クイックスタート: カスタム要約 (プレビュー)
この記事を使って、要約の上でカスタム モデルをトレーニングできるカスタム要約プロジェクトの作成を開始します。 モデルとは、特定のタスクを実行するためにトレーニングされる人工知能ソフトウェアです。 このシステムでは、モデルはテキスト要約を行い、インポートされたデータから学習することでトレーニングされます。
この記事では、Language Studio を使って、カスタム要約の主要な概念を示します。 例として、短い退院記録から施設または治療場所を抽出するカスタム要約モデルを構築します。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します
新しい Azure AI Language リソースと Azure ストレージ アカウントを作成する
カスタム要約を使えるようになるためには、Azure AI Language リソースを作成する必要があります。これにより、プロジェクトを作成してモデルのトレーニングを始めるために必要な資格情報が提供されます。 また、モデルの構築に使用するデータセットをアップロードできる Azure ストレージ アカウントも必要です。
重要
すぐに始めるには、この記事で示す手順を使用して新しい Azure AI Language リソースを作成することをお勧めします。 この記事の手順を使用すると、言語リソースとストレージ アカウントを同時に作成することができ、後で行うより簡単です。
Azure portal から新しいリソースを作成します
Azure portal に移動し、新しい Azure AI Language リソースを作成します。
表示されるウィンドウで、カスタム機能からこのサービスを選択します。 画面の下部にある [続けてリソースの作成を行う] を選択します。
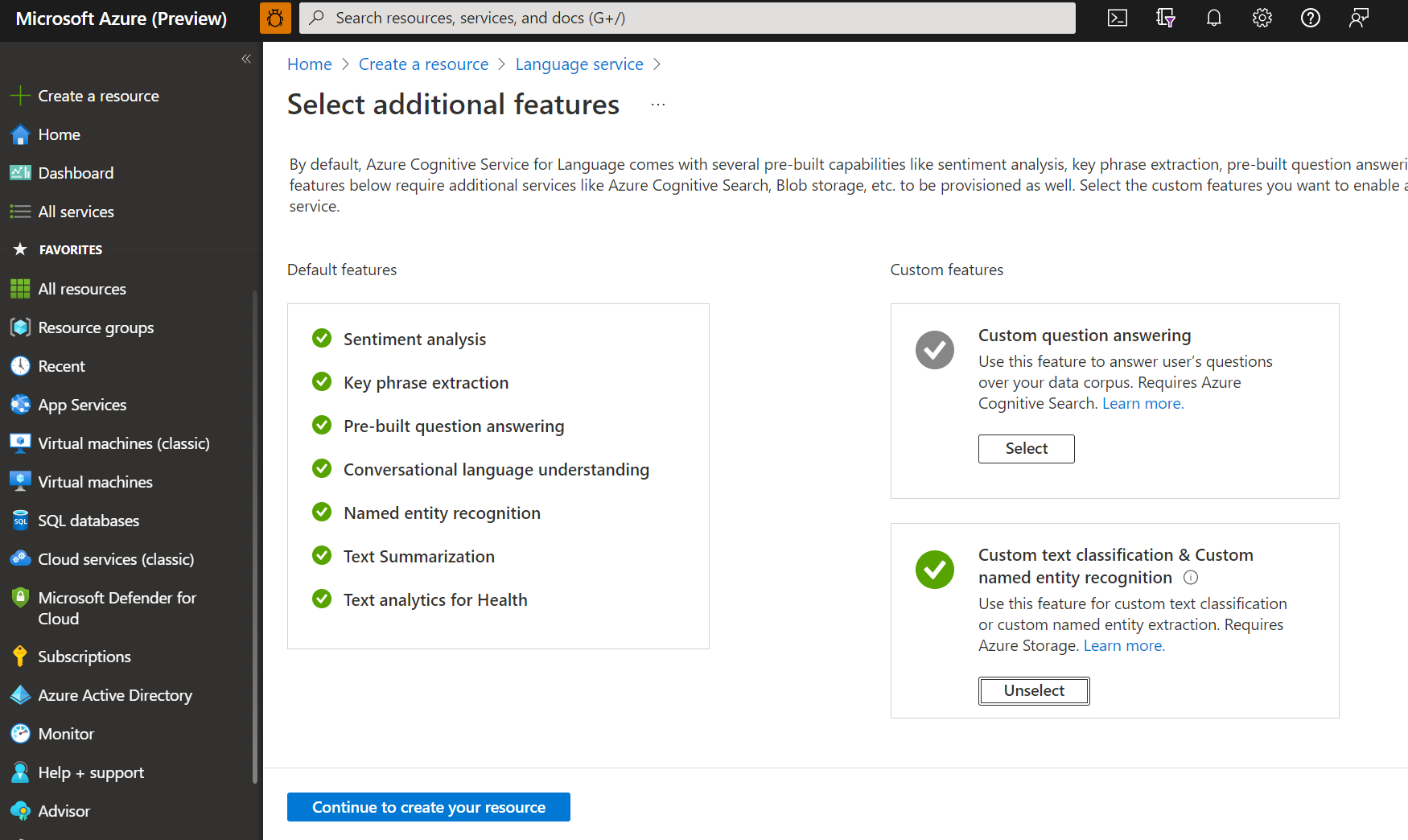
次の詳細を使用して言語リソースを作成します。
名前 説明 サブスクリプション Azure サブスクリプション。 リソース グループ リソースが格納されるリソース グループ。 既存のものを使用するか、新しく作成することができます。 リージョン 言語リソースのリージョン。 たとえば "米国西部 2" にします。 名前 リソースの名前。 Pricing tier 言語リソースの価格レベル。 Free (F0) レベルを利用してサービスを試用できます。 注意
"ログイン アカウントが選択したストレージ アカウントのリソース グループの所有者ではない" ことを通知するメッセージが表示された場合は、言語リソースを作成する前に、アカウントでそのリソース グループに所有者ロールを割り当てる必要があります。 Azure サブスクリプションの所有者に問い合わせてください。
このサービスのセクションで、既存のストレージ アカウントを選択するか、新しいストレージ アカウントを選択します。 これらの値は使用を開始するためのものであり、必ずしもご自分の運用環境で使用するストレージ アカウントの値でありません。 プロジェクトのビルド中の待機時間を回避するには、言語リソースと同じリージョンのストレージ アカウントに接続します。
ストレージ アカウントの値 推奨値 ストレージ アカウント名 任意の名前 ストレージ アカウントの種類 標準 LRS [責任ある AI の通知] がオンになっていることを確認します。 ページの下部にある [確認と作成] を選択して、[作成] を選択します。

サンプル データをダウンロードする
サンプル データが必要な場合は、このクイックスタートの目的で ドキュメントの概要作成 と 会話の概要作成 シナリオのためにいくつかを提供しました。
サンプル データを BLOB コンテナーにアップロードする
ストレージ アカウントにアップロードするファイルを見つける
Azure portal で、作成したストレージ アカウントに移動して選択します。
ストレージ アカウントで、左側のメニューの [データ ストレージ] の下にある [コンテナー] を選択します。 表示された画面で、[+ コンテナー] を選択します。 コンテナーに example-data という名前を付け、既定のパブリック アクセス レベルをそのまま使用します。
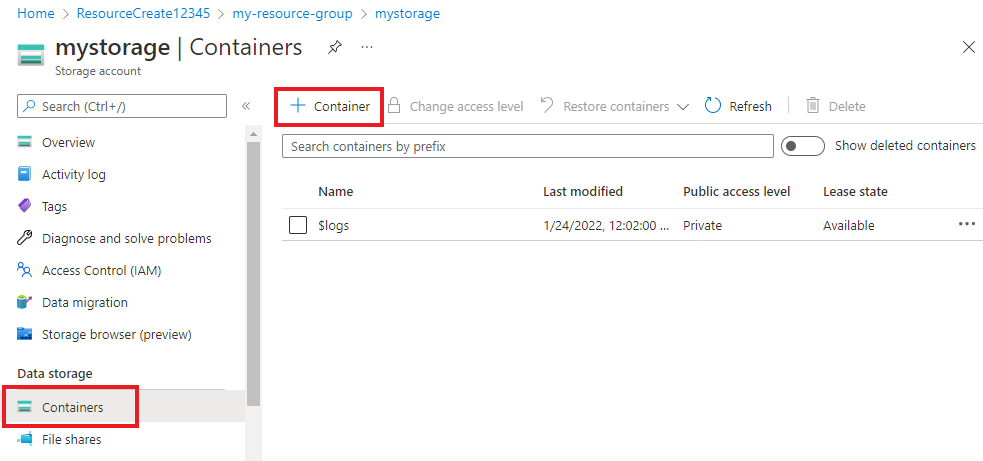
コンテナーが作成されたら、それを選択します。 次に、[アップロード] ボタンを選択して、先ほどダウンロードした
.txtおよび.jsonファイルを選択します。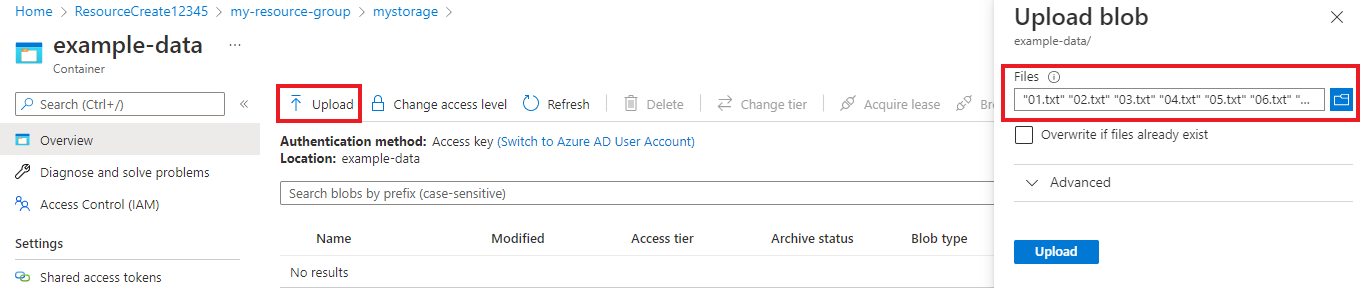


カスタム要約プロジェクトを作成する
リソースとストレージ アカウントが構成されたら、新しいカスタム要約プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
Language Studio にサインインします。 サブスクリプションと言語リソースを選ぶためのウィンドウが表示されます。 上の手順で作成した言語リソースを選択します。
Language Studio で使用したい機能を選択します。
プロジェクト ページの上部メニューから、 [Create new project](新しいプロジェクトの作成) を選択します。 プロジェクトを作成すると、データのラベル付け、モデルのトレーニング、評価、改善、デプロイを実行できます。

名前、説明、プロジェクト内のファイルの言語など、プロジェクト情報を入力します。 サンプル データセットを使用する場合は、[英語] を選択します。 プロジェクトの名前は後で変更できません。 [次へ] を選択します
ヒント
データセットは、すべて同じ言語である必要はありません。 サポートされる言語がそれぞれ異なる複数のドキュメントを得ることができます。 データセットに異なる言語のドキュメントが含まれる場合や、実行時に異なる言語のテキストが必要になると考えられる場合は、プロジェクトの基本情報を入力するときに、[多言語データセットを有効にする] オプションを選択します。 このオプションは、後で [プロジェクトの設定] ページから有効にすることができます。
[新しいプロジェクトの作成] を選択すると、ストレージ アカウントを接続するためのウィンドウが表示されます。 既にストレージ アカウントを接続している場合は、そのストレージ アカウントが表示されます。 まだ接続していない場合は、表示されるドロップダウンからストレージ アカウントを選択し、[ストレージ アカウントの接続] を選択します。これにより、ストレージ アカウントに必要なロールが設定されます。 ストレージ アカウントの所有者として割り当てられていない場合、この手順でエラーが返される可能性があります。
Note
- この手順は、使用する新しいリソースごとに 1 回だけ行う必要があります。
- この処理は元に戻すことができません。ストレージ アカウントを言語リソースに接続すると、後で切断することはできません。
- 言語リソースは 1 つのストレージ アカウントにのみ接続できます。
データセットをアップロードしたコンテナーを選択します。
既にデータのラベル付けを完了している場合は、それがサポートされている形式に従っていることを確認し、[はい、ファイルは既にラベル付けされており、JSON ラベル ファイルを書式設定しています] を選択し、ドロップダウン メニューからラベル ファイルを選択します。 [次へ] を選択します。 クイックスタートのデータセットを使用している場合、JSON ラベル ファイルの書式設定を確認する必要はありません。
入力したデータを確認し、 [Create Project](プロジェクトの作成) を選びます。

モデルをトレーニングする
プロジェクトを作成したら、続けてモデルのトレーニングを開始します。
Language Studio 内からモデルのトレーニングを開始するには:
左側のメニューから [トレーニング ジョブ] を選択します。
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスにモデル名を入力します。 また、[既存のモデルを上書きする] オプションを選択し、ドロップダウン メニューから上書きするモデルを選択することにより、既存のモデルを上書きすることもできます。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
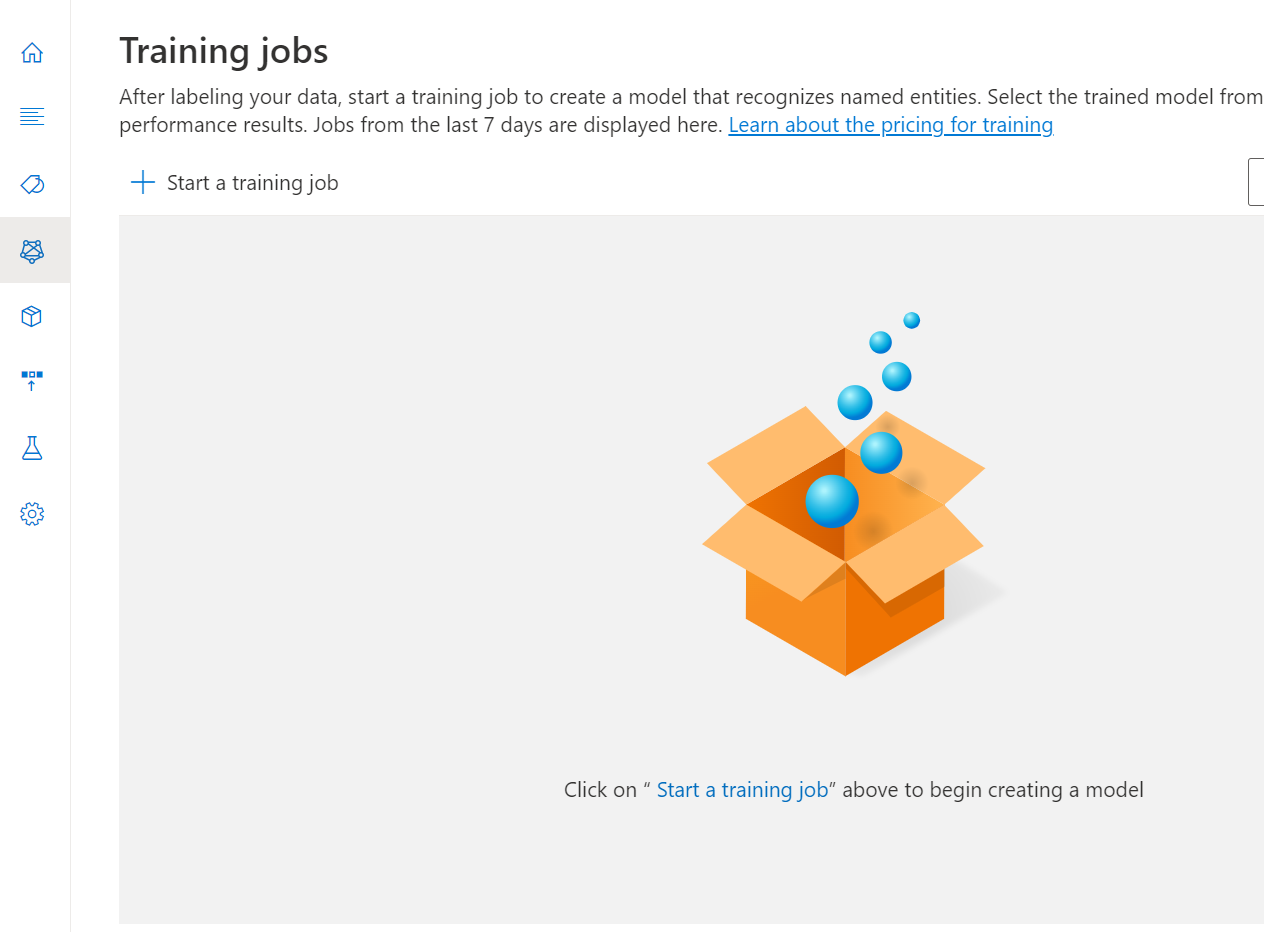
既定では、システムは指定された割合で、ラベル付きデータをトレーニング セットとテスト セットに分割します。 テスト セットにドキュメントがある場合は、トレーニング データとテスト データを手動で分割できます。
[トレーニング] ボタンを選択します。
一覧からトレーニング ジョブ ID を選択すると、サイド ペインが表示され、そのジョブの [トレーニングの進行状況]、[ジョブの状態]、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、ラベル付けされたデータのサイズに応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了するまで、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。

モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認し、必要に応じて改善を行います。 このクイックスタートでは、モデルを単にデプロイして、Language Studio で試せるように利用可能にします。
Language Studio 内からモデルのデプロイを開始するには、次の手順を行います。
左側のメニューから [Deploying a model](モデルのデプロイ) を選びます。
[デプロイの追加] を選択して、新しいデプロイ ジョブを開始します。
[デプロイの新規作成] を選択して新しいデプロイを作成し、下のドロップダウンからトレーニング済みのモデルを割り当てます。 既存のデプロイを上書きすることもできます。そのためにはこのオプションを選択して、下のドロップダウンから割り当てるトレーニング済みモデルを選択します。
注意
既存のデプロイを上書きしても、予測 API の呼び出しを変更する必要はありませんが、その結果は、新しく割り当てたモデルに基づくものになります。
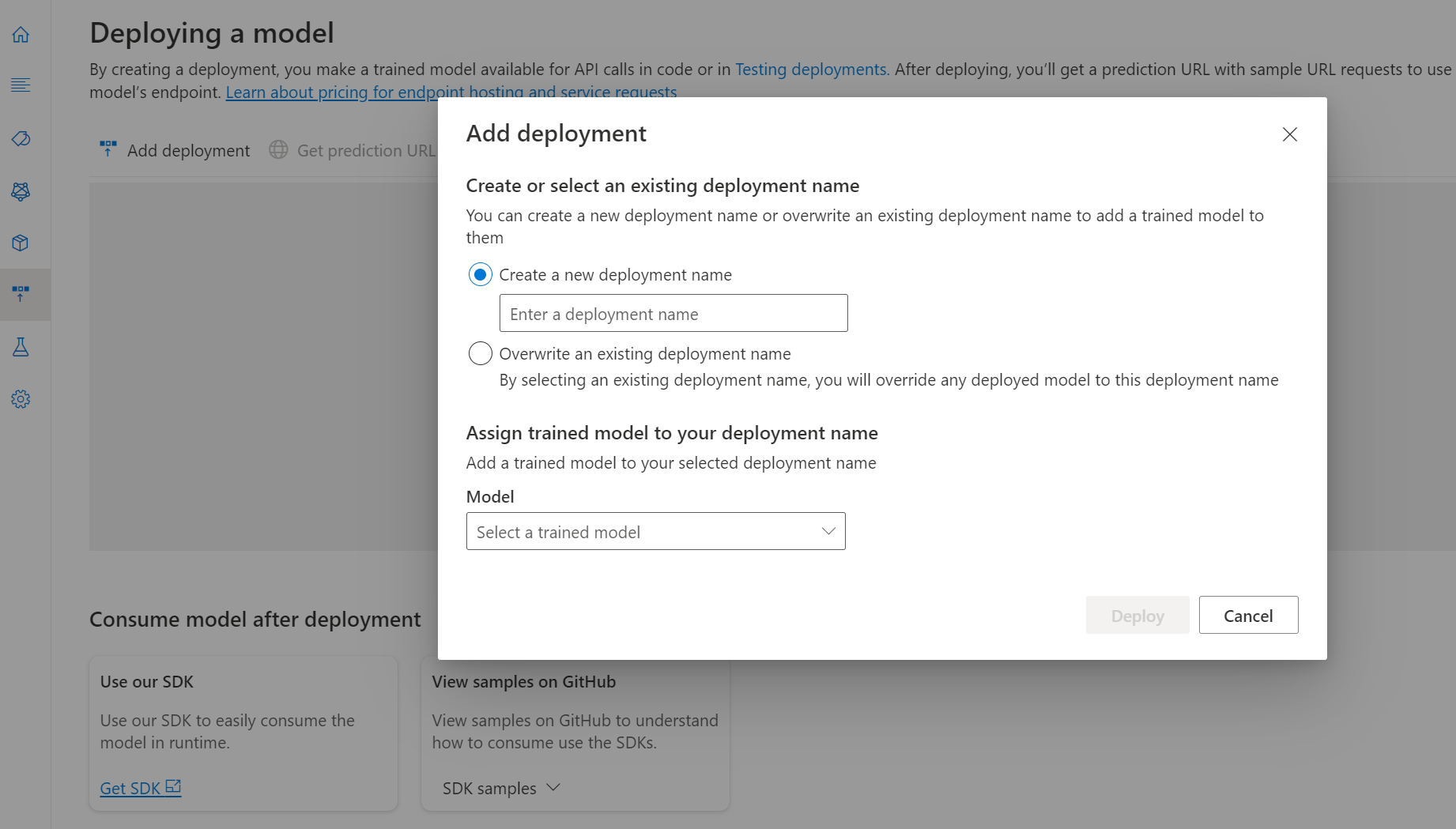
[デプロイ] を選択して、デプロイ ジョブを開始します。
デプロイが成功すると、その横に有効期限が表示されます。 デプロイの有効期限とは、デプロイされたモデルを予測に使用できなくなるときであり、通常は、トレーニング構成の有効期限が切れる 12 か月後に発生します。


モデルのテスト
このクイックスタートでは、Language Studio を使用して、カスタム要約タスクを送信し、結果を視覚化します。 先ほどダウンロードしたサンプル データセットには、この手順で使用できるテスト ドキュメントがいくつかあります。
Language Studio 内からデプロイされたモデルをテストするには、次の手順を行います。
左側のメニューから [デプロイのテスト] を選びます。
テストするデプロイを選択します。 テストできるのは、デプロイに割り当てられているモデルのみです。
多言語プロジェクトの場合は、[言語] ドロップダウンから、テストするテキストの言語を選択します。
ドロップダウンからクエリ/テストするデプロイを選択します。
要求に送信するテキストを入力するか、使用する
.txtファイルをアップロードできます。上部のメニューから [テストの実行] を選択します。
[Result](結果) タブでは、テキストから抽出されたエンティティとその型を確認できます。 [JSON] タブで JSON 応答を表示することもできます。

リソースをクリーンアップする
プロジェクトが不要な場合は、Language Studio を使ってプロジェクトを削除できます。 上部で使用している機能を選択し、削除したいプロジェクトを選択します。 上部のメニューから [削除] を選んで、プロジェクトを削除します。