Azure SQL Database エラスティック プールを使用したアプリケーションのディザスター リカバリー戦略
適用対象: ![]() Azure SQL データベース
Azure SQL データベース
Azure SQL Database には、壊滅的な状況が発生した場合にアプリケーションのビジネス継続性を提供するための機能がいくつかあります。 エラスティック プールと Single Database は、同様のディザスター リカバリー (DR) 機能をサポートしています。 この記事では、Azure SQL Database のこれらのビジネス継続性機能を活用する、エラスティック プールのいくつかの DR 戦略について説明します。
この記事では、次のような標準的な SaaS ISV アプリケーション パターンを使用します。
最新のクラウド ベースの Web アプリケーションが、エンド ユーザーごとに 1 つのデータベースをプロビジョニングします。 ISV は多数の顧客を抱えており、テナント データベースと呼ばれる多数のデータベースを使用します。 通常、テナント データベースのアクティビティ パターンは予測できないため、ISV はエラスティック プールを使用して、長期間にわたるデータベース コストを予測可能にします。 エラスティック プールは、ユーザー アクティビティが急増した場合のパフォーマンスの管理も簡略化します。 アプリケーションは、テナント データベースだけでなく、ユーザー プロファイルの管理、セキュリティの確保、使用パターンの収集などのためのデータベースもいくつか使用します。個々のテナントの可用性は、アプリケーションの可用性全体には影響しません。 ただし、管理データベースの可用性とパフォーマンスは、アプリケーションの機能にとって重要であり、管理データベースがオフラインになると、アプリケーション全体がオフラインになります。
この記事では、費用重視型スタートアップ アプリケーションから、厳しい可用性要件があるアプリケーションまで、さまざまなシナリオを対象とした DR 戦略について説明します。
注意
Premium または Business Critical データベースとエラスティック プールを使用している場合、これらをゾーン冗長デプロイ構成に変換することで、リージョン障害に対する回復性を与えることができます。 「ゾーン冗長データベース」をご覧ください。
シナリオ 1. 費用重視型スタートアップ
新規事業を立ち上げたところであり、コストに非常に敏感になっています。 アプリケーションのデプロイと管理は簡略化する一方で、個々の顧客に対する SLA は制限付きでもよいと思っています。 ただし、全体的には、アプリケーションがオフラインになることがないようにしたいと考えています。
簡素化の要件を満たすために、すべてのテナント データベースを選択した Azure リージョンの 1 つのエラスティック プールにデプロイし、管理データベースを geo レプリケートされる Single Database としてデプロイする必要があります。 テナントのディザスター リカバリーには、geo リストアを使用します。この機能は、追加コストなしで利用できます。 管理データベースの可用性を確保するには、フェールオーバー グループを使用して管理データベースを別のリージョンに geo レプリケートする必要があります (手順 1)。 このシナリオでのディザスター リカバリー構成の継続的なコストは、セカンダリ データベースの合計コストと等しくなります。 この構成を次の図に示します。
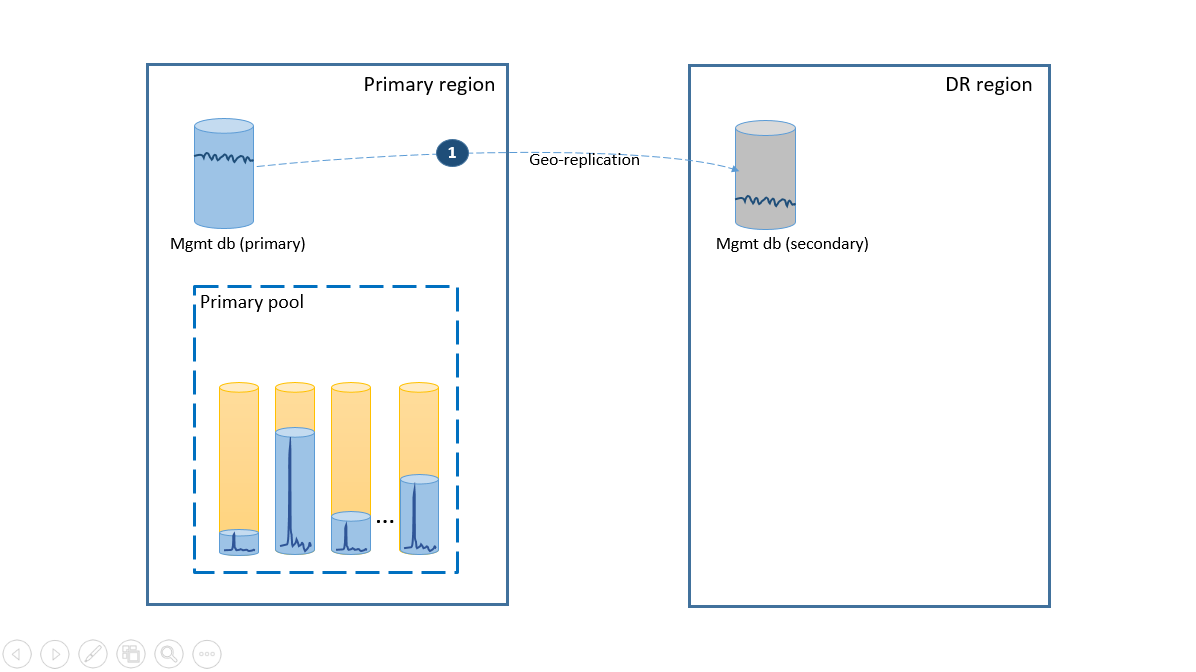
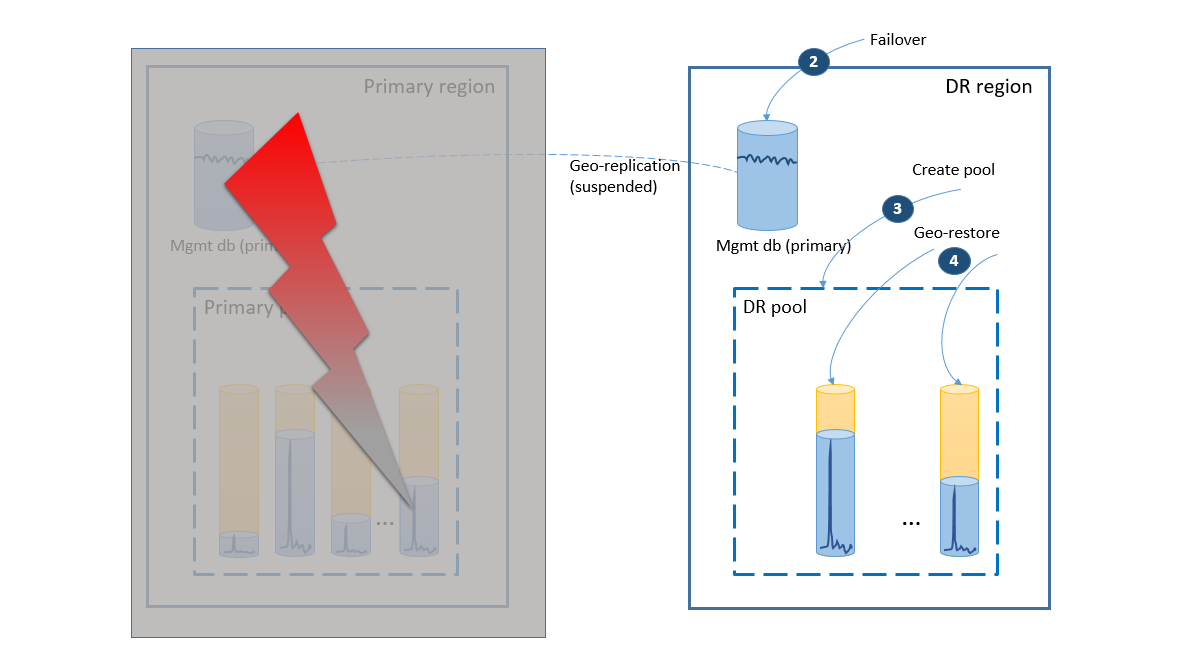
プライマリ リージョンで障害が発生した場合にアプリケーションをオンラインにするための復旧手順を、次の図に示します。
- フェールオーバー グループが DR リージョンへの管理データベースの自動フェールオーバーを開始します。 アプリケーションは新しいプライマリに自動的に再接続され、新しいアカウントとテナント データベースがすべて DR リージョンに作成されるようになります。 既存の顧客は、データが一時的に使用不可になります。
- 元のプールと同じ構成で、エラスティック プールを作成します (2)。
- geo リストアを使用して、テナント データベースのコピーを作成します (3)。 エンド ユーザー接続ごとに個々の復元をトリガーすることを検討してもよいほか、その他のアプリケーション固有の優先度スキームを使用することもできます。
この時点で、アプリケーションは DR リージョンでオンラインに戻りますが、一部の顧客がデータにアクセスするときに遅延が発生します。
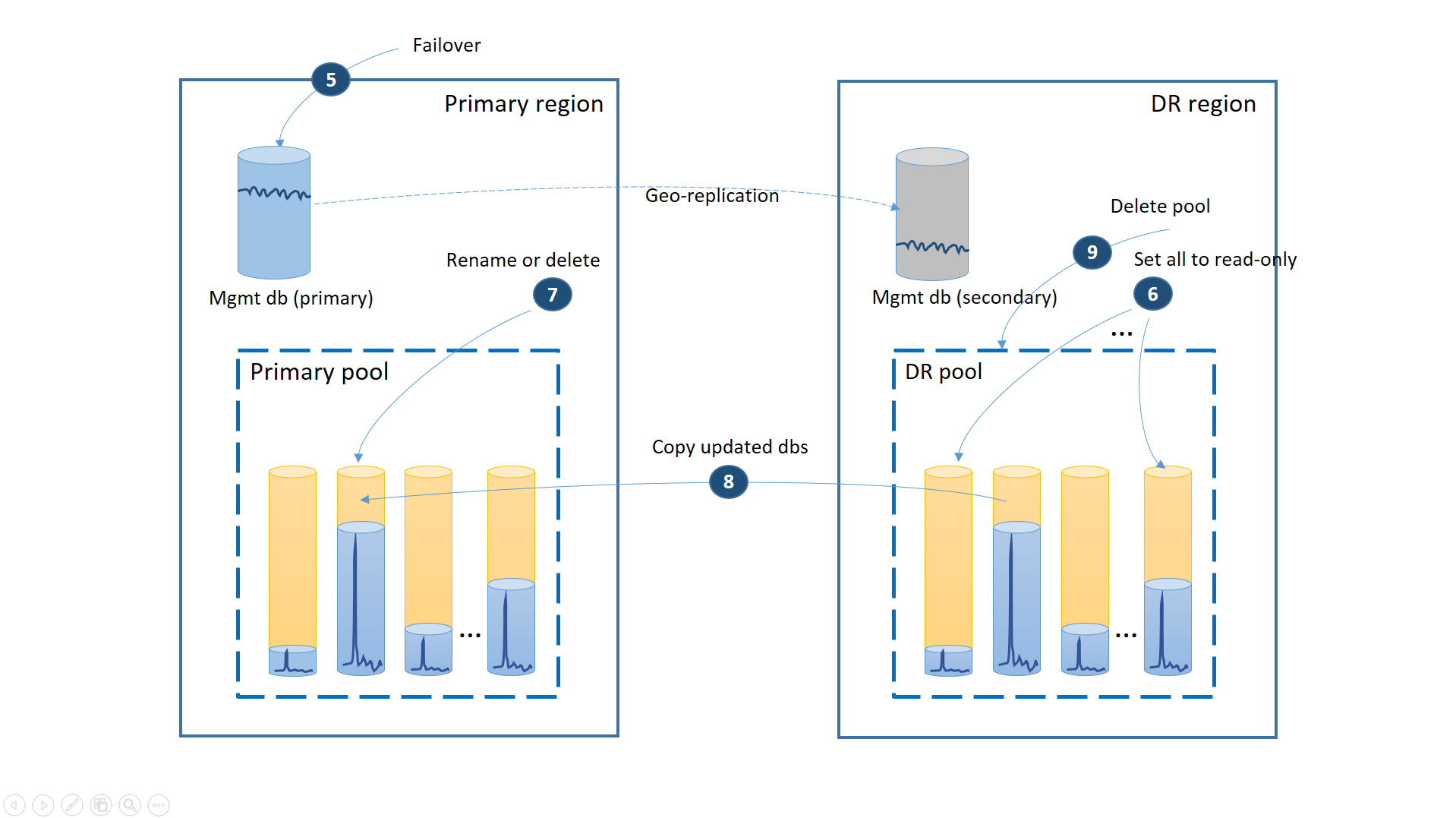
障害が一時的であった場合は、DR リージョンですべてのデータベースの復元が完了する前に、プライマリ リージョンが Azure によって復旧されることがあります。 その場合は、プライマリ リージョンへのアプリケーションの移動を調整する必要があります。 この処理の手順は、次の図のようになります。
- 未処理のすべての geo リストア要求を取り消します。
- 管理データベースをプライマリ リージョンにフェールオーバーします (5)。 リージョンの復旧後、古いプライマリは自動的にセカンダリになります。 ここで、もう一度役割を切り替えます。
- アプリケーションの接続文字列を、元のプライマリ リージョンを示す文字列に変更します。 これで、新しいアカウントとテナント データベースがすべてプライマリ リージョンに作成されるようになります。 一部の既存の顧客は、データが一時的に使用不可になります。
- DR プール内のすべてのデータベースを読み取り専用に設定して、DR リージョンで変更できないようにします (6)。
- 復旧後に変更された DR プール内のデータベースごとに、プライマリ プール内の対応するデータベースの名前を変更するか、そのデータベースを削除します (7)。
- 更新されたデータベースを DR プールからプライマリ プールにコピーします (8)。
- DR プールを削除します (9)。
この時点で、アプリケーションはプライマリ リージョンでオンラインになり、プライマリ プールですべてのテナント データベースが使用可能になります。
長所
この戦略の主なメリットは、データ層の冗長性を確保するための継続的なコストが低いことです。 Azure SQL Database を使用すると、アプリケーションを書き換えることなく、追加コストなしでデータベースを自動的にバックアップすることができます。 コストは、エラスティック データベースが復元されるときにのみ発生します。
トレードオフ
トレードオフは、すべてのテナント データベースの完全な復旧に長時間かかることです。 必要な時間は、DR リージョンで開始する復元の合計数と、テナント データベース全体のサイズによって決まります。 一部のテナントの復元を他より優先する場合でも、同じリージョンで開始される他のすべての復元との競合が発生します。これは、既存の顧客のデータベースへの全体的な影響を最小限にするために、サービスが調停および調整されるためです。 また、テナント データベースの復旧は、DR リージョンで新しいエラスティック プールが作成されるまで開始できません。
シナリオ 2. 階層化されたサービスを備えた成熟したアプリケーション
階層化されたサービス プランを備え、試用版を利用している顧客と有料の顧客とで異なる SLA を持つ、成熟した SaaS アプリケーションがあります。 試用版の顧客については、できるだけコストを削減する必要があります。 試用版の顧客にはダウンタイムが生じてもかまいませんが、その可能性は低くします。 有料の顧客には、ダウンタイムは契約を失いかねないリスクです。 そのため、有料の顧客は常にデータにアクセスできるようにします。
このシナリオを実現するには、試用版のテナントを別のエラスティック プールに置くことによって、試用版のテナントと有料のテナントを分離する必要があります。 試用版の顧客は、テナントあたりの eDTU または仮想コアが低く、SLA が低レベルで、復旧時間が長くなります。 有料の顧客は、テナントあたりの eDTU または仮想コアが高いプールに配置され、SLA が高レベルになります。 最短の復旧時間を保証するために、有料の顧客のテナント データベースは geo レプリケートする必要があります。 この構成を次の図に示します。
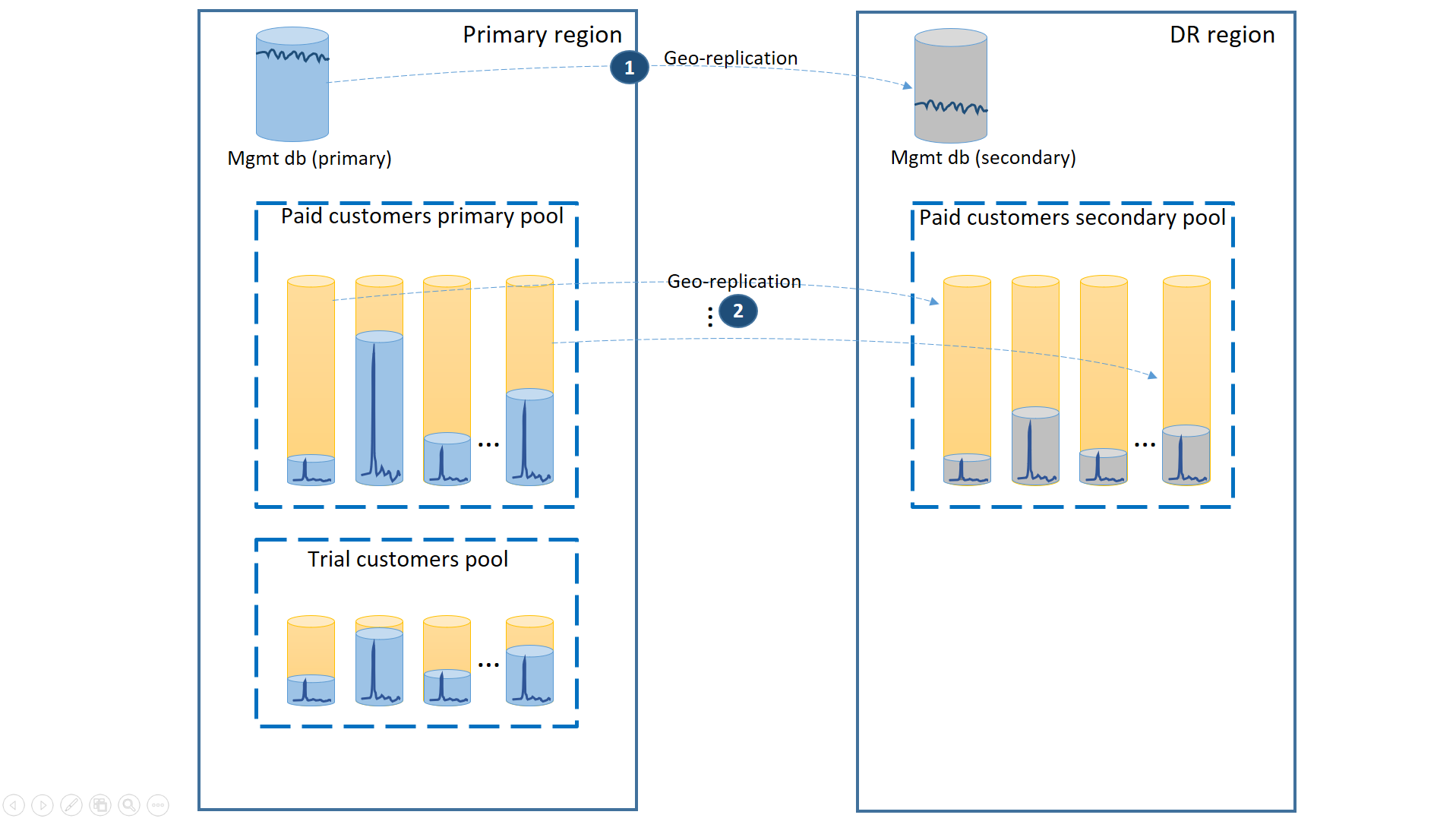
最初のシナリオと同様に、管理データベースはかなりアクティブに使用されるので、geo レプリケートされる Single Database を使用します (1)。 そうすることで、新しい顧客サブスクリプションやプロファイルの更新などの管理操作について、予測可能なパフォーマンスが保証されます。 管理データベースのプライマリが存在するリージョンがプライマリ リージョンになり、管理データベースのセカンダリが存在するリージョンが DR リージョンになります。
有料の顧客のテナント データベースについては、プライマリ リージョンにプロビジョニングされた "有料" プール内にアクティブなデータベースが配置されます。 DR リージョン内に、同じ名前のセカンダリ プールをプロビジョニングしてください。 各テナントは、セカンダリ プールに geo レプリケートされます (2)。 そうすることで、フェールオーバーを使用して、すべてのテナント データベースを迅速に復旧することができます。
プライマリ リージョンで障害が発生した場合にアプリケーションをオンラインにするための復旧手順を、次の図に示します。
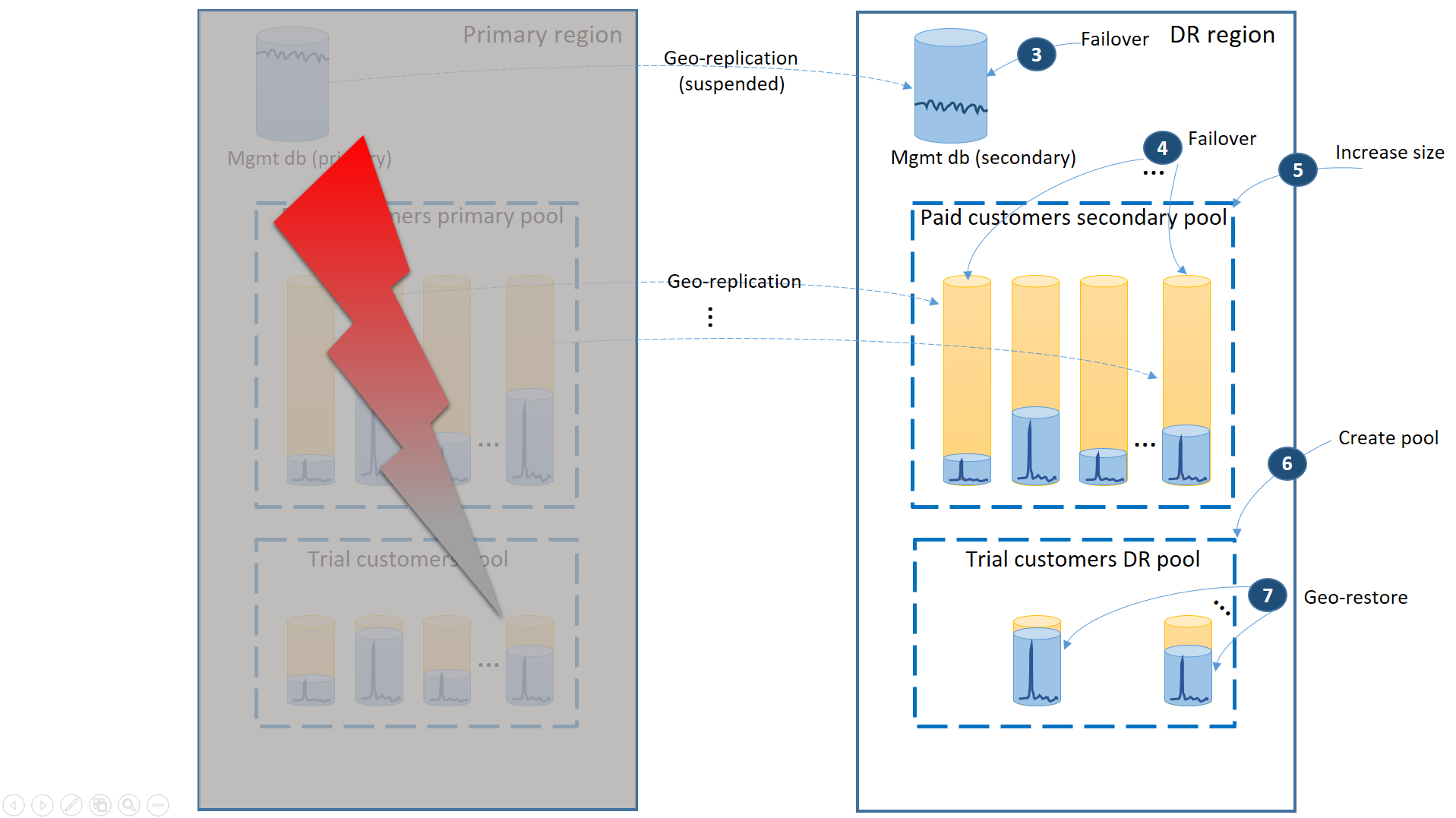
- すぐに管理データベースを DR リージョンにフェールオーバーします (3)。
- アプリケーションの接続文字列を、DR リージョンを指すように変更します。 これで、新しいアカウントとテナント データベースがすべて DR リージョンに作成されるようになります。 既存の試用版の顧客は、一時的にデータを使用できなくなります。
- 可用性をすぐに回復させるために、有料のテナントのデータベースを DR リージョンのプールにフェールオーバーします (4)。 フェールオーバーは、迅速なメタデータ レベルの変更であるため、エンド ユーザー接続ごとにオンデマンドで個々のフェールオーバーがトリガーされる最適化を検討してください。
- セカンダリ データベースがセカンダリである間は変更ログを処理する容量しか必要ないため、セカンダリ プールの eDTU サイズまたは仮想コアの値がプライマリよりも小さかった場合は、すぐにプールの容量を増やして、すべてのテナントのワークロードに完全に対応できるようにする必要があります (5)。
- 試用版の顧客のデータベース用に、DR リージョンに同じ名前と構成で新しいエラスティック プールを作成します (6)。
- 試用版の顧客のプールが作成されたら、geo リストアを使用して、新しいプールに個々の試用テナント データベースを復元します (7)。 エンド ユーザー接続ごとに個々の復元をトリガーすることを検討するか、その他のアプリケーション固有の優先度スキームを使用してください。
この時点で、アプリケーションは DR リージョンでオンラインに戻ります。 有料の顧客はいずれもデータにアクセスできますが、試用版の顧客はデータにアクセスするときに遅延が発生します。
DR リージョンでアプリケーションを復元した 後 で、Azure によってプライマリ リージョンが復旧される場合は、DR リージョンでアプリケーションを実行し続けることも、プライマリ リージョンにフェールバックすることもできます。 フェールオーバー処理が完了する "前" に、プライマリ リージョンが復旧される場合は、直ちにフェールバックすることを考慮する必要があります。 フェールバックの手順は、次の図のようになります。
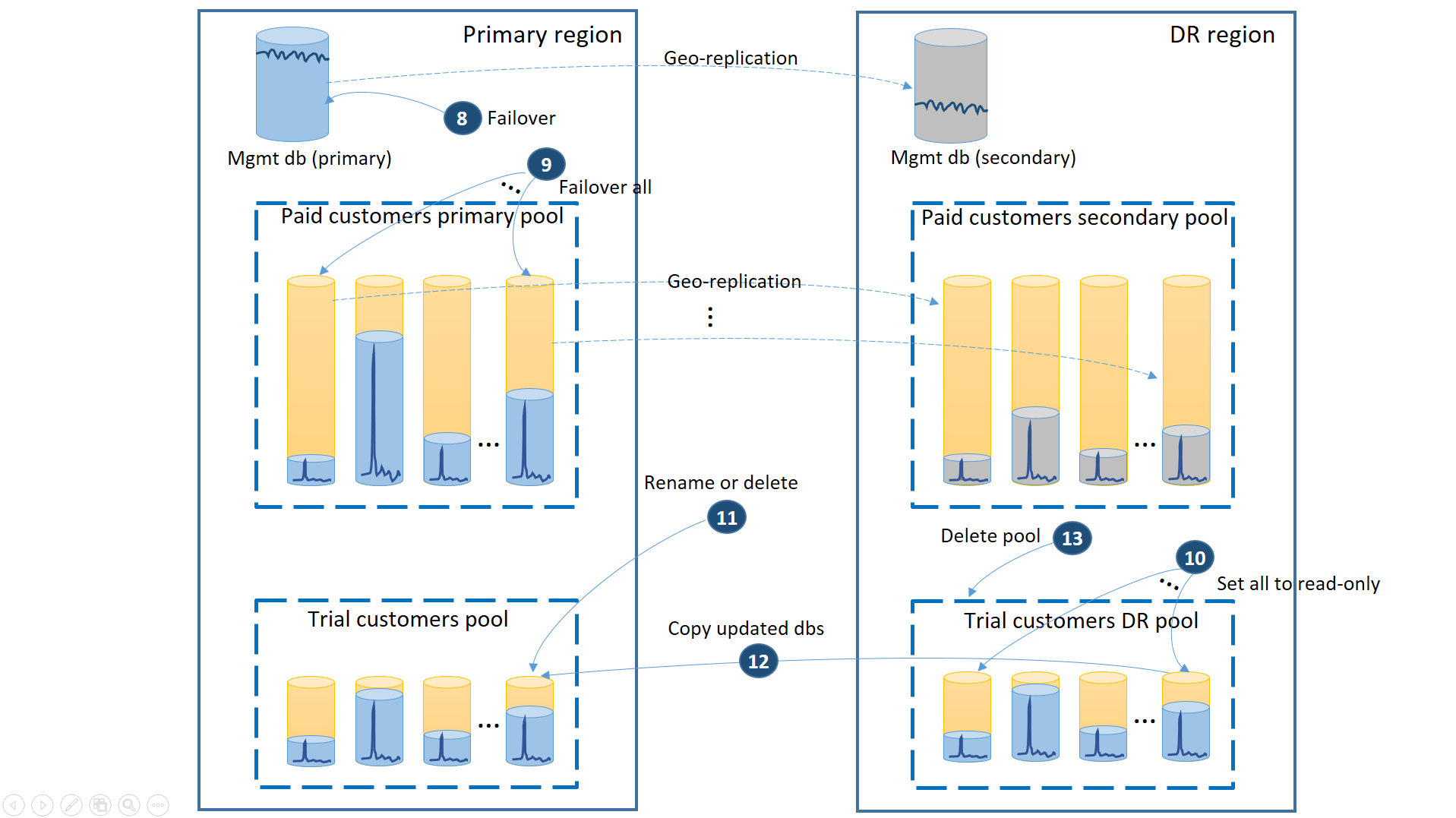
- 未処理のすべての geo リストア要求を取り消します。
- 管理データベースをフェールオーバーします (8)。 リージョンの復旧後、古いプライマリは自動的にセカンダリになります。 これが再びプライマリになります。
- 有料テナント データベースをフェールオーバーします (9)。 同様に、リージョンの復旧後、古いプライマリは自動的にセカンダリになります。 これらが再びプライマリになります。
- DR リージョンで変更された、復元された試用データベースを、読み取り専用に設定します (10)。
- 復旧後に変更された、試用版の顧客の DR プール内のデータベースごとに、試用版の顧客のプライマリ プール内にある対応するデータベースの名前を変更するか、そのデータベースを削除します (11)。
- 更新されたデータベースを DR プールからプライマリ プールにコピーします (12)。
- DR プールを削除します (13)。
注意
フェールオーバー操作は非同期です。 復旧時間を最小限に抑えるには、少なくとも 20 個のデータベースをひとまとめにして、テナント データベースのフェールオーバー コマンドを実行することが重要です。
長所
この戦略の主なメリットは、有料の顧客に最高の SLA を提供できることです。 また、試用 DR プールが作成されしだい、新たな試用がブロックされなくなることも保証できます。
トレードオフ
トレードオフは、このセットアップでは、有料顧客用のセカンダリ DR プールのコストによって、テナント データベースの総コストが増加することです。 さらに、セカンダリ プールのサイズが異なる場合は、フェールオーバー後、DR リージョンでプールのアップグレードが完了するまで、有料の顧客に対するパフォーマンスが低下します。
シナリオ 3. 階層化されたサービスを備え、地理的に分散したアプリケーション
階層化したサービス プランを備えた、成熟した SaaS アプリケーションがあります。 有料の顧客に極めて高い SLA を提供し、障害発生時の影響のリスクを最小限に抑えたいと考えています。短い中断でも、顧客は不満に感じるためです。 有料の顧客が常にデータにアクセスできることが重要です。 試用版は無料であり、試用期間中は SLA は提供されません。
このシナリオをサポートするには、3 つの個別のエラスティック プールを使用します。 有料の顧客のテナント データベースを格納するには、データベースあたりの eDTU または仮想コアが高い 2 つの同じサイズのプールを、2 つの異なるリージョンにプロビジョニングしてください。 試用版のテナントを含む 3 つ目のプールは、データベースあたりの eDTU または仮想コアは低くなり、2 つのリージョンのいずれかにプロビジョニングされます。
障害時に最短の復旧時間を保証するために、有料の顧客のテナント データベースは、プライマリ データベースを 50% ずつという割合で、2 つのリージョンそれぞれに geo レプリケートします。 同様に、各リージョンにセカンダリ データベースを 50% ずつ配置します。 こうすることで、リージョンがオフラインになった場合、有料の顧客のデータベースの 50% だけが影響を受け、フェールオーバーされることになります。 他のデータベースは影響を受けず、そのまま残ります。 この構成を示したのが次の図です。
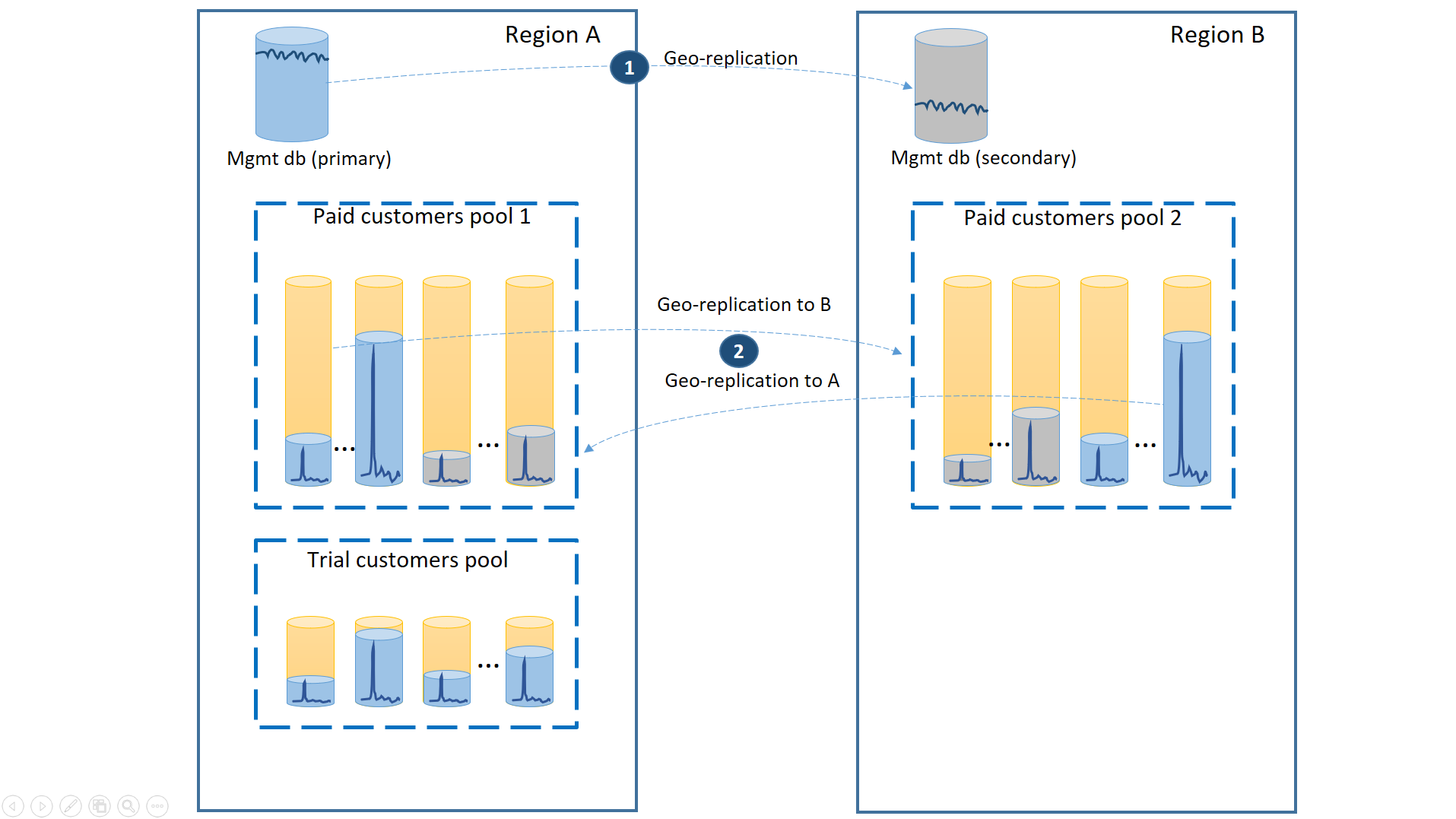
前のシナリオと同様に、管理データベースはかなりアクティブに使用されるので、geo レプリケートされる Single Database として構成する必要があります (1)。 そうすることで、新しい顧客サブスクリプションやプロファイルの更新などの管理操作について、予測可能なパフォーマンスが保証されます。 リージョン A は管理データベースのプライマリ リージョンになり、リージョン B は管理データベースの復旧のために使用されます。
有料の顧客のテナント データベースも geo レプリケートされますが、プライマリとセカンダリがリージョン A とリージョン B に分割されます (2)。 こうすることで、障害の影響を受けたテナント プライマリ データベースを他のリージョンにフェールオーバーし、使用可能にすることができます。 残りの半分のテナント データベースはまったく影響を受けません。
次の図は、リージョン A で障害が発生した場合に実行する復旧手順を示しています。
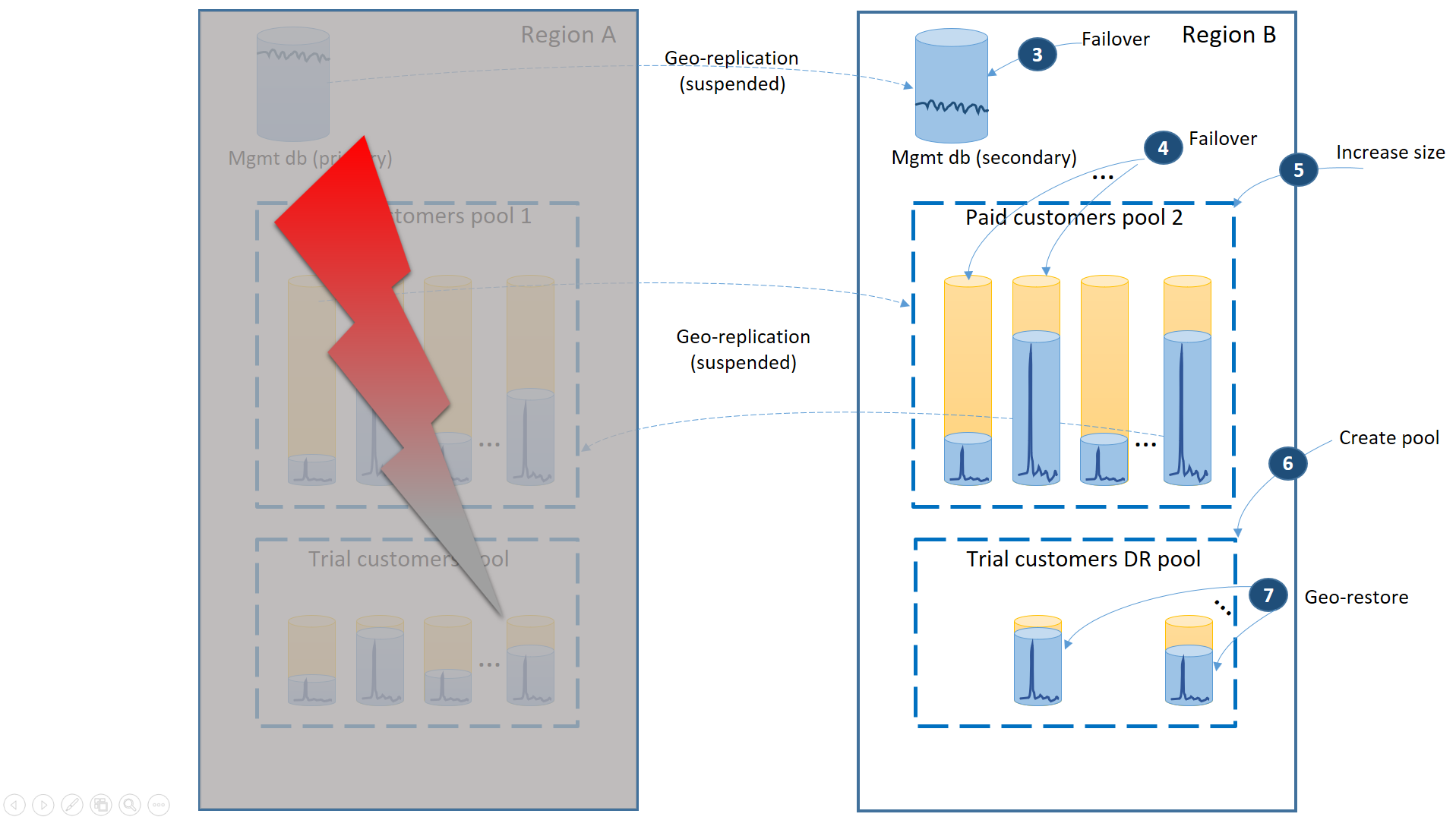
- すぐに管理データベースをリージョン B にフェールオーバーします (3)。
- アプリケーションの接続文字列を、リージョン B 内の管理データベースを指すように変更します。管理データベースを変更し、新しいアカウントとテナント データベースがリージョン B に作成されるようにすると共に、既存のテナント データベースもそこで見つかるようにします。 既存の試用版の顧客は、一時的にデータを使用できなくなります。
- 可用性をすぐに回復させるために、有料のテナントのデータベースをリージョン B のプール 2 にフェールオーバーします (4)。 フェールオーバーは、迅速なメタデータ レベルの変更であるため、エンド ユーザー接続ごとにオンデマンドで個々のフェールオーバーがトリガーされる最適化を検討することもできます。
- これで、プール 2 にはプライマリ データベースだけが含まれるようになり、プールの総ワークロードが増えるため、すぐに eDTU サイズまたは仮想コア数を増やすことができます (5)。
- 試用版の顧客のデータベース用に、リージョン B に同じ名前と構成で新しいエラスティック プールを作成します (6)。
- プールが作成されたら、geo リストアを使用して、プールに個々の試用テナント データベースを復元します (7)。 エンド ユーザー接続ごとに個々の復元をトリガーすることを検討してもよいほか、その他のアプリケーション固有の優先度スキームを使用することもできます。
注意
フェールオーバー操作は非同期です。 復旧時間を最小限に抑えるには、少なくとも 20 個のデータベースをひとまとめにして、テナント データベースのフェールオーバー コマンドを実行することが重要です。
この時点で、アプリケーションはリージョン B でオンラインに戻ります。有料の顧客はいずれもデータにアクセスできますが、試用版の顧客はデータにアクセスするときに遅延が発生します。
リージョン A が復旧するときに、試用版の顧客のためにリージョン B を使用するか、試用版の顧客のリージョン A のプールを使用してフェールバックするかを判断する必要があります。判断条件の 1 つは、復旧以降に変更された試用テナント データベースの割合です。 判断に関係なく 2 つのプール間で有料のテナントを再調整する必要があります。 次の図は、試用版のテナント データベースがリージョン A にフェールバックするときの処理を示しています。
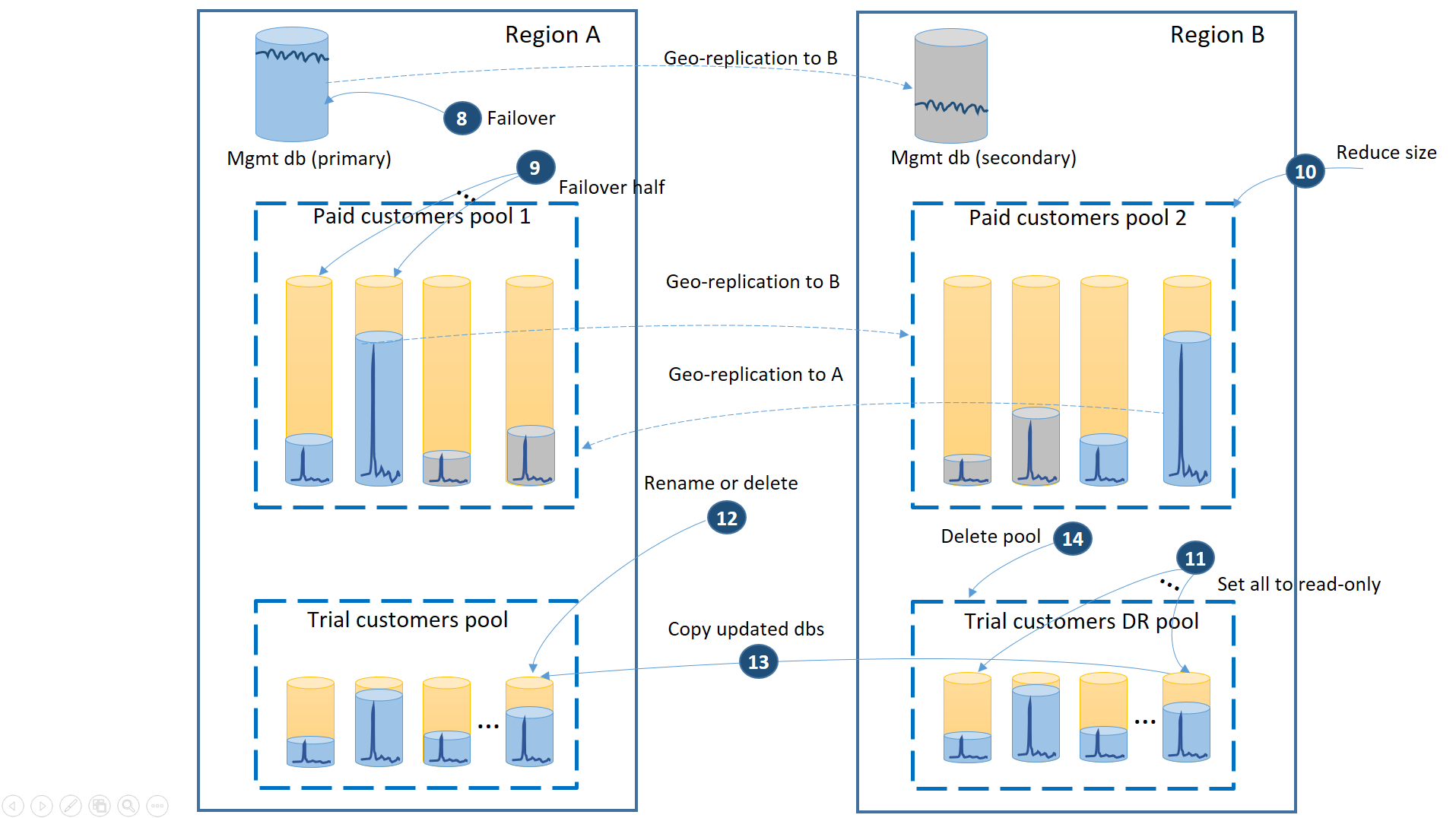
- 試用 DR プールへの未処理のすべての geo リストア要求を取り消します。
- 管理データベースをフェールオーバーします (8)。 リージョンの復旧後、古いプライマリは自動的にセカンダリになっています。 これが再びプライマリになります。
- どの有料テナント データベースをプール 1 にフェールバックするかを選択し、セカンダリへのフェールオーバーを開始します (9)。 リージョンの復旧後に、プール 1 のすべてのデータベースは自動的にセカンダリになっています。 これで、それらの 50% が再びプライマリになります。
- プール 2 のサイズを元の eDTU または仮想コア数に戻します (10)。
- リージョン B 内の復元されたすべての試用データベースを読み取り専用に設定します (11)。
- 復旧後に変更された試用 DR プール内のデータベースごとに、試用プライマリ プール内の対応するデータベースの名前を変更するか、そのデータベースを削除します (12)。
- 更新されたデータベースを DR プールからプライマリ プールにコピーします (13)。
- DR プールを削除します (14)。
長所
この戦略の主なメリットは、次のとおりです。
- 障害が 50% を超えるテナント データベースに影響することはないため、有料の顧客のために最高レベルの SLA をサポートできます。
- 復旧中に試用 DR プールが作成されしだい、新たな試用がブロックされなくなることを保証できます。
- プール 1 とプール 2 のセカンダリ データベースの 50% はプライマリ データベースよりもアクティブに使用されなくなるため、プールの容量をより効率的に使用できます。
トレードオフ
主なトレードオフは、次のとおりです。
- 管理データベースに対する CRUD 操作の遅延は、リージョン A に接続しているエンド ユーザーの方がリージョン B に接続しているエンド ユーザーよりも短くなります。この操作は、管理データベースのプライマリに対して実行されるためです。
- 管理データベースに、より複雑な設計が必要になります。 たとえば、各テナント レコードには、フェールオーバーとフェールバック時に変更する必要がある場所タグが必要です。
- リージョン B のプールのアップグレードが完了するまで、有料の顧客に対するパフォーマンスが通常よりも低下することがあります。
まとめ
この記事では、SaaS ISV マルチテナント アプリケーションで使用されるデータベース層のディザスター リカバリー戦略に焦点を当てています。 戦略は、ビジネス モデル、顧客に提供する SLA、予算の制約など、アプリケーションのニーズに基づいて選択する必要があります。各戦略のメリットとトレードオフの概要が説明されているため、それを参考にして判断できます。 また、アプリケーションによっては、他の Azure コンポーネントが含まれることがあります。 したがって、ビジネス継続性ガイダンスを確認し、こうしたコンポーネントとデータベース層の復旧を調整する必要があります。 Azure でデータベース アプリケーションの復旧を管理する方法の詳細については、ディザスター リカバリーのためのクラウド ソリューションの設計に関するページをご覧ください。
次のステップ
- Azure SQL Database 自動バックアップの詳細については、Azure SQL Database の自動バックアップに関するページを参照してください。
- ビジネス継続性の概要およびシナリオについては、 ビジネス継続性の概要に関する記事を参照してください。
- 自動バックアップを使用して復旧する方法については、 サービス主導のバックアップからのデータベース復元に関するページをご覧ください
- より迅速な復旧オプションについては、アクティブ geo レプリケーションとフェールオーバー グループに関する記事を参照してください。
- 自動バックアップを使用したアーカイブについては、 データベースのコピーに関する記事を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示