回答の信頼度スコア
ユーザー クエリがナレッジ ベースに対して一致すると、QnA Maker は、信頼度スコアと共に該当する回答を返します。 このスコアは、回答が特定のユーザー クエリに最適である信頼度を示します。
信頼スコアは 0 から 100 の範囲の数値です。 100 点は完全一致であるの可能性が高いのに対して、0 点は一致する回答が見つからなかったことを意味します。 スコアが高得点であるほど、回答の信頼度は高くなります。 与えられた 1 つのクエリに対して、複数の回答が返されることがあります。 その場合、回答は信頼度スコアが高い順に返されます。
次の例では、1 つの QnA エンティティと 2 つの質問があります。

上記の例では、ユーザー クエリのさまざまな種類に応じて以下のスコア範囲サンプルのようなスコアを予想できます。
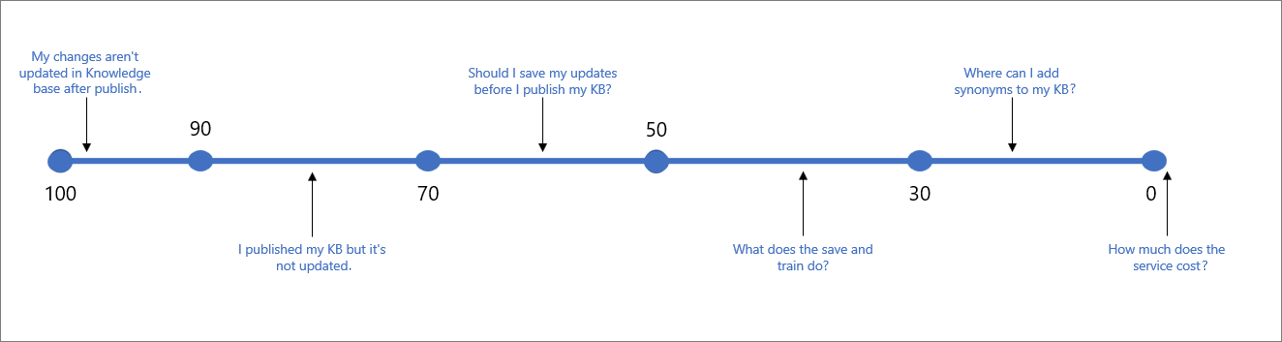
次の表は、特定のスコアに関連付けられる標準的な信頼度を示します。
| スコアの値 | スコアの意味 | サンプル クエリ |
|---|---|---|
| 90 - 100 | ユーザー クエリと KB の質問がほぼ完全に一致 | "My changes aren't updated in KB after publish" |
| > 70 | 高信頼度 - 通常、ユーザーのクエリに対する完全な答えとなる良い回答 | "I published my KB but it's not updated" |
| 50 - 70 | 中程度の信頼度 - 通常、ユーザー クエリの主な意図に答えるかなり良い回答 | "Should I save my updates before I publish my KB?" |
| 30 - 50 | 低信頼度 - 通常、ユーザーの意図の一部に答える回答。 | " What does the save and train do?" |
| < 30 | 非常に低い信頼度 - 通常ユーザーのクエリに答えていないが、一部、一致する単語や語句がある回答 | " Where can I add synonyms to my KB" |
| 0 | 一致なし。回答は返されません。 | "How much does the service cost" |
スコアのしきい値を選択します。
上記の表は、たいていの KB で予想されるスコアをしています。 ただし、各 KB はそれぞれに異なり、さまざまな種類の単語や意図、目的があるため、自分に最も合うしきい値をテストし、選ぶことをお勧めします。 既定では、しきい値は 0 に設定されているため、考えられるすべての回答が返されます。 たいていの KB に合う、推奨されるしきい値は 50 です。
しきい値を選択するさいは、Accuracy (精度) と Coverage (カバレッジ) のバランスを考慮し、自分の要件に基づいて、しきい値を調整してください。
Accuracy(精度または正確さ) が重要な場合は、しきい値を大きくします。 そうすることで、回答が返されるたびに、信頼度の高いケースがずっと多くなり、ユーザーが求めている回答になる可能性がずっと高くなります。探している可能性が高くなります。 このケースでは、最終的に回答を得られない質問が多くなる可能性があります。 例:しきい値を 70 にした場合、「what is save and train?」などの曖昧な例が見逃される可能性があります。
Coverage(カバレッジまたはリコール)が重要で、ユーザーの質問に対して部分的な関係しかなくても、できるだけ多くの質問に答えるようにしたい場合は、しきい値を小さくします。 このことは、ユーザーの実際のクエリに対する答えにはなっていないものの、他の多少関係のある回答が得られるケースが増える可能性があることを意味します。 例: しきい値を 30 にすると、"どこで KB を編集できますか?" などのクエリに回答する場合があります。
Note
QnA Maker の新しいバージョンにはスコアリング ロジックの機能強化が含まれ、しきい値に影響を与える可能性があります。 サービスを更新するときは常に、テストを行い、必要に応じてしきい値を調整してください。 お使いの QnA サービスのバージョンは、こちらで確認できます。最新の更新プログラムの入手方法については、こちらをご覧ください。
しきい値の設定
しきい値のスコアは、GenerateAnswer API JSON 本文のプロパティとして設定します。 つまり、GenerateAnswer を呼び出すたびに設定します。
ボット フレームワークからは、C# または Node.js で options オブジェクトの一部としてスコアを設定します。
信頼度スコアの向上
ユーザー クエリに対する特定の応答の信頼度スコアを上げるには、その応答に対する代替質問として、ユーザー クエリをナレッジ ベースに追加できます。 大文字と小文字が区別される単語変更を使用して、KB のキーワードにシノニムを追加することもできます。
類似する信頼度スコア
複数の応答の信頼度スコアが似ている場合は、クエリが一般的すぎるために、複数の回答で信頼度が等しくなっている可能性があります。 QnA の構造を改善して、すべての QnA エンティティが明確な意図を持つようにすることを試してください。
テストと実稼働の間の信頼度スコアの違い
コンテンツが同じ場合でも、ナレッジ ベースのテスト バージョンと公開バージョンの間で、回答の信頼度スコアが、無視できるほどですが、変化する場合があります。 これは、ナレッジ ベースのテスト バージョンと公開バージョンのコンテンツが、異なる Azure AI Search インデックスに配置されるためです。
テスト インデックスはナレッジ ベースのすべての QnA ペアを保持します。 テスト インデックスに対してクエリを実行すると、クエリはインデックス全体に適用され、結果はその特定のナレッジ ベースのパーティションに制限されます。 テスト クエリの結果がナレッジ ベースを検証する機能に悪影響を与える場合は、次のことができます。
- 次のいずれかを使用してナレッジ ベースを整理します。
- 1 つのリソースを 1 つの KB に制限する: 単一の QnA リソース (および結果の Azure AI Search テスト インデックス) を 1 つのナレッジ ベースに制限します。
- 2 つのリソース (テストに 1 つ、実稼働に 1 つ): 2 つの QnA Maker リソースを、1 つはテストに使用し (独自のテスト インデックスと実稼働インデックスを含みます)、もう 1 つは製品用に使用します (こちらも独自のテスト インデックスと実稼働インデックスを含みます)。
- また、テストと実稼働の両方のナレッジ ベースに対してクエリを実行する場合は、top などの同じパラメーターを常に使用します。
ナレッジ ベースを公開すると、ナレッジ ベースの質問と回答コンテンツが、Azure Search のテスト インデックスから実稼働インデックスへ移動されます。 公開のしくみを確認してください。
異なるリージョンにナレッジ ベースがある場合は、各リージョンが独自の Azure AI Search インデックスを使用しています。 異なるインデックスが使用されるため、スコアはまったく同じにはなりません。
一致が見つからない
ランク付けによって適切な一致が見つからない場合は、0.0 または "None" の信頼度スコアが返され、既定の応答は [No good match found in the KB]\(KB で適切な一致が見つかりませんでした\) になります。 エンドポイントを呼び出すボットまたはアプリケーションのコードで、この既定の応答を上書きできます。 別の方法として、Azure に上書き応答を設定することもできます。この場合は、特定の QnA Maker サービスにデプロイされたすべてのナレッジ ベースの既定値が変更されます。