Azure Backup には、バックアップの正常性を監視できる、Azure Monitor の組み込みメトリックのセットが用意されています。 また、メトリックが定義したしきい値を超えたときにトリガーされるアラート ルールを構成することもできます。
Azure Backup では、次の主な機能が提供されています。
- バックアップ項目のバックアップと復元の正常性に関連するすぐに使用できるメトリックと、それに関連する傾向を表示する機能
- バックアップ項目の正常性を効率的に監視するために、これらのメトリックに対するカスタム アラート ルールを記述する機能
- メール、ITSM、Webhook、ロジック アプリなど、Azure Monitor によってサポートされるさまざまな通知チャネルに、発生したメトリック アラートをルーティングする機能。
Azure Monitor のメトリックについて詳しくは、こちらをご覧ください。
サポートされるシナリオ
次のワークロードの種類に対する組み込みメトリックがサポートされます。
- Azure VM、Azure VM 内の SQL データベース
- Azure VM 内の SAP HANA データベース
- Azure Files
- Azure BLOB。
HANA インスタンスのワークロードの種類に対するメトリックは、現在はサポートされていません。
各リージョンとサブスクリプション内のすべての Recovery Services コンテナーについて、メトリックを一度に表示できます。 現在、さらに大きなスコープのメトリックを Azure portal で表示することは、サポートされていません。 メトリック アラート ルールの構成にも、同じ制限が適用されます。
サポートされるメトリック
現在、Azure Backup では次のメトリックがサポートされています。
バックアップ正常性イベント: このメトリックの値は、特定の時間内にコンテナーで発生した、バックアップ ジョブの正常性に関連する正常性イベントの数を表します。 バックアップ ジョブが完了すると、Azure Backup サービスによってバックアップ正常性イベントが作成されます。 ジョブの状態 (成功または失敗など) に基づいて、イベントに関連付けられるディメンションは異なります。
復元正常性イベント: このメトリックの値は、特定の時間内にコンテナーで発生した、復元ジョブの正常性に関連する正常性イベントの数を表します。 復元ジョブが完了すると、Azure Backup サービスによって復元正常性イベントが作成されます。 ジョブの状態 (成功または失敗など) に基づいて、イベントに関連付けられるディメンションは異なります。
Note
バックアップは継続的であり、ここではバックアップ ジョブの概念がないため、Azure BLOB ワークロードに対してのみ復元正常性イベントがサポートされます。
既定では、件数はコンテナー レベルで表示されます。 特定のバックアップ項目についての件数とジョブの状態を表示するには、サポートされている任意のディメンションでメトリックをフィルター処理できます。
次の表に、バックアップ正常性イベントと復元正常性イベントのメトリックでサポートされるディメンションを示します。
| ディメンション名 | 説明 |
|---|---|
| Datasource ID (データソース ID) | ジョブに関連付けられたデータソースの一意の ID。
SQL AG データベース バックアップの場合、このようなシナリオにはデータソース (VM) が含まれていないため、 [Datasource ID](データソース ID) フィールドは空です。 AG 内の特定のデータベースのメトリックを表示するには、 [Backup Instance ID](バックアップ インスタンス ID) フィールドを使用します。 |
| データソースの種類 | ジョブに関連付けられたデータソースの種類。 サポートされているデータソースの種類を次に示します。
|
| Backup Instance ID (バックアップ インスタンス ID) | ジョブに関連付けられたバックアップ インスタンスの ARM ID。 たとえば、 /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/testRG/providers/Microsoft.RecoveryServices/vaults/testVault/backupFabrics/Azure/protectionContainers/IaasVMContainer;iaasvmcontainerv2;testRG;testVM/protectedItems/VM;iaasvmcontainerv2;testRG;testVM のように指定します。 |
| Backup Instance Name (バックアップ インスタンス名) | 読みやすくするためのバックアップ インスタンスのフレンドリ名。
{protectedContainerName};{backupItemFriendlyName} のような形式です。 たとえば、 testStorageAccount;testFileShare のように指定します。 |
| 正常性状態 | ジョブが完了した後のバックアップ項目の正常性を表します。 次のいずれかの値になります: Healthy (正常)、Transient Unhealthy (一時的に異常)、Persistent Unhealthy (永続的に異常)、Transient Degraded (一時的に機能低下)、Persistent Degraded (永続的に機能低下)。
|
Azure portal でメトリックを表示する
Azure portal でメトリックを表示するには、次の手順のようにします。
Azure portal で、回復性>監視 + レポート>Metrics に移動します。
あるいは、[Recovery Services コンテナー] または [Azure Monitor] に移動し、[メトリック] を選択することもできます。
メトリックをフィルター処理するには、次のデータの種類を選択します。
- 範囲
- サブスクリプション (一度に 1 つしか選択できません)
- Recovery Services コンテナー/ リソースの種類としてのバックアップ コンテナー
- ロケーション
Note
- [Recovery Services コンテナー]/ 、[バックアップ コンテナー] の順に選択し、[メトリック] にアクセスすると、メトリックの範囲が事前に選択されています。
- リソースの種類として [Recovery Services コンテナー]/ 、[バックアップ コンテナー] の順に選択すると、バックアップ関連の組み込みメトリック (バックアップ正常性イベントおよび復元正常性イベント) を追跡できます。
- 現在、メトリックを表示できる範囲は、特定のサブスクリプションとリージョン内のすべての Recovery Services コンテナーです。 たとえば、TestSubscription1 の米国東部のすべての Recovery Services コンテナーなどです。
メトリックを表示するコンテナーまたはコンテナーのグループを選びます。
現在、メトリックを表示できる最大のスコープは、特定のサブスクリプションとリージョン内のすべての Recovery Services コンテナーです。 たとえば、TestSubscription1 の米国東部のすべての Recovery Services コンテナーなどです。
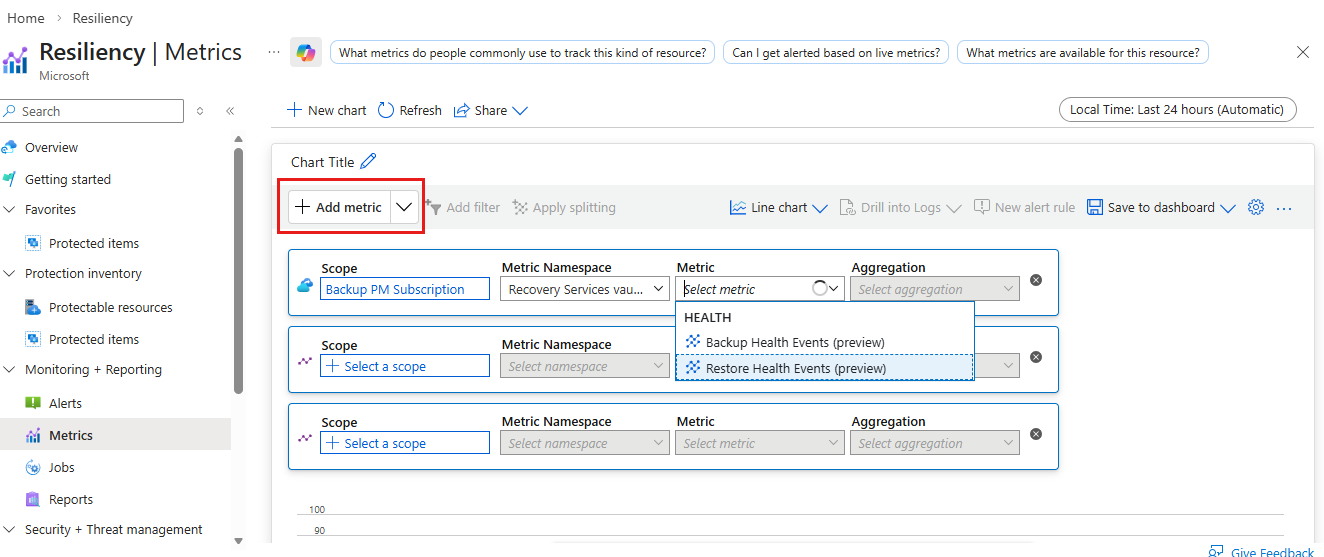
メトリックを選択して、"バックアップ正常性イベントまたは復元正常性イベント" を表示します。
これにより、コンテナーの正常性イベントの数を示すグラフがレンダリングされます。 画面の上部にあるフィルターを使用して、時間の範囲と集計の単位を調整できます。
異なるディメンションでメトリックをフィルター処理するには、 [フィルターの追加] ボタンをクリックして、関連するディメンション値を選びます。
- たとえば、Azure VM バックアップの正常性イベント数のみを表示する場合は、フィルター
Datasource Type = Microsoft.Compute/virtualMachinesを追加します。 - コンテナー内の特定のデータソースまたはバックアップ インスタンスの正常性イベントを表示するには、データソース ID またはバックアップ インスタンス ID のフィルターを使います。
- 失敗したバックアップの正常性イベントのみを表示するには、異常または機能低下の正常性状態に対応する値を選んで、HealthStatus のフィルターを使用します。
- たとえば、Azure VM バックアップの正常性イベント数のみを表示する場合は、フィルター


アラートを管理する
生成されたメトリック アラートを表示するには、次の手順のようにします。
- Azure portal で、回復性>監視 + レポート>Alerts に移動します。
- [シグナルの種類] = 、[メトリック]、[アラートの種類] = 、[構成済み] でフィルター処理します。
- アラートの詳細を表示し、状態を変更するには、アラートをクリックします。
Note
このアラートには、 [監視の状態] (発生/解決済み) と [アラートの状態] (新規/確認/終了) の 2 つのフィールドがあります。
- [アラートの状態] : このフィールドは編集できます (次のスクリーンショットを参照)。
- [監視の状態] : このフィールドは編集できません。 このフィールドは、サービス自体によってアラートが解決されるシナリオでよく使用されます。 たとえば、メトリック アラートの自動解決動作では、 [監視の状態] フィールドを使用してアラートが解決されます。
データソース アラートとグローバル アラート
アラート ルールの構成に基づいて、発生したアラートが回復性の [アラート] ブレードに表示されます。
アラートを表示およびフィルター処理する方法については、こちらを参照してください。
Note
現時点では、BLOB 復元アラートが発生した場合に、それらのアラートが [データソース アラート] の下に表示されるのは、アラート ルールの作成時に dimensions - datasourceId と datasourceType の両方を選択した場合のみです。 ディメンションが選択されていない場合、アラートは [グローバル アラート] の下に表示されます。
プログラムでのメトリックへのアクセス
PowerShell、CLI、REST API などのさまざまなプログラム クライアントを使用して、メトリック機能にアクセスできます。 詳しくは、Azure Monitor REST API のドキュメントをご覧ください。
アラートのシナリオの例
過去 24 時間以内に、あるコンテナーのすべてのトリガーされたバックアップが成功した場合、1 つのアラートを発生させる
アラート ルール: 過去 24 時間のバックアップ正常性イベント<が 1 件の場合、アラートを生成する:
Dimensions["HealthStatus"]!= "Healthy"
すべての失敗したバックアップ ジョブの後でアラートを発生させる
アラート ルール: 過去 5 分間のバックアップ正常性イベント>が 0 件の場合、、アラートを生成する:
- Dimensions["HealthStatus"]!= "健康"
- Dimensions["DatasourceId"]= "現在と将来のすべての値"
過去 24 時間に同じ項目で連続してバックアップ エラーが発生した場合、アラートを発生させる
アラート ルール: 過去 24 時間のバックアップ正常性イベント>が 1 件の場合、アラートを生成する:
- Dimensions["HealthStatus"]!= "健康"
- Dimensions["DatasourceId"]= "現在と将来のすべての値"
過去 24 時間に項目でバックアップ ジョブが実行されなかった場合、アラートを発生させる
アラート ルール: 過去 24 時間のバックアップ正常性イベントが< 1 件の場合、アラートを生成する:
Dimensions["DatasourceId"]= "現在と将来のすべての値"