークロード設計
アーキテクトは、Azure Well-Architected Framework の柱で説明されている目標と原則に対処するために、ワークロードの設計でスロットリングパターンをどのように使用できるかを評価する必要があります。 次に例を示します。
| 柱 | このパターンが柱の目標をサポートする方法 |
|---|---|
| 信頼性 設計の決定により、ワークロードが 誤動作 に対して復元力を持ち、障害発生後も完全に機能する状態に 回復 することができます。 | 誤動作を引き起こす可能性のあるリソース不足の発生を防ぐために、制限を設計します。 このパターンをグレースフル デグラデーション プランの制御メカニズムとして使用することもできます。 - RE:07 自己保護 |
| セキュリティ設計の決定により、ワークロードのデータとシステムの機密性、整合性、および可用性が確保されます。 | 自動処理によるシステムの不正使用が原因でリソース不足が発生するのを防ぐために、制限を設計できます。 - SE:06 ネットワーク制御 - SE:08 リソースの強化 |
| コスト最適化は、ワークロードの投資収益率の維持と改善に重点を置いています。 | 適用される制限により、コスト モデルに情報を提供できます。制限をアプリケーションのビジネス モデルに直接関連付けることもできます。 また、使用率に明確な上限が設けられるため、それを考慮に入れてリソースのサイズを設定できます。 - CO:02 コスト モデル - CO:12 スケーリング コスト |
| パフォーマンスの効率化 は、スケーリング、データ、コードを最適化することによって、ワークロードが 効率的にニーズを満たす のに役立ちます。 | システムが高需要下にある場合、このパターンは、パフォーマンスのボトルネックとなる可能性のある輻輳を軽減するために役立ちます。 また、うるさい隣人のシナリオを事前に回避するためにも使用できます。 - PE:02 容量計画 - PE:05 スケーリングとパーティショニング |
設計決定と同様に、このパターンで導入される可能性のある他の柱の目標とのトレードオフを考慮してください。
例
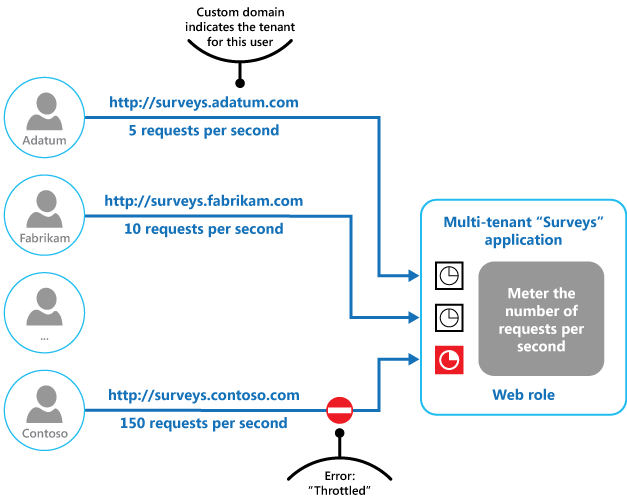
最終図は、マルチテナントシステムでスロットリングを実装する方法であることを示します。 各テナント組織のユーザーが、クラウドでホストされているアプリケーションにアクセスし、アンケートに記入して送信します。 このアプリケーションには、これらのユーザーがアプリケーションに要求を送信する頻度を監視するインストルメンテーションが含まれています。
1 つのテナントのユーザーが、他のすべてのユーザーに対するアプリケーションの応答性と可用性に影響を与えることを防止するため、ユーザーが 1 つのテナントから送信できる 1 秒あたりの要求数を制限します。 このアプリケーションは、制限を超える要求をブロックします。
次のステップ
このパターンを実装する場合は、次のガイダンスも関連している可能性があります。
- インストルメンテーションとテレメトリーガイダンス。 調整は、サービスの使用状況に関する情報収集に依存しています。 カスタムの監視情報を生成してキャプチャする方法を説明します。
- Service Metering Guidance (サービスの測定に関するガイダンス)。 サービスの使用状況を理解するために、サービスの使用量を測定する方法を説明します。 この情報は、サービスを調整する方法を決めるのに役立ちます。
- 自動スケール ガイダンス。 スロットリングは、システムが自動スケールしている間の暫定的な措置として使用されるか、または自動スケールの必要性を軽減するために使用されます。 自動スケール戦略に関する情報が含まれています。
関連リソース
このパターンを実装する場合は、次のパターンも関連している可能性があります。
- キュー ベースの負荷平準化パターン。 キュー ベースの負荷平準化は、スロットリングを実装するためによく使用されるメカニズムです。 キューは、アプリケーションから送信された要求がサービスまで届く頻度を平準化するのに役立つバッファーとして機能します。
- 優先順位キュー パターン。 システムは、調整戦略の一部として優先順位キューを使用して、比較的重要ではないアプリケーションのパフォーマンスを低下させつつ、非常に重要な、または比較的高価値のアプリケーションのパフォーマンスを維持することができます。
- 外部構成ストア パターン。 スロットリング ポリシーを一元化して外部化すると、再デプロイを必要とせずに実行時に構成を変更する機能が提供されます。 サービスは、新しい構成を直ちに適用する構成変更をサブスクライブして、システムを安定させることができます。