Azure Stream Analytics 統合を使用して Azure SQL Database にデータをストリーム配信する (プレビュー)
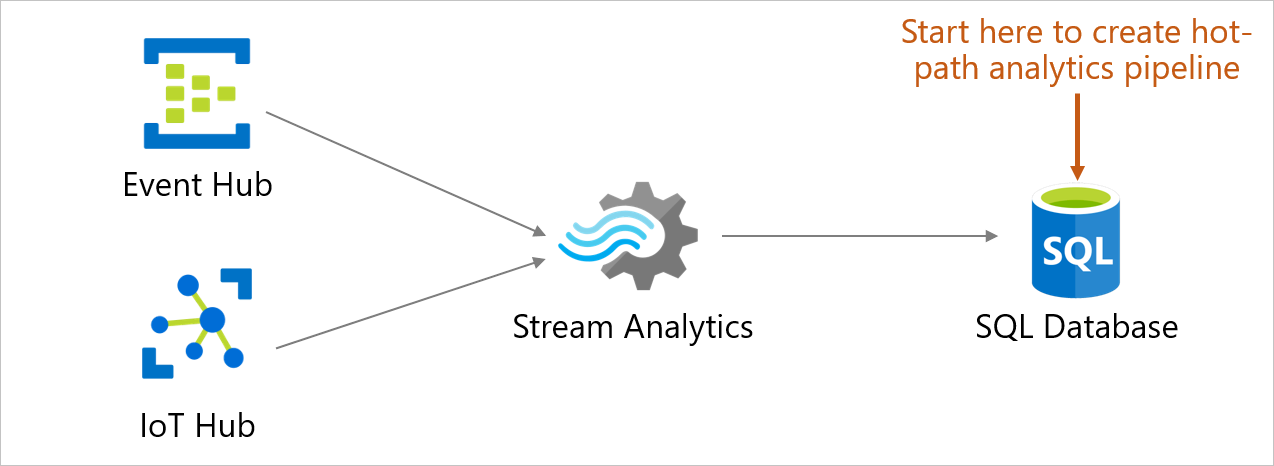
ユーザーは、Azure SQL Database 内のデータベースから直接リアルタイムのストリーミング データをテーブルに取り込み、それを処理、表示、分析できるようになりました。 それを Azure Stream Analytics を使用して Azure portal で行います。 このエクスペリエンスにより、コネクテッド カー、リモート監視、不正行為の検出など、さまざまなシナリオが可能になります。 Azure portal では、イベント ソース (イベント ハブ/IoT ハブ) を選択し、受信したリアルタイム イベントを表示して、イベントを格納するテーブルを選択できます。 また、ポータルで Azure Stream Analytics クエリ言語クエリを作成して、受信イベントを変換し、それを選択したテーブルに格納することもできます。 この新しいエントリ ポイントは、Stream Analytics に既に存在する作成と構成のエクスペリエンスに追加されます。 このエクスペリエンスはデータベースのコンテキストから開始されるため、Stream Analytics ジョブをすばやく設定し、Azure SQL Database 内のデータベースと Stream Analytics エクスペリエンスの間をシームレスに移動できます。
主な利点
- 最低限のコンテキスト切り替え:ポータルの Azure SQL Database のデータベースから開始し、他のサービスに切り替えることなくリアルタイム データをテーブルに取り込むことができます。
- ステップ数の削減:データベースとテーブルのコンテキストが Stream Analytics ジョブを事前構成するために使用されます。
- プレビュー データによる使いやすさの向上:イベント ソース (イベント ハブ/IoT ハブ) から受信したデータを選択したテーブルのコンテキストでプレビューできます
重要
Azure Stream Analytics ジョブは、Azure SQL Database、Azure SQL Managed Instance、または Azure Synapse Analytics に出力できます。 詳細については、「出力」を参照してください。
前提条件
この記事の手順を完了するには、次のリソースが必要です。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
- Azure SQL Database 内のデータベース。 詳細については、Azure SQL Database での単一データベースの作成に関する記事を参照してください。
- コンピューターがサーバーに接続するためのファイアウォール規則。 詳細については、サーバーレベルのファイアウォール規則の作成に関する記事を参照してください。
Stream Analytics 統合を構成する
Azure portal にサインインします。
ストリーミング データを取り込むデータベースに移動します。 [Stream analytics (preview)](Stream Analytics (プレビュー)) を選択します。

このデータベースへのストリーミング データの取り込み開始するには、 [作成] を選択し、ストリーミング ジョブに名前を付けて、 [Next: Input](次へ: 入力) を選択します。
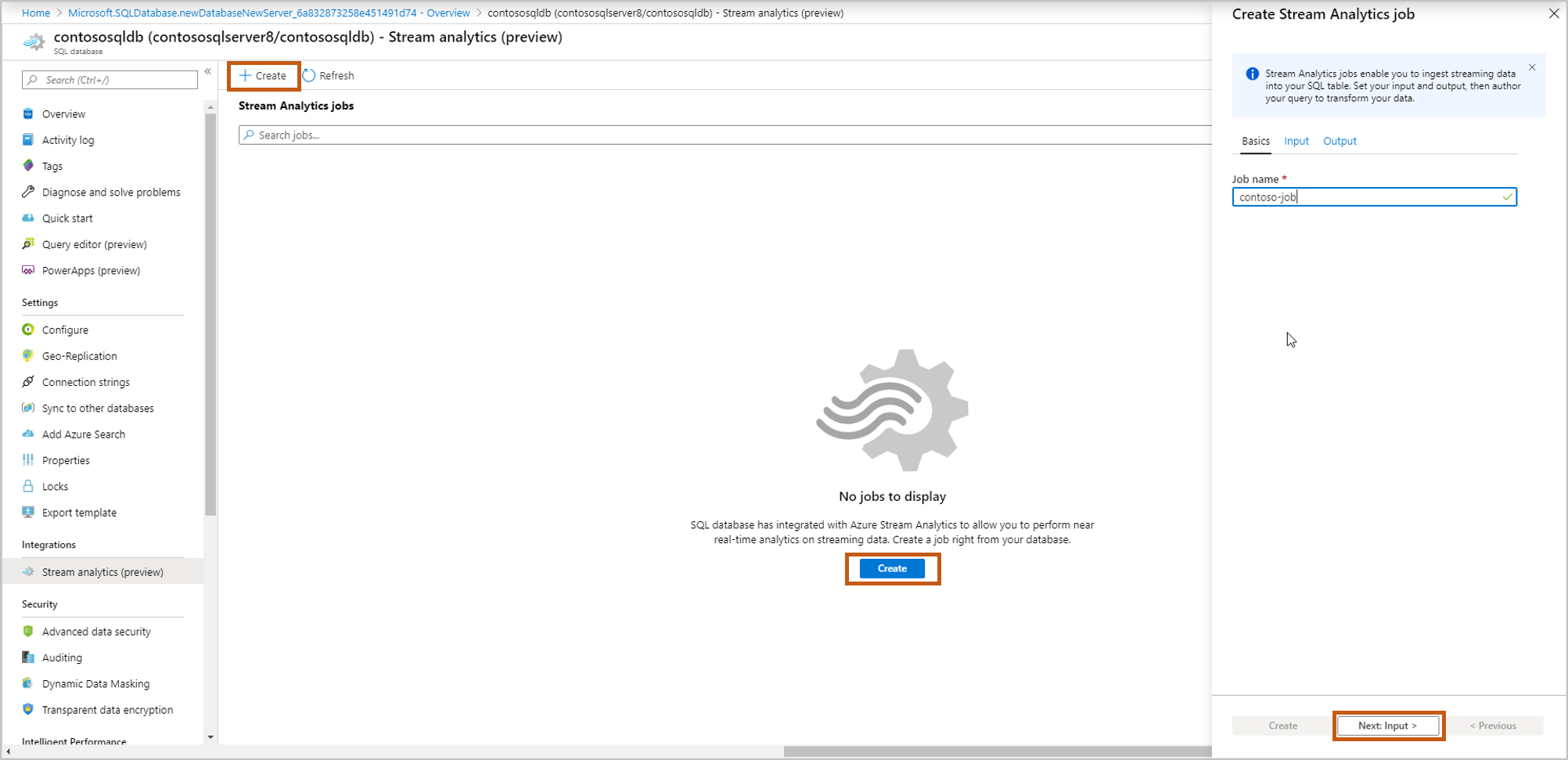
イベント ソースの詳細を入力し、 [Next:Output](次へ: 出力) を選択します。
[Input type](入力の種類) :イベントハブ/IoT ハブ
入力のエイリアス:イベント ソースを識別する名前を入力してください
サブスクリプション:Azure SQL Database のサブスクリプションと同じです
[イベント ハブの名前空間] :名前空間の名前
[イベント ハブ名] : 選択した名前空間内のイベント ハブの名前
[イベント ハブ ポリシー名] \(既定では新規作成):ポリシー名を指定します
[イベント ハブ コンシューマー グループ] \(既定では新規作成):コンシューマー グループ名を指定します
ここで作成する新しい各 Azure Stream Analytics ジョブに対してコンシューマー グループとポリシーを作成することをお勧めします。 コンシューマー グループでは、同時実行の閲覧者は 5 人しか許可されないので、ジョブごとに専用のコンシューマー グループを指定することで、その上限を超過した場合に発生するエラーを回避します。 専用ポリシーを利用すると、他のリソースに影響を及ぼさずに、キーを交代で利用したりアクセス許可を取り消したりできます。
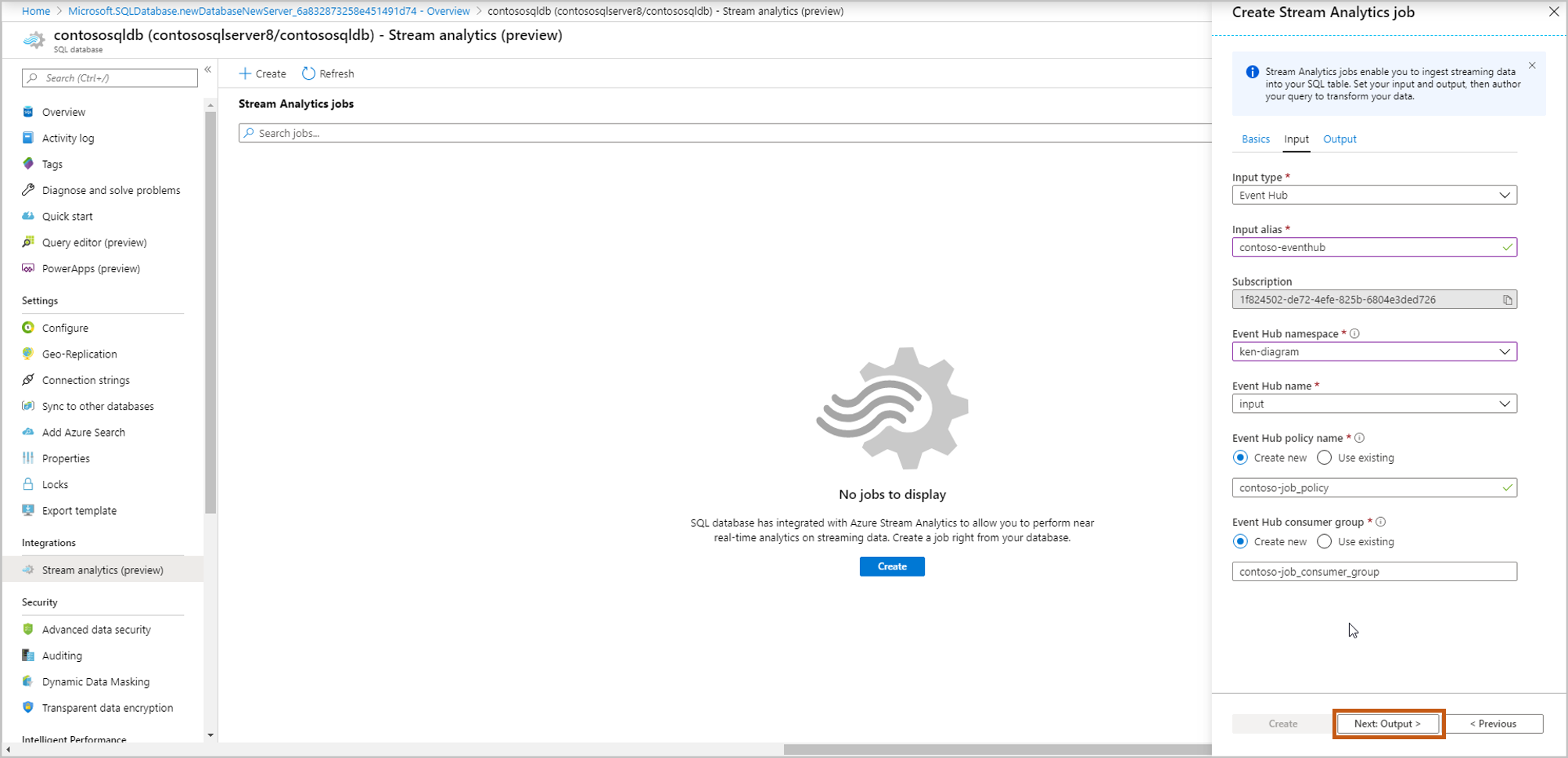
ストリーミング データを取り込むテーブルを選択します。 完了したら、 [作成] を選択します。
[ユーザー名] 、 [パスワード] :SQL サーバー認証用の資格情報を入力します。 [検証] を選択します。
テーブル: [新規作成] または [既存のデータを使用する] を選択します。 このフローでは、[作成] を選択します。 これにより、Stream Analytics ジョブの開始時に新しいテーブルが作成されます。
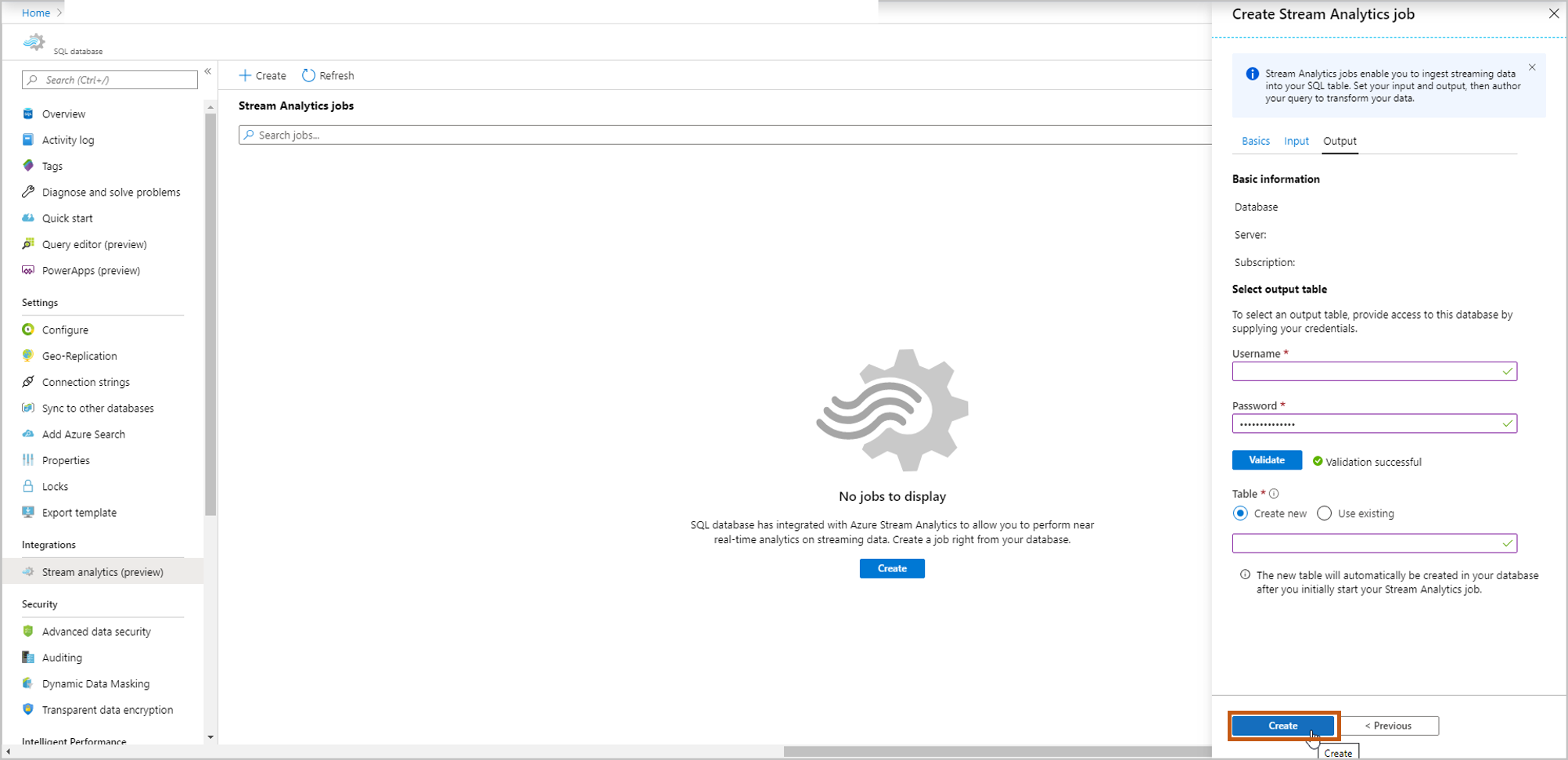
クエリ ページが開き、次の詳細が表示されます。
データの取り込み元となる [入力] (入力イベント ソース)
変換されたデータを格納する [出力] \(出力テーブル)
SELECT ステートメントを使用するサンプルの SAQL クエリ。
[入力のプレビュー] :入力イベント ソースからの最新の受信データのスナップショットを表示します。
- お使いのデータでのシリアル化の種類が、自動検出されます (JSON/CSV)。 JSON/CSV/AVRO に手動で変更することも可能です。
- 表形式または未加工の形式で受信データをプレビューできます。
- 表示されたデータが最新でない場合、 [更新] を選択して最新のイベントを表示します。
- 特定の時間範囲の受信イベントに対してクエリをテストするには、 [時間範囲の選択] を選択します。
- サンプルの JSON/CSV ファイルをアップロードしてクエリをテストするには [サンプル入力のアップロード] を選択します。 SAQL クエリのテストの詳細については、「サンプル データを利用した Azure Stream Analytics ジョブのテスト」を参照してください。
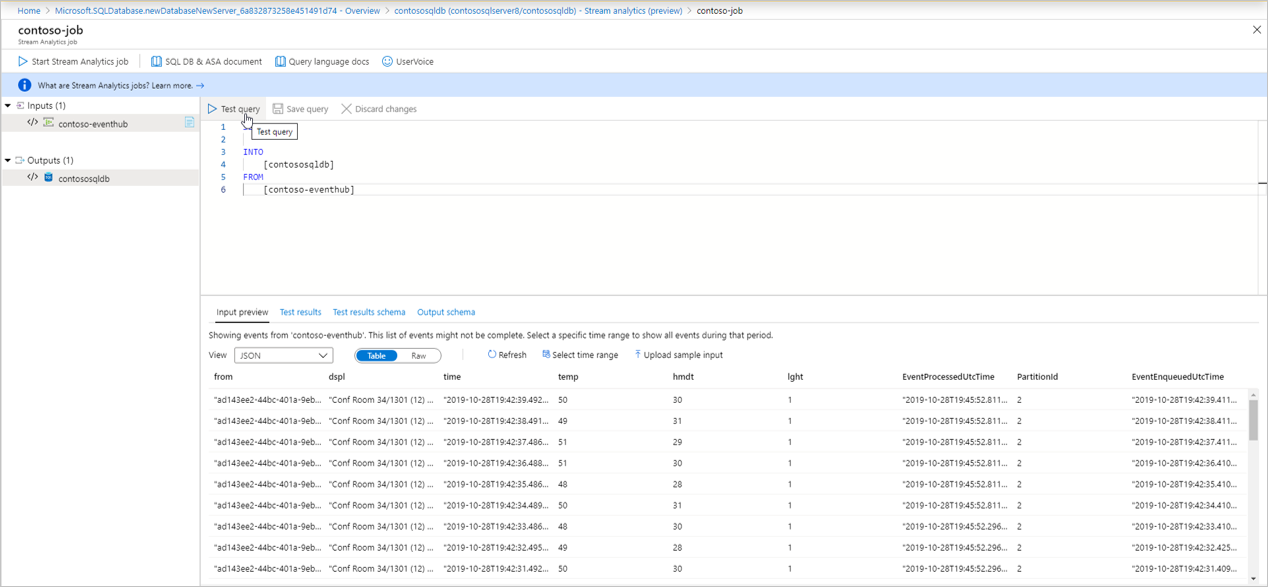
[テスト結果] : [Test query](クエリのテスト) を選択すると、ストリーミング クエリの結果が表示されます
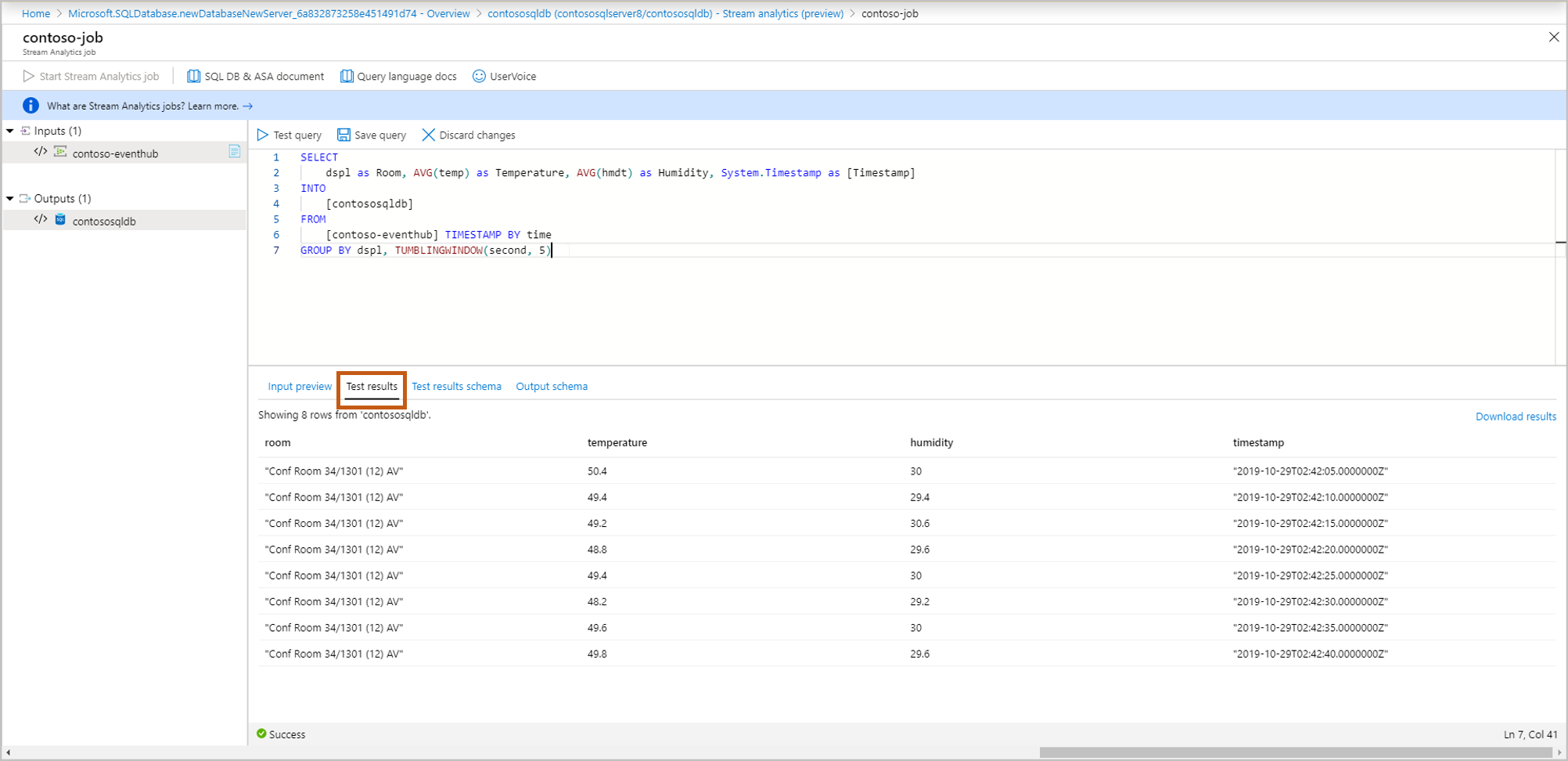
[Test results schema](テスト結果のスキーマ) :テスト後のストリーミング クエリの結果のスキーマを表示します。 テスト結果のスキーマが出力スキーマと一致していることを確認します。
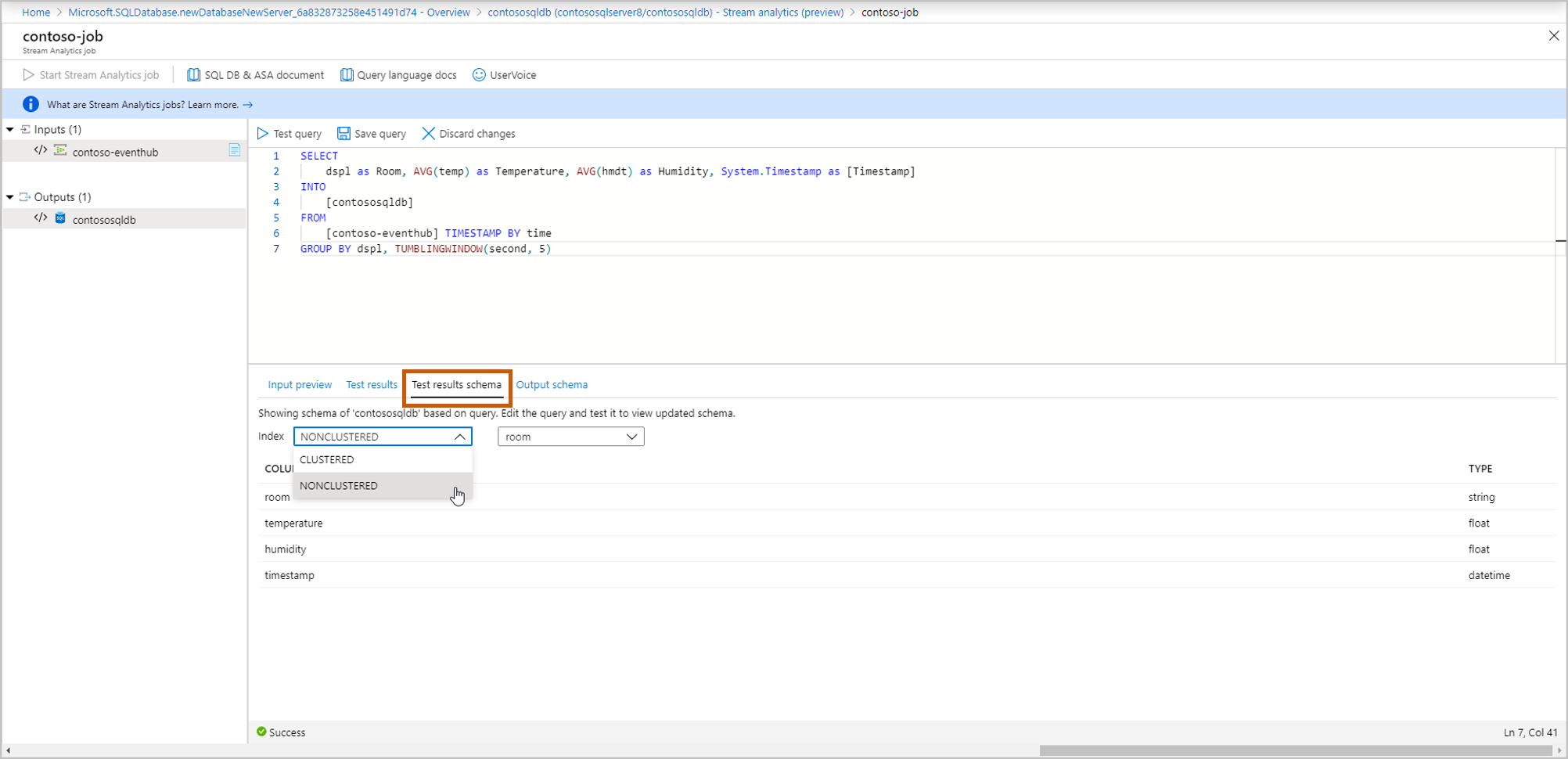
[Output Schema](出力スキーマ) :これには、手順 5 で選択したテーブルのスキーマが含まれます (新規または既存)。
- [新規作成]: 手順 5 でこのオプションを選択した場合は、ストリーミング ジョブを開始するまでスキーマが表示されません。 新しいテーブルを作成する場合は、適切なテーブル インデックスを選択します。 テーブル インデックス作成の詳細については、「クラスター化インデックスと非クラスター化インデックスの説明」を参照してください。
- [既存のものを使用]:手順 5. でこのオプションを選択した場合は、選択したテーブルのスキーマが表示されます。
クエリの作成およびテストを完了したら、[クエリの保存] を選択します。 [Start Stream Analytics job](Stream Analytics ジョブを開始する) を選択して、変換されたデータを SQL テーブルに取り込む操作を開始します。 次のフィールドを確定したら、ジョブを開始します。
[出力開始時刻] :これにより、ジョブの最初の出力時刻が定義されます。
- [今すぐ]:ジョブはすぐに開始され、新しい受信データを処理します。
- カスタム:ジョブはすぐに開始されますが、特定の時点 (過去または将来の可能性があります) のデータを処理します。 詳細については、「Azure Stream Analytics ジョブを開始する方法」を参照してください。
[ストリーミング ユニット] :Azure Stream Analytics の価格は、このサービスに入力されるデータを処理するために必要なストリーミング ユニットの数に基づいて決まります。 詳細については、「Azure Stream Analytics の価格」をご覧ください。
[出力データのエラー処理] :
- Retry: エラーが発生すると、Azure Stream Analytics により、書き込みが成功するまで無期限でイベントの書き込みが試行されます。 再試行にはタイムアウトがありません。 最終的には、再試行しているイベントによって後続のすべてのイベントの処理が妨げられます。 このオプションは既定の出力エラー処理ポリシーです。
- ドロップ:Azure Stream Analytics により、データ変換エラーを起こした出力イベントがドロップされます。 ドロップされたイベントを、後で再処理のために復旧することはできません。 (ネットワーク エラーなど) 一時的なエラーはすべて、出力エラー処理ポリシーの構成に関係なく、再試行されます。
[SQL Database output settings](SQL Database 出力の設定) :ご自分の以前のクエリ ステップのパーティション構成を継承し、テーブルへの複数のライターによる完全な並列トポロジを有効にするためのオプションです。 詳細については、「Azure SQL Database への Azure Stream Analytics の出力」を参照してください。
[Max batch count](最大バッチ カウント) :各一括挿入トランザクションで送信されるレコード数の推奨される上限です。
出力エラー処理の詳細については、「Azure Stream Analytics の出力エラーポリシー」を参照してください。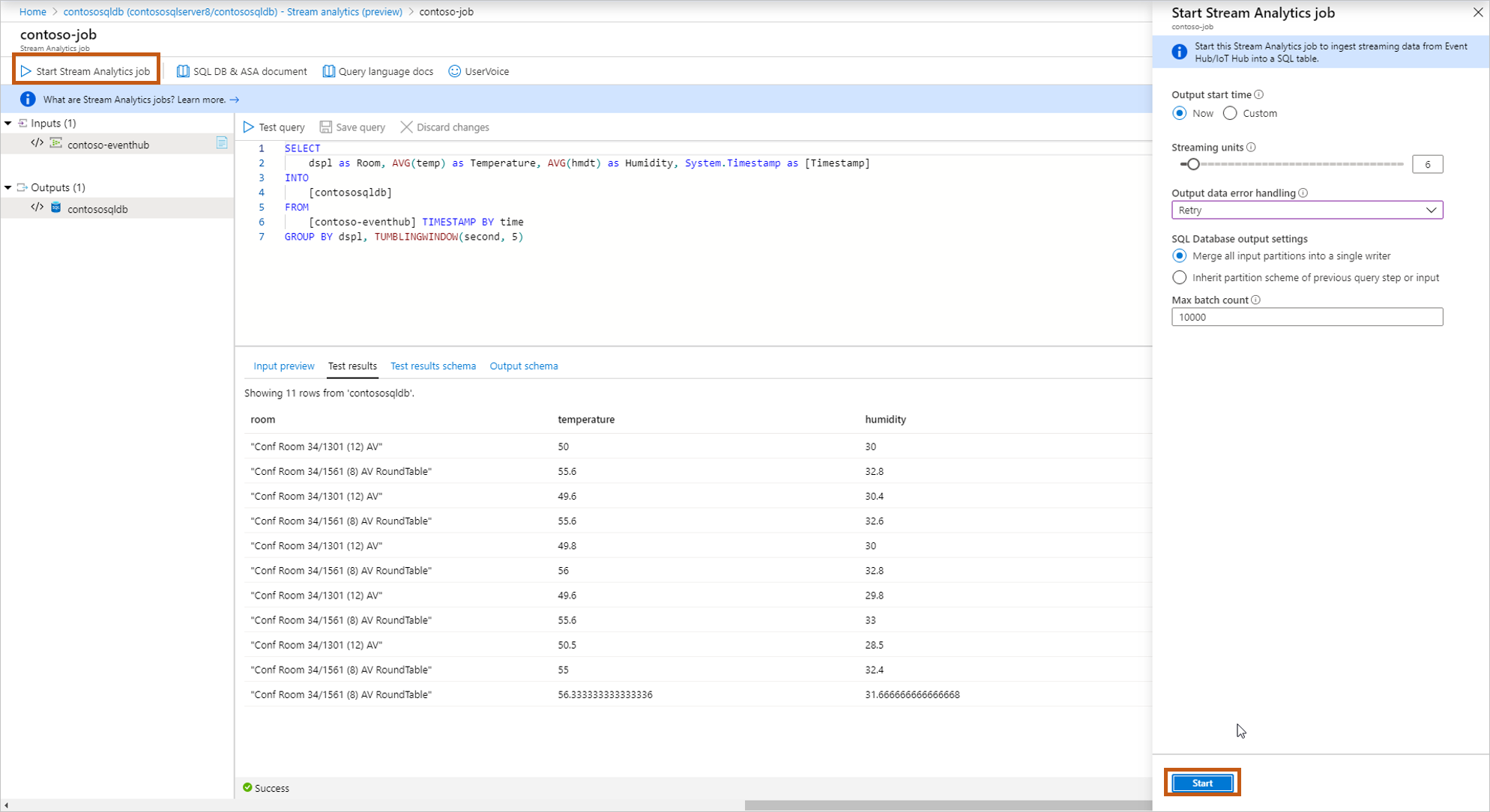
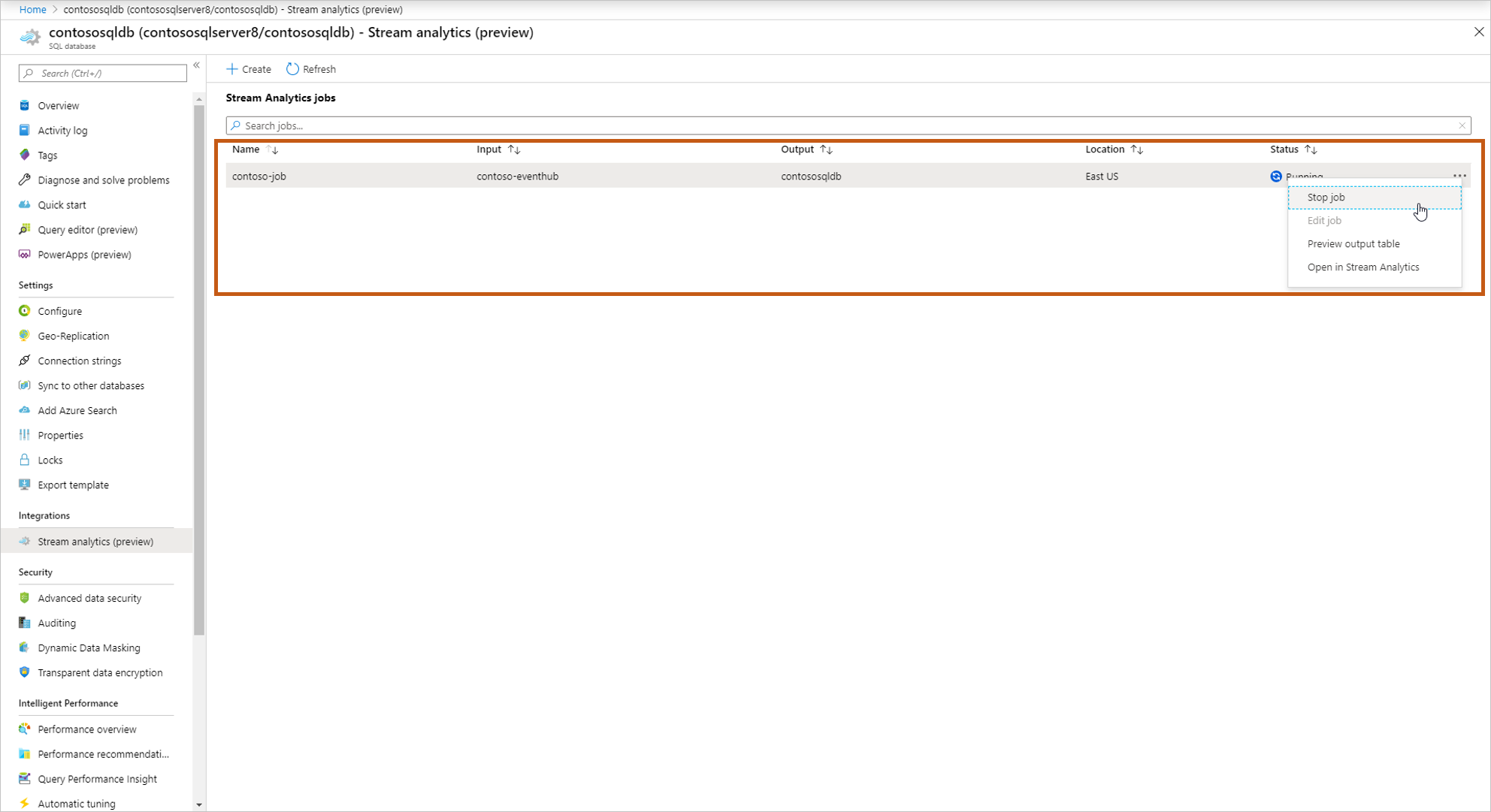
ジョブを開始すると、実行中のジョブが一覧に表示され、次のアクションを実行できるようになります。
[Start/stop the job](ジョブの開始/停止) :ジョブが実行されている場合は、ジョブを停止できます。 ジョブが停止している場合は、ジョブを開始できます。
[Edit job](ジョブの編集) :クエリを編集できます。 ジョブにさらに多くの変更を加える場合 (入力/出力を追加するなど)、Stream Analytics でジョブを開きます。 ジョブの実行中は、編集オプションは無効になっています。
[Preview output table](出力テーブルのプレビュー) :SQL クエリ エディターでテーブルをプレビューできます。
[Open in Stream Analytics](Stream Analytics で開く) :Stream Analytics でジョブを開いて、ジョブの詳細の監視およびデバッグを表示します。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示