この記事では、開発チームでメトリックを使用してボトルネックを発見し、分散システムのパフォーマンスを向上させた方法について説明します。 この記事は、サンプル アプリケーションに対して行われた実際のロード テストに基づいています。 アプリケーションは、マイクロサービスの Azure Kubernetes Service (AKS) ベースラインからのものです。
この記事はシリーズの一部です。 最初のパートはこちらからお読みください。
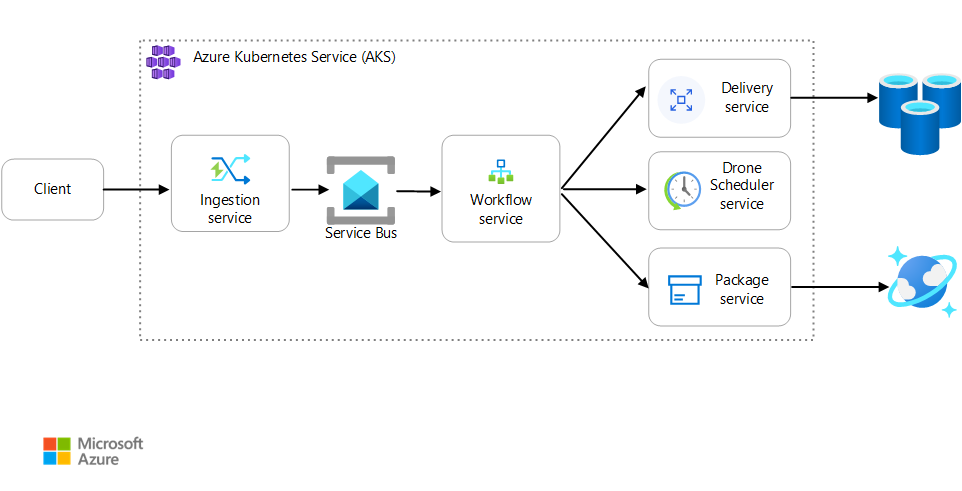
シナリオ:クライアント アプリケーションが、複数のステップからなるビジネス トランザクションを開始します。
このシナリオでは、AKS 上で実行されるドローン配達アプリケーションを扱います。 顧客は Web アプリを使用してドローンによる配達をスケジュールします。 各トランザクションには、バックエンドで個別のマイクロサービスによって実行される複数のステップが必要です。
- Delivery サービスは配達を管理します。
- Drone Scheduler サービスは集荷用のドローンをスケジュールします。
- Package サービスは荷物を管理します。
他にも 2 つのサービスがあります。クライアント要求を受け付けて処理キューに入れる Ingestion サービスと、ワークフローのステップを調整する Workflow サービスです。
このシナリオの詳細については、「マイクロサービス アーキテクチャの設計」を参照してください。
テスト 1:ベースライン
最初のロード テストでは、チームは 6 ノードの AKS クラスターを作成し、各マイクロサービスの 3 つのレプリカをデプロイしました。 このロード テストは、2 人のシミュレートされたユーザーから開始してユーザーを 40 人まで増やしていくステップロード テストでした。
| 設定 | 値 |
|---|---|
| クラスター ノード | 6 |
| ポッド | サービスあたり 3 |
次のグラフは、Visual Studio で示されるロード テストの結果を示しています。 紫色の線はユーザー負荷をプロットし、オレンジ色の線は合計要求数をプロットします。
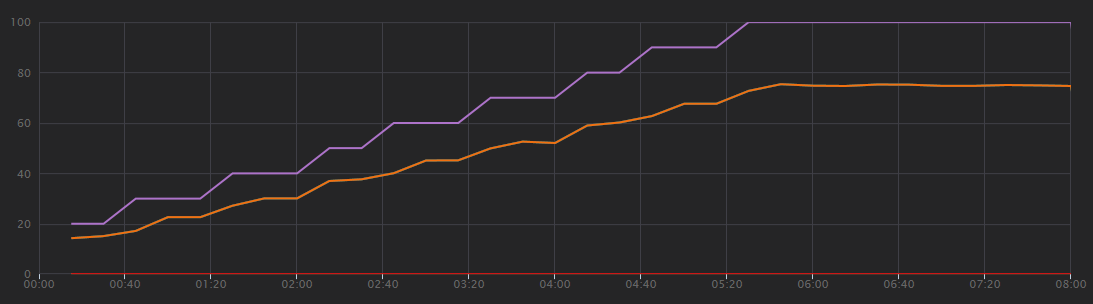
このシナリオについて最初に理解すべきことは、1 秒あたりのクライアント要求数は有用なパフォーマンス メトリックではないという点です。 それは、アプリケーションが非同期で要求を処理し、クライアントはすぐに応答を得るからです。 応答コードは常に HTTP 202 (Accepted) で、これは、要求は受理されたが処理が完了していないという意味です。
本当に知りたいのは、バックエンドが要求のレートに追いついているかどうかです。 Service Bus キューは急増を吸収できますが、バックエンドが持続的な負荷を処理できない場合、処理はますます遅れます。
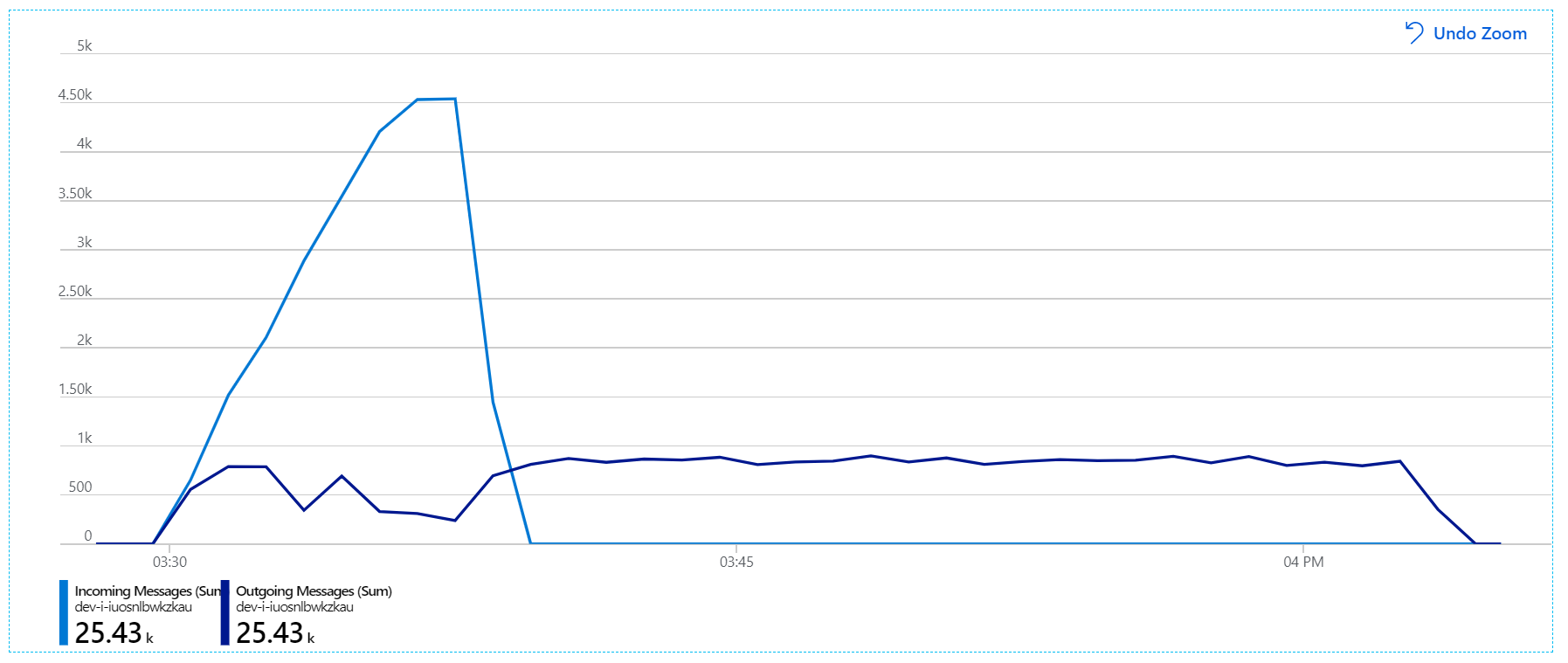
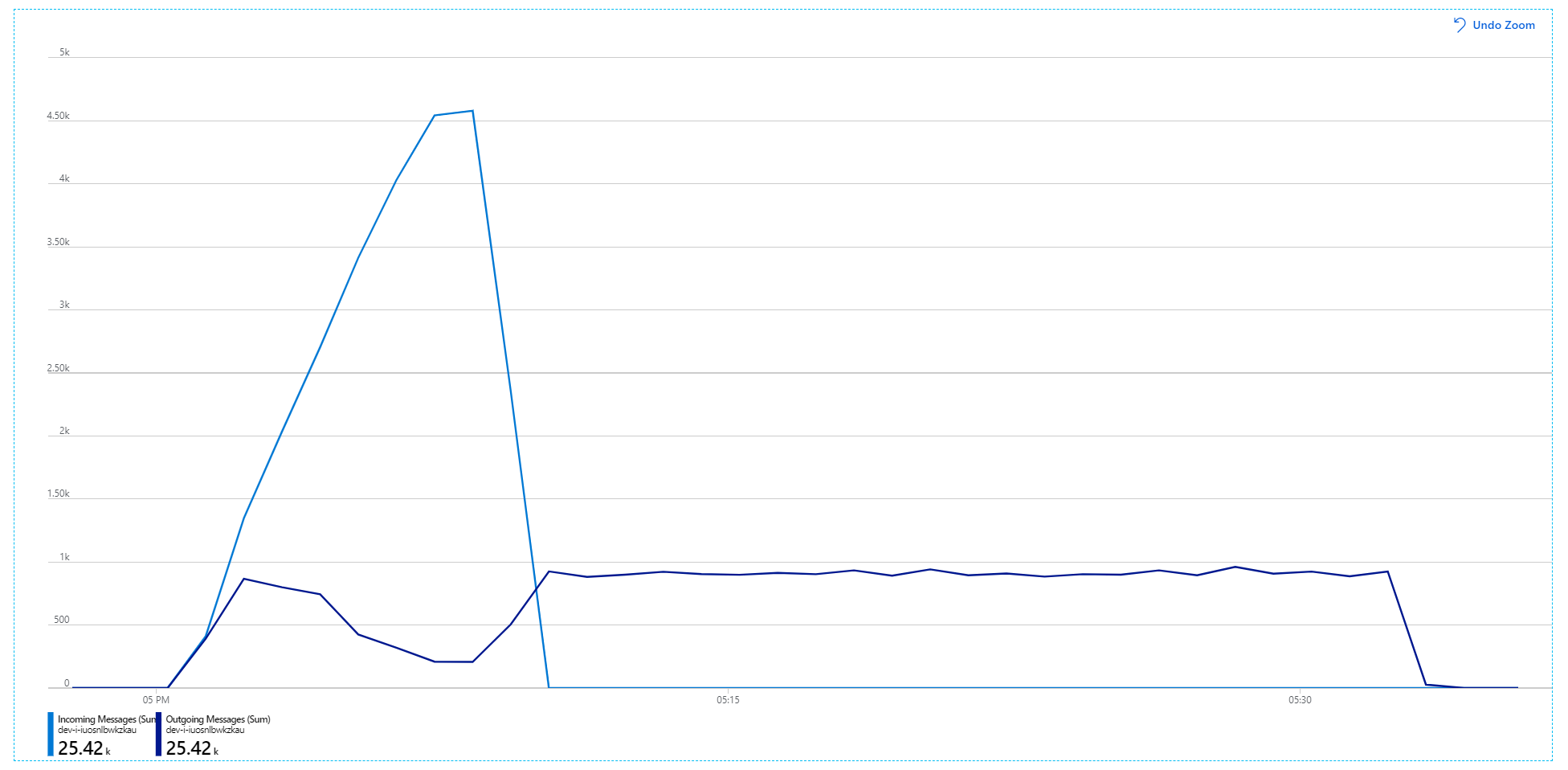
より有益なグラフを次に示します。 これは、Service Bus キューの受信メッセージと送信メッセージの数をプロットしたものです。 受信メッセージは薄い青色で、送信メッセージは濃い青色で示されています。
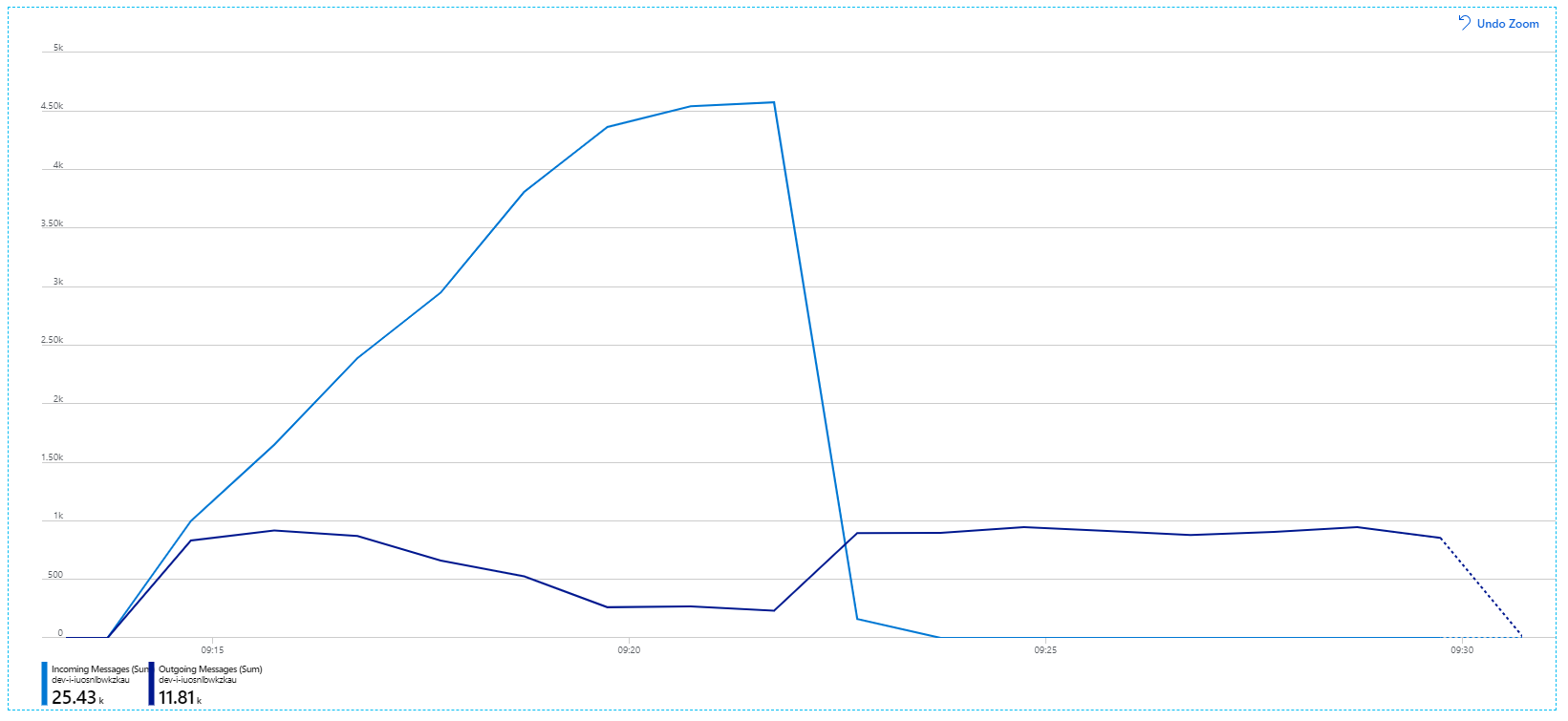
このグラフは、受信メッセージのレートが上昇してピークに達した後、ロード テストの終了時には再びゼロまで低下することを示しています。 一方、送信メッセージの数はテストの早い段階でピークに達し、その後は実際に低下します。 つまり、要求を処理する Workflow サービスが追いついていません。 ロード テストが終了 (グラフの 9:22 前後) した後も、Workflow サービスはキューを空にし続けるので、メッセージはまだ処理されています。
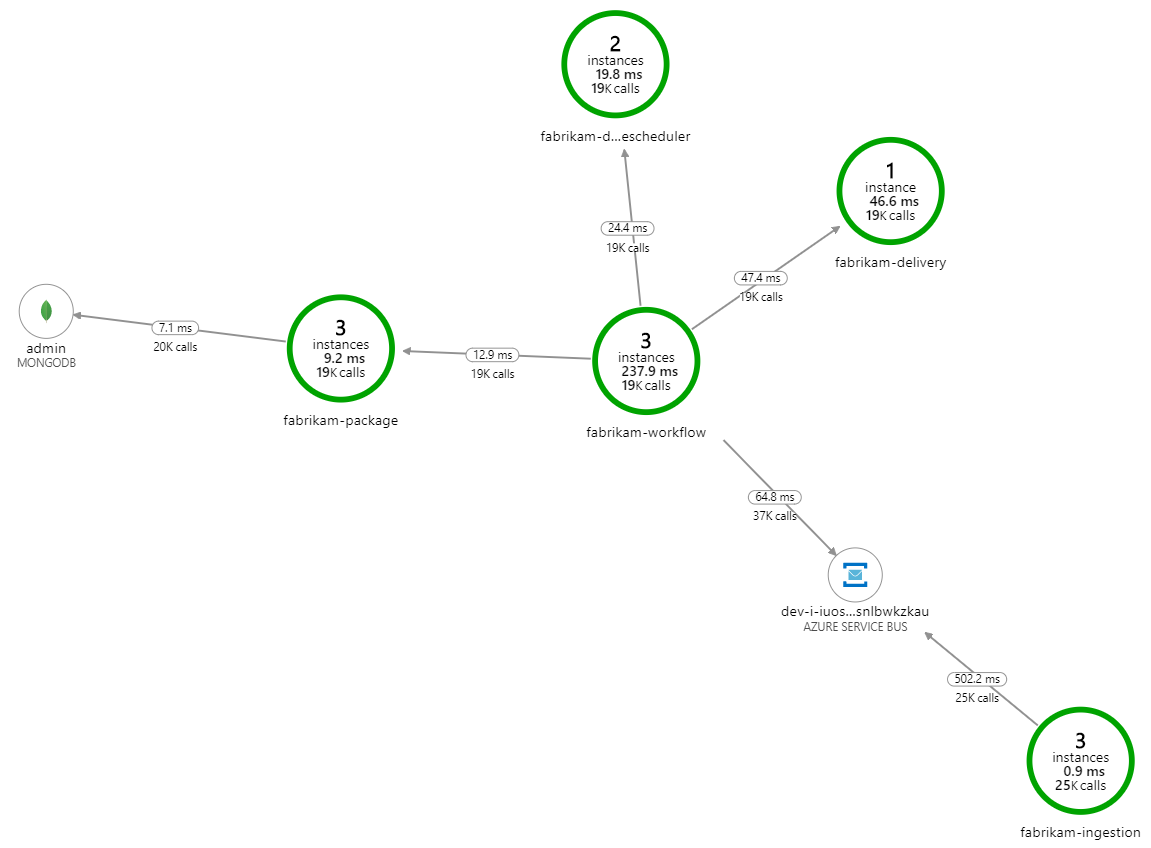
処理を遅くしている要因は何でしょうか。 最初に調べる必要があるのは、システムの問題を示すことがあるエラーまたは例外です。 Azure Monitor のアプリケーション マップには、コンポーネント間の呼び出しのグラフが表示されます。これを使用して問題をすばやく特定し、クリック操作でさらに詳細を確認することができます。
案の定、アプリケーション マップは、Workflow サービスが Delivery サービスからエラーを受け取っていることを示しています。
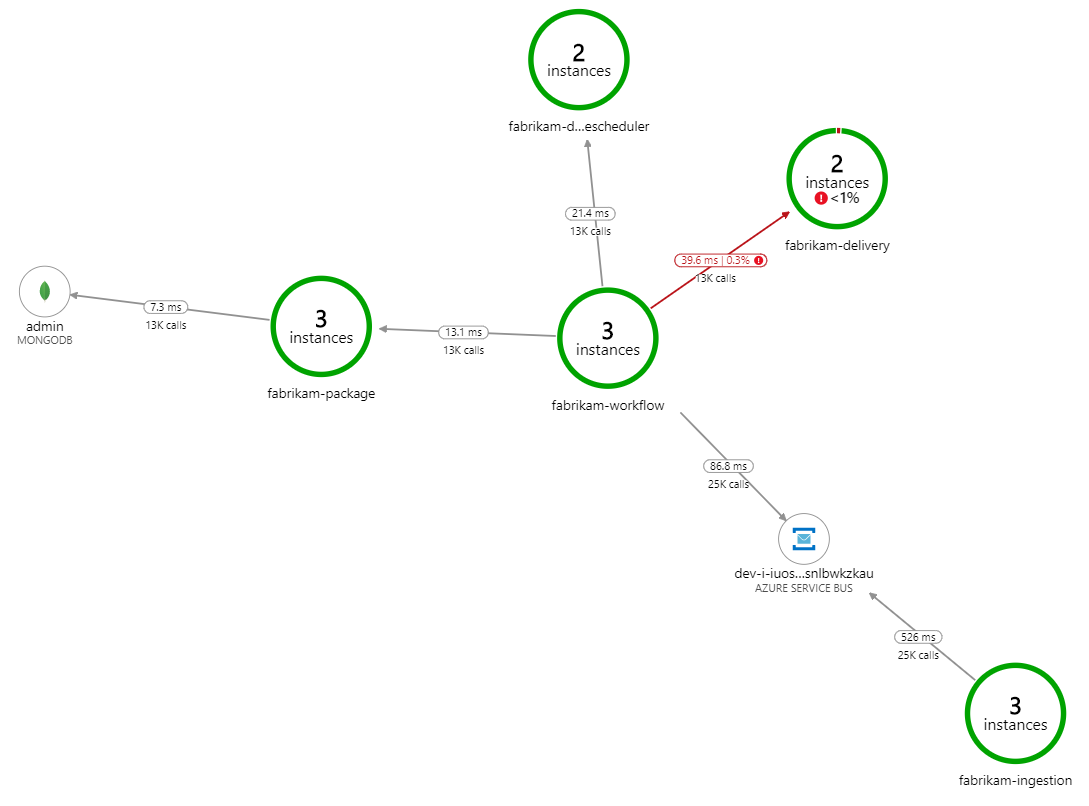
さらに詳細を見るには、グラフ内のノードを選択し、クリックしてエンドツーエンドのトランザクションのビューを表示します。 この場合、Delivery サービスが HTTP 500 エラーを返していることを示します。 このエラー メッセージは、Azure Cache for Redis のメモリ制限のため例外がスローされていることを示します。
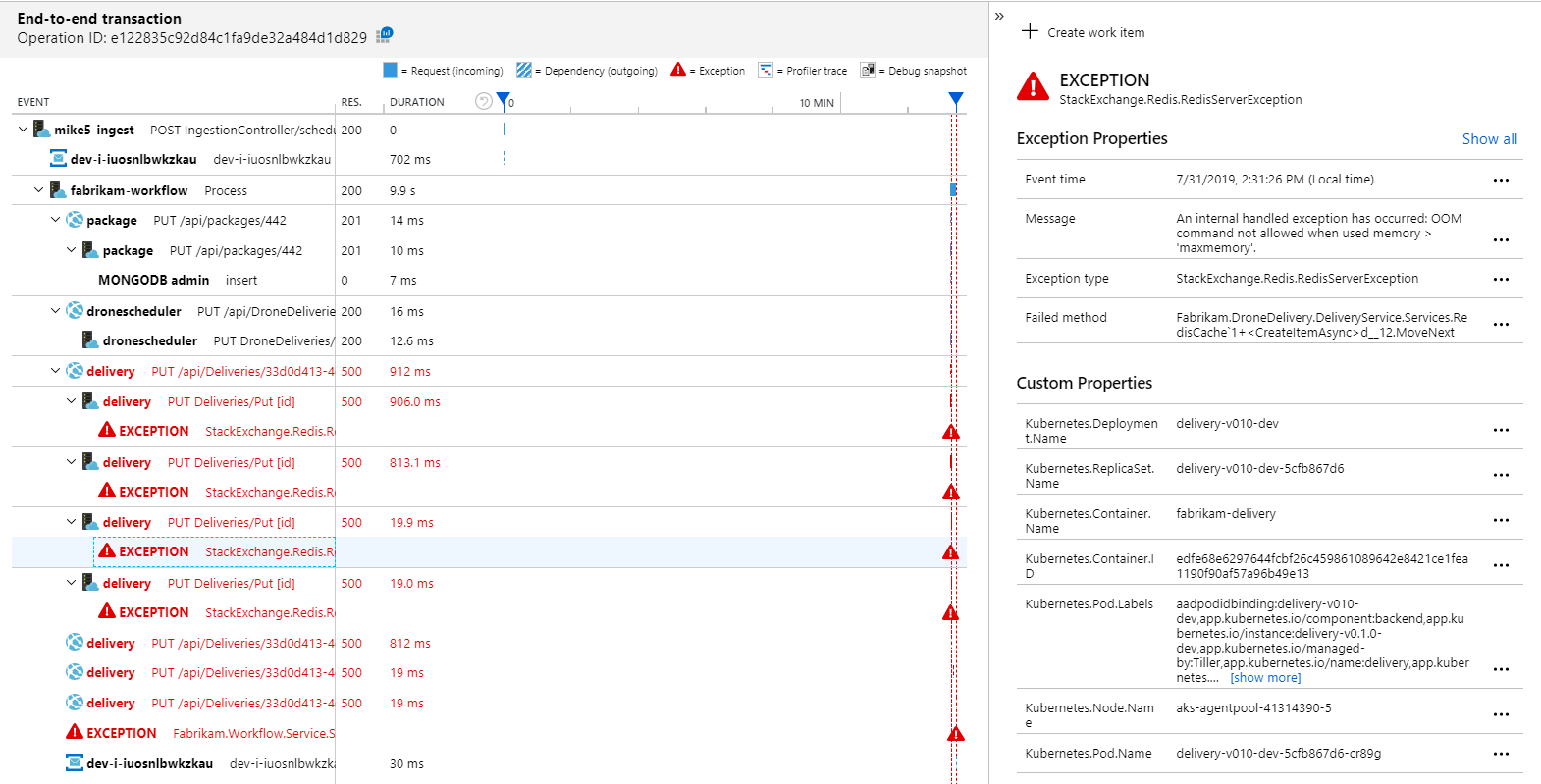
Redis に対するこれらの呼び出しがアプリケーション マップに表示されていないことにお気付きかもしれません。 これは、Application Insights の .NET ライブラリに、Redis を依存関係として追跡するためのサポートが組み込まれていないためです。 (既定でサポートされている機能の一覧については、「依存関係の自動収集」を参照してください。)代わりに、TrackDependency API を使用して依存関係を追跡することができます。 このようなテレメトリのギャップがロード テストで明らかになることはよくあり、それらは修復可能です。
テスト 2:キャッシュ サイズの引き上げ
2 回目のロード テストでは、開発チームは Azure Cache for Redis でキャッシュ サイズを増やしました。 (「Azure Cache for Redis のスケーリング方法」を参照してください。)この変更により、メモリ不足の例外が解決され、アプリケーション マップに示されるエラーが 0 個になりました。
しかし、メッセージの処理にはまだ大きなラグがあります。 ロード テストのピーク時には、受信メッセージ レートが送信レートの 5 倍を超えます。
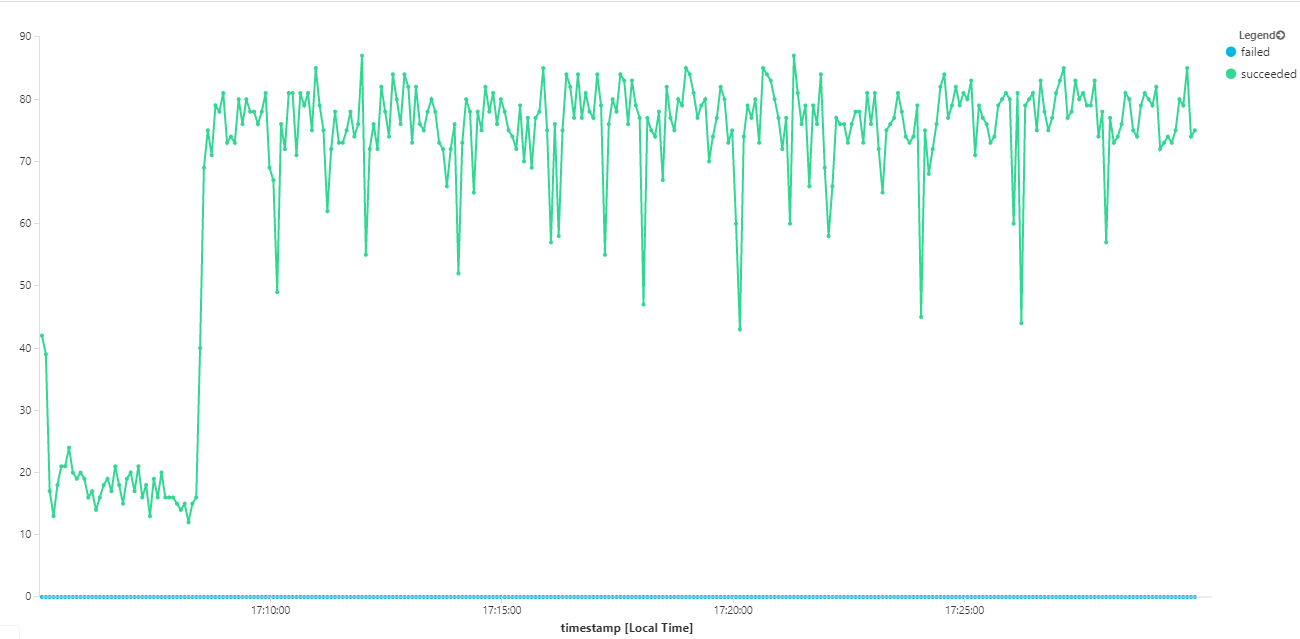
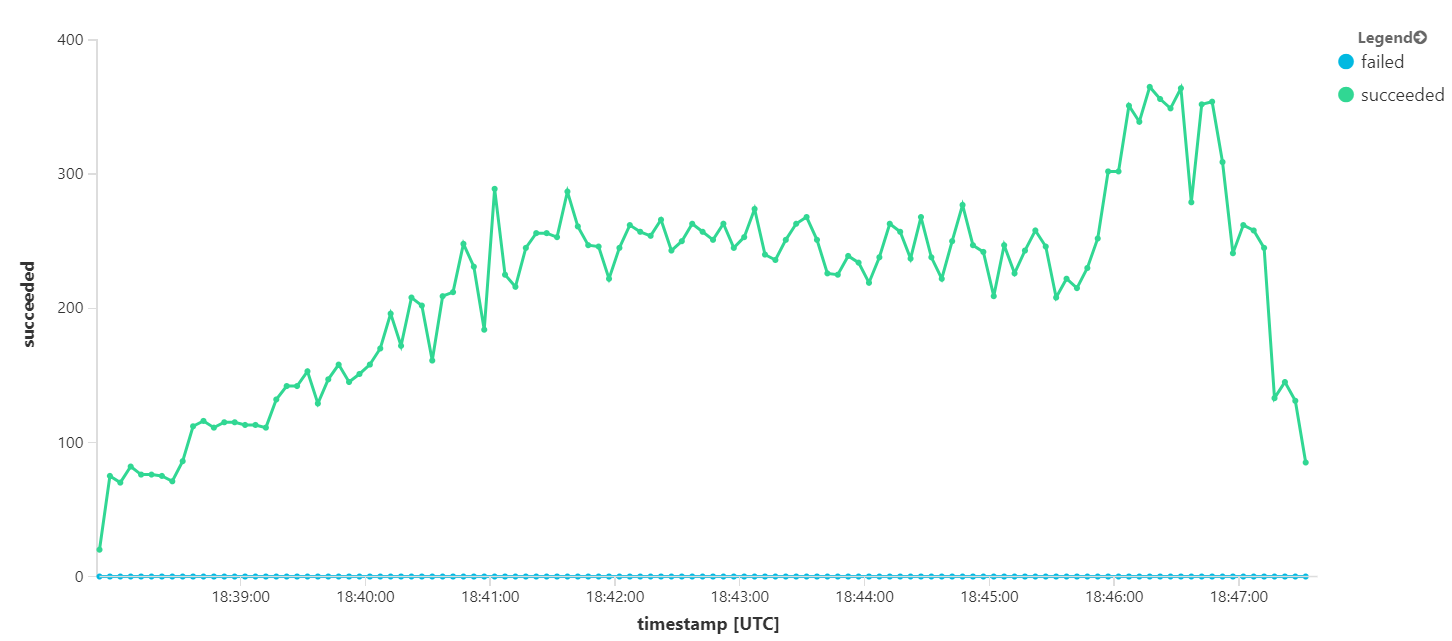
次のグラフでは、メッセージの完了の観点から、つまり、Workflow サービスが Service Bus メッセージを完了とマークする割合でスループットを計測しています。 グラフ上の各点は 5 秒分のデータを表し、1 秒あたり 16 個以下の最大スループットを示しています。
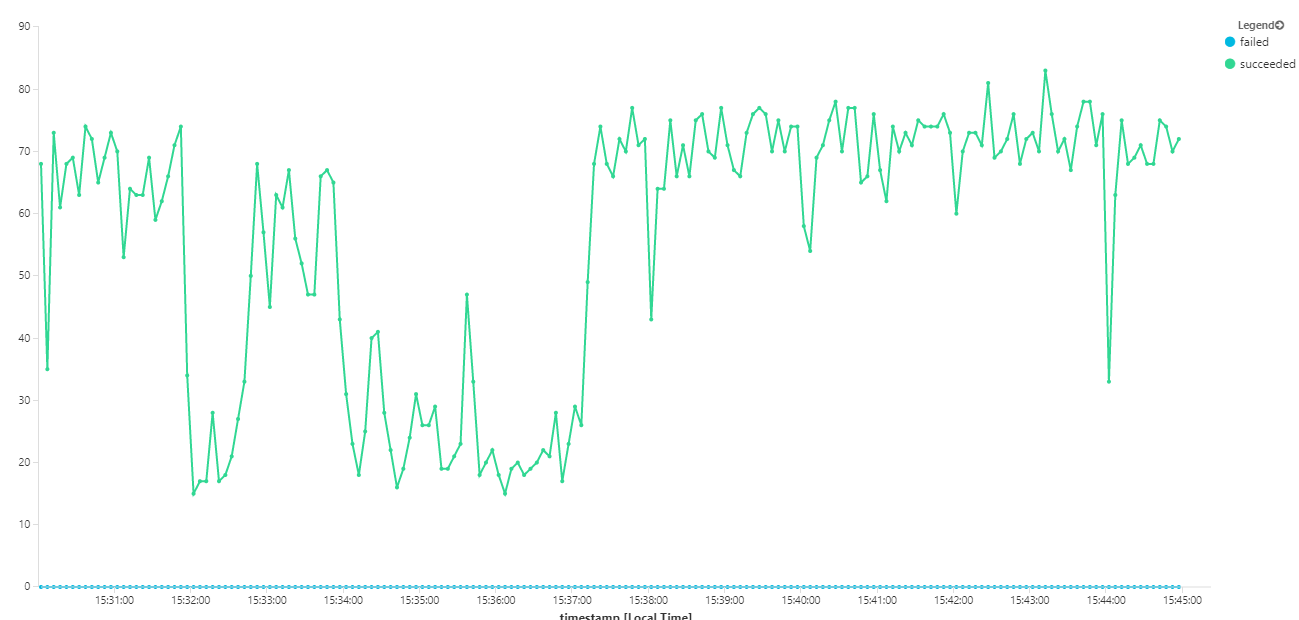
このグラフは、Kusto クエリ言語を使用して、Log Analytics ワークスペースでクエリを実行することによって生成されました。
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
テスト 3:バックエンド サービスのスケールアウト
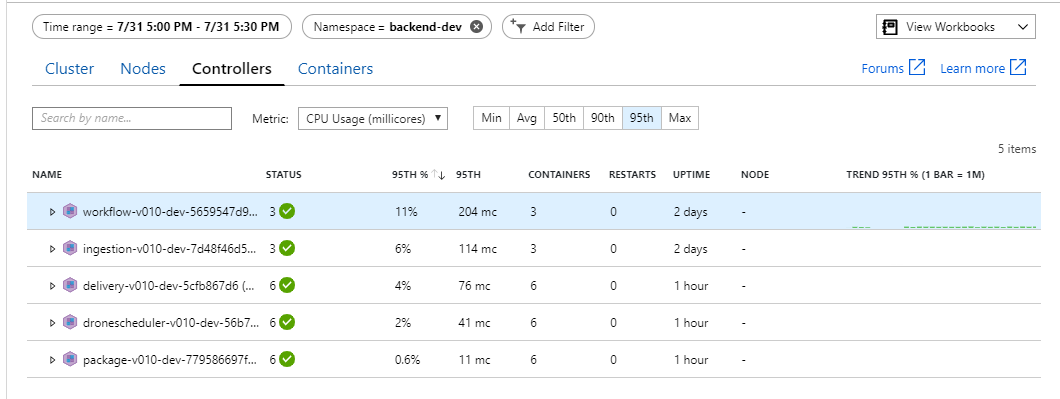
バックエンドがボトルネックのようです。 次の簡単なステップは、ビジネス サービス (Package、Delivery、および Drone Scheduler) をスケールアウトし、スループットが向上するかどうかを確認することです。 次のロード テストでは、チームはこれらのサービスを 3 つのレプリカから 6 つのレプリカにスケールアウトしました。
| 設定 | 値 |
|---|---|
| クラスター ノード | 6 |
| Ingestion サービス | 3 個のレプリカ |
| Workflow サービス | 3 個のレプリカ |
| Package、Delivery、Drone Scheduler サービス | それぞれ 6 個のレプリカ |
残念ながら、このロード テストはわずかな向上しか示していません。 送信メッセージはまだ受信メッセージに追いついていません。
スループットは少し安定しましたが、達成された最大値は前のテストとほぼ同じです。
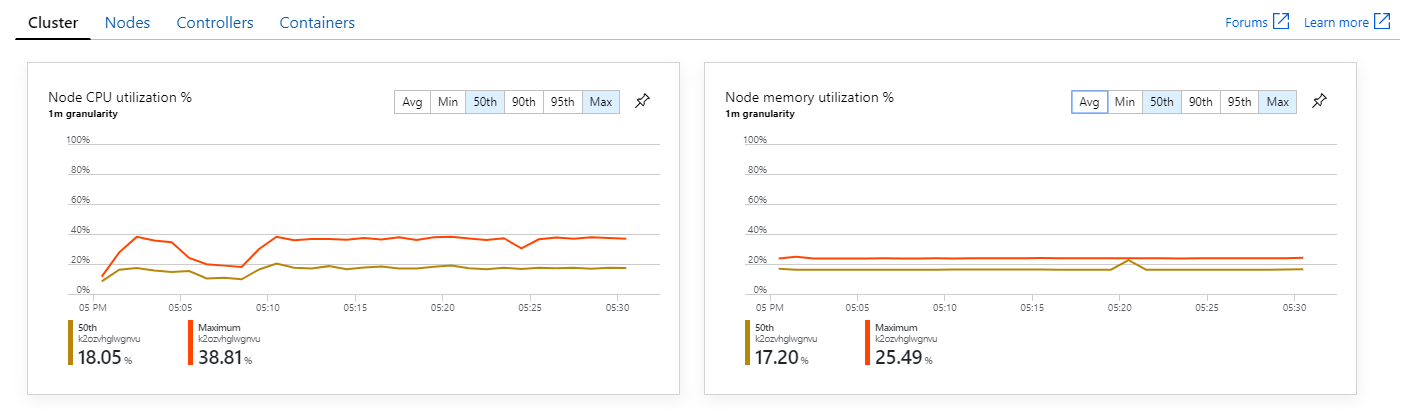
さらに、Azure Monitor Container Insights を見ると、問題の原因はクラスター内のリソースの枯渇ではなさそうです。 まず、ノードレベルのメトリックは、95 パーセンタイルでも CPU 使用率が 40% 未満にとどまり、メモリ使用率は約 20% であることを示しています。
Kubernetes 環境では、ノードが制約されない場合でも、個々のポッドがリソースに制約される可能性があります。 しかし、ポッドレベルのビューは、すべてのポッドが正常であることを示しています。
このテストの結果から、バックエンドにポッドを追加するだけでは奏功しないと考えられます。 次のステップは、Workflow サービスをさらに詳しく調べて、サービスがメッセージを処理するときに何が起きているかを理解することです。 Application Insights は、Workflow サービスの Process 操作の平均継続時間が 246 ミリ秒であることを示しています。
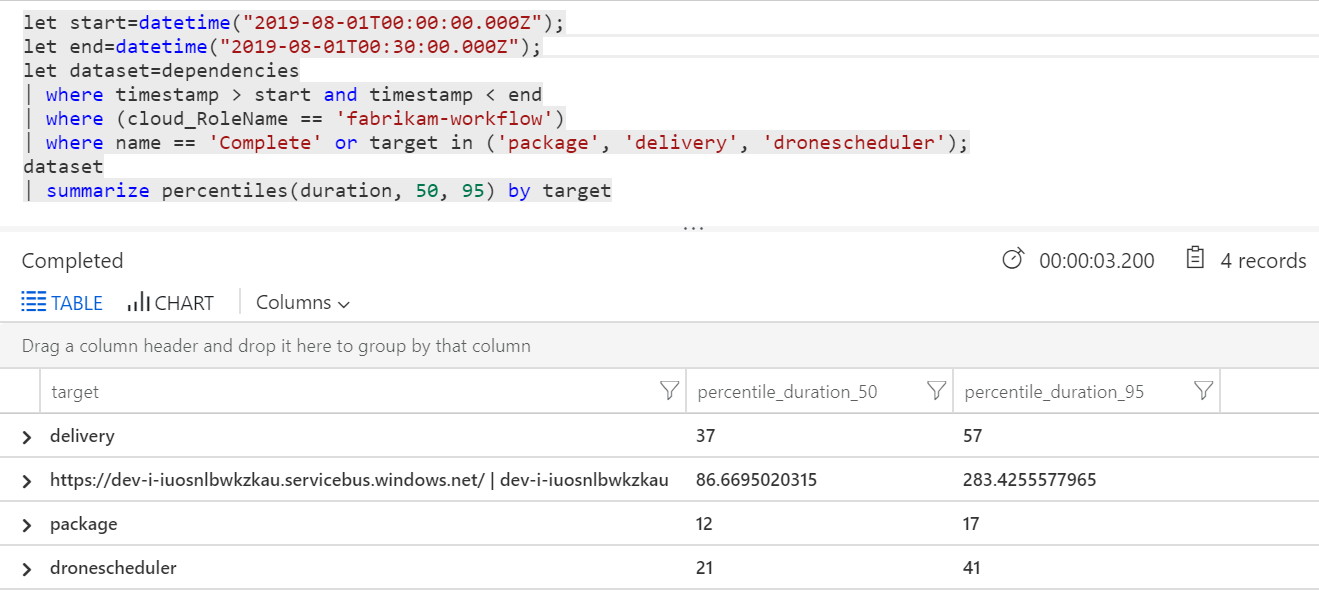
クエリを実行して、各トランザクション内の個々の操作のメトリックを取得することもできます。
| ターゲット (target) | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| 配信を使用) | 37 | 57 |
| パッケージ | 12 | 17 |
| dronescheduler | 21 | 41 |
この表の 1 行目は Service Bus キューを表しています。 他の行はバックエンド サービスの呼び出しです。 参考までに、この表に対応する Log Analytics クエリを次に示します。
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
これらの待機時間は妥当なように思われます。 しかし、次のような重要な洞察が得られます。合計操作時間が 250 ミリ秒以下の場合、メッセージを直列で処理できる速度には厳密な上限が設けられます。 したがって、スループットを向上させるための鍵は並列性の向上です。
次の 2 つの理由により、このシナリオでそのように言える可能性はあるはずです。
- これらはネットワーク呼び出しなので、ほとんどの時間は I/O 完了の待機に費やされる
- メッセージは独立していて、順番に処理する必要はない
テスト 4:並列性の向上
このテストでは、チームは並列性の向上に焦点を絞りました。 その目的のために、Workflow サービスによって使用される Service Bus クライアント上で 2 つの設定を調整しました。
| 設定 | 説明 | Default | 新しい値 |
|---|---|---|---|
MaxConcurrentCalls |
同時に処理するメッセージの最大数。 | 1 | 20 |
PrefetchCount |
クライアントが事前にそのローカル キャッシュにフェッチするメッセージの数。 | 0 | 3000 |
これらの設定の詳細については、「Service Bus メッセージングを使用したパフォーマンス向上のためのベスト プラクティス」を参照してください。 上記の設定でテストを実行すると、次のグラフが生成されました。
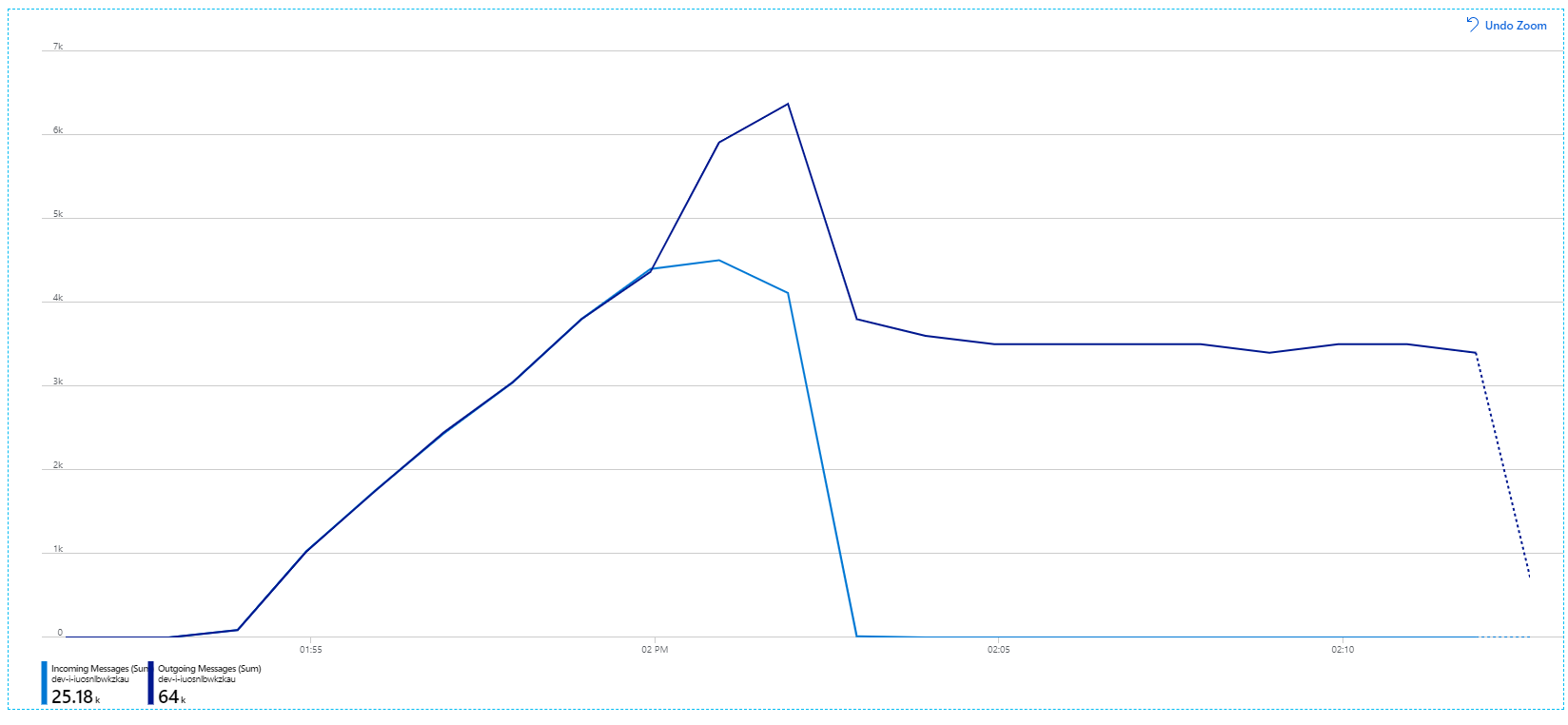
受信メッセージは薄い青色で、送信メッセージは濃い青色で示されていることを思い出してください。
一見すると、これはかなり奇妙なグラフです。 しばらくの間、送信メッセージのレートは受信レートをぴったり追跡します。 しかし、2:03 のあたりから、受信メッセージのレートが横ばいになる一方、送信メッセージの数は上昇し続けて、実際に受信メッセージの合計数を上回ります。 それは不可能なように思われます。
この謎を解く鍵は Application Insights の [依存関係] ビューにあります。 このグラフは、Workflow サービスが Service Bus に対して行ったすべての呼び出しをまとめたものです。
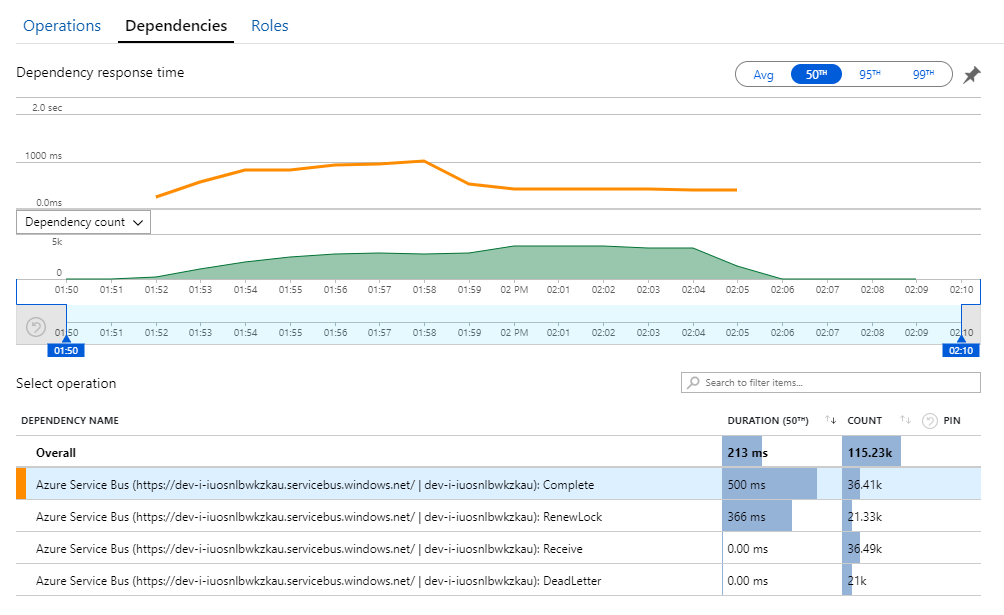
DeadLetter のエントリに注目してください。 その呼び出しは、メッセージが Service Bus の配信不能キューに入ろうとしていることを示します。
何が起きているか理解するには、Service Bus の Peek-Lock セマンティクスを理解する必要があります。 クライアントが Peek-Lock を使用するとき、Service Bus はアトミックにメッセージを取得してロックします。 ロックが保持されている間、メッセージは他の受信者に配信されないことが保証されます。 ロックの期限が切れると、他の受信者がメッセージを処理できるようになります。 (構成可能な) 最大回数の配信試行後、Service Bus によってメッセージが配信不能キューに移動され、後で確認できるようになります。
Workflow サービスが大量のメッセージ (一度に 3000 メッセージ) をプリフェッチしていることに注意してください。 それが意味するのは、個々のメッセージを処理するための合計時間がさらに長くなり、結果としてメッセージがタイムアウトになり、キューに戻り、最終的には配信不能キューに行き着くということです。
この動作は例外においても確認することができ、そこでは無数の MessageLostLockException が記録されています。
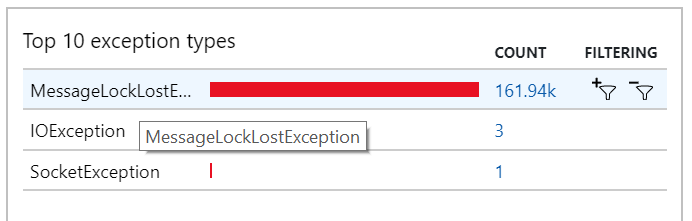
テスト 5:ロック期間を長くする
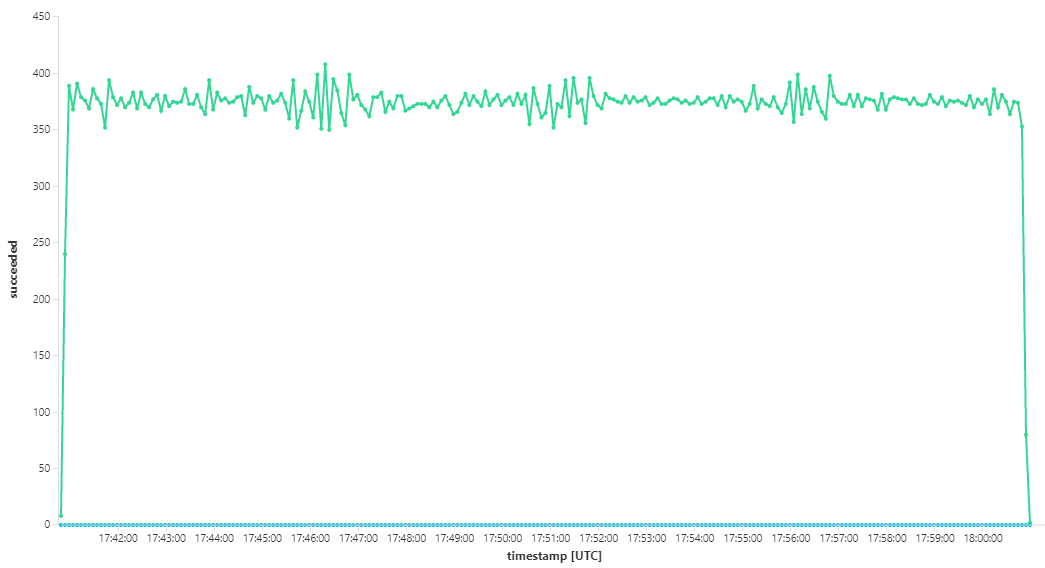
このロード テストでは、ロック タイムアウトを防ぐために、メッセージのロック期間を 5 分に設定しました。 受信および送信メッセージのグラフは、システムが受信メッセージの速度に追いついていることを示しています。
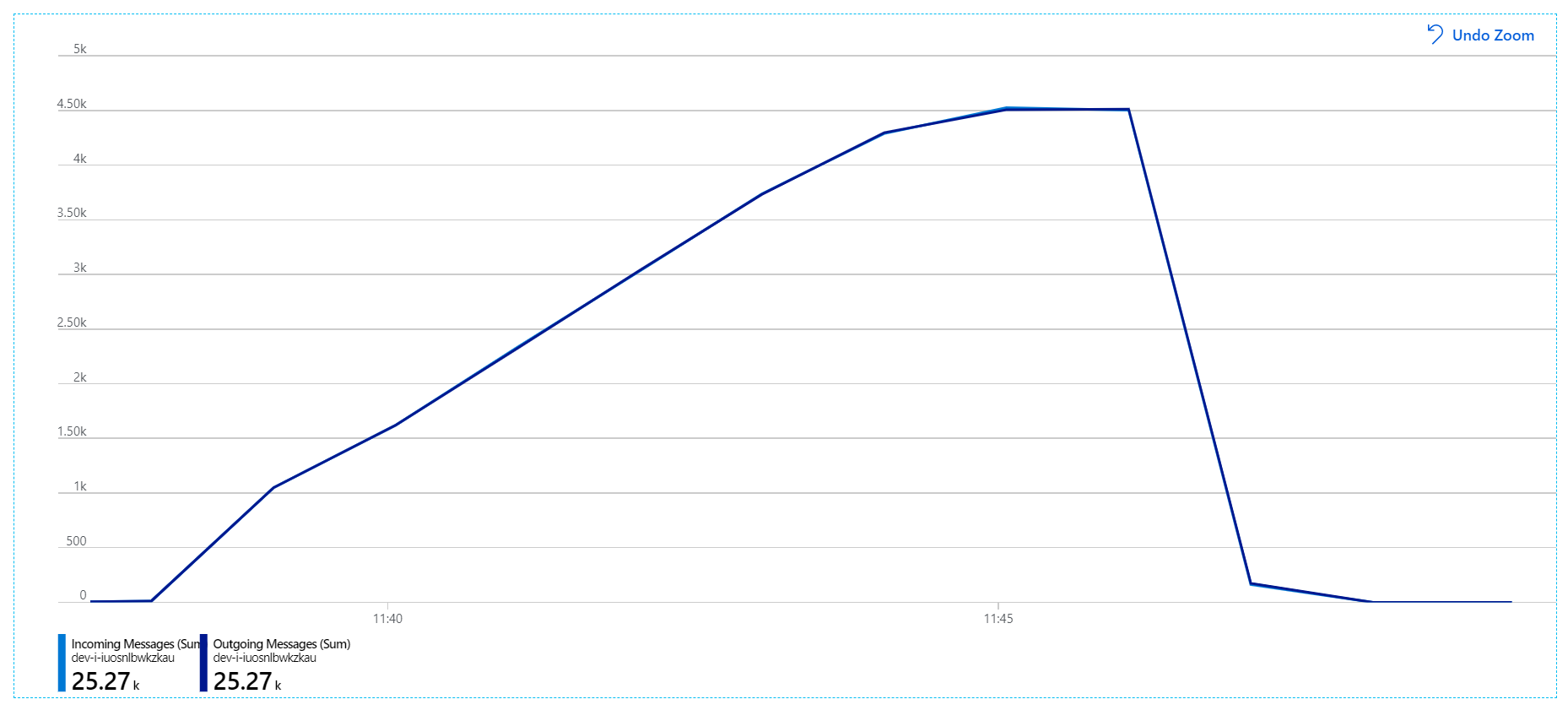
8 分間のロード テストの期間全体で、アプリケーションは 25,000 操作を完了し、ピーク スループットは 72 操作/秒で、これは 400% の最大スループット上昇を表しています。
ただし、より長期間にわたって同じテストを実行したところ、アプリケーションはこのレートを維持できないことが示されました。
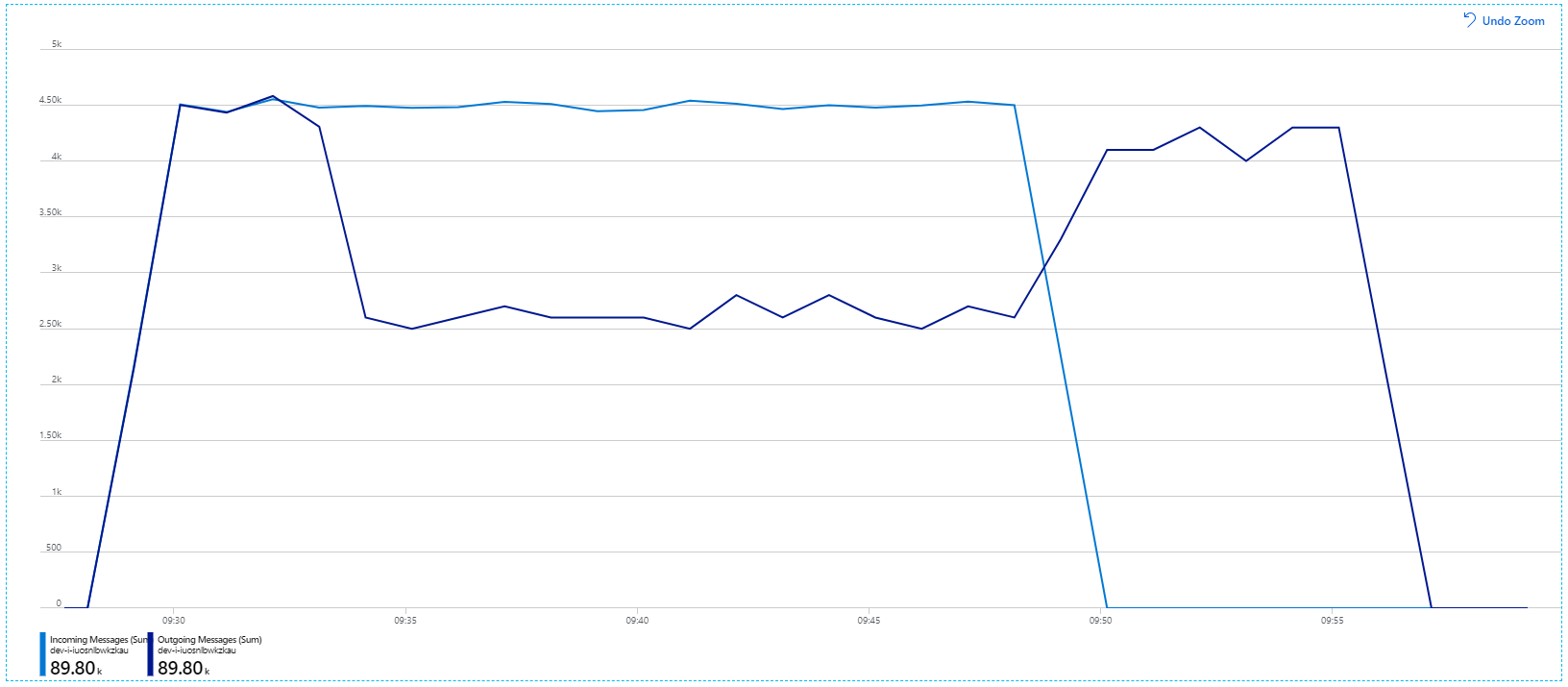
コンテナー メトリックは、最大 CPU 使用率が 100% に近いことを示しています。 この時点では、アプリケーションは CPU にバインドされているようです。 以前にスケールアウトを試みた場合とは異なり、今回は、クラスターをスケーリングすればパフォーマンスが向上する可能性があります。
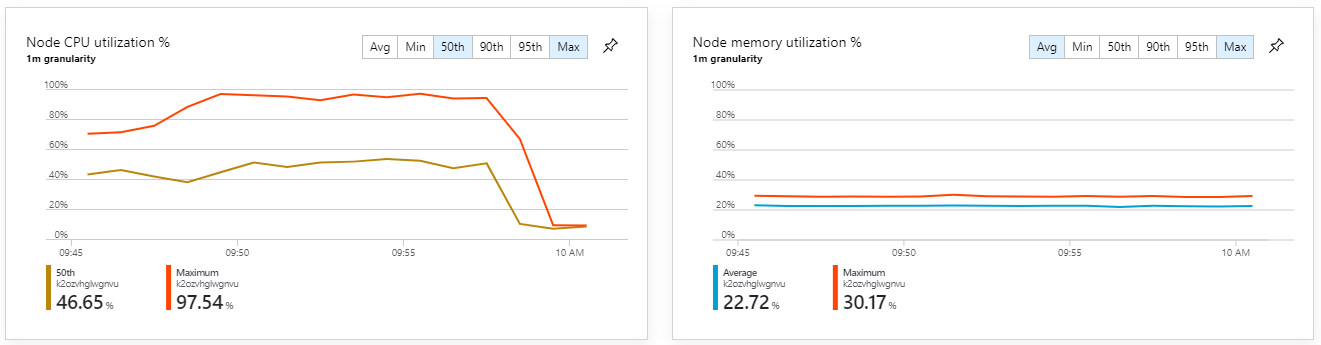
テスト 6:バックエンド サービスのスケールアウト (再度)
一連のうち最後のロード テストで、チームは Kubernetes クラスターとポッドを次のようにスケールアウトしました。
| 設定 | 値 |
|---|---|
| クラスター ノード | 12 |
| Ingestion サービス | 3 個のレプリカ |
| Workflow サービス | 6 個のレプリカ |
| Package、Delivery、Drone Scheduler サービス | それぞれ 9 個のレプリカ |
このテストの結果としては、スループットの持続性が向上し、メッセージの処理に大きなラグはありませんでした。 さらに、ノードの CPU 使用率は 80% 未満を維持しました。
まとめ
このシナリオでは、次のボトルネックが特定されました。
- Azure Cache for Redis でのメモリ不足例外。
- メッセージ処理での並列性の不足。
- メッセージのロック期間が不十分なためロック タイムアウトが発生し、メッセージが配信不能キューに送られる。
- CPU の枯渇。
これらの問題を診断するため、開発チームは次のメトリックを利用しました。
- 受信および送信 Service Bus メッセージのレート。
- Application Insights のアプリケーション マップ。
- エラーと例外。
- カスタムの Log Analytics クエリ。
- Azure Monitor Container Insights での CPU およびメモリ使用率。
次のステップ
このシナリオの設計の詳細については、「マイクロサービス アーキテクチャの設計」を参照してください。