Azure Cosmos DB for MongoDB を使用すると、インデックス作成を使用してクエリのパフォーマンスを高速化できます。 この記事では、データの取得を高速化し、効率を向上させるためにインデックスを管理および最適化する方法について説明します。
MongoDB サーバー バージョン 3.6 以降のインデックス作成
Azure Cosmos DB for MongoDB サーバー バージョン 3.6 以降では、_id フィールドとシャード キー (シャード コレクションのみ) のインデックスが自動的に作成されます。 この API は、シャード キーごとに _id フィールドが一意になるようにします。
MongoDB 用 API は、既定ですべてのフィールドにインデックスを付ける Azure Cosmos DB for NoSQL とは動作が異なります。
インデックス作成ポリシーの編集
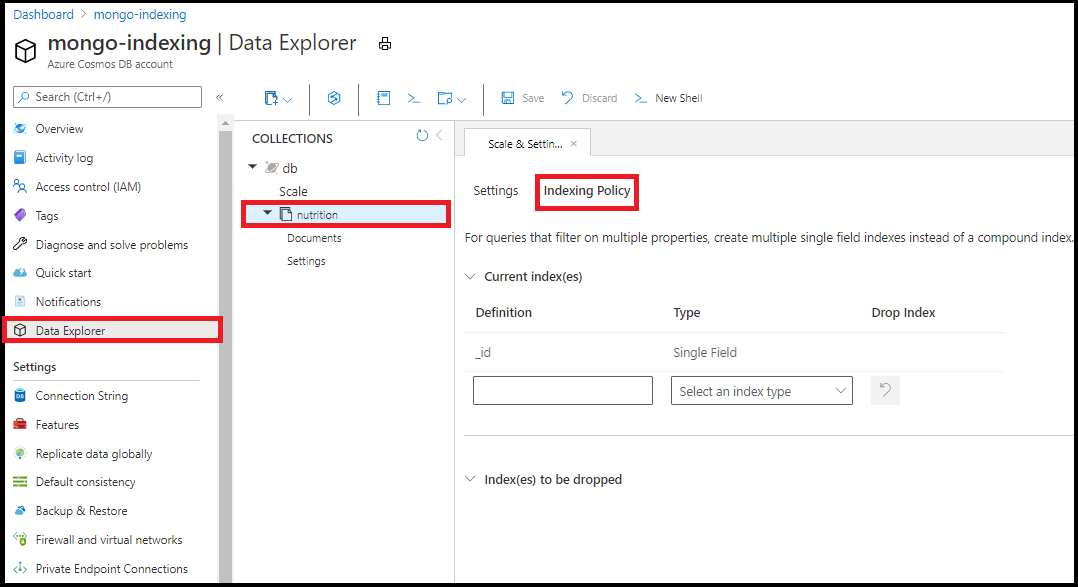
Azure portal のデータ エクスプローラーでインデックス作成ポリシーを編集します。 データ エクスプローラーのインデックス作成ポリシー エディターから単一フィールドとワイルドカード インデックスを追加します。
注
データ エクスプローラーのインデックス作成ポリシー エディターを使用して複合インデックスを作成することはできません。
インデックスの種類
単一フィールド
任意の 1 つのフィールドにインデックスを作成します。 単一フィールドのインデックスの並べ替え順序は重要ではありません。 フィールド name にインデックスを作成するには、次のコマンドを使用します。
db.coll.createIndex({name:1})
Azure portal で、name に同じ単一フィールド インデックスを作成するには次のようにします。
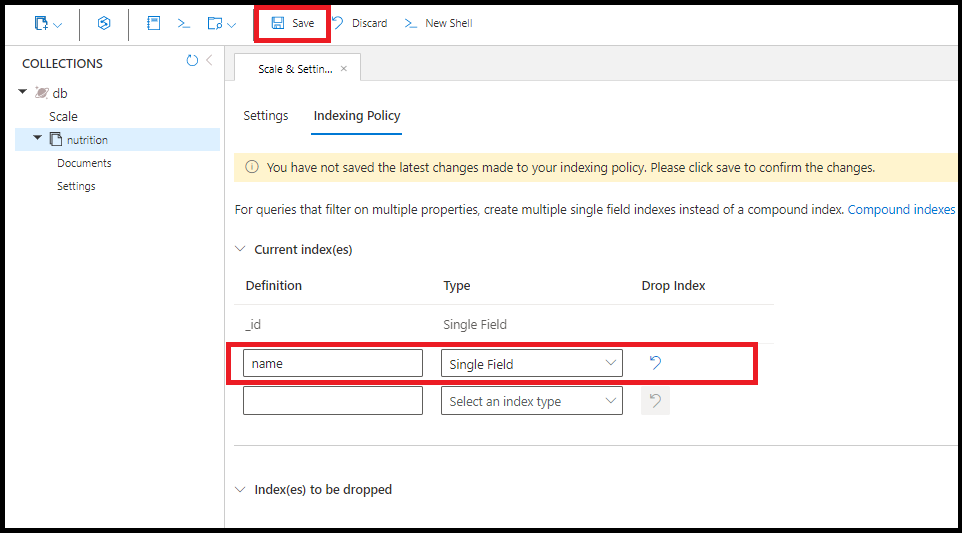
クエリは、使用可能な場合は複数の単一フィールド インデックスを使用します。 コレクションごとに最大 500 個の単一フィールド インデックスを作成します。
複合インデックス (MongoDB サーバー バージョン 3.6 以降)
MongoDB 用 API では、複数のフィールドを一度に並べ替えるクエリで複合インデックスを使用します。 並べ替える必要がない、複数のフィルターを使用するクエリの場合は、複合インデックスではなく、複数の単一フィールド インデックスを作成して、インデックス作成コストを節約します。
複合インデックス内の各フィールドの複合インデックスや単一フィールド インデックスは、クエリでのフィルター処理のパフォーマンスが同じになります。
配列に制限があるため、入れ子になったフィールドの複合インデックスは既定ではサポートされていません。 入れ子になったフィールドに配列がない場合、インデックスは意図したとおりに動作します。 入れ子になったフィールドのパス上の任意の場所に配列がある場合、その値はインデックスでは無視されます。
たとえば、people.dylan.age を含む複合インデックスは、この場合はパスに配列がないため、機能します。
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
この場合はパスに配列があるため、同じ複合インデックスが機能しません。
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
"EnableUniqueCompoundNestedDocs" 機能を有効化して、データベース アカウントに対してこの機能を有効にします。
注
配列に複合インデックスを作成することはできません。
次のコマンドでは、フィールド name と age に対して複合インデックスを作成します。
db.coll.createIndex({name:1,age:1})
複合インデックスを使用すると、次の例に示すように、一度に複数のフィールドで効率的に並べ替えることができます。
db.coll.find().sort({name:1,age:1})
上記の複合インデックスを使用して、すべてのフィールドに対して逆の並べ替え順序でクエリを効率的に並べ替えることもできます。 次に例を示します。
db.coll.find().sort({name:-1,age:-1})
ただし、複合インデックス内のパスの順序は、クエリと完全に一致している必要があります。 追加の複合インデックスを必要とするクエリの例を次に示します。
db.coll.find().sort({age:1,name:1})
複数キー インデックス
Azure Cosmos DB は、配列内のコンテンツにインデックスを付けるために複数キー インデックスを作成します。 配列値を持つフィールドのインデックスを作成すると、Azure Cosmos DB は配列内の各要素のインデックスを自動的に作成します。
地理空間のインデックス
多くの地理空間演算子は、地理空間インデックスを活用します。 Azure Cosmos DB for MongoDB は、2dsphere インデックスをサポートしています。 API は、2d インデックスをまだサポートしていません。
location フィールドに対して地理空間インデックスを作成する例を以下に示します。
db.coll.createIndex({ location : "2dsphere" })
テキスト インデックス
Azure Cosmos DB for MongoDB は、テキスト インデックスをまだサポートしていません。 文字列に対するテキスト検索クエリについては、Azure AI Search と Azure Cosmos DB の統合を使用してください。
ワイルドカード インデックス
ワイルドカード インデックスを使用して、不明なフィールドに対するクエリをサポートします。 家族に関するデータを含むコレクションを想像してみてください。
そのコレクション内のドキュメント例の一部を次に示します。
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
children に異なるプロパティのセットを持つ別の例を次に示します。
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
このコレクション内のドキュメントには、多くの異なるプロパティを含めることができます。
children 配列内のすべてのデータにインデックスを作成するには、プロパティごとに別個のインデックスを作成するか、children 配列全体に対して 1 つのワイルドカード インデックスを作成します。
ワイルドカード インデックスの作成
children 内のすべてのプロパティにワイルドカード インデックスを作成するには、次のコマンドを使用します。
db.coll.createIndex({"children.$**" : 1})
- MongoDB とは異なり、ワイルドカード インデックスはクエリ述語内の複数のフィールドをサポートできます。 プロパティごとに別個のインデックスを作成する代わりに、単一のワイルドカード インデックスを使用しても、クエリのパフォーマンスに違いはありません。
ワイルドカード構文を使用して、次のインデックスの種類を作成します。
- 単一フィールド
- GeoSpatial
すべてのプロパティのインデックス作成
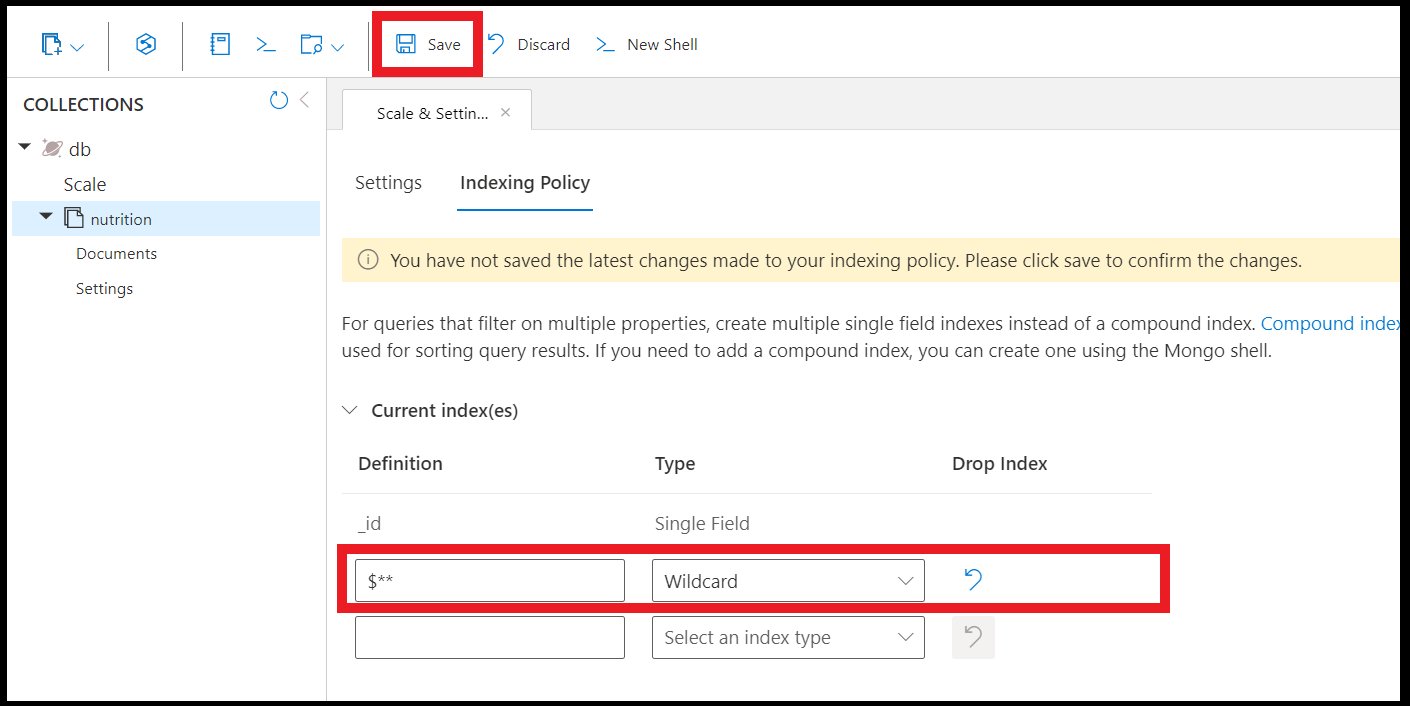
すべてのフィールドにワイルドカード インデックスを作成するには、次のコマンドを使用します。
db.coll.createIndex( { "$**" : 1 } )
Azure portal でデータ エクスプローラーを使用してワイルドカード インデックスを作成するには、次のようにします。
注
開発を開始したばかりの場合は、すべてのフィールドにワイルドカード インデックスを使用することから始めてください。 この方法により、開発が簡素化され、クエリの最適化が簡単になります。
多くのフィールドを持つドキュメントでは、書き込みと更新に対して高い要求ユニット (RU) 使用量が発生する可能性があります。 書き込み負荷の高いワークロードがある場合は、ワイルドカードではなく、個別にインデックス付けされたパスを使用してください。
制限事項
ワイルドカード インデックスでは、次のインデックスの種類やプロパティはいずれもサポートされません。
複合
TTL
一意
MongoDB とは異なり、Azure Cosmos DB for MongoDB では、次の場合にワイルドカード インデックスを使用できません。
複数の特定のフィールドを含むワイルドカード インデックスの作成
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )複数の特定のフィールドを除外するワイルドカード インデックスの作成
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
代替の方法として、複数のワイルドカード インデックスを作成してください。
インデックスのプロパティ
ワイヤ プロトコル バージョン 4.0 以前のバージョンを使用するアカウントでは、次の操作が一般的です。 サポートされているインデックスとインデックス付きプロパティの詳細をご確認ください。
一意なインデックス
一意なインデックスを使用すると、2 つ以上のドキュメントのインデックス付きフィールド値が同じでないことを確認できます。
student_id フィールドに一意のインデックスを作成するには、次のコマンドを実行します。
db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
シャード コレクションの場合は、シャード (パーティション) キーを指定して一意なインデックスを作成します。 シャード コレクションのすべての一意なインデックスは複合インデックスであり、フィールドの 1 つがシャード キーです。 シャード キーは、インデックス定義の最初のフィールドである必要があります。
coll という名前の (シャード キーとして university を持つ) シャード コレクションと、student_id フィールドと university フィールドに対する一意なインデックスを作成するには、次のコマンドを実行します。
db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
前の例の "university":1 句を省略すると、次のエラー メッセージが表示されます。
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
制限事項
一意なインデックスは、コレクションが空の間に作成します。
継続的バックアップを使用する Azure Cosmos DB for MongoDB アカウントでは、既存のコレクションの一意のインデックスの作成はサポートされていません。 このようなアカウントでは、コレクションの作成と共に一意のインデックスを作成する必要があります。このインデックスは、コレクション の作成拡張機能コマンドを使用してのみ行う必要があります。
db.runCommand({customAction:"CreateCollection", collection:"coll", shardKey:"student_id", indexes:[
{key: { "student_id" : 1}, name:"student_id_1", unique: true}
]});
配列に制限があるため、入れ子になったフィールドの一意なインデックスは既定ではサポートされていません。 入れ子になったフィールドに配列がない場合、インデックスは意図したとおりに動作します。 入れ子になったフィールドのパス上の任意の場所に配列がある場合、その値は一意なインデックスでは無視され、その値の一意性は維持されません。
たとえば、people.tom.age の一意なインデックスは、この場合はパスに配列がないため、機能します。
{
"people": {
"tom": {
"age": "25"
},
"mark": {
"age": "30"
}
}
}
しかしこの場合は、パスに配列があるため、機能しません。
{
"people": {
"tom": [
{
"age": "25"
}
],
"mark": [
{
"age": "30"
}
]
}
}
ご自分のデータベース アカウントに対してこの機能を有効にするには、"EnableUniqueCompoundNestedDocs" 機能を有効にします。
TTL インデックス
ドキュメントをコレクション内で期限切れにするには、Time to Live (TTL) インデックスを作成します。 TTL インデックスは、_ts 値を持つ expireAfterSeconds フィールドのインデックスです。
例:
db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
前のコマンドは、10 秒以上前に変更された db.coll コレクション内のすべてのドキュメントを削除します。
注
_ts フィールドは Azure Cosmos DB に固有であり、MongoDB クライアントからはアクセスできません。 これは、ドキュメントの最後の変更のタイム スタンプを含む予約済み (システム) プロパティです。
インデックスの進行状況を追跡する
バージョン 3.6 以上の Azure Cosmos DB for MongoDB は、データベース インスタンスのインデックス作成の進行状況を追跡する currentOp() コマンドをサポートしています。 このコマンドは、データベース インスタンスに対する進行中の操作に関する情報を含むドキュメントを返します。 ネイティブ MongoDB のすべての進行中の操作を追跡するには、currentOp コマンドを使用します。 Azure Cosmos DB for MongoDB では、このコマンドはインデックス操作のみを追跡します。
currentOp コマンドを使用してインデックス作成の進行状況を追跡する方法の例を次に示します。
コレクションのインデックスの進行状況を取得するには、次のようにします。
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})データベース内のすべてのコレクションのインデックスの進行状況を取得するには、次のようにします。
db.currentOp({"command.$db": <databaseName>})Azure Cosmos DB アカウント内のすべてのデータベースとコレクションのインデックスの進行状況を取得するには、次のようにします。
db.currentOp({"command.createIndexes": { $exists : true } })
インデックスの進行状況の出力例
インデックス作成の進行状況の詳細には、現在のインデックス操作の進捗率が表示されます。 インデックス作成の進行状況のさまざまな段階の出力ドキュメント形式の例を次に示します。
"foo" コレクションと "bar" データベースに対するインデックス操作が 60% 完了した出力ドキュメントは次のようになります。
Inprog[0].progress.totalフィールドには、ターゲットの完了パーセンテージとして 100 が示されています。{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 60 %", "progress": { "done": 60, "total": 100 }, ... } ], "ok": 1 }"foo" コレクションと "bar" データベースでインデックス操作が開始されたばかりの場合、測定可能なレベルに達するまで出力ドキュメントに 0% の進行状況が表示される可能性があります。
{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 0 %", "progress": { "done": 0, "total": 100 }, ... } ], "ok": 1 }インデックス操作が完了すると、出力ドキュメントに空の
inprog操作が表示されます。{ "inprog" : [], "ok" : 1 }
バックグラウンドでのインデックスの更新
インデックスの更新は、Background インデックス プロパティに設定した値に関係なく、常にバックグラウンドで実行されます。 インデックスの更新は、他のデータベース アクションよりも優先順位の低い要求ユニット (RU) が使用されるため、インデックスの変更によって書き込み、更新、または削除のダウンタイムが発生することはありません。
新しいインデックスを追加しても、読み取り可用性には影響しません。 クエリでは、インデックス変換が完了した後にのみ新しいインデックスが使用されます。 変換中、クエリ エンジンは既存のインデックスを使用し続けるため、インデックスの変更を開始する前と同様の読み取りパフォーマンスが維持されます。 新しいインデックスを追加しても、不完全なクエリ結果や一貫性のないクエリ結果のリスクはありません。
インデックスを削除し、それらの削除されたインデックスに対してフィルター処理するクエリをすぐに実行すると、インデックス変換が完了するまで結果に一貫性がなく、不完全になる可能性があります。 クエリ エンジンは、新しく削除されたインデックスをフィルター処理するクエリに対して、一貫性のある結果や完全な結果を提供しません。 ほとんどの開発者はインデックスを削除してからすぐにクエリを実行しないため、このような状況はあまりありません。
注
インデックスの進行状況を追跡することができます。
reIndex コマンド
reIndex コマンドは、コレクションのすべてのインデックスを再作成します。 まれに、reIndex コマンドを実行すると、クエリのパフォーマンスやその他のインデックスの問題がコレクション内で修正される可能性があります。 インデックスの問題が発生している場合は、reIndex コマンドを使用してインデックスを再作成してみてください。
reIndex コマンドを実行するには、次の構文を使用します。
db.runCommand({ reIndex: <collection> })
reIndex コマンドを実行するとコレクションのクエリ パフォーマンスが向上するかどうかを確認するには、次の構文を使用します。
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
サンプル出力:
{
"database": "myDB",
"collection": "myCollection",
"provisionedThroughput": 400,
"indexes": [
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "myDB.myCollection",
"requiresReIndex": true
},
{
"v": 1,
"key": {
"b.$**": 1
},
"name": "b.$**_1",
"ns": "myDB.myCollection",
"requiresReIndex": true
}
],
"ok": 1
}
reIndex によってクエリのパフォーマンスが向上する場合は、requiresReIndex が true になります。
reIndex によってクエリのパフォーマンスが向上しない場合は、このプロパティが省略されます。
インデックス付きのコレクションを移行する
一意なインデックスは、コレクションにドキュメントがない場合にのみ作成できます。 一般的な MongoDB 移行ツールは、データのインポート後に一意なインデックスを作成しようとします。 この問題を回避するには、移行ツールを試す代わりに、対応するコレクションと一意なインデックスを手動で作成します。
mongorestore に対してこの動作を実現するには、コマンド ラインで --noIndexRestore フラグを使用します。
MongoDB バージョン 3.2 のインデックス作成
MongoDB ワイヤ プロトコルのバージョン 3.2 を使用する Azure Cosmos DB アカウントでは、インデックスの機能と既定値が異なります。 feature-support-36.md#protocol-support でアカウントのバージョンを確認し、upgrade-version.md でバージョン 3.6 にアップグレードしてください。
バージョン 3.2 を使用する場合、次のセクションでバージョン 3.6 以降との主な違いについて説明します。
既定のインデックスの削除 (バージョン 3.2)
バージョン 3.6 以降とは異なり、Azure Cosmos DB for MongoDB バージョン 3.2 は、既定ですべてのプロパティのインデックスを作成します。 次のコマンドを使用して、コレクション (coll) に対するこれらの既定のインデックスをすべて削除してください。
db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
既定のインデックスを削除したら、バージョン 3.6 以降と同様にインデックスを追加します。
複合インデックス (バージョン 3.2)
複合インデックスは、ドキュメント内の複数のフィールドを参照します。 複合インデックスを作成するには、upgrade-version.md でバージョン 3.6 または 4.0 にアップグレードしてください。
ワイルドカード インデックス (バージョン 3.2)
ワイルドカード インデックスを作成するには、upgrade-version.md でバージョン 4.0 または 3.6 にアップグレードしてください。