Azure Data Lake Storage Gen2 でのアクセス制御とデータ レイクの構成
この記事は、Azure Data Lake Storage Gen2 でのアクセス制御メカニズムを評価し、理解するのに役立ちます。 これらのメカニズムには、Azure ロールベースのアクセス制御 (RBAC) とアクセス制御リスト (ACL) が含まれます。 学習内容は、次のとおりです。
- Azure RBAC と ACL の間でアクセスを評価する方法
- これらのメカニズムのいずれかまたは両方を使用してアクセス制御を構成する方法
- これらのアクセス制御メカニズムをデータ レイク実装パターンに適用する方法
ストレージ コンテナー、セキュリティ グループ、Azure RBAC、ACL に関する基本的な知識が必要です。 説明の枠組みとして、未加工ゾーン、エンリッチ ゾーン、キュレーション ゾーンという一般的なデータ レイク構造に言及しています。
このドキュメントは、データ アクセス管理と共に使用できます。
組み込みの Azure RBAC ロールを使用する
Azure Storage には、サービス管理とデータという 2 つのアクセスのレイヤーがあります。 サブスクリプションとストレージ アカウントにはサービス管理レイヤーを介してアクセスできます。 コンテナー、BLOB、およびその他のデータ リソースには、データ レイヤーを介してアクセスします。 たとえば、Azure のストレージ アカウントの一覧が必要な場合は、管理エンドポイントに要求を送信します。 ストレージ アカウント内のファイル システム、フォルダー、またはファイルの一覧が必要な場合は、サービス エンドポイントに要求を送信します。
ロールには、管理レイヤーまたはデータ レイヤーにアクセスするためのアクセス許可が含まれている場合があります。 閲覧者ロールによって、管理レイヤー リソースへの読み取り専用アクセスが許可されますが、データへの読み取りアクセスは許可されません。
所有者、共同作成者、閲覧者、ストレージ アカウント共同作成者などのロールは、セキュリティ プリンシパルがストレージ アカウントを管理することを許可します。 しかし、これらはそのアカウント内のデータへのアクセスは提供しません。 データ アクセス用に明示的に定義されたロールのみが、セキュリティ プリンシパルがデータにアクセスすることを許可します。 これらのロール (閲覧者を除く) は、データにアクセスするためのストレージ キーへのアクセスを取得します。
組み込みの管理ロール
組み込みの管理ロールを次に示します。
- 所有者:リソースへのアクセスを含め、すべてを管理します。 このロールでは、キーへのアクセスが提供されます。
- 共同作成者: リソースへのアクセス以外のすべてを管理します。 このロールでは、キーへのアクセスが提供されます。
- ストレージ アカウント共同作業者: ストレージ アカウントの完全な管理。 このロールでは、キーへのアクセスが提供されます。
- 閲覧者:リソースを読み取って一覧表示します。 このロールでは、キーへのアクセスは提供されません。
組み込みのデータ ロール
組み込みのデータ ロールを次に示します。
- ストレージ BLOB データ所有者: 所有権の設定や POSIX アクセス制御の管理を含む、Azure Storage の BLOB コンテナーおよびデータへのフル アクセス。
- ストレージ BLOB データ共同作成者:Azure Storage コンテナーと BLOB の読み取り、書き込み、削除を行います。
- ストレージ BLOB データ閲覧者:Azure Storage コンテナーと BLOB の読み取りと一覧表示を行います。
ストレージ BLOB データ所有者は、すべての変更操作へのフル アクセスが付与されているスーパーユーザー ロールです。 これらの操作には、ディレクトリまたはファイルの所有者や、所有者ではないディレクトリおよびファイルの ACL の設定が含まれます。 スーパー ユーザーのアクセス権は、リソースの所有者を変更するために承認された唯一の方法です。
Note
Azure RBAC の割り当ては、反映されて有効になるまでに最大 5 分かかることがあります。
アクセスが評価される方法
セキュリティ プリンシパルベースの認可の際に、システムは次の順序で権限を評価します。 詳細については、次の図を確認してください。
- Azure RBAC が最初に評価され、ACL の割り当てよりも優先されます。
- RBAC に基づいて操作が全面的に認可される場合、ACL はまったく評価されません。
- 操作が全面的に認可されない場合は、ACL が評価されます。
詳細については、「権限を評価する方法」を参照してください。
Note
このアクセス許可モデルは Azure Data Lake Storage にのみ適用されます。 これは、階層型名前空間が有効になっていない、汎用ストレージまたは BLOB ストレージには適用されません。
この説明には、共有キーと SAS 認証方法は含まれていません。 また、スーパーユーザー アクセスを提供するストレージ BLOB データ所有者組み込みロールが、セキュリティ プリンシパルに割り当てられているシナリオも除外されます。
アクセスが ID によって監査されるように allowSharedKeyAccess を false に設定します。

特定の操作に必要な ACL ベースのアクセス許可の詳細については、「Azure Data Lake Storage Gen2 のアクセス制御リスト」を参照してください。
Note
- アクセス制御リストは、ゲスト ユーザーを含め、同じテナント内のセキュリティ プリンシパルにのみ適用されます。
- クラスターにアタッチするためのアクセス許可を持つすべてのユーザーは、Azure Databricks マウント ポイントを作成できます。 サービス プリンシパルの資格情報または Microsoft Entra パススルー オプションを使用してマウント ポイントを構成します。 作成時にアクセス許可は評価されません。 アクセス許可は、操作でマウント ポイントが使用されるときに評価されます。 クラスターにアタッチできるすべてのユーザーが、マウント ポイントの使用を試みることができます。
- ユーザーは、Azure Databricks または Azure Synapse Analytics でテーブル定義を作成する場合、基になるデータに対する読み取りアクセスを持っている必要があります。
Azure Data Lake Storage へのアクセスを構成する
Azure RBAC、ACL、またはその両方の組み合わせを使用して、Azure Data Lake Storage のアクセス制御を設定します。
Azure RBAC のみを使用してアクセスを構成する
コンテナーレベルのアクセス制御が十分であれば、Azure RBAC の割り当ては、データのセキュリティ保護のための簡単な管理アプローチを提供します。 アクセス制御リストを使用することをお勧めするのは、制限付きのデータ アセットが多数ある場合や、細かなアクセス制御が必要な場合です。
ACL のみを使用してアクセスを構成する
クラウド規模の分析用のアクセス制御リスト構成の推奨事項を次に示します。
アクセス制御エントリは、個々のユーザーまたはサービス プリンシパルではなく、セキュリティ グループに割り当てます。 詳細については、「セキュリティ グループの使用と個々のユーザーの違い」を参照してください。
グループに対するユーザーの追加または削除を行う場合、Data Lake Storage を更新する必要はありません。 また、グループを使用すると、ファイルまたはフォルダー ACL ごとの 32 個のアクセス制御エントリを超える可能性が低くなります。 4 つの既定エントリを除くと、権限割り当てには 28 個のエントリしか残りません。
グループを使用しても、ディレクトリ ツリーの最上位レベルに多くのアクセス制御エントリがある可能性があります。 この状況は、さまざまなグループに細かな権限が必要な場合に発生します。

Azure RBAC とアクセス制御リストの両方を使用してアクセスを構成する
ストレージ BLOB データ共同作成者とストレージ BLOB データ閲覧者のアクセス許可では、ストレージ アカウントではなくデータへのアクセスが提供されます。 アクセスはストレージ アカウント レベルまたはコンテナー レベルで付与できます。 ストレージ BLOB データ共同作成者が割り当てられた場合、ACL を使用してアクセスを管理することはできません。 ストレージ BLOB データ閲覧者が割り当てられた場合には、ACL を使用して昇格された書き込み権限を付与できます。 詳細については、「アクセスが評価される方法」を参照してください。
このアプローチが適しているのは、ほとんどのユーザーが読み取りアクセスを必要とし、ごく少数のユーザーが書き込みアクセスを必要とするというシナリオです。 データ レイクのゾーンによってストレージ アカウントが異なり、データ資産によってコンテナーが異なる可能性があります。 データ レイクのゾーンをコンテナーで表し、データ資産をフォルダーで表すことができます。
入れ子のアクセス制御リスト グループのアプローチ
入れ子の ACL グループに対して 2 つのアプローチがあります。
オプション 1: 親実行グループ
ファイルとフォルダーを作成する前に、親グループから始めます。 そのグループ実行アクセス許可を、コンテナー レベルで既定 ACL とアクセス ACL の両方に割り当てます。 次に、データ アクセスを必要とするグループを親グループに追加します。
警告
再帰的な削除がある場合、このパターンはお勧めしません。代わりに、「オプション 2: アクセス制御リストの [その他] のエントリ」の使用をお勧めします。
この手法は、入れ子グループと呼ばれます。 メンバー グループが、親グループのアクセス許可を継承します。これにより、すべてのメンバー グループにグローバル実行アクセス許可が付与されます。 メンバー グループには、これらのアクセス許可が継承されるため、実行アクセス許可は必要ありません。 入れ子を増やすことで、柔軟性と機敏性が向上します。 チームまたは自動化されたジョブを表すセキュリティ グループを、データ アクセスの読み取りグループと書き込みグループに追加します。
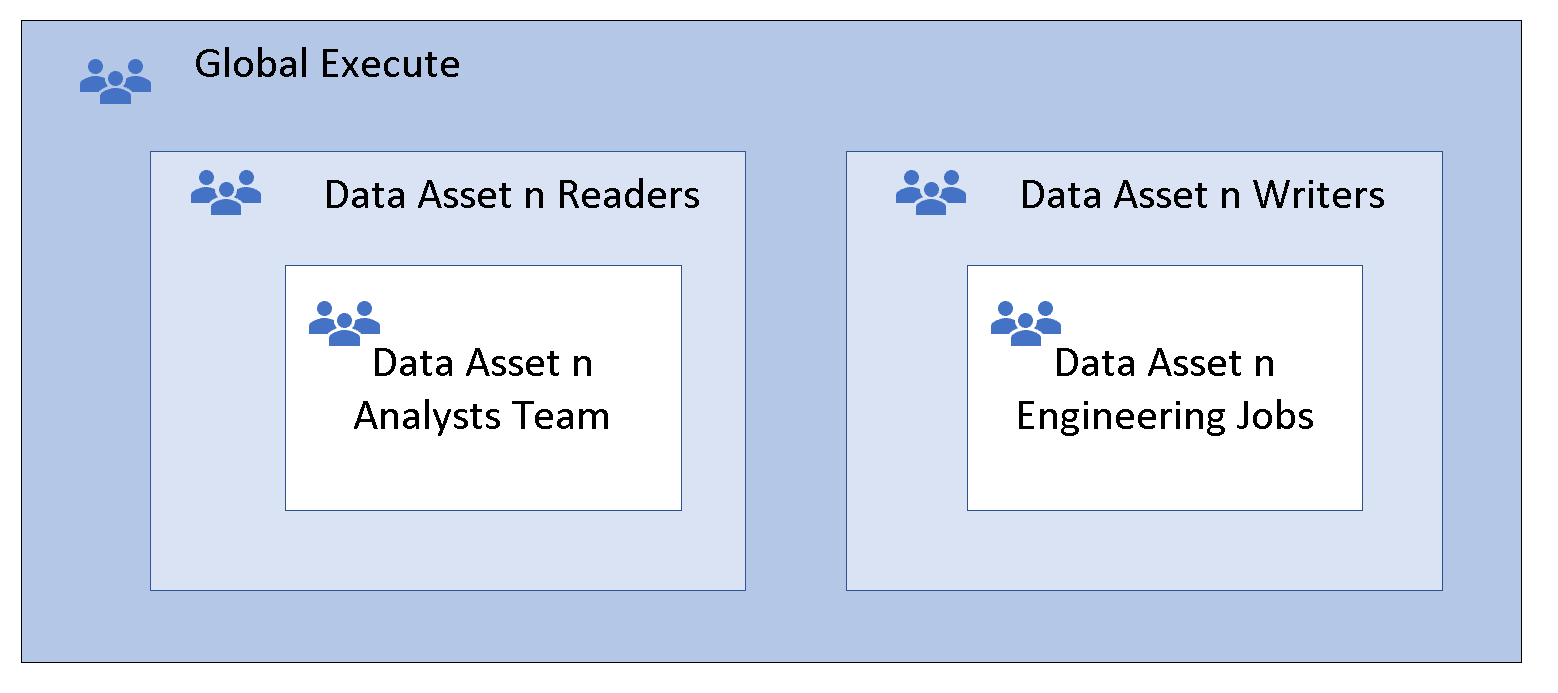
オプション 2: アクセス制御リストの [その他] のエントリ
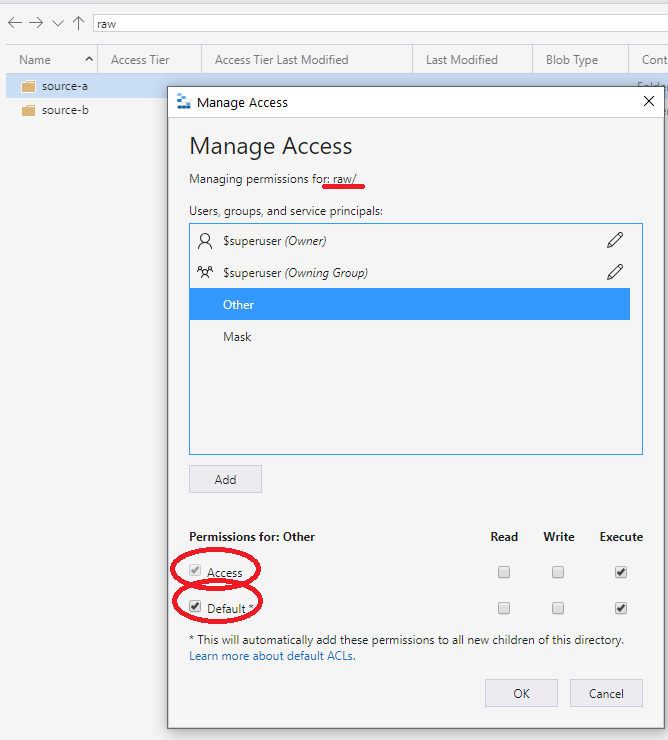
推奨されるアプローチは、コンテナーまたはルートで設定された ACL の [その他] のエントリの使用です。 次の画面に示すように、既定 ACL とアクセス ACL を指定します。 このアプローチにより、ルート レベルから最下レベルまでパスのすべての部分に実行アクセス許可が付与されます。
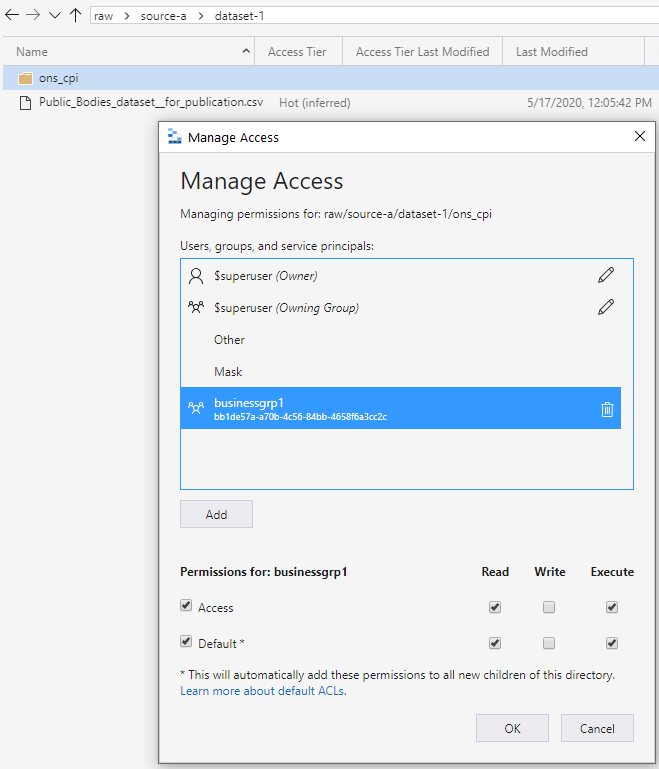
この実行権限は、追加されるすべての子フォルダーへと伝達されます。 アクセス許可は、目的のアクセス グループが読み取りや実行のためにアクセス許可を必要とする深さまで伝達されます。 次の画面に示すように、このレベルはチェーンの最も低い部分にあります。 このアプローチによって、データを読み取るアクセス権がグループに付与されます。 このアプローチは、書き込みアクセスでも同様に機能します。
推奨されるデータ レイク ゾーンのセキュリティ
次に示す使用方法は、各データ レイク ゾーンの推奨セキュリティ パターンです。
- 未加工では、セキュリティ プリンシパル名 (SPN) のみを使用してデータへのアクセスを許可する必要があります。
- エンリッチでは、セキュリティ プリンシパル名 (SPN) のみを使用してデータへのアクセスを許可する必要があります。
- キュレーションでは、セキュリティ プリンシパル名 (SPN) とユーザー プリンシパル名 (UPN) の両方を使用してアクセスを許可する必要があります。
Microsoft Entra セキュリティ グループを使用するシナリオの例
グループを設定するには、さまざまな方法があります。 たとえば、サーバーによって生成されるログ データを保持する /LogData という名前のディレクトリがあると想定します。 Azure Data Factory により、そのフォルダーにデータが取り込まれます。 サービス エンジニアリング チームの特定のユーザーが、ログをアップロードし、このフォルダーの他のユーザーを管理します。 Azure Databricks の分析およびデータ サイエンス ワークスペース クラスターでは、このフォルダーのログを分析できます。
これらのアクティビティを有効にするには、LogsWriter グループと LogsReader グループを作成します。 次のアクセス許可を割り当てます。
LogsWriterグループを、rwxというアクセス許可で、/LogDataディレクトリの ACL に追加します。LogsReaderグループを、r-xというアクセス許可で、/LogDataディレクトリの ACL に追加します。- Data Factory に対するサービス プリンシパル オブジェクトまたは管理サービス ID (MSI) を、
LogsWritersグループに追加します。 - サービス エンジニアリング チームのユーザーを、
LogsWriterグループに追加します。 - Azure Databricks には、Azure Data Lake ストアへの Microsoft Entra パススルーが構成されています。
サービス エンジニアリング チームのユーザーが別のチームに移った場合は、そのユーザーを LogsWriter グループから削除するだけです。
そのユーザーをグループに追加せず、代わりにそのユーザーの専用 ACL エントリを追加していた場合は、その ACL エントリを /LogData ディレクトリから削除する必要があります。 また、/LogData ディレクトリのディレクトリ階層全体のすべてのサブディレクトリとファイルから、そのエントリを削除する必要もあります。
Azure Synapse Analytics データ アクセス制御
Azure Synapse ワークスペースをデプロイするには、Azure Data Lake Storage Gen2 アカウントが必要です。 Azure Synapse Analytics によって、いくつかの統合シナリオでプライマリ ストレージ アカウントが使用されます。また、データはコンテナーに格納されます。 コンテナーの /synapse/{workspaceName} というフォルダーの下に、Apache Spark テーブルおよびアプリケーション ログが含まれます。 ワークスペースでは、インストールしたライブラリを管理するためにコンテナーも使用されます。
Azure portal でのワークスペース デプロイ中に、既存のストレージ アカウントを指定するか、新しいものを作成します。 指定するストレージ アカウントは、ワークスペースのプライマリ ストレージ アカウントです。 デプロイ プロセスでは、 [ストレージ BLOB データ共同作成者] ロールを使用して、指定した Data Lake Storage Gen2 アカウントへのアクセス権がワークスペース ID に付与されます。
Azure portal 外でワークスペースをデプロイする場合は、Azure Synapse Analytics ワークスペース ID をストレージ BLOB データ共同作成者ロールに手動で追加します。 最小限の特権の原則に従うために、ストレージ BLOB データ共同作成者のロールはコンテナー レベルで割り当てることをお勧めします。
ジョブを介してパイプライン、ワークフロー、ノートブックを実行する場合、これらはワークスペース ID 権限のコンテキストを使用します。 いずれかのジョブがワークスペースのプライマリ ストレージに対して読み取りまたは書き込みを行う場合、ワークスペース ID は、 [ストレージ BLOB データ共同作成者] を介して付与された読み取り/書き込みアクセス許可を使用します。
ユーザーがスクリプトの実行や開発のためにワークスペースにサインインする場合、ユーザーのコンテキスト権限はプライマリ ストレージに対する読み取り/書き込みアクセスを許可します。
アクセス制御リストを使用した Azure Synapse Analytics のきめ細かいデータ アクセス制御
データ レイクのアクセス制御を設定する場合、組織によっては、細かなレベルのアクセス権が必要です。 組織には、組織内の一部のグループが見ることができない機密データがある場合があります。 Azure RBAC で許可されるのは、ストレージ アカウントとコンテナー レベルのみの読み取りまたは書き込みです。 ACL を使用すると、フォルダーやファイル レベルでのきめ細かいアクセス制御を設定して、特定のグループに対してデータのサブセットの読み取り/書き込みを許可することができます。
Spark テーブルを使用する場合の考慮事項
Spark プールで Apache Spark テーブルを使用すると、ウェアハウス フォルダーが作成されます。 このフォルダーは次のようにワークスペース プライマリ ストレージのコンテナーのルート内にあります。
synapse/workspaces/{workspaceName}/warehouse
Azure Synapse Spark プールに Apache Spark テーブルを作成する予定がある場合は、Spark テーブルを作成するコマンドを実行するグループに対して、ウェアハウス フォルダーへの書き込みアクセス許可を付与します。 コマンドがパイプラインでトリガーされたジョブを介して実行される場合には、ワークスペース MSI に書き込み権限を付与します。
次の例では、Spark テーブルが作成されます。
df.write.saveAsTable("table01")
詳細については、「Synapse ワークスペースのアクセス制御を設定する方法」を参照してください。
Azure Data Lake へのアクセスの概要
データ レイク アクセスを管理する 1 つのアプローチがすべてのユーザーに適するということはありません。 データ レイクの主要な利点は、フリクションのないデータ アクセスが提供されることです。 実際には、組織ごとに、データに対して多様なレベルのガバナンスと制御が必要です。 ある組織では、集権的なチームによって、厳格な内部管理下でアクセスを管理してグループをプロビジョニングしています。 別の組織では、機敏性が高い、分散型の制御を行っています。 ガバナンスのレベルを満たすアプローチを選択します。 その選択によって、データへのアクセスを得る際に過度の遅延やフリクションが生じないようにします。