このチュートリアルでは、基本的なベクター類似性検索のユース ケースについて説明します。 Azure OpenAI Service によって生成された埋め込みと Azure Managed Redis の組み込みのベクター検索機能を使用して、映画のデータセットに対してクエリを実行し、最も関連性の高い一致を見つけます。
このチュートリアルでは、Wikipedia Movie Plots データセットを使用します。これには、Wikipedia にある、1901 年から 2017 年までの 35,000 本を超える映画のプロットの説明が掲載されています。 このデータセットには、各映画のプロットの要約に加えて、映画が公開された年、監督、メイン キャスト、ジャンルなどのメタデータが含まれています。 チュートリアルの手順に従って、プロットの概要に基づいて埋め込みを生成し、他のメタデータを使用してハイブリッド クエリを実行します。
このチュートリアルでは、以下の内容を学習します。
- ベクター検索用に構成された Azure Managed Redis インスタンスを作成する
- Azure OpenAI とその他の必要な Python ライブラリをインストールする。
- 映画データセットをダウンロードし、分析のための準備を行う。
- text-embedding-ada-002 (バージョン 2) モデルを使用して埋め込みを生成する。
- Azure Managed Redis でベクター インデックスを作成する
- コサインの類似度を用いて検索結果を優先度付けします。
- RediSearch によるハイブリッド クエリ機能を使用してデータを事前フィルター処理し、ベクトル検索をさらに強力にします。
Von Bedeutung
このチュートリアルでは、Jupyter Notebook の構築について説明します。 Python コード ファイル (.py) を使用してこのチュートリアルに従うと、"同様" の結果を得ることができますが、結果を確認するには、このチュートリアルのすべてのコード ブロックを .py ファイルに追加し、1 回実行する必要があります。 つまり、セルを実行すると、Jupyter Notebook に中間結果が提供されますが、これは Python コード ファイルで作業するときに予期される動作ではありません。
Von Bedeutung
代わりに完成した Jupyter Notebook で作業を進める場合は、tutorial.ipynb という名前の Jupyter ノートブック ファイルをダウンロードし、新しい redis-vector フォルダーに保存します。
[前提条件]
- Azure サブスクリプション - 無料アカウントを作成します
- 目的の Azure サブスクリプション内の Azure OpenAI に付与されたアクセス権。 現時点では、Azure OpenAI へのアクセスを申請する必要があります。 Azure OpenAI へのアクセスを申請するには、https://aka.ms/oai/access のフォームに入力してください。 <--わからない場合
- Python 3.8 以降のバージョン
- Jupyter Notebook (オプション)
- text-embedding-ada-002 (バージョン 2) モデルがデプロイされた Azure OpenAI リソース。 このモデルは現在、特定のリージョンでのみ使用できます。 モデルをデプロイする手順については、リソースのデプロイ ガイドを参照してください。
Azure Managed Redis インスタンスを作成する
「クイック スタート: Azure Managed Redis Instance の作成」ガイドに従ってキャッシュを作成しますが、作成時に RedisSearch モジュールを必ず追加してください。
[詳細] ページで、RediSearch を追加していること、およびエンタープライズ クラスター ポリシーを選択していることを確認します。 他のすべての設定は、クイックスタートで説明されている既定値にすることができます。
キャッシュが作成されるまで数分かかります。 この間、次の手順に進むことができます。
開発環境を設定する
ローカル コンピューター上の通常プロジェクトを保存する場所に redis-vector という名前のフォルダーを作成します。
フォルダー内に新しい Python ファイル (tutorial.py) または Jupyter ノートブック (tutorial.ipynb) を作成します。
必要な Python パッケージをインストールします。
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
データセットをダウンロードする
Web ブラウザーで、https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots に移動します。
Kaggle にサインインするか、登録します。 ファイルをダウンロードするには、登録する必要があります。
Kaggle で [ダウンロード] リンクを選んで、archive.zip ファイルをダウンロードします。
archive.zip ファイルを抽出し、wiki_movie_plots_deduped.csv を redis-vector フォルダーに移動します。
ライブラリをインポートして接続情報を設定する
Azure OpenAI に対して正常に呼び出しを行うには、エンドポイントとキーが必要です。 また、Azure Managed Redis に接続するための エンドポイント と キー も必要です。
Azure portal で、Azure OpenAI リソースに移動します。
[リソース管理] セクションで、[エンドポイントとキー] を見つけます。 エンドポイントとアクセス キーをコピーします。これらは、API 呼び出しを認証するために両方とも必要です。 エンドポイントの例:
https://docs-test-001.openai.azure.com。KEY1またはKEY2を使用できます。Azure portal で Azure Managed Redis リソースの [概要 ] ページに移動します。 エンドポイントをコピーします。
[設定] セクションで [アクセス キー] を見つけます。 アクセス キーをコピーします。
PrimaryまたはSecondaryを使用できます。次のコードを新しいコード セルに追加します。
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"API_KEYとRESOURCE_ENDPOINTの値を、Azure OpenAI デプロイのキーとエンドポイントの値で更新します。DEPLOYMENT_NAMEは、text-embedding-ada-002 (Version 2)埋め込みモデルを使用するデプロイの名前に設定し、MODEL_NAMEは、使用する特定の埋め込みモデルにする必要があります。azure Managed Redis インスタンスのエンドポイントとキー値を使用して、
REDIS_ENDPOINTとREDIS_PASSWORDを更新します。Von Bedeutung
API キー、エンドポイント、デプロイ名の情報を渡すには、環境変数またはシークレット マネージャー (Azure Key Vault など) を使用することを強くお勧めします。 ここでは、わかりやすくするために、これらの変数をプレーンテキストで設定しています。
コード セル 2 を実行します。
データセットを pandas にインポートしてデータを処理する
次に、csv ファイルを pandas DataFrame に読み込みます。
次のコードを新しいコード セルに追加します。
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfコード セル 3 を実行します。 次の出力が表示されます。

次に、データを処理します。
idインデックスを追加し、列タイトルからスペースを削除し、映画をフィルター処理して 1970 年以降に制作された英語圏の国または地域の映画のみを取得します。 このフィルター処理のステップによって、データセット内の映画の本数が減り、埋め込みを生成するために必要なコストと時間が削減されます。 フィルター パラメーターは、必要に応じて自由に変更または削除できます。データをフィルター処理するには、次のコードを新しいコード セルに追加します。
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfコード セル 4 を実行します。 次のような結果が表示されます。

空白と句読点を削除してデータをクリーンする関数を作成し、それを、プロットを含むデータフレームに対して使用します。
次のコードを新しいコード セルに追加して実行します。
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))最後に、プロットの説明が埋め込みモデルにとって長すぎるエントリを削除します。 (つまり、8192 個の制限を超える数のトークンを必要とするもの) をすべて削除し、埋め込みの生成に必要なトークンの数を計算します。 これも埋め込み生成の価格に影響を与えます。
次のコードを新しいコード セルに追加します。
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))コード セル 6 を実行します。 あなたはこの出力を見るべきです:
Number of movies: 11125 Number of tokens required:7044844Von Bedeutung
必要なトークン数に基づいて埋め込みの生成コストを計算するには、「Azure OpenAI Service の価格」を参照してください。


DataFrame を LangChain に読み込む
DataFrameLoader クラスを使用して DataFrame を LangChain に読み込みます。 データを LangChain ドキュメントに含めると、LangChain ライブラリを使用してはるかに簡単に埋め込みを生成し、類似性検索を実行することができます。
Plotをpage_content_columnとして設定し、この列に埋め込みが生成されるようにします。
次のコードを新しいコード セルに追加して実行します。
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
埋め込みを生成して Redis に読み込む
データをフィルター処理し、LangChain に読み込んだので、埋め込みを作成して、各映画のプロットに対してクエリを実行できるようにします。 次のコードでは、Azure OpenAI を構成し、埋め込みを生成し、埋め込みベクターを Azure Managed Redis に読み込みます。
次のコードを新しいコード セルに追加します。
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")コード セル 8 を実行します。 これが完了するまで、30 分以上かかる場合があります。
redis_schema.yamlファイルも生成されます。 このファイルは、埋め込みを再生成せずに Azure Managed Redis インスタンス内のインデックスに接続する場合に便利です。
Von Bedeutung
埋め込みの生成速度は、Azure OpenAI モデルで利用できるクォータによって異なります。 クォータが 1 分あたり 240,000 トークンの場合、データ セット内の 700 万トークンを処理するには約 30 分かかります。
ベクトル検索クエリを実行する
データセット、Azure OpenAI サービス API、Redis インスタンが設定されたので、ベクトルを使用して検索することができます。 この例では、特定のクエリに対して上位 10 件の結果が返されます。
次のコードを Python コード ファイルに追加します。
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')コード セル 9 を実行します。 次の出力が表示されます。
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)類似度による映画の序数ランキングと共に類似度スコアが返されます。 より具体的なクエリの類似性スコアは、一覧の下に行くほど早く減少することに注意してください。
ハイブリッド検索
RediSearch は、ベクトル検索に加えて、豊富な検索機能も備えているため、映画のジャンル、キャスト、公開年、監督などのデータセット内のメタデータによって結果をフィルター処理することができます。 この場合は、ジャンル
comedyに基づいてフィルター処理します。次のコードを新しいコード セルに追加します。
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')コード セル 10 を実行します。 次の出力が表示されます。
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Azure Managed Redis と Azure OpenAI Service を使用すると、埋め込みとベクター検索を使用して、強力な検索機能をアプリケーションに追加できます。
リソースをクリーンアップする
この記事で作成したリソースを引き続き使用する場合は、リソース グループを保持します。
それ以外の場合、リソースを使い終わったら、課金されないように、作成した Azure リソース グループを削除できます。
Von Bedeutung
リソース グループを削除すると、元に戻すことができません。 リソース グループを削除すると、そのリソース グループ内のすべてのリソースは完全に削除されます。 間違ったリソース グループやリソースをうっかり削除しないようにしてください。 リソースを既存のリソース グループ内に作成し、そのリソース グループ内に保持したいリソースが含まれている場合は、リソース グループを削除するのではなく、各リソースを個別に削除できます。
リソース グループを削除するには
Azure portal にサインインし、 [リソース グループ] を選択します。
削除するリソース グループを選択します。
多数のリソース グループがある場合は、[任意のフィールドのフィルター...] ボックスを使用し、この記事用に作成したリソース グループの名前を入力します。 結果リストでリソース グループを選びます。
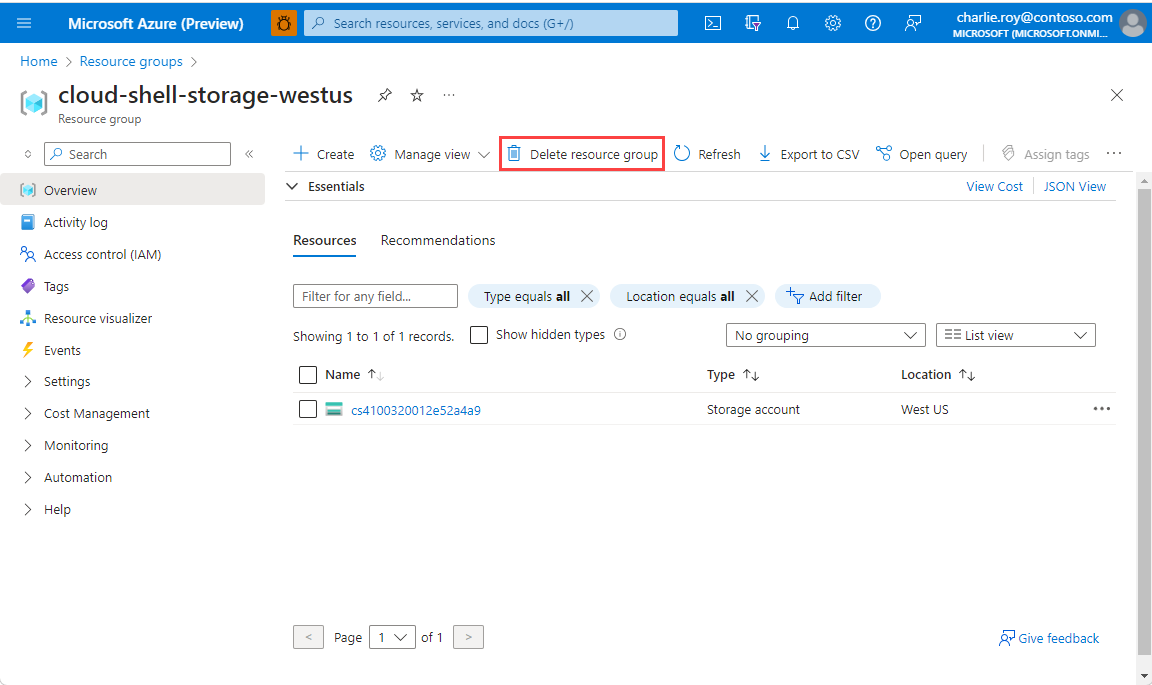
[リソース グループの削除] を選択します。
リソース グループの削除の確認を求めるメッセージが表示されます。 確認のためにリソース グループの名前を入力し、[削除] を選択します。
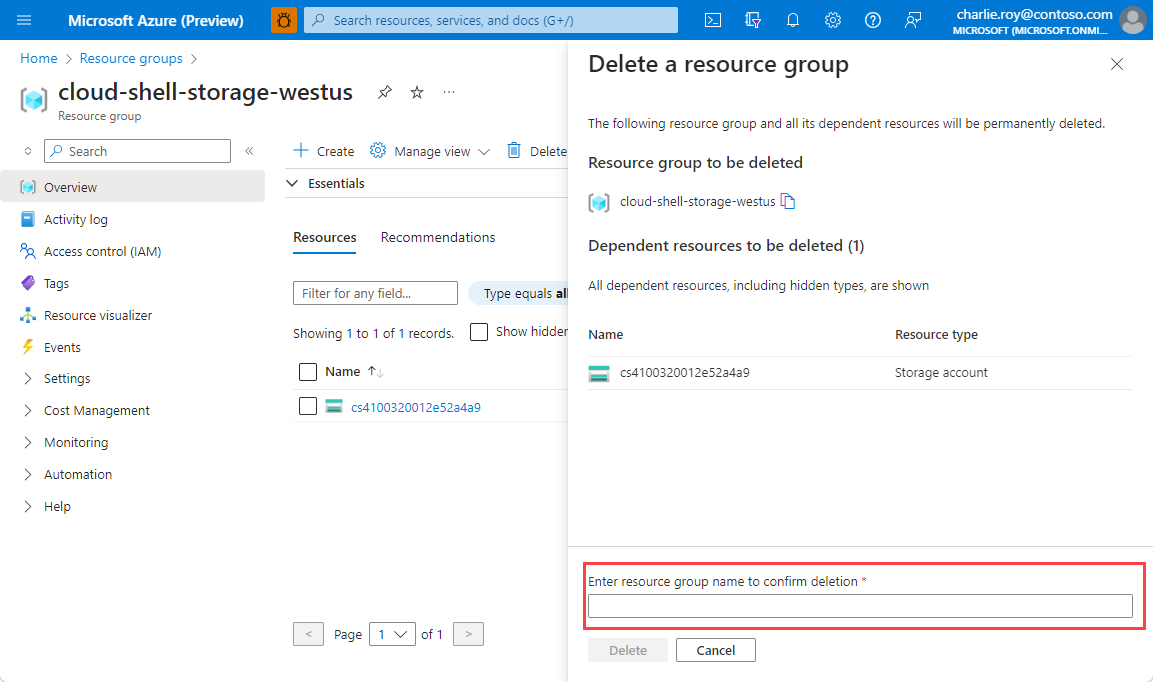
しばらくすると、リソース グループとそのリソースのすべてが削除されます。