Important
Azure SQL Edge は、2025 年 9 月 30 日の時点で廃止されます。 詳細と移行オプションについては、「廃止に関する通知」を参照してください。
注
Azure SQL Edge は ARM64 プラットフォームをサポートしなくなりました。
このチュートリアルでは、Azure Data Factory を使用し、Azure SQL Edge インスタンス内のテーブルから Azure Blob Storage にデータを増分同期する方法について説明します。
開始する前に
Azure SQL Edge デプロイでデータベースまたはテーブルをまだ作成していない場合、次のいずれかの方法で 1 つ作成してください。
SQL Server Management Studio または Azure Data Studio を使用して SQL Edge に接続します。 SQL スクリプトを実行して、データベースとテーブルを作成します。
SQL Edge モジュールに直接接続して sqlcmd を使い、データベースとテーブルを作成します。 詳細については、sqlcmd を使用したデータベース エンジンへの接続に関するページを参照してください。
SQLPackage.exe を使用して、DAC パッケージ ファイルを SQL Edge コンテナーにデプロイします。 このプロセスは、モジュールの必要なプロパティの構成の一環として SqlPackage ファイル URI を指定することで自動化できます。 また、SqlPackage.exe クライアント ツールを直接使用して DAC パッケージを SQL Edge にデプロイすることもできます。
SqlPackage.exe をダウンロードする方法については、「sqlpackage をダウンロードしてインストールする」を参照してください。 SqlPackage.exe 用のサンプル コマンドの一部を次に示します。 詳細については、SqlPackage.exe のドキュメントを参照してください。
DAC パッケージを作成する
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>DAC パッケージを適用する
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
基準値レベルを格納および更新するための SQL テーブルとプロシージャを作成する
基準値テーブルは、データが Azure Storage と同期された最終タイムスタンプを格納するために使用されます。 Transact-SQL (T-SQL) ストアド プロシージャは、同期のたびに基準値テーブルを更新するために使用されます。
SQL Edge インスタンスで次のコマンドを実行します。
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Data Factory パイプラインを作成する
このセクションでは、Azure SQL Edge 内のテーブルから Azure Blob Storage にデータを同期するための Azure Data Factory パイプラインを作成します。
Data Factory UI を使用してデータ ファクトリを作成する
このチュートリアルの手順に従って、データ ファクトリを作成します。
Data Factory パイプラインを作成する
Azure Data Factory UI の [Let's get started](始めましょう) ページで、 [パイプラインを作成] を選択します。

パイプラインの [プロパティ] ウィンドウの [全般] ページで、名前に「PeriodicSync」と入力します。
古い基準値を取得するためのルックアップ アクティビティを追加します。 [アクティビティ] ペインで [全般] を展開し、パイプライン デザイナー画面に [ルックアップ] アクティビティをドラッグします。 アクティビティの名前を OldWatermark に変更します。
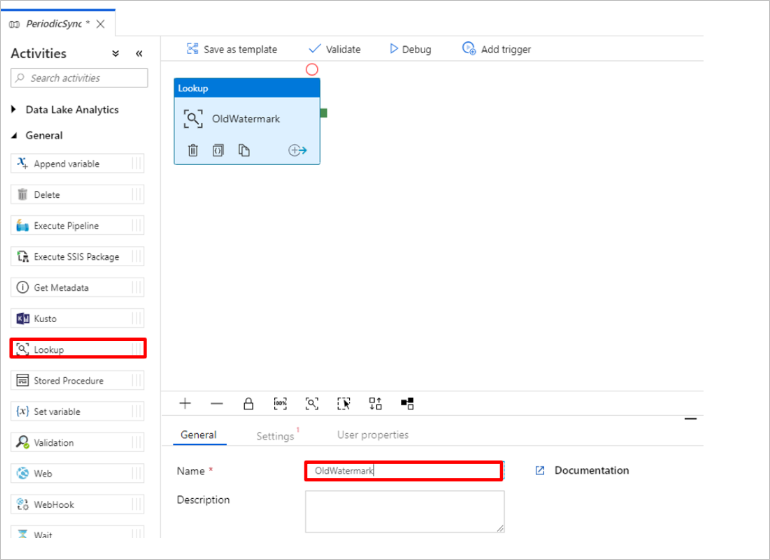
[設定] タブに切り替えて、 [Source Dataset](ソース データセット) の [新規] を選択します。 ここで、基準値テーブル内のデータを表すデータセットを作成します。 このテーブルには、前のコピー操作で使用されていた古い基準が含まれています。
[新しいデータセット] ウィンドウで [Azure SQL Server] を選択し、 [続行] を選択します。
データセットの [プロパティの設定] ウィンドウで、 [名前] に「WatermarkDataset」と入力します。
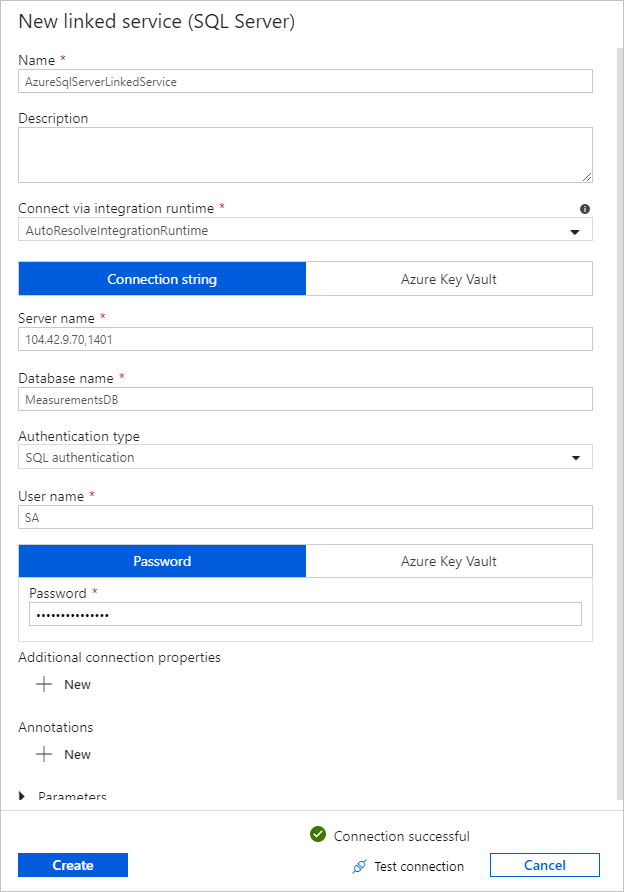
[リンクされたサービス] で [新規] を選択して、次の手順を実行します。
[名前] に「SQLDBEdgeLinkedService」と入力します。
[サーバー名] に SQL Edge サーバーの詳細を入力します。
一覧から目的のデータベース名を選択します。
[ユーザー名] と [パスワード] を入力します。
SQL Edge インスタンスへの接続をテストするために、 [テスト接続] を選択します。
を選択してを作成します。
[OK] を選択.
[設定] タブで、 [編集] を選択します。
[接続] タブで、
[dbo].[watermarktable]に を選択します。 テーブル内のデータをプレビューする場合、 [データのプレビュー] を選択します。上部のパイプライン タブを選択するか、左側のツリー ビューでパイプラインの名前を選択し、パイプライン エディターに切り替えます。 ルックアップ アクティビティのプロパティ ウィンドウで、 [Source dataset](ソース データセット) の一覧で [WatermarkDataset] が選択されていることを確認します。
[アクティビティ] ペインで [全般] を展開し、パイプライン デザイナー画面に [ルックアップ] アクティビティをもう 1 つドラッグします。 プロパティ ウィンドウの [全般] タブで、名前を NewWatermark に設定します。 このルックアップ アクティビティは、ソース データを含むテーブルから新しい基準値を取得して、それをターゲットにコピーできるようにします。
2 つ目のルックアップ アクティビティのプロパティ ウィンドウで、 [設定] タブに切り替え、 [新規] を選択し、新しい基準値を含むソース テーブルを指すデータセットを作成します。
[新しいデータセット] ウィンドウで、 [SQL Edge instance](SQL Edge インスタンス) を選択し、 [続行] を選択します。
[プロパティの設定] ウィンドウで、 [名前] に「SourceDataset」と入力します。 [リンクされたサービス] で [SQLDBEdgeLinkedService] を選択します。
[テーブル] で、同期するテーブルを選択します。 このチュートリアルで後述するように、このデータセットに対するクエリを指定することもできます。 このクエリは、この手順で指定するテーブルよりも優先されます。
[OK] を選択.
上部のパイプライン タブを選択するか、左側のツリー ビューでパイプラインの名前を選択し、パイプライン エディターに切り替えます。 ルックアップ アクティビティのプロパティ ウィンドウで、 [Source Dataset](ソース データセット) の一覧で [SourceDataset] が選択されていることを確認します。
[Use query](クエリの使用) で、 [クエリ] を選択します。 次のクエリ内のテーブル名を更新し、そのクエリを入力します。 テーブルから
timestampの最大値のみを選択します。 必ず [First row only](先頭行のみ) を選択してください。SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];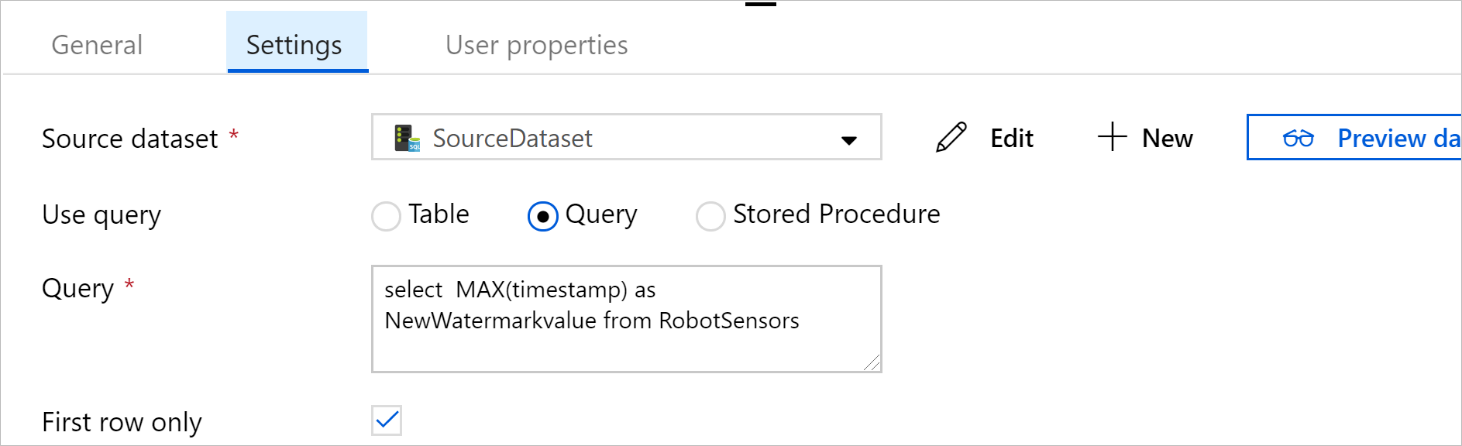
[アクティビティ] ペインで、[Move & Transform]\(移動と変換\) を展開し、[アクティビティ] ペインからデザイナー画面に [コピー] アクティビティをドラッグします。 アクティビティの名前を IncrementalCopy に設定します。
2 つのルックアップ アクティビティにコピー アクティビティに接続します。これには、ルックアップ アクティビティにアタッチされている緑のボタンをコピー アクティビティにドラッグします。 コピー アクティビティの境界線の色が青に変わったら、マウス ボタンを離します。
コピー アクティビティを選択し、そのアクティビティのプロパティが [プロパティ] ウィンドウに表示されることを確認します。
[プロパティ] ウィンドウで [ソース] タブに切り替え、次の手順を実行します。
[Source dataset](ソース データセット) ボックスで、 [SourceDataset] を選択します。
[クエリの使用] で、 [クエリ] を選択します。
[クエリ] ボックスに SQL クエリを入力します。 クエリの例を次に示します。
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';[シンク] タブの [Sink Dataset](シンク データセット) で [新規] を選択します。
このチュートリアルでのシンク データ ストアは Azure Blob Storage データ ストアです。 [新しいデータセット] ウィンドウで [Azure Blob Storage] を選択し、 [続行] を選択します。
[形式の選択] ウィンドウでデータの形式を選択し、 [続行] を選択します。
[プロパティの設定] ウィンドウで、 [名前] に「SinkDataset」と入力します。 [リンクされたサービス] で [新規] を選択します。 次に、使用する Azure Blob Storage への接続 (リンクされたサービス) を作成します。
[New Linked Service (Azure Blob storage)](新しいリンクされたサービス (Azure Blob Storage)) ウィンドウで、次の手順を実行します。
[名前] ボックスに「AzureStorageLinkedService」と入力します。
[ストレージ アカウント名] で、お使いの Azure サブスクリプションの Azure ストレージ アカウントを選択します。
接続をテストし、 [完了] を選択します。
[プロパティの設定] ウィンドウの [リンクされたサービス] で [AzureStorageLinkedService] が選択されていることを確認します。 [作成] 、 [OK] の順に選択します。
[シンク] タブで、 [編集] を選択します。
SinkDataset の [接続] タブに移動し、次の手順を実行します。
[ファイル パス] に「
asdedatasync/incrementalcopy」と入力します。ここで、asdedatasyncは BLOB コンテナー名、incrementalcopyはフォルダー名です。 このコンテナーが存在しない場合は、コンテナーを作成するか、既存のコンテナーの名前を使用してください。 出力フォルダーincrementalcopyが存在しない場合は、Azure Data Factory で自動的に作成されます。 [ファイル パス] の [参照] ボタンを使用して、BLOB コンテナー内のフォルダーに移動することもできます。[ファイル パス] のファイル部分で [動的なコンテンツの追加 [Alt+P]] を選択し、表示されたウィンドウで「
@CONCAT('Incremental-', pipeline().RunId, '.txt')」と入力します。 完了 を選択します。 ファイル名は、この式によって動的に生成されます。 各パイプラインの実行には、一意の ID があります。 コピー アクティビティは、実行 ID を使用して、ファイル名を生成します。
上部のパイプライン タブを選択するか、左側のツリー ビューでパイプラインの名前を選択し、パイプライン エディターに切り替えます。
[アクティビティ] ペインで [全般] を展開し、 [アクティビティ] ペインからパイプライン デザイナー画面に [ストアド プロシージャ] アクティビティをドラッグします。 コピー アクティビティの緑 (成功) の出力をストアド プロシージャ アクティビティに接続します。
パイプライン デザイナーでストアド プロシージャ アクティビティを選択し、その名前を
SPtoUpdateWatermarkActivityに変更します。[SQL アカウント] タブに切り替えて、 [リンクされたサービス] で [QLDBEdgeLinkedService] を選択します。
[ストアド プロシージャ] タブに切り替えて、次の手順を実行します。
[ストアド プロシージャ名] で
[dbo].[usp_write_watermark]を選択します。ストアド プロシージャのパラメーターの値を指定するには、 [Import parameter](インポート パラメーター) を選択し、各パラメーターに次の値を入力します。
名前 タイプ 価値 LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}パイプライン設定を検証するには、ツール バーの [検証] を選択します。 検証エラーがないことを確認します。 [Pipeline Validation Report](パイプライン検証レポート) ウィンドウを閉じるには、[>>] を選びます。
[すべて公開] ボタンを選択して、エンティティ (リンクされたサービス、データセット、およびパイプライン) を Azure Data Factory サービスに公開します。 公開操作が成功したことを確認するメッセージが表示されるまで待ちます。
スケジュールに基づいてパイプラインをトリガーする
パイプライン ツール バーで [トリガーの追加] を選択し、 [New/Edit](新規作成/編集) を選択して、 [新規] を選択します。
トリガーに HourlySync という名前を付けます。 [種類] で、 [スケジュール] を選択します。 [繰り返し] を 1 時間ごとに設定します。
[OK] を選択.
[すべて公開] を選択します。
[Trigger Now](今すぐトリガー) を選択します。
左側で [監視] タブに切り替えます。 手動トリガーによってトリガーされたパイプラインの実行の状態を確認できます。 [最新の情報に更新] を選択して、一覧を更新します。
## 関連コンテンツ
- このチュートリアルの Azure Data Factory パイプラインでは、SQL Edge インスタンス上のテーブルから Azure Blob Storage 内のある場所に 1 時間ごとにデータがコピーされます。 他のシナリオでの Data Factory の使用については、これらのチュートリアルを参照してください。