Anomaly Detector 一変量 API を使用するためのベスト プラクティス
重要
2023 年 9 月 20 日以降は、新しい Anomaly Detector リソースを作成できなくなります。 Anomaly Detector サービスは、2026 年 10 月 1 日に廃止されます。
Anomaly Detector API はステートレスな異常検出サービスです。 結果の精度とパフォーマンスは、次の事項によって影響を受けます。
- 時系列データの準備方法。
- 使用した Anomaly Detector API パラメーター。
- API 要求のデータ ポイント数。
この記事では、この API を使用してデータに関する最良の結果を得るためのベスト プラクティスについて説明します。
バッチ (全体) または最新バージョン (直近) の異常検出をポイントを使用する場合
Anomaly Detector API のバッチの検出エンドポイントにより、時系列データ全体を通して、異常を検出することができます。 この検出モードにおいて 1 つの統計モデルが作成され、データ セット内の各ポイントに適用されます。 時系列が特徴を下回る場合、バッチの検出を使用して 1 つの API 呼び出しで、データをプレビューします。
- 季節による時系列。不定期異常あり。
- フラットな傾向のある時系列。不定期に上昇/下落あり。
バッチの異常検出をリアルタイム データ監視に使用したり、上記の特性を持たない時系列データで使用したりすることはお勧めしません。
バッチの検出では 1 つのモデルのみが作成され、適用されます。各ポイントの検出は、全系列のコンテキストで実行されます。 時系列データが季節に関係なく上下する傾向がある場合、ある時点での変化 (データの下落と上昇) はモデルで見落とされる可能性があります。 同様に、データ セット内の後からのものよりも重要性が低い一部の変更ポイントは、モデルに組み込まれるだけの重要性がないとみなされる可能性があります。
バッチの検出は、分析対象のポイント数により、リアルタイムのデータ監視を実施する際に、直近ポイントの異常状態の検出よりも遅くなります。
リアルタイムのデータの監視の場合、最新のデータ ポイントのみの異常状態の検出をお勧めします。 最新のポイント検出を継続的に適用することにより、ストリーミング データの監視をより効率的かつ正確に行えます。
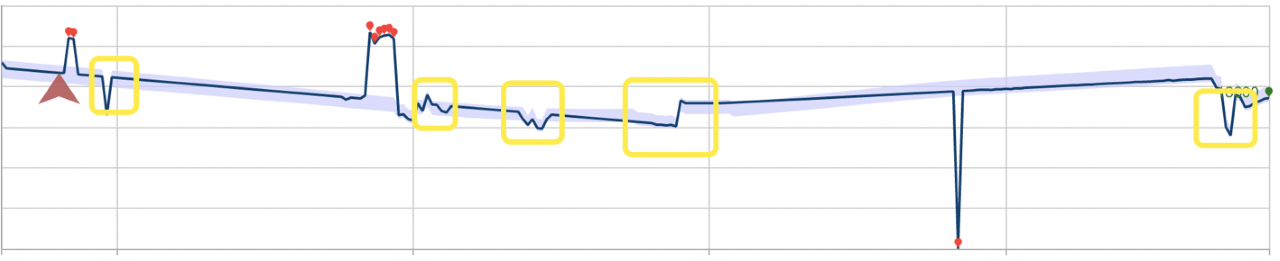
次の例では、これらの検出モードがパフォーマンスに及ぼす影響について説明します。 最初の図は、以前に見られた 28 のデータ ポイントのほか、異常状態の最新のポイントを継続して検出した結果を示します。 赤い点は、異常です。

バッチの異常検出を使用した同じデータ セットを次に示します。 操作用に構築されたモデルには、四角形でマークされているいくつかの異常が無視されます。
データの準備
Anomaly Detector API では、JSON 要求オブジェクトへフォーマットされた時系列データを受け入れます。 時系列データは、一定期間にわたって順番に記録された数値データです。 API のパフォーマンスを改善するために、複数の時間枠の時系列データを Anomaly Detector API エンドポイントに送信できます。 送信できるデータ ポイントの最小数は 12 ポイントで、最大数は 8640 ポイントです。 粒度は、データがサンプリングされる速度と定義されています。
Anomaly Detector API に送信されるデータ ポイントには、有効な協定世界時 (UTC) のタイムスタンプと、数値が含まれている必要があります。
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
データが非標準の時間間隔でサンプリングされている場合は、要求に customInterval 属性を追加することでこれを指定できます。 たとえば、系列が 5 分ごとにサンプリングされている場合は、JSON 要求に次のコードを追加できます。
{
"granularity" : "minutely",
"customInterval" : 5
}
欠落データ ポイント
均等に分散された時系列データ セットでは、データ ポイントの欠落はよくあることです。特に細分化されたデータ (たとえば、数分ごとなどの短いサンプリング期間にサンプリングされたデータ) でよく見られます。 データで予想されるデータ ポイント数の不足が 10% 以下の場合、検出結果に悪影響はありません。 前の期間のデータ ポイントとの置き換え、線状補間、または移動平均などにより、その特徴に基づいて、データの不足部分を埋めることを検討します。
分散データを集計する
Anomaly Detector API は均等に分散された時系列に最適です。 データがランダムに分散されている場合は、時間の単位 (分単位、時間単位、日単位など) 別に集計する必要があります。
季節性パターンを使用したデータの異常検出
時系列データに季節性パターン (定期的に発生するパターン) があることが分かっている場合は、精度と API の応答時間を改善できます。
JSON 要求を作成するときに period を指定すると、異常検出の待機時間を最大で 50% 短縮できます。 period は、時系列でパターンが繰り返されるまでのデータ ポイント数を大まかに指定する整数です。 たとえば、1 日あたり 1 つのデータ ポイントを持つ時系列の period は 7 となり、1 時間あたり 1 つのポイントを (毎週同じパターンで) 持つ時系列の period は 7*24 となります。 データのパターンが不明な場合は、このパラメーターを指定する必要はありません。
最良の結果を得るには、4 つの period に相当するデータ ポイントと、追加で 1 つのデータ ポイントを指定します。 たとえば、上記で説明した毎週のパターンを持つ時間単位のデータでは、要求本文で 673 個のデータ ポイント (7 * 24 * 4 + 1) を指定する必要があります。
リアルタイム監視用のデータのサンプリング
ストリーミング データを短期間 (秒単位や分単位など) でサンプリングした場合、推奨される数のデータ ポイントを送信すると、Anomaly Detector API で許容される最大数 (8640 データ ポイント) を超える可能性があります。 データの季節性パターンが安定している場合、より長期間 (時間単位など) で時系列データのサンプルを送信することを検討してください。 このようにデータをサンプリングすると、API の応答時間も大幅に短縮できます。