Azure でのクラウド規模の分析内で Azure Databricks を使用する
Azure Databricks は、Microsoft Azure Cloud Services プラットフォーム用に最適化されたデータ分析プラットフォームです。 Azure Databricks により、データ集中型アプリケーションを開発するための次の 2 つの環境が提供されます:
Azure Databricks SQL を使用すると、データ レイク上でアドホック SQL クエリをすばやく実行できます。
Azure Databricks Data Science & Engineering (単に "ワークスペース" と呼ばれることもあります) は、Apache Spark に基づく分析プラットフォームです。 これは Azure に統合されており、ワンクリックでのセットアップ、効率化されたワークフロー、およびデータ エンジニア、データ サイエンティスト、機械学習エンジニアの間のコラボレーションを可能にする対話型ワークスペースを提供します。
クラウド規模の分析では、Azure Databricks Data Science & Engineering に重点を置きます。
概要
デプロイするすべてのデータ ランディング ゾーンについて、2 つの共有ワークスペースをデプロイするオプションがあります。 1 つはデータに依存しないインジェスト用、もう 1 つは分析用です。
- インジェストと処理のための Azure Databricks エンジニアリング ワークスペースは、Azure サービス プリンシパル経由で Azure Data Lake に接続します。 これは、データに依存しないインジェストによって呼び出されます。
- Azure Databricks 分析ワークスペースは、すべてのデータ科学者とデータ操作チームのためにプロビジョニングできます。 このワークスペースは、Microsoft Entra パススルー認証を使って Azure Data Lake に接続します。 Azure Databricks 分析とデータ サイエンス ワークスペースは、データ ランディング ゾーン全体の、ワークスペースにアクセスできるすべてのユーザーの間で共有されます。
自動のデータに依存しないインジェスト エンジンがある場合、Azure Databricks エンジニアリング ワークスペースは、Azure メタデータ サービス リソースグループで作成された Azure Key Vault インスタンスを使用して、未加工状態からエンリッチ済み状態へのデータ インジェスト パイプラインを実行します。
Azure Databricks 分析とワークスペースには、高コンカレンシー クラスターの作成を求めるクラスター ポリシーが必要です。 この種類のクラスターでは、Microsoft Entra 資格情報パススルーを使ってデータ レイクを探索できます。 詳細については、「Azure Data Lake Storage でのアクセス制御とデータ レイクの構成」を参照してください。
Azure Databricks を構成する
Azure Databricks のデプロイは、部分的には Azure Resource Manager テンプレートと YAML スクリプトによるパラメーター ベースですが、すべてのワークスペースを構成するには手作業もある程度必要です。
すべての Azure Databricks ワークスペースで Premium プランを使用する必要があり、それにより次の必要な機能が提供されます。
- コンピューティングの最適化された自動スケーリング
- Microsoft Entra 資格情報のパススルー認証
- 条件付き認証
- ノートブック、クラスター、ジョブ、テーブルのロールベースのアクセス制御
- 監査ログ
クラウド規模の分析に合わせるため、すべてのワークスペースで次の既定のデプロイ オプションを構成することをお勧めします。
- Azure Databricks のワークスペースは、データ ランディング ゾーン内の外部 Apache Hive メタストア インスタンスに接続します。
- databricks-monitoring-rg で Databricks の診断ログを Azure Log Analytics に送信するように各ワークスペースを構成します。
- 一連のルールに基づいてクラスターを作成する機能を制限クラスター ポリシーを実装します。 詳細については、「クラスター ポリシーの管理」を参照してください。
- 複数のクラスター ポリシーを定義します。 オンボード プロセスの一環として、データ ランディング ゾーン運用チームが使用するアクセス許可を各ターゲット グループに割り当てます。 既定では、クラスター作成アクセス許可は、運用チームに対してのみ付与されます。 異なるチームまたはグループに、クラスター ポリシーを使用するためのアクセス許可を付与します。
- クラスター ポリシーを Azure Databricks プールと組み合わせて使用し、アイドル状態のすぐに使用できるインスタンスのセットを維持することで、クラスターの起動時間と自動スケーリングの時間を短縮します。 詳細については、「プール」を参照してください。
- SPN の資格情報や接続文字列など、Azure Databricks のすべての操作シークレットを Azure Key Vault インスタンスから取得します。
- SCIM (クロスドメイン ID 管理システム) で使用するためのエンタープライズ アプリケーションを、ワークスペースごとに個別に構成します。 各ワークスペースへのアクセスとアクセス許可を制御するため、Azure Databricks ワークスペースにリンクします。 詳細については、「SCIM を使用してユーザーとグループをプロビジョニングする」と「Microsoft Entra ID 用に SCIM プロビジョニングを構成する」を参照してください。
警告
Azure Databricks SCIM インターフェイスを使用するように Azure Databricks ワークスペースを構成しないと、セキュリティ コントロールの提供方法に影響します。 自動プロセスから手動プロセスに移行し、すべてのデプロイ CI/CD パイプラインが中断されます。
すべての Databricks ワークスペースに、次のアクセス制御オプションが設定されます。
- ワークスペース可視性制御: 有効 (既定: 無効)
- クラスター可視性制御: 有効 (既定: 無効)
- ジョブ可視性制御: 有効 (既定: 無効)
Azure Databricks 分析ワークスペースでは、次のオプションを有効にすることができます。
- ノートブック エクスポート: 無効 (既定: 有効)
- ノートブック テーブル クリップボード機能: 無効 (既定: 有効)
- テーブル アクセス制御: 有効 (既定: 無効)
- Microsoft Entra 条件付きアクセス
Azure Databricks をデプロイする
新しいデータランディングゾーンのデプロイの一部として Azure Databricks ワークスペースをデプロイする場合。 次の図は、クラウド規模の分析に Azure Databricks 環境をデプロイするサンプル ワークフローを示したものです。
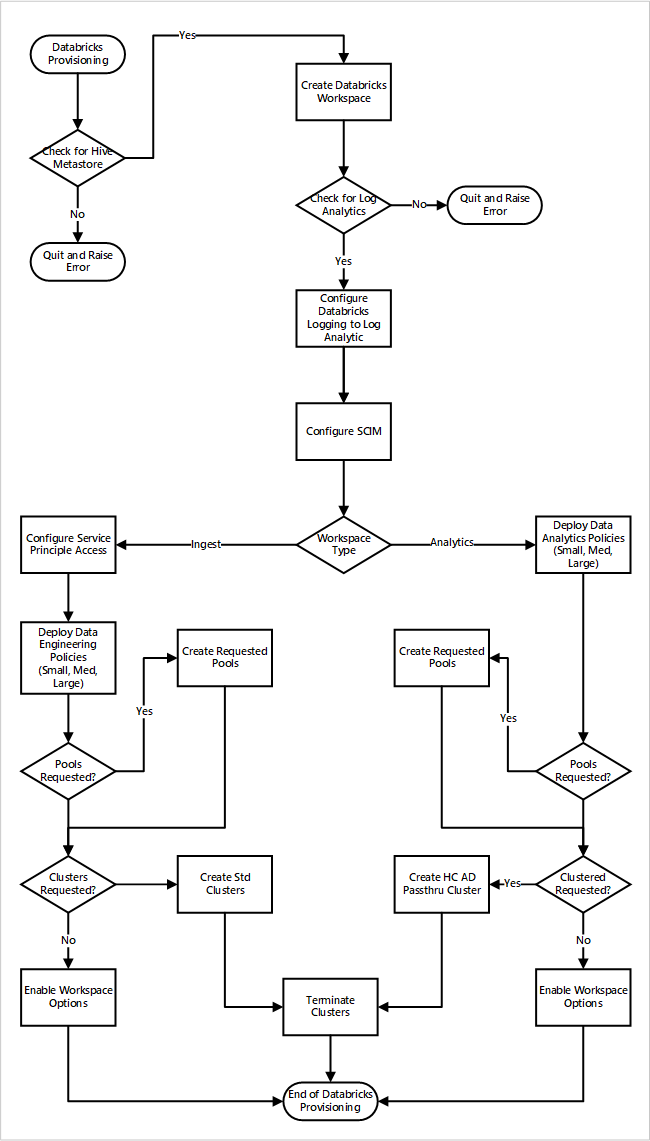
- プロビジョニング プロセスでは、まず、データ ランディング ゾーンに Apache Hive メタストア インスタンスが存在することが確認されます。 Apache Hive メタストアが見つからない場合は終了し、エラーが発生します。
- Apache Hive メタストアが正常に検出されると、ワークスペースが作成されます。
- このプロセスでは、データ ランディング ゾーン内の Log Analytics ワークスペースが確認されます。 Log Analytics ワークスペースが見つからない場合は、終了してエラーが発生します。
- ワークスペースごとに、Microsoft Entra アプリケーションが作成されて、SCIM が構成されます。
Azure Databricks 取り込みワークスペースの場合:
- このプロセスでは、サービス プリンシパル アクセスを使用してワークスペースが構成されます。
- データ プラットフォーム運用チームによって定義された Data Engineering ポリシーがデプロイされます。
- データ ランディング ゾーン運用チームが Databricks プールまたはクラスターを要求している場合は、それらをデプロイ プロセスに統合できます。
- これにより、Azure Databricks エンジニアリング ワークスペースに固有のワークスペース オプションが有効になります。
Azure Databricks 分析ワークスペースの場合:
- このプロセスでは、データ プラットフォーム運用チームによって定義されたデータ分析ポリシーがデプロイされます。
- データ ランディング ゾーン運用チームが Databricks プールまたはクラスターを要求している場合は、それらをデプロイ プロセスに統合できます。
- これにより、Azure Databricks エンジニアリング ワークスペースに固有のワークスペース オプションが有効になります。
外部の Hive metastore
Azure Databricks ワークスペースのデプロイにおいて:
- 新しいグローバル初期化スクリプトによって、すべてのクラスターの Apache Hive メタストアの設定が構成されます。 このスクリプトは、新しいグローバル初期化スクリプト API によって管理されます。
新しいグローバル初期化スクリプト API はパブリック プレビュー段階です。 Azure Databricks のパブリック プレビュー機能は、運用環境向けに準備されており、サポート チームによってサポートされます。 詳細については、「Azure Databricks プレビュー リリース」を参照してください。
- このソリューションでは、Azure Database for MySQL を使用して、Apache Hive メタストア インスタンスが格納されます。 このデータベースは、コスト効率および Apache Hive との高い互換性のために選択されました。
次の手順
クラウド規模の分析では、次のガイドラインに従って Azure Databricks が統合されます。