数百テラバイトのデータを Azure Cosmos DB に移行する
適用対象: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() Table
Table
Azure Cosmos DB には、テラバイト単位のデータを格納できます。 大規模なデータ移行を実行して、運用ワークロードを Azure Cosmos DB に移動することができます。 この記事では、Azure Cosmos DB への大規模なデータの移行に伴う課題について説明し、それらの課題に対応して Azure Cosmos DB にデータを移行するツールについて説明します。 このケース スタディでは、顧客は Azure Cosmos DB の NoSQL 用 API を使用しています。
ワークロード全体を Azure Cosmos DB に移行する前に、データのサブセットを移行して、パーティション キーの選択、クエリのパフォーマンス、データ モデリングなどのいくつかの側面を検証することができます。 概念実証を検証した後、ワークロード全体を Azure Cosmos DB に移動できます。
データ移行のためのツール
現在、Azure Cosmos DB の移行方法は、API の選択とデータのサイズによって異なります。 データ モデリング、クエリ パフォーマンス、パーティションキーの選択などの検証のために小規模なデータセットを移行するには、Azure Data Factory の Azure Cosmos DB コネクタを選択できます。 Spark を使い慣れている場合は、Azure Cosmos DB Spark コネクタを使用してデータを移行することもできます。
大規模な移行での課題
Azure Cosmos DB にデータを移行するための既存のツールには、大規模な移行で特に明らかになる制限事項がいくつかあります。
スケールアウト機能に制限がある:数テラバイトのデータをできるだけ迅速に Azure Cosmos DB に移行し、プロビジョニング済みのスループット全体を効率的に使用するために、移行クライアントには無制限にスケールアウトできる機能が必要です。
進行状況の追跡とチェックポイント設定の機能がない:大規模なデータセットの移行中は、移行の進行状況を追跡し、チェックポイント処理を行うことが重要です。 そうしないと、移行中に発生したエラーによって移行が停止し、最初からプロセスを開始しなければなりません。 全移行プロセスの 99% が既に完了しているときに、それを再び開始するのは生産的ではありません。
配信不能キューがない:大規模なデータ セット内では、ソース データの一部に問題がある場合があります。 また、クライアントまたはネットワークに一時的な問題がある可能性もあります。 どちらの場合も、移行全体が失敗することはありません。 ほとんどの移行ツールには、断続的な問題から保護する堅牢な再試行機能がありますが、必ずしも十分であるとは限りません。 たとえば、ソース データ ドキュメントの 0.01% 未満でサイズが 2 MB を超えていると、Azure Cosmos DB でドキュメントの書き込みが失敗します。 理想的には、これらの "失敗した" ドキュメントを、移行後に処理できる別の配信不能キューに保持すると移行ツールにとって役立ちます。
これらの制限の多くは、Azure Data Factory、Azure データ移行サービスなどのツールでは修正されています。
Bulk Executor ライブラリを使用するカスタム ツール
上記のセクションで説明した課題は、複数のインスタンス間で簡単にスケールアウトできるカスタム ツールを使用することによって解決できます。また、このツールには、一時的な障害に対する回復力があります。 さらに、このカスタム ツールでは、さまざまなチェックポイントで移行を一時停止したり再開したりできます。 Azure Cosmos DB には、これらの機能の一部が組み込まれた Bulk Executor ライブラリが既に用意されています。 たとえば、Bulk Executor ライブラリには、一時的なエラーを処理する機能が既にあり、単一ノード内でスレッドをスケールアウトして、ノードあたり約 500 K の RU を使用することができます。 また、Bulk Executor ライブラリは、ソース データセットを、チェックポイント処理として独立して操作されるマイクロバッチにパーティション分割します。
このカスタム ツールでは、Bulk Executor ライブラリを使用して複数のクライアント間でのスケールアウトをサポートし、取り込みプロセス中のエラーを追跡します。 このツールを使用するには、Azure Data Lake Storage (ADLS) でソース データを個別のファイルにパーティション分割して、異なる移行ワーカーが各ファイルを取得して Azure Cosmos DB に取り込めるようにする必要があります。 カスタム ツールでは、個別のコレクションが使用されます。それには ADLS 内の個々のソース ファイルの移行の進行状況に関するメタデータが格納されており、それらに関連したエラーが追跡されています。
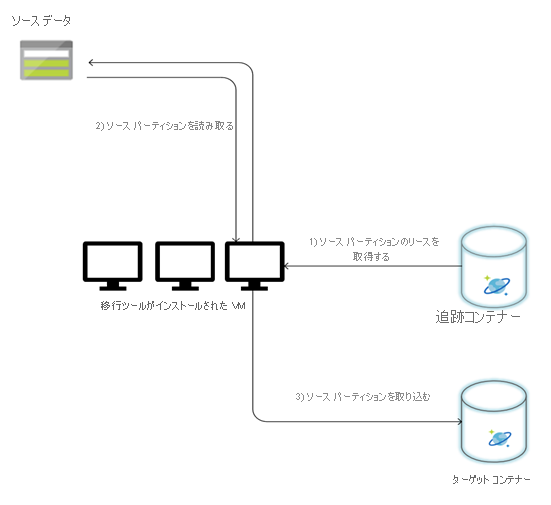
次の図は、このカスタム ツールを使用した移行プロセスについて説明しています。 このツールは一連の仮想マシンで実行されており、各仮想マシンは Azure Cosmos DB の追跡コレクションに対してクエリを実行し、いずれかのソース データ パーティションでリースを取得します。 この処理が完了すると、ソース データ パーティションはツールによって読み取られ、Bulk Executor ライブラリを使用して Azure Cosmos DB に取り込まれます。 次に、追跡コレクションが更新されて、データ インジェストの進行状況と発生したエラーが記録されます。 データ パーティションが処理された後、ツールは次に使用可能なソース パーティションを照会しようとします。 すべてのデータが移行されるまで、次のソース パーティションの処理が続行されます。 このツールのソース コードは、Azure Cosmos DB 一括インジェスト リポジトリで入手できます。
追跡コレクションには、次の例に示すようなドキュメントが含まれています。 ソース データ内のパーティションごとに、このようなドキュメントが 1 つあります。 各ドキュメントには、ソース データ パーティションのメタデータ (その場所、移行の状態、エラー (ある場合) など) が含まれています。
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
データ移行の前提条件
データ移行を開始する前に、考慮すべきいくつかの前提条件があります。
データ サイズを推定する:
ソース データのサイズは Azure Cosmos DB のデータ サイズに正確にマップされていない可能性があります。 Azure Cosmos DB でのデータのサイズを確認するために、ソースからいくつかのサンプル ドキュメントを挿入できます。 サンプル ドキュメントのサイズによって、Azure Cosmos DB 移行後の合計データ サイズを推定できます。
たとえば、Azure Cosmos DB での移行後の各ドキュメントが約 1 KB で、ソース データセットに約 600 億個のドキュメントがある場合は、Azure Cosmos DB の推定サイズが 60 TB に近くになることを意味します。
十分な RU を備えたコンテナーを事前に作成する:
Azure Cosmos DB ではストレージは自動的にスケールアウトされますが、最小のコンテナー サイズで開始することはお勧めできません。 コンテナーを小さくすると、スループットの可用性が低下します。これは、移行が完了するまでにかかる時間が長くなることを意味します。 代わりに、(前の手順で推定した) 最終的なデータ サイズでコンテナーを作成し、プロビジョニング済みスループットが移行ワークロードで完全に使用されるようにすると便利です。
前の手順で データ サイズは約 60 TB と推定されたので、データセット全体を格納するには、少なくとも 2.4 M の RU のコンテナーが必要になります。
移行速度を推定する:
移行ワークロードがプロビジョニング済みスループット全体を使用できると想定すると、プロビジョニング済みスループットで移行速度を推定できます。 先ほどの例の続きとして、1 KB のドキュメントを Azure Cosmos DB の NoSQL 用 API アカウントに書き込むには 5RU が必要です。 240 万 RU で、1 秒間に 48 万ドキュメントを転送できます (480 MB/秒)。 つまり、60 TB を完全に移行するには、125,000 秒 (約 34 時間) かかります。
1 日以内に移行を完了したい場合は、プロビジョニング済みスループットを 500 万 RU に増やす必要があります。
インデックス作成をオフにする:
移行はできるだけ早く完了する必要があるため、取り込まれた各ドキュメントのインデックス作成に費やされる時間と RU は最小限に抑えることをお勧めします。 Azure Cosmos DB ではすべてのプロパティのインデックスが自動的に作成されるため、インデックス作成を最小限に抑えて、いくつかの選択した用語に制限したり、移行中は完全にオフにすると効果的です。 次に示すように、indexingMode を none に変更することで、コンテナーのインデックス作成ポリシーを無効にすることができます。
{
"indexingMode": "none"
}
移行が完了したら、インデックス作成を更新できます。
移行プロセス
前提条件が完了したら、次の手順でデータを移行できます。
まず、ソースから Azure Blob Storage にデータをインポートします。 移行の速度を上げるには、個別のソース パーティション間で並列化すると役立ちます。 移行を開始する前に、ソース データセットを約 200 MB のサイズのファイルにパーティション分割する必要があります。
Bulk Executor ライブラリは、1 つのクライアント VM で 500,000 RU を使用するようにスケールアップできます。 使用可能なスループットは 500 万 RU なので、Azure Cosmos DB データベースがあるのと同じリージョンに、10 台の Ubuntu 16.04 VM (Standard_D32_v3) をプロビジョニングする必要があります。 移行ツールとその設定ファイルを使用してこれらの VM を準備する必要があります。
いずれかのクライアント仮想マシンでキュー手順を実行します。 この手順では、ADLS コンテナーをスキャンして、ソース データセットのパーティション ファイルごとに進行状況追跡ドキュメントを作成する追跡コレクションを作成します。
次に、すべてのクライアント VM でインポート手順を実行します。 各クライアントは、ソース パーティションの所有権を取得し、そのデータを Azure Cosmos DB に取り込むことができます。 それが完了して、追跡コレクションで状態が更新されると、クライアントは追跡コレクションで次に使用可能なソース パーティションを照会できます。
このプロセスは、ソース パーティションのセット全体が取り込まれるまで続行されます。 すべてのソース パーティションが処理されたら、同じ追跡コレクションに対してエラー修正モードでツールを再実行する必要があります。 この手順は、エラーのために再処理が必要なソース パーティションを特定するために必要です。
これらのエラーのいくつかは、ソース データのドキュメントが正しくないことが原因の可能性があります。 これらは、特定して修正する必要があります。 次に、失敗したパーティションに対してインポート手順を再実行して、それらを再度取り込む必要があります。
移行が完了したら、Azure Cosmos DB のドキュメント数がソース データベースのドキュメント数と同じであることを確認できます。 この例では Azure Cosmos DB の合計サイズは 65 テラバイトになりました。 移行後は、インデックス作成を選択的に有効にし、RU をワークロードの操作に必要なレベルまで下げることができます。
次のステップ
- .NET と Java で Bulk Executor ライブラリを使用するサンプル アプリケーションを試して、さらに詳しく学習します。
- バルク エグゼキューター ライブラリは Azure Cosmos DB Spark コネクタに統合されています。詳細については、Azure Cosmos DB Spark コネクタに関する記事を参照してください。
- 大規模な移行に関して別途支援が必要な場合は、問題のタイプに "General Advisory (一般的な勧告)" を、問題のサブタイプに "Large (TB+) migrations (大規模な (TB 以上の) 移行)" を選択してサポート チケットを開き、Azure Cosmos DB 製品チームに連絡します。
- Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コア数または仮想 CPU 数を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください