現実の例を使用して Azure Cosmos DB のデータをモデル化およびパーティション分割する方法
適用対象: ![]() NoSQL
NoSQL
この記事では、データ モデリング、パーティション分割、プロビジョニング済みスループットなどの Azure Cosmos DB のいくつかの概念を基にして、現実世界のデータ設計に取り組む方法を示します。
通常、リレーショナル データベースで作業している場合は、データ モデルの設計方法についての習慣や直感が築かれているはずです。 Azure Cosmos DB に固有の制約のため (それは Azure Cosmos DB だけが持つ長所でもありますが)、それらのベスト プラクティスのほとんどはうまく流用できず、次善のソリューションになってしまうことがあります。 この記事の目的は、項目のモデリングからエンティティのコロケーションやコンテナーのパーティション分割まで、Azure Cosmos DB で現実のユース ケースをモデル化する完全なプロセスの手順を示すことです。
この記事の概念を示すコミュニティで作成されたソース コードは、こちらでダウンロードまたは表示できます。
重要
コミュニティの共同作成者がこのコード サンプルを提供したのであり、Azure Cosmos DB チームはそのメンテナンスをサポートしていません。
シナリオ
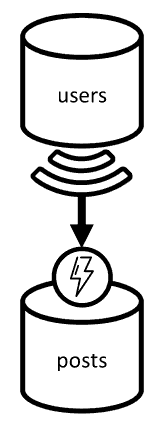
この演習では、"ユーザー" が "投稿" を作成できるブログ作成プラットフォームのドメインについて考えます。 また、ユーザーは "いいね! " を付けたり、投稿に "コメント" を追加したりすることもできます。
ヒント
"斜体" で強調されているいくつかの単語は、モデルで操作する必要がある "モノ" の種類を示します。
仕様への要件の追加:
- フロント ページには、最近作成された投稿のフィードが表示されます。
- 1 人のユーザーのすべての投稿、1 つの投稿に対するすべてのコメント、1 つの投稿に対するすべてのいいね! をフェッチできます。
- 投稿と共に、作成者のユーザー名および投稿に付いているコメントといいね! の数が返されます。
- コメントといいね! については、それを作成したユーザーのユーザー名も返されます。
- 一覧表示するときは、投稿の内容の切り詰められた概要だけを表示する必要があります。
主要なアクセス パターンを明らかにする
最初に、ソリューションのアクセス パターンを明らかにすることにより、初期の仕様に構造を提供します。 Azure Cosmos DB のデータ モデルを設計するときは、モデルで対応する必要がある要求を理解し、モデルがそれらの要求に効率的に対応できることを確認することが重要です。
全体的なプロセスをわかりやすくするため、CQRS のボキャブラリを借りて、さまざまな要求をコマンドまたはクエリに分類します。 CQRS では、コマンドは書き込み要求 (つまり、システムを更新する意図) であり、クエリは読み取り専用の要求です。
プラットフォームで公開される要求の一覧を次に示します。
- [C1] ユーザーを作成/編集する
- [Q1] ユーザーを取得する
- [C2] 投稿を作成/編集する
- [Q2] 投稿を取得する
- [Q3] ユーザーの投稿を短い形式で一覧表示する
- [C3] コメントを作成する
- [Q4] 投稿のコメントを一覧表示する
- [C4] 投稿に "いいね!" を付ける
- [Q5] 投稿のいいね! を一覧表示する
- [Q6] 最近作成された x 件の投稿を短い形式で一覧表示する (フィード)
この段階では、各エンティティ (ユーザー、投稿など) の内容の詳細については考えていません。 これは、通常、リレーショナル ストアについて設計するときに最初に取り組むステップの 1 つです。 これらのエンティティをテーブル、列、外部キーなどの観点から変換する方法を把握する必要があるので、このステップを最初に開始します。書き込み時にスキーマが適用されないドキュメント データベースでは、これはそれほど重要なことではありません。
最初からアクセス パターンを明らかにすることが重要である主な理由は、この要求の一覧がテスト スイートになるためです。 データ モデルの作業を繰り返すたびに、各要求を検討してパフォーマンスとスケーラビリティを確認します。 各モデルで使用される要求ユニットを計算して最適化します。 これらのすべてのモデルでは、既定のインデックス作成ポリシーが使用されますが、これは特定のプロパティのインデックスを作成することでオーバーライドすることができ、それによって RU の使用量と待機時間をさらに向上させることができます。
V1: 最初のバージョン
2 つのコンテナー users と posts から始めます。
users コンテナー
このコンテナーにはユーザー項目のみが格納されます。
{
"id": "<user-id>",
"username": "<username>"
}
このコンテナーは id でパーティション分割します。つまり、そのコンテナー内の各論理パーティションには、1 つの項目だけが格納されます。
posts コンテナー
このコンテナーでは、投稿、コメント、いいね! などのエンティティをホストします。
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
このコンテナーは postId でパーティション分割します。つまり、そのコンテナー内の各論理パーティションには、1 つの投稿、その投稿に対するすべてのコメント、およびその投稿に対するすべてのいいね! が格納されます。
このコンテナーでホストされるエンティティの 3 つの種類を区別するため、このコンテナーに格納される項目に type プロパティを導入しました。
また、関連データについては埋め込みではなく参照を選択してあります (これらの概念について詳しくは、こちらのセクションを確認してください)。これは次のような理由によるものです。
- ユーザーが作成できる投稿の数には上限がない。
- 投稿の長さは任意である。
- 投稿が保持できるコメントといいね! の数に上限はない。
- 投稿自体を更新することなく、投稿にコメントまたはいいね! を追加できるようにしたい。
モデルのパフォーマンスの確認
ここでは、最初のバージョンのパフォーマンスとスケーラビリティを評価します。 前に識別した要求ごとに、その待機時間と、消費される要求ユニットの数を測定します。 この測定に使用するダミー データ セットには、100,000 人のユーザーが含まれ、1 ユーザーあたり 5 ~ 50 件の投稿、1 投稿あたり最大 25 個のコメントと 100 個のいいね! が含まれます。
[C1] ユーザーを作成/編集する
この要求は、users コンテナーの項目を作成または更新するだけなので、簡単に実装できます。 id パーティション キーのおかげで、要求はすべてのパーティションにうまく分散します。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1] ユーザーを取得する
ユーザーの取得は、users コンテナーから対応する項目を読み取ることによって行われます。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2] 投稿を作成/編集する
[C1] と同様に、posts コンテナーに書き込むことだけが必要です。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2] 投稿を取得する
最初に、posts コンテナーから対応するドキュメントを取得します。 ただし、それだけでは不十分です。仕様では、投稿の作成者のユーザー名、投稿に対するコメントの数、いいね! の数を集計する必要もあります。 一覧表示されている集計では、さらに 3 つの SQL クエリを発行する必要があります。
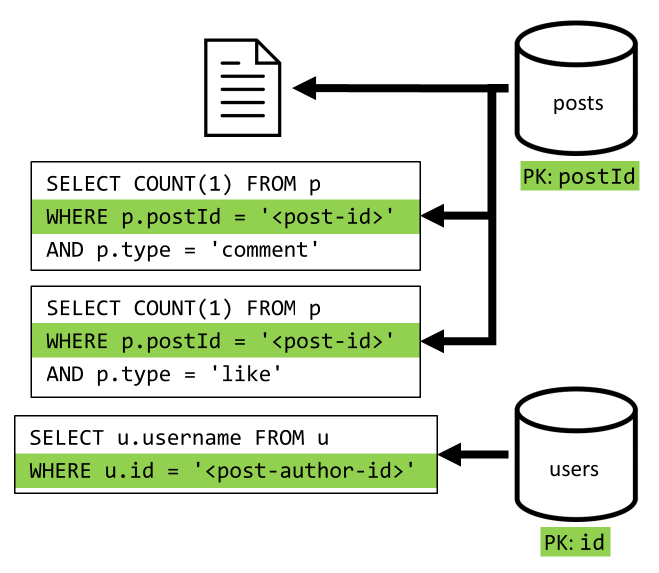
その他のクエリごとに、それぞれのコンテナーのパーティション キーでフィルター処理を行います。これこそが、パフォーマンスとスケーラビリティを最大にする必要がある部分です。 ただし、最終的には 1 つの投稿を返すために 4 つの操作を実行する必要があるので、その改善は次の繰り返しで行います。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3] ユーザーの投稿を短い形式で一覧表示する
最初に、その特定のユーザーに対応する投稿をフェッチする SQL クエリを使用して、目的の投稿を取得する必要があります。 ただし、作成者のユーザー名およびコメントといいね! の数を集計するため、クエリをさらに発行する必要があります。
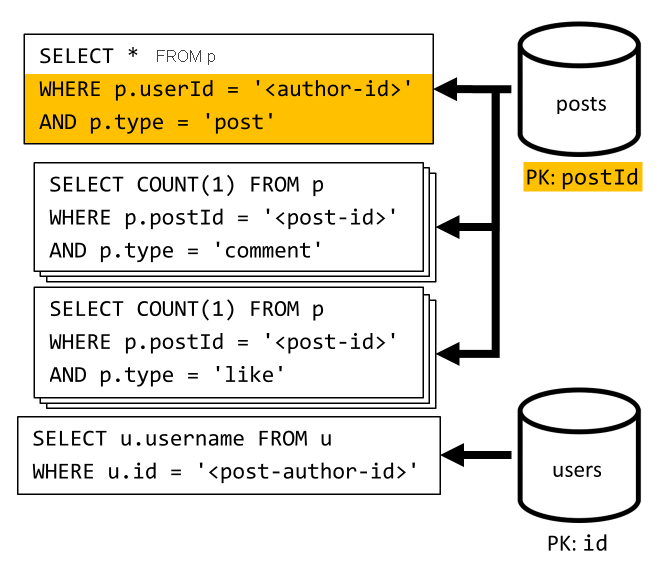
この実装では、多くの欠点が示されています。
- 最初のクエリによって返される各投稿に対し、コメントといいね! の数を集計するクエリを発行する必要があります。
- メインのクエリでは
postsコンテナーのパーティション キーによるフィルター処理が行われないので、ファンアウトとパーティション スキャンがコンテナー全体に対して行われます。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3] コメントを作成する
コメントは、対応する項目を posts コンテナーに書き込むことによって作成されます。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
7 ms |
8.57 RU |
✅ |
[Q4] 投稿のコメントを一覧表示する
最初に、やはりその投稿のすべてのコメントをフェッチするクエリを実行し、コメントごとに個別にユーザー名を集計する必要もあります。
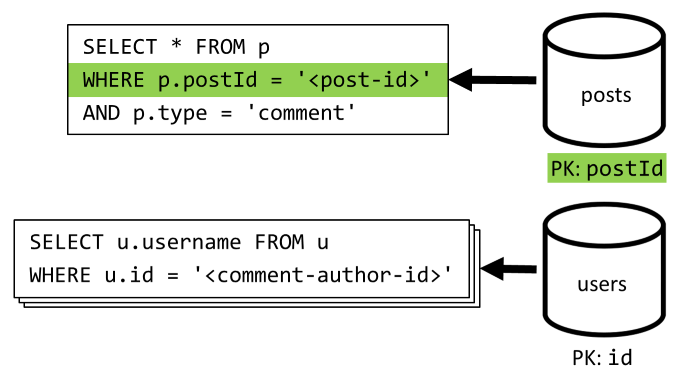
メイン クエリはコンテナーのパーティション キーでフィルター処理されますが、ユーザー名の個別集計は全体的なパフォーマンスに悪影響を与えます。 それについては後に改善します。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4] 投稿に "いいね!" を付ける
[C3] と同じように、posts コンテナーに対応する項目を作成します。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
6 ms |
7.05 RU |
✅ |
[Q5] 投稿のいいね! を一覧表示する
[Q4] と同じように、その投稿に対するいいね! のクエリを実行した後、それらのユーザー名を集計します。
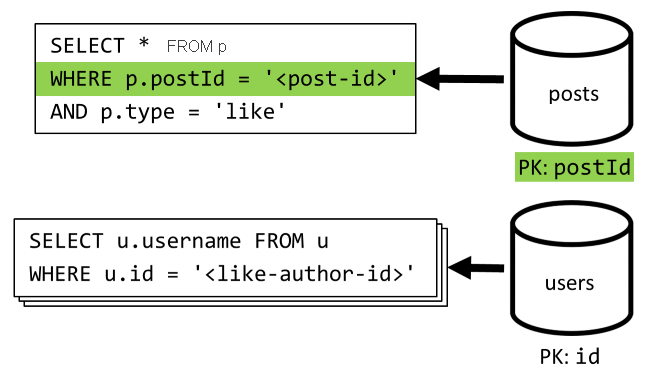
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6] 最近作成された x 件の投稿を短い形式で一覧表示する (フィード)
作成日の降順に並べ替えられた posts コンテナーのクエリを実行することによって最新の投稿をフェッチした後、各投稿のユーザー名およびコメントといいね! の数を集計します。
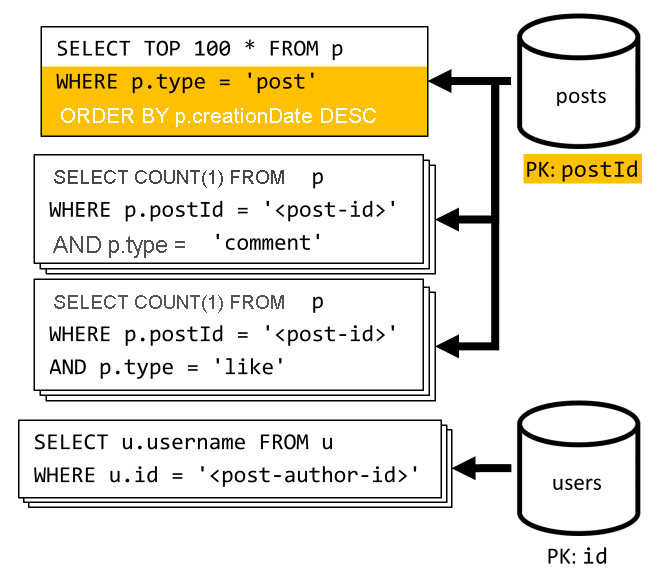
やはり、最初のクエリでは posts コンテナーのパーティション キーによるフィルター処理は行われないので、コストのかかるファンアウトが発生します。この場合は、大きい結果セットを対象とし、結果を ORDER BY 句で並べ替えるためさらに悪くなり、要求ユニットに関するコストがさらに高くなります。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
V1 のパフォーマンスの検討
前のセクションで直面したパフォーマンスの問題を調べると、問題には主に 2 つのクラスがあることがわかります。
- 一部の要求では、必要なすべてのデータを収集するため、複数のクエリを発行する必要があります。
- 一部のクエリでは、対象のコンテナーのパーティション キーでフィルター処理されていないため、スケーラビリティを損なうファンアウトが発生します。
これらの問題を解決しましょう。まずは 1 つ目です。
V2: 非正規化を導入して読み取りクエリを最適化する
一部のケースでさらに要求を発行する必要があるのは、最初の要求の結果に取得する必要があるすべてのデータが含まれていないためです。 Azure Cosmos DB のような非リレーショナル データ ストアを使用する場合、データを非正規化することによって、データ セット全体でのこの種の問題が解決します。
この例では、投稿項目を変更し、投稿の作成者のユーザー名、コメントの数、いいね! の数を追加します。
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
また、コメント項目といいね! 項目も変更し、それらを作成したユーザーのユーザー名を追加します。
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
コメントといいね! の数の非正規化
実現したいのは、コメントまたはいいね! を追加するたびに、対応する投稿の commentCount または likeCount も増分することです。 postId によって posts コンテナーがパーティション分割されているので、新しい項目 (コメントまたはいいね!) とその対応する投稿は、同じ論理パーティション内に存在します。 その結果、ストアド プロシージャを使用して、その操作を実行できます。
コメント ([C3]) を作成するとき、posts コンテナーに新しい項目を追加するだけでなく、そのコンテナーに対して次のストアド プロシージャを呼び出します。
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
このストアド プロシージャは、投稿の ID と新しいコメントの本文をパラメーターとして受け取り、次のことを行います。
- 投稿を取得します
commentCountを増分します- 投稿を置き換えます
- 新しいコメントを追加します
ストアド プロシージャはアトミック トランザクションとして実行されるので、commentCount の値とコメントの実際の数が常に同期します。
新しいいいね! を追加するときも似たストアド プロシージャを呼び出して、likeCount を増分します。
ユーザー名の非正規化
ユーザー名の場合は、ユーザーが異なるパーティションに存在するだけでなく、異なるコンテナーに存在しているので、別のアプローチが必要になります。 パーティションとコンテナー間でデータを非正規化する場合は、ソース コンテナーの変更フィードを使用できます。
この例では、users コンテナーの変更フィードを使用して、ユーザーが自分のユーザー名を更新するたびに対応します。 それが発生したら、posts コンテナーで別のストアド プロシージャを呼び出すことによって、変更を反映します。
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
このストアド プロシージャは、ユーザーの ID と新しいユーザー名をパラメーターとして受け取り、次のことを行います。
userIdと一致するすべての項目をフェッチします (投稿、コメント、いいね!)- これらの項目ごとに次のことを行います
userUsernameを置き換えます- 項目を置き換えます
重要
このストアド プロシージャを posts コンテナーのすべてのパーティションで実行する必要があるため、この操作にはコストがかかります。 ほとんどのユーザーはサインアップ時に適切なユーザー名を選択し、変更することはないものと想定されるので、この更新が実行されることはほとんどありません。
V2 でのパフォーマンス向上の内容
V2 のパフォーマンス向上について説明しましょう。
[Q2] 投稿を取得する
これで、非正規化が行われたので、その要求を処理するために必要なのは 1 つの項目をフェッチすることだけです。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
2 ms |
1 RU |
✅ |
[Q4] 投稿のコメントを一覧表示する
ここでも、ユーザー名をフェッチしていた余分な要求を行わなくてよくなり、パーティション キーでフィルター処理を行う 1 つのクエリだけになります。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
4 ms |
7.72 RU |
✅ |
[Q5] 投稿のいいね! を一覧表示する
いいね! を一覧表示するときもまったく同じ状況です。
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
4 ms |
8.92 RU |
✅ |
V3: すべての要求がスケーラブルであることを確認する
全体的なパフォーマンスの向上を調べると、完全には最適化されていない要求がまだ 2 つあります。 これらの要求は [Q3] と [Q6] です。 これらは、対象コンテナーのパーティション キーでフィルター処理を行っていないクエリに関連する要求です。
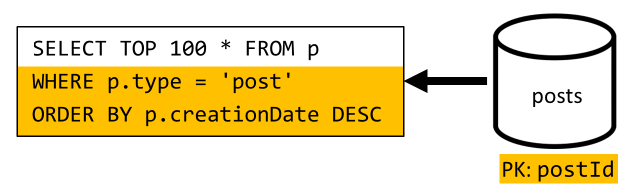
[Q3] ユーザーの投稿を短い形式で一覧表示する
この要求は既に、これ以上のクエリを不要にする V2 で導入された改善によるメリットがあります。

しかし、残りのクエリではまだ、posts コンテナーのパーティション キーによるフィルター処理が行われていません。
このような状況について考慮する方法は、単純です。
- この要求では、特定のユーザーに対するすべての投稿をフェッチしたいので、
userIdでフィルター処理を行う "必要があります"。 - それは、
userIdでパーティション分割していないpostsコンテナーに対して実行されるため、パフォーマンスがよくありません。 - 当然、このパフォーマンスの問題を解決するには、
userIdでパーティション分割されたコンテナーに対して要求を実行します。 - そのようなコンテナーは既にあります。
usersコンテナーです。
そこで、users コンテナーに投稿全体を複製することにより、2 番目のレベルの非正規化を導入します。 それを行うことで、パーティション分割されているディメンションが異なるだけの、投稿のコピーを実質的に取得し、その userId によっていっそう効率的に取得できるようになります。
users コンテナーには 2 種類の項目が含まれるようになっています。
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
次の点に注意してください。
- ユーザーと投稿を区別するため、ユーザー項目に
typeフィールドが導入されています。 - また、ユーザー項目に
userIdフィールドが追加されています。これはidフィールドと重複しますが、usersコンテナーが (以前のようなidではなく)userIdによってパーティション分割されるようになったため必要です
その非正規化を実現するには、再び変更フィードを使用します。 今回は、posts コンテナーの変更フィードに対応して、新しい投稿または更新された投稿を users コンテナーにディスパッチします。 また、投稿の一覧表示では完全なコンテンツを取得する必要はないので、処理で切り詰めることができます。
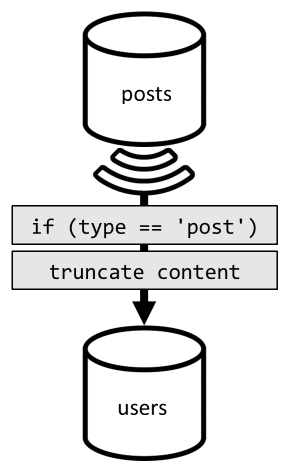
これで、クエリを users コンテナーにルーティングし、コンテナーのパーティション キーでフィルター処理できるようになりました。

| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
4 ms |
6.46 RU |
✅ |
[Q6] 最近作成された x 件の投稿を短い形式で一覧表示する (フィード)
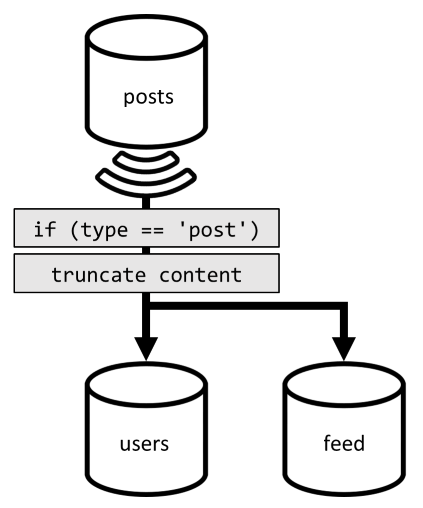
ここでも似た状況に対応する必要があります。V2 で導入された非正規化により、残っていた不要なその他のクエリが除去された後も、残りのクエリではコンテナーのパーティション キーによるフィルター処理が行われていません。
同じ方法で、この要求のパフォーマンスとスケーラビリティを最大限にするには、1 つのパーティションのみにヒットすることが必要です。 限られた数の項目だけを返す必要があるので、1 つのパーティションにのみヒットすると考えられます。 このブログ作成プラットフォームのホーム ページを設定するには、最新の 100 件の投稿を取得するだけでよく、データ セット全体をページ分割する必要はありません。
そのため、この最後の要求を最適化するには、この要求を処理するためだけに、3 番目のコンテナーを設計に導入します。 その新しい feed コンテナーに対して投稿を非正規化します。
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
type フィールドはこのコンテナーをパーティション分割します。これは常に項目内で post になります。 そうすることで、このコンテナー内のすべての項目は、必ず同じパーティション内に配置されます。
非正規化を実現するには、その新しいコンテナーに投稿をディスパッチするために前に導入した変更フィード パイプラインでフックすることだけが必要です。 考慮する必要がある 1 つの重要な点は、最新の 100 件の投稿のみが格納されることを確認する必要があることです。そうでない場合は、コンテナーのコンテンツがパーティションの最大サイズを超えて拡大する可能性があります。 この制限は、ドキュメントがコンテナーに追加されるたびに事後トリガーを呼び出すことで実装できます。
コレクションを切り詰める事後トリガーの本体を次に示します。
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
最後のステップは、新しい feed コンテナーにクエリを再ルーティングすることです。
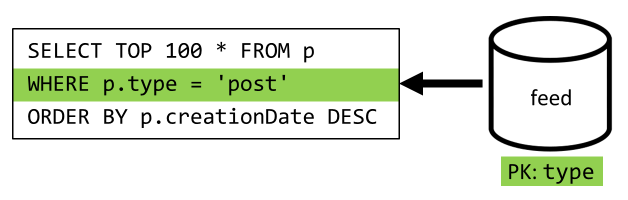
| 待機時間 | RU 料金 | パフォーマンス |
|---|---|---|
9 ms |
16.97 RU |
✅ |
まとめ
設計のさまざまなバージョンに導入したパフォーマンスとスケーラビリティの全体的な向上を調べてみましょう。
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
読み取り負荷の高いシナリオを最適化しました
お気付きかもしれませんが、ここでの作業では、書き込み要求 (コマンド) を犠牲にして、読み取り要求 (クエリ) のパフォーマンスを向上させることに集中しています。 多くの場合、書き込み操作では、変更フィードによって後続の非正規化がトリガーされるようになったため、計算の負荷は大きくなり、実現には時間がかかります。
これが読み取りパフォーマンスに重点を置いていることは、(多くのソーシャル アプリと同様に) ブログ作成プラットフォームでは読み取り負荷が高いという事実によって正当化されます。 読み取り負荷の高いワークロードの場合、通常、対応する必要がある読み取り要求の量が、書き込み要求数より桁違いに多いことを示します。 そのため、読み取り要求を低コストで高パフォーマンスにするため、書き込み要求の実行コストを高くすることには意味があります。
ここで行ったものの中で最も極端な最適化を調べた場合、[Q6] は 2000 以上の RU がわずか 17 RU になりました。項目あたり約 10 RU のコストで投稿を非正規化することによって、それを実現しました。 投稿の作成または更新より多くのフィード要求に対応するので、全体的なコスト削減を考えると、この非正規化のコストはごくわずかです。
非正規化は段階的に適用できる
この記事で調べたスケーラビリティの向上には、データ セット全体のデータの非正規化と複製が含まれます。 これらの最適化を一度に行う必要はないことに注意する必要があります。 パーティション キーでフィルター処理を行うクエリは大きな規模でパフォーマンスが向上しますが、あまり呼び出されない場合、または限られたデータ セットに対して呼び出される場合であれば、クロスパーティション クエリでも問題ありません。 プロトタイプを構築するだけの場合、または小規模の制御されたユーザー ベースで製品を使い始める場合は、おそらく、これらの改善を後回しにすることができます。 その場合に重要なことは、モデルのパフォーマンスを監視して、いつ着手すべきかを判断できるようにすることです。
更新を他のコンテナーに配布するために使用した変更フィードでは、すべての更新が永続的に格納されます。 この永続性により、コンテナーの作成時からのすべての更新を要求することができ、システムに既に多数のデータが存在する場合であっても、1 回限りのキャッチアップ操作として非正規化されたビューを開始できます。
次のステップ
実用的なデータ モデリングとパーティション分割に関するこの概要の後は、ここで説明した概念を次の記事で確認できます。