[アーティクル] 03/18/2024
2 人の共同作成者
フィードバック
この記事の内容
適用対象: Azure SQL データベース
この記事では、Azure SQL Database Hyperscale の名前付きレプリカ を構成および管理するためのサンプルを提供します。
Hyperscale の名前付きレプリカを作成する
次のサンプル シナリオでは、Azure portal、T-SQL、PowerShell、または Azure CLI を使用して、データベース WideWorldImporters の名前付きレプリカ WideWorldImporters_NamedReplica を作成する方法について説明します。
次の例では、T-SQL を使用してデータベース WideWorldImporters の名前付きレプリカ WideWorldImporters_NamedReplica が作成されます。 プライマリ レプリカでは、サービス レベル目標 HS_Gen5_4 が使用されますが、名前付きレプリカでは HS_Gen5_2 が使用されます。 どちらも contosoeast という名前の同じ論理サーバーを使用します。
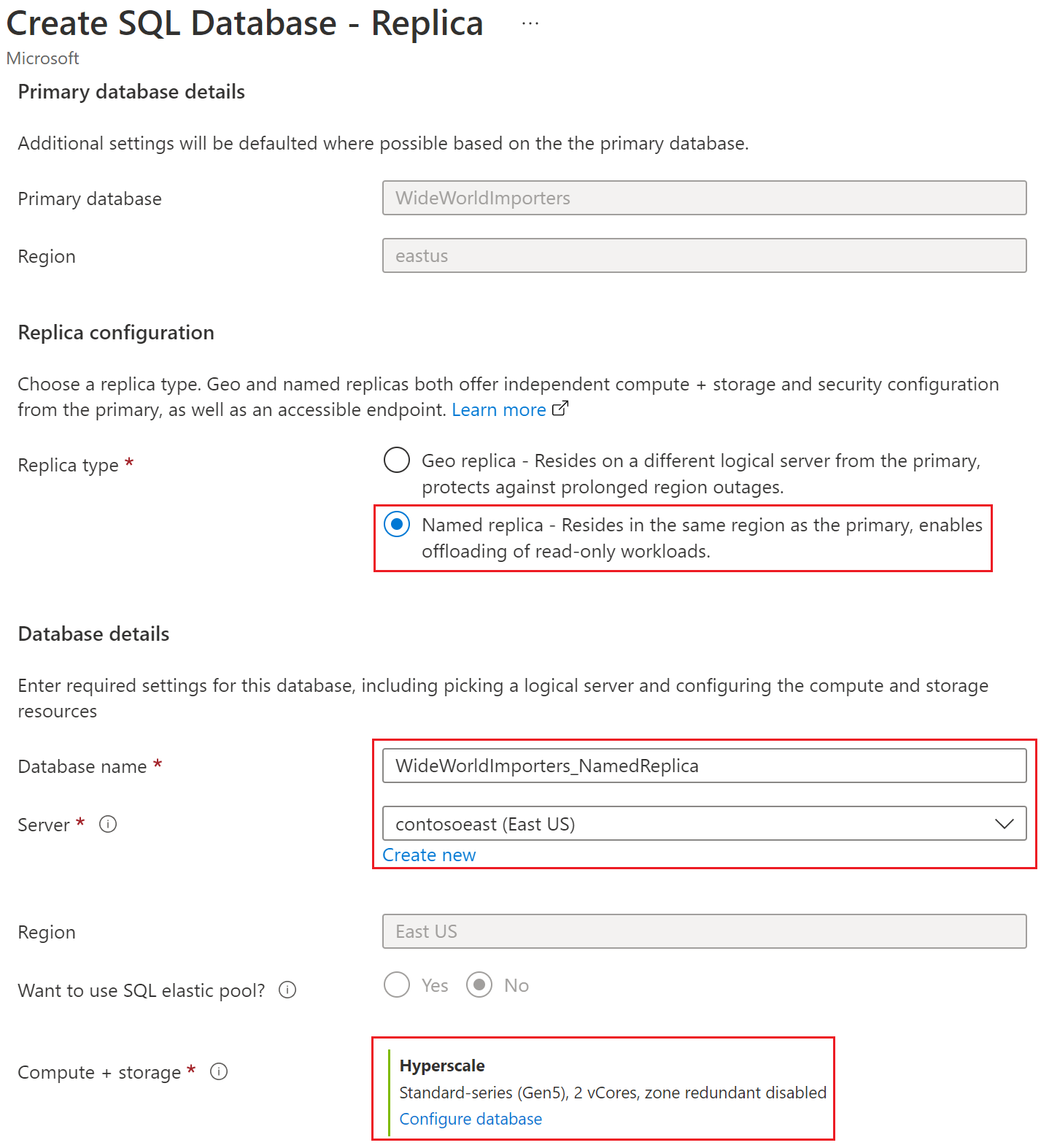
Azure portal で、名前付きレプリカを作成するデータベースを参照します。
[SQL Database] ページで、データベースを選択し、[データ管理] までスクロールします。次に、[レプリカ] を選択し、[レプリカの作成] を選択します。
[レプリカの構成] で [名前付きレプリカ] を選択します。 既存のサーバーを選択するか、名前付きレプリカの新しいサーバーを作成します。 名前付きレプリカ データベース名を入力し、必要に応じて[コンピューティングとストレージ] オプションを構成します。
必要に応じて、ゾーン冗長 Hyperscale の名前付きレプリカを構成します。 詳細については、「Azure SQL データベース Hyperscale の名前付きレプリカのゾーン冗長 」を参照してください。
[データベースの構成 ] ページで、このデータベースをゾーン冗長にしますか? に [はい] を選択します。
構成に少なくとも 1 つの高可用性セカンダリ レプリカを追加します。
適用 を選択します。
[確認と作成] を選択し、情報を確認し、[作成] を選びます。
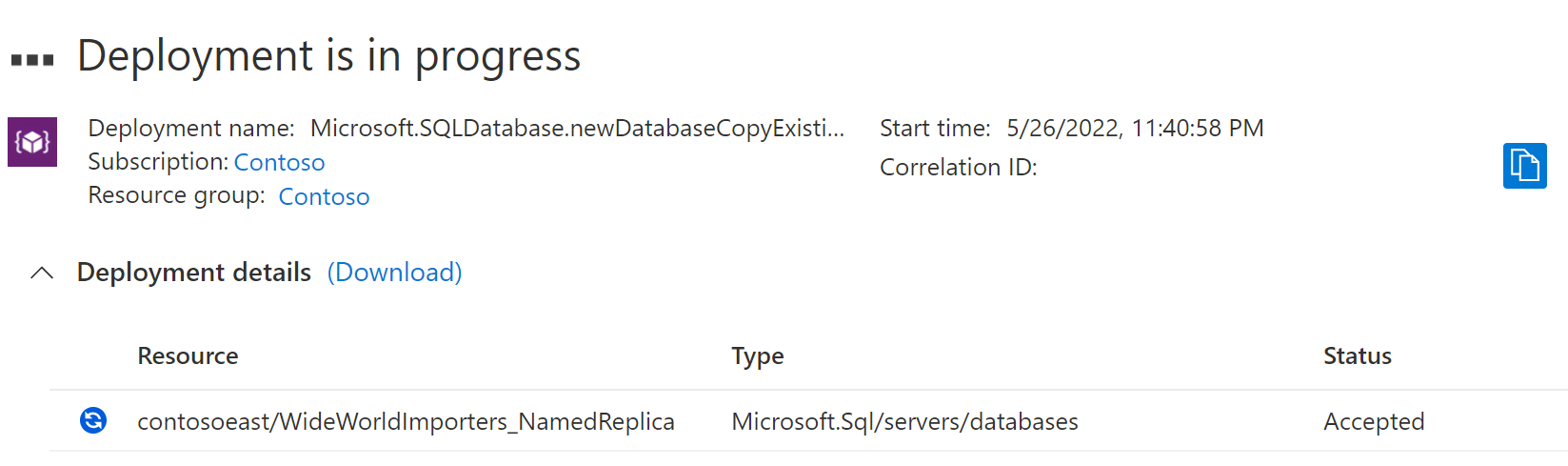
名前付きレプリカのデプロイ プロセスが開始されます。
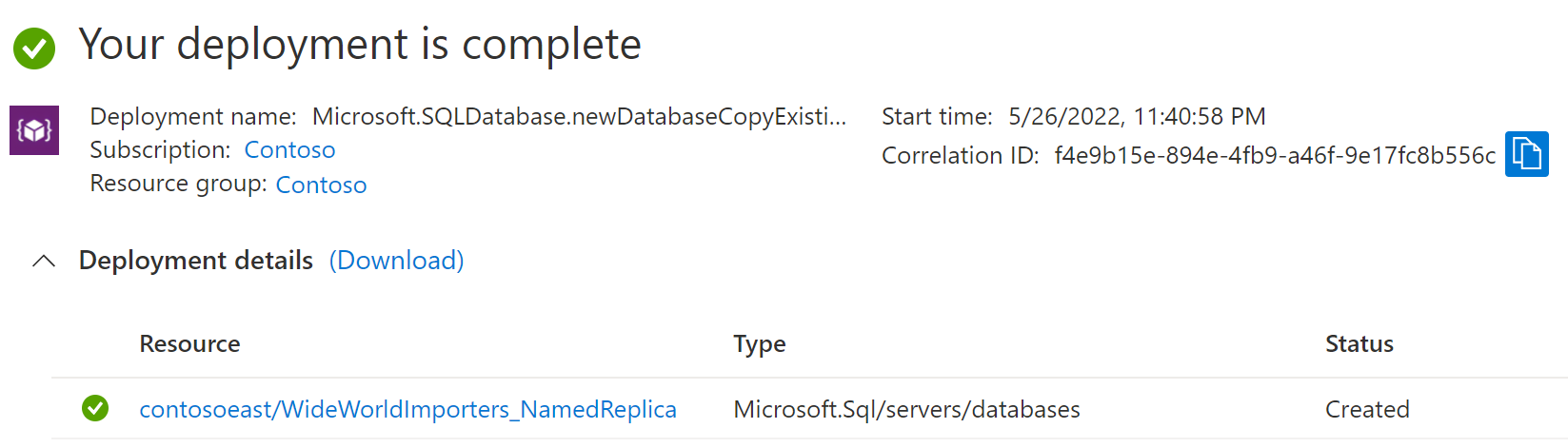
デプロイが完了すると、名前付きレプリカにその状態が表示されます。
プライマリ データベース ページに戻り、 [レプリカ] を選択します。 名前付きレプリカの一覧が [名前付きレプリカ] の下に表示されます。
次の例では、T-SQL を使用してデータベース WideWorldImporters の名前付きレプリカ WideWorldImporters_NamedReplica が作成されます。 プライマリ レプリカでは、サービス レベル目標 HS_Gen5_4 が使用されますが、名前付きレプリカでは HS_Gen5_2 が使用されます。 どちらも contosoeast という名前の同じ論理サーバーを使用します。
ALTER DATABASE [WideWorldImporters]
ADD SECONDARY ON SERVER [contosoeast]
WITH (SERVICE_OBJECTIVE = 'HS_Gen5_2', SECONDARY_TYPE = Named, DATABASE_NAME = [WideWorldImporters_NamedReplica]);
次の例では、PowerShell コマンドレット New-AzSqlDatabaseSecondary を使用して、データベース WideWorldImporters の名前付きレプリカ WideWorldImporters_NamedReplica を作成します。 プライマリ レプリカでは、サービス レベル目標 HS_Gen5_4 が使用されますが、名前付きレプリカでは HS_Gen5_2 が使用されます。 どちらも contosoeast という名前の同じ論理サーバーを使用します。
New-AzSqlDatabaseSecondary -ResourceGroupName "MyResourceGroup" -ServerName "contosoeast" -DatabaseName "WideWorldImporters" -PartnerResourceGroupName "MyResourceGroup" -PartnerServerName "contosoeast" -PartnerDatabaseName "WideWorldImporters_NamedReplica" -SecondaryType Named -SecondaryServiceObjectiveName HS_Gen5_2
ゾーン冗長 Hyperscale の名前付きレプリカ を構成するには、New-AzSqlDatabaseSecondary の –ZoneRedundant パラメーターと -HighAvailabilityReplicaCount 入力パラメーターの両方を指定する必要があります。
New-AzSqlDatabaseSecondary -ResourceGroupName "MyResourceGroup" -ServerName "contosoeast" -DatabaseName "WideWorldImporters" -PartnerResourceGroupName "MyResourceGroup" -PartnerServerName "contosoeast" -PartnerDatabaseName "WideWorldImporters_NamedReplica" -SecondaryType Named -SecondaryServiceObjectiveName HS_Gen5_2 -HighAvailabilityReplicaCount 1 -ZoneRedundant
名前付きレプリカが作成されているかどうかを検証するには、Get-AzSqlDatabase を使用します。
Get-AzSqlDatabase -DatabaseName "WideWorldImporters_NamedReplica" -ResourceGroupName "MyResourceGroup" -ServerName "contosoeast"
次の例では、Azure CLI コマンド az sql db replica create を使用して、データベース WideWorldImporters の名前付きレプリカ WideWorldImporters_NamedReplica を作成します。 プライマリ レプリカでは、サービス レベル目標 HS_Gen5_4 が使用されますが、名前付きレプリカでは HS_Gen5_2 が使用されます。 どちらも contosoeast という名前の同じ論理サーバーを使用します。
az sql db replica create -g MyResourceGroup -n WideWorldImporters -s contosoeast --secondary-type named --partner-database WideWorldImporters_NamedReplica --partner-server contosoeast --service-objective HS_Gen5_2
ゾーン冗長 Hyperscale の名前付きレプリカ を構成するには、az sql db replica create の –zone-redundant パラメーターと ha-replicas 入力パラメーターの両方を指定する必要があります。
az sql db replica create -g MyResourceGroup -n WideWorldImporters -s contosoeast --secondary-type named --partner-database WideWorldImporters_NamedReplica --partner-server contosoeast --service-objective HS_Gen5_2 --ha-replicas 1 -zone-redundant
名前付きレプリカが作成されているかどうかを検証するには:
az sql db show -g MyResourceGroup -n WideWorldImporters -s contosoeast
名前付きレプリカは、データ移動が伴わないので、ほとんどの場合、ほんの一瞬で作成されます。 名前付きレプリカが利用可能になると、Azure portal やコマンドライン ツール (AZ CLI、PowerShell など) から見えるようになります。 名前付きレプリカは、通常の読み取り専用データベースとして利用できます。
Hyperscale の名前付きレプリカに接続する
Hyperscale の名前付きレプリカに接続するには、そのサーバー名とデータベース名を参照して、その名前付きレプリカの接続文字列を使用する必要があります。 名前付きレプリカは常に読み取り専用であるため、ApplicationIntent=ReadOnly オプションを指定する必要はありません。
プライマリ、HA、名前付きレプリカは、同じ一連のページ サーバー上の同じデータを共有しますが、個々の名前付きレプリカのデータ キャッシュは、HA レプリカの場合と同様、プライマリと同期状態に保たれます。 同期は、プライマリから名前付きレプリカにログ レコードを転送するトランザクション ログ サービスによって維持されます。 ログ レコードが適用される速度は、名前付きレプリカで処理されているワークロードによって異なる場合があり、プライマリ レプリカを基準とするデータの待機時間もレプリカごとに異なる結果となります。
Hyperscale の名前付きレプリカを変更する
名前付きレプリカのサービス レベル目標は、その作成時に、ALTER DATABASE コマンドのほか、サポートされているあらゆる手段 (ポータル、AZ CLI、PowerShell) を用いて定義できます。 名前付きレプリカの作成後にサービス レベル目標を変更する必要が生じた場合は、その名前付きレプリカ自体に対して ALTER DATABASE ... MODIFY コマンドを使用して変更できます。
次の例で、WideWorldImporters_NamedReplica は WideWorldImporters データベースの名前付きレプリカです。
名前付きレプリカ データベース ページを開き、[コンピューティングとストレージ] を選択します。 仮想コアを更新します。
ALTER DATABASE [WideWorldImporters_NamedReplica] MODIFY (SERVICE_OBJECTIVE = 'HS_Gen5_4')
Set-AzSqlDatabase -ResourceGroup "MyResourceGroup" -ServerName "contosoeast" -DatabaseName "WideWorldImporters_NamedReplica" -RequestedServiceObjectiveName "HS_Gen5_4"
az sql db update -g MyResourceGroup -s contosoeast -n WideWorldImporters_NamedReplica --service-objective HS_Gen5_4
Hyperscale の名前付きレプリカを削除する
Hyperscale の名前付きレプリカを削除するには、通常のデータベースと同様に削除します。
名前付きレプリカ データベース ページを開き、Delete オプションを選択します。
ドロップする名前付きレプリカがあるサーバーの master データベースに接続されていることを確認してから、次のコマンドを使用します。
このコマンドは、WideWorldImporters_NamedReplica という名前 のデータベースを削除します。
DROP DATABASE [WideWorldImporters_NamedReplica];
このコマンドは、論理サーバー WideWorldImporters_NamedReplica から contosoeast という名前のデータベースを削除します。
Remove-AzSqlDatabase -ResourceGroupName "MyResourceGroup" -ServerName "contosoeast" -DatabaseName "WideWorldImporters_NamedReplica"
このコマンドは、論理サーバー WideWorldImporters_NamedReplica から contosoeast という名前のデータベースを削除します。
az sql db delete -g MyResourceGroup -s contosoeast -n WideWorldImporters_NamedReplica
重要
名前付きレプリカの作成元となったプライマリ レプリカが削除されると、その名前付きレプリカは自動的に削除されます。
関連するコンテンツ