Azure Cosmos DB for Apache Cassandra の一般的な問題をトラブルシューティングする
適用対象: ![]() Cassandra
Cassandra
Azure Cosmos DB の Cassandra 用 API は、オープンソースの Apache Cassandra データベースにワイヤ プロトコルのサポートを提供する互換性レイヤーです。
この記事では、Azure Cosmos DB for Apache Cassandra を使用するアプリケーションの一般的なエラーと解決策について説明します。 お客様のエラーが記載されておらず、Cassandra でサポートされる操作を実行するときにエラーが発生するが、ネイティブの Apache Cassandra の使用時にはエラーが存在しない場合は、Azureサポート リクエストを作成してください。
Note
フル マネージド クラウドネイティブ サービスとして、Azure Cosmos DB は、Cassandra 用 API に可用性、スループット、および整合性に対する保証を提供します。 また Cassandra 用 API は、メンテナンス不要のプラットフォーム操作とダウンタイム不要の修正プログラム適用を容易にします。
Apache Cassandra の以前の実装では、これらの保証はできないため、Cassandra 用 API バックエンド操作の多くは Apache Cassandra とは異なります。 一般的なエラーを回避するために、特定の設定とアプローチをお勧めします。
NoNodeAvailableException
このエラーは最上位レベルのラッパー例外であり、考えられる原因と内部例外が多数あり、その多くがクライアントに関連している可能性があります。
一般的な原因と解決策:
Azure LoadBalancers のアイドル タイムアウト: この問題は、
ClosedConnectionExceptionのように発生する場合もあります。 この問題を解決するには、ドライバーのキープアライブ設定を行い (「Java ドライバーのキープアライブを有効にする」を参照)、お使いのオペレーティング システムのキープアライブ設定値を引き上げるか、または Azure Load Balancer でアイドル タイムアウトを調整します。クライアント アプリケーション リソースの枯渇: クライアント マシンに要求を完了するための十分なリソースがあることを確認します。
ホストに接続できない
"Cannot connect to any host, scheduling retry in 600000 milliseconds." (どのホストにも接続できません。600000 ミリ秒で再試行をスケジュールします) というエラーが表示されることがあります。
このエラーは、クライアント側でのソース ネットワーク アドレス変換 (SNAT) の枯渇が原因である可能性があります。 この問題を解決するには、アウトバウンド接続での SNAT に関するページの手順に従ってください。
また、このエラーは、Azure ロード バランサーで既定で 4 分間のアイドル タイムアウトが発生する、アイドル タイムアウトの問題である場合もあります。 ロード バランサーのアイドル タイムアウトに関するページを参照してください。 Java ドライバーのキープアライブを有効にし、オペレーティング システムの keepAlive 間隔を 4 分未満に設定してください。
例外を処理するその他の方法については、NoHostAvailableException のトラブルシューティングに関する記事を参照してください。
OverloadedException (Java)
使用された要求ユニットの合計数が、キースペースまたはテーブルでプロビジョニングされた要求ユニットの数よりも多いため、要求が調整されています。
Azure portal からキースペースまたはテーブルに割り当てられたスループットのスケーリング (「Azure Cosmos DB for Apache Cassandra アカウントをエラスティックにスケーリングする」を参照) または再試行ポリシーの実装を検討してください。
Java の場合は、v3.x ドライバーと v4.x ドライバーの再試行サンプルをご覧ください。 「Java 用 Azure Cosmos DB Cassandra 拡張機能」も参照してください。
スループットが十分であるにもかかわらず発生する OverloadedException
要求の量または消費された要求ユニット コストに対して十分なスループットがプロビジョニングされているにもかかわらず、システムは要求を調整しているように見えます。 原因として、次の 2 つが考えられます。
スキーマ レベルの操作: Cassandra 用 API は、スキーマレベルの操作 (CREATE TABLE、ALTER TABLE、DROP TABLE) に対してシステム スループット予算を実装します。 実稼働システムでのスキーマ操作には、この予算で十分です。 ただし、スキーマ レベルの操作の数が多い場合は、この制限を超える可能性があります。
この予算はユーザーが制御できるものではないため、実行するスキーマ操作の数を減らすことを検討してください。 そのアクションで問題が解決されない場合、またはワークロードに対して実行可能ではない場合は、Azure サポート リクエストを作成してください。
データ スキュー: スループットが Cassandra 用 API でプロビジョニングされている場合は、物理パーティション間で均等に分割され、各物理パーティションに上限があります。 1 つの特定のパーティションから大量のデータを挿入または照会する場合、そのテーブルに大量の全体的なスループット (要求ユニット) をプロビジョニングしているにもかかわらず、レートが制限される可能性があります。
データ モデルを確認し、ホット パーティションを発生させる可能性のある過度なスキューがないことを確認してください。
断続的な接続エラー (Java)
接続が予想外に切断したりタイムアウトしたりします。
Java 用 Apache Cassandra ドライバーには、ExponentialReconnectionPolicy と ConstantReconnectionPolicy の 2 つのネイティブ再接続ポリシーが用意されています。 既定では、 ExponentialReconnectionPolicyです。 ただし、Azure Cosmos DB for Apache Cassandra の場合は、2 秒の遅延で ConstantReconnectionPolicy を実行することをお勧めします。
Java 4.x ドライバーのドキュメント、Java 3.x ドライバーのドキュメント、または「Java ドライバーの ReconnectionPolicy の構成」の例を参照してください。
負荷分散ポリシーのエラー
次のようなコードを使用して、Java Datastax ドライバーの v3.x に負荷分散ポリシーを実装している場合があります。
cluster = Cluster.builder()
.addContactPoint(cassandraHost)
.withPort(cassandraPort)
.withCredentials(cassandraUsername, cassandraPassword)
.withPoolingOptions(new PoolingOptions() .setConnectionsPerHost(HostDistance.LOCAL, 1, 2)
.setMaxRequestsPerConnection(HostDistance.LOCAL, 32000).setMaxQueueSize(Integer.MAX_VALUE))
.withSSL(sslOptions)
.withLoadBalancingPolicy(DCAwareRoundRobinPolicy.builder().withLocalDc("West US").build())
.withQueryOptions(new QueryOptions().setConsistencyLevel(ConsistencyLevel.LOCAL_QUORUM))
.withSocketOptions(getSocketOptions())
.build();
withLocalDc() の値がコンタクト ポイントのデータセンターと一致しない場合、断続的なエラーが発生することがあります: com.datastax.driver.core.exceptions.NoHostAvailableException: All host(s) tried for query failed (no host was tried)。
CosmosLoadBalancingPolicy を実装してください。 これを機能させるには、次のコードを使用して DataStax をアップグレードする必要が生じる可能性があります。
LoadBalancingPolicy loadBalancingPolicy = new CosmosLoadBalancingPolicy.Builder().withWriteDC("West US").withReadDC("West US").build();
大きなテーブルでカウントが失敗する
多数の行で select count(*) from table または同様のものを実行すると、サーバーがタイムアウトになります。
ローカルの CQLSH クライアントを使用している場合は、--connect-timeout または --request-timeout の設定を変更してください。 「cqlsh: the CQL shell」を参照してください。
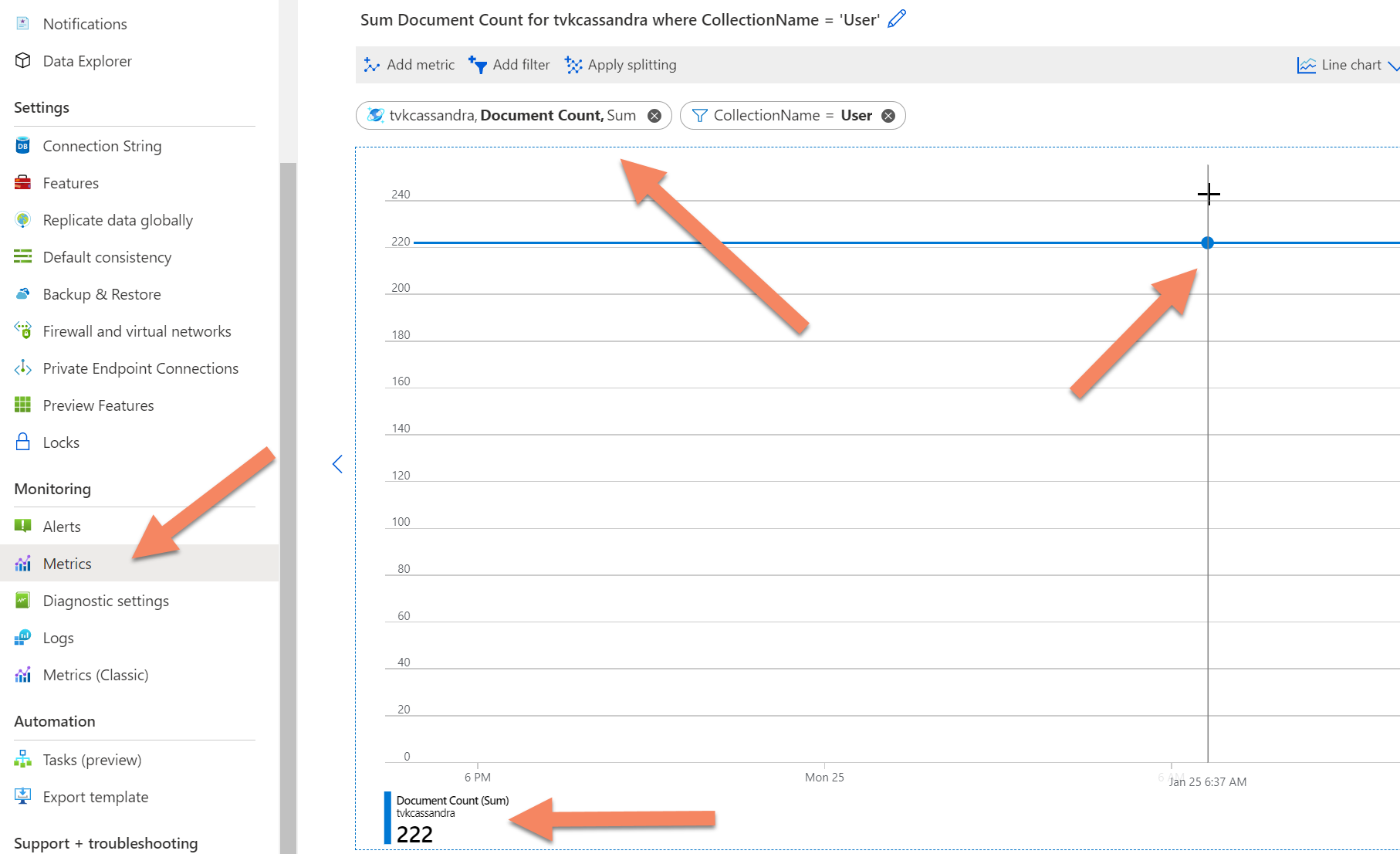
カウントがまだタイムアウトになる場合は、Azure portal の [メトリック] タブに移動し、メトリック document count を選択して、データベースまたはコレクションのフィルターを追加することによって、Azure Cosmos DB バックエンド テレメトリからレコードのカウントを取得できます (Azure Cosmos DB のテーブルのアナログ)。 その後、レコード数をカウントする特定の時点のグラフにマウス ポインターを合わせることができます。
Java ドライバーの ReconnectionPolicy を構成する
バージョン 3.x
Java ドライバーのバージョン 3.x では、クラスター オブジェクトの作成時に再接続ポリシーを構成します。
import com.datastax.driver.core.policies.ConstantReconnectionPolicy;
Cluster.builder()
.withReconnectionPolicy(new ConstantReconnectionPolicy(2000))
.build();
バージョン 4.x
Java ドライバーのバージョン 4.x では、reference.conf ファイルの設定をオーバーライドして再接続ポリシーを構成します。
datastax-java-driver {
advanced {
reconnection-policy{
# The driver provides two implementations out of the box: ExponentialReconnectionPolicy and
# ConstantReconnectionPolicy. We recommend ConstantReconnectionPolicy for API for Cassandra, with
# base-delay of 2 seconds.
class = ConstantReconnectionPolicy
base-delay = 2 second
}
}
Java ドライバーのキープアライブを有効にする
バージョン 3.x
Java ドライバーのバージョン 3.x では、クラスター オブジェクトの作成時にキープアライブを設定し、キープアライブがオペレーティング システムで有効になっていることを確認します。
import java.net.SocketOptions;
SocketOptions options = new SocketOptions();
options.setKeepAlive(true);
cluster = Cluster.builder().addContactPoints(contactPoints).withPort(port)
.withCredentials(cassandraUsername, cassandraPassword)
.withSocketOptions(options)
.build();
バージョン 4.x
Java ドライバーのバージョン 4.x では、reference.conf の設定をオーバーライドしてキープアライブを設定し、キープアライブがオペレーティング システムで有効になっていることを確認します。
datastax-java-driver {
advanced {
socket{
keep-alive = true
}
}
次のステップ
- Azure Cosmos DB for Apache Cassandra でサポートされている機能について確認します。
- ネイティブの Apache Cassandra から Azure Cosmos DB for Apache Cassandra に移行する方法について確認します。