Azure Cosmos DBでは、パーティション分割を使用して、アプリケーションのパフォーマンスニーズに合わせてデータベース内のコンテナーをスケーリングします。 コンテナー内の項目は、論理パーティションと呼ばれる個別のサブセットに分割されます。 論理パーティションは、コンテナー内の各項目に関連付けられている パーティション キー の値に基づいて形成されます。 1 つの論理パーティション内のすべての項目で、パーティション キーの値は同じです。
たとえば、あるコンテナーに項目が保持されているとします。 各項目の UserID プロパティには一意の値があります。
UserID がそのコンテナー内の項目のパーティション キーであり、1,000 個の一意の UserID 値がある場合、1,000 個の論理パーティションがそのコンテナー内に作成されます。
コンテナー内の各項目には、その論理パーティションと、そのパーティション内で一意の項目 ID を決定するパーティション キーがあります。 パーティション キーと項目 ID を組み合わせて、項目のインデックスが作成されます。インデックスによって、項目が一意に識別されます。 パーティション キーを選択することは、アプリケーションのパフォーマンスに影響する重要な決定事項です。
注
一部の分散データベース システムと学習資料では、 シャード キー という用語を使用して、シャード間でのデータの分散方法を決定するプロパティを記述します。 Azure Cosmos DBでは、この同じ概念を パーティション キー と呼びます。
どちらの用語もデータの分散と検索に使用される値を指しますが、パーティション キー は、Azure Cosmos DBドキュメントと API 全体で使用される正式で正しい用語です。
この記事では、論理パーティションと物理パーティションの関係について説明し、パーティション分割のベスト プラクティスについて説明し、Azure Cosmos DBでの水平スケーリングのしくみの詳細を示します。 パーティション キーを選択するためにこれらの内部の詳細を理解する必要はありませんが、この記事では、Azure Cosmos DBのしくみを明確にするために説明します。
論理パーティション
論理パーティションは、同じパーティション キーを共有する一連のアイテムです。 たとえば、食物の栄養に関するデータが含まれているコンテナーでは、すべてのアイテムに foodGroup プロパティが含まれています。 このコンテナーのパーティション キーとして foodGroup プロパティを使用します。
foodGroup、Beef Products、Baked Products など、Sausages and Luncheon Meats に特定の値を持つアイテムのグループが、個別の論理パーティションを形成します。
論理パーティションでは、データベース トランザクションのスコープも定義します。 論理パーティション内のアイテムは、スナップショット分離が指定されたトランザクションを使用して更新することができます。 コンテナーに新しい項目が追加されると、新しい論理パーティションがシステムによって透過的に作成されます。 基になるデータを削除するときに、論理パーティションの削除について心配する必要はありません。
コンテナー内の論理パーティションの数に制限はありません。 各論理パーティションには、最大 20 GB のデータを格納できます。 有効なパーティション キーには、さまざまな値があります。 たとえば、すべてのアイテムに foodGroup プロパティが含まれているコンテナーでは、Beef Products 論理パーティション内のデータを最大 20 GB まで拡張できます。 可能性がある多様な値を格納できるパーティション キーを選択することで、コンテナーを確実にスケーリングできます。
階層型パーティション キーを使用してパーティション キーが 20 GB を超える可能性があるシナリオがある場合は、役立ちます。 この機能を使用する場合は、パーティション キーに対して最大 3 レベルの階層を構成して、データ分散をさらに最適化し、より高いレベルのスケーリングを行うことができます。 階層パーティション キーの概要を参照してください。
Azure Monitor アラートを使用して論理パーティションのサイズが20 GBに近づいているかどうかを監視。
物理パーティション
コンテナーは、物理パーティション間でデータとスループットを分散することでスケーリングされます。 内部的には、1 つまたは複数の論理パーティションが単一の物理パーティションにマップされます。 小さなコンテナーには通常、多くの論理パーティションがありますが、必要なのは 1 つの物理パーティションのみです。 論理パーティションとは異なり、物理パーティションは内部システム実装であり、Azure Cosmos DBはそれらを完全に管理します。
コンテナー内の物理パーティションの数は、次の特性によって決まります。
プロビジョニングされたスループットの量 (個々の物理パーティションからは、1 秒あたり最大 10,000 の要求ユニットのスループットを提供できます)。 物理パーティションに 10,000 RU/秒の制限がある場合、論理パーティションにも 10,000 RU/秒の制限があることを意味します。各論理パーティションは 1 つの物理パーティションにのみマップされるためです。
データ ストレージの合計 (個々の物理パーティションには、最大 50 GB のデータを格納できます)。
注
物理パーティションは内部システム実装であり、Azure Cosmos DBによって完全に管理されます。 物理パーティションは制御できないため、ソリューションを開発するときは物理パーティションには重点を置かないでください。 代わりに、パーティション キーに重点を置いてください。 論理パーティション間でスループットの消費が均等に分散されるパーティション キーを選択すると、物理パーティション間でのスループットが確実に均等に消費されます。
コンテナー内の物理パーティションの合計数に制限はありません。 プロビジョニングされたスループットまたはデータ サイズが大きくなると、Azure Cosmos DBは既存の物理パーティションを分割して新しい物理パーティションを自動的に作成します。 物理パーティションの分割がアプリケーションの可用性に影響を与えることはありません。 物理パーティションが分割された後も、単一の論理パーティション内のすべてのデータは同じ物理パーティションに格納されます。 物理パーティションの分割では、物理パーティションに対する論理パーティションの新しいマッピングが作成されるだけです。
コンテナーに対してプロビジョニングされたスループットは、物理パーティション間で均等に分割されます。 要求を均等に分散しないパーティション キーの設計では、"ホット" になるパーティションの小さなサブセットに送信される要求の数が多すぎる可能性があります。ホットなパーティションは、プロビジョニングされたスループットの使用が非効率的になる原因となります。これにより、レート制限が発生し、コストが高くなります。
たとえば、パーティション キーとして指定されたパス /foodGroup を持つコンテナーを考えてみましょう。 コンテナーには任意の数の物理パーティションを含めることができますが、この例では 3 つとします。 1 つの物理パーティションには複数のパーティション キーを含めることができます。 例として、最も大きい物理パーティションには、上位 3 つの最も大きいサイズの論理パーティション (Beef Products、Vegetable and Vegetable Products、Soups, Sauces, and Gravies) が含まれているとします。
1 秒あたり 18,000 要求ユニット (RU/秒) のスループットを割り当てた場合、3 つの物理パーティションではそれぞれ、プロビジョニングされたスループットの合計の 3 分の 1 を使用できます。 選択されている物理パーティション内では、論理パーティション キー (Beef Products、Vegetable and Vegetable Products、および Soups, Sauces, and Gravies) は、物理パーティションにプロビジョニングされた 6,000 RU/秒を共同で利用できます。 プロビジョニングされたスループットはコンテナーの物理パーティション全体に均等に分割されるため、スループットの消費が均等に分散されるパーティション キーを選択することが重要です。 詳細については、適切な論理パーティション キーの選択に関するセクションを参照してください。
論理パーティションの管理
Azure Cosmos DBは、コンテナーのスケーラビリティとパフォーマンスのニーズを満たすために、物理パーティションへの論理パーティションの配置を自動的に管理します。 アプリケーションのスループットとストレージの要件が増えると、Azure Cosmos DBは論理パーティションを移動して、より多くの物理パーティションに負荷を分散させます。 物理パーティションの詳細を確認する。
Azure Cosmos DBでは、ハッシュベースのパーティション分割を使用して、論理パーティションを物理パーティションに分散します。 Azure Cosmos DBは、項目のパーティション キー値をハッシュします。 ハッシュの結果で、論理パーティションが決定します。 次に、Azure Cosmos DBは、パーティション キー ハッシュのキー領域を物理パーティション全体に均等に割り当てます。
ストアド プロシージャまたはトリガー内のトランザクションは、1 つの論理パーティション内の項目に対してのみ使用できます。
レプリカ セット
各物理パーティションは、一連のレプリカで構成されます (レプリカ セット とも呼ばれます)。 各レプリカによって、データベース エンジンのインスタンスがホストされます。 レプリカ セットにより、物理パーティション内に格納されたデータの耐久性、高可用性、一貫性が確保されます。 物理パーティションの各レプリカは、そのパーティションのストレージ クォータを継承します。 物理パーティションのすべてのレプリカは、物理パーティションに割り当てられたスループットを一元的にサポートします。 Azure Cosmos DBレプリカ セットを自動的に管理します。
小さなコンテナーは通常、1 つの物理パーティションを必要としますが、少なくとも 4 つのレプリカが保持されます。
この図は、論理パーティションがグローバルに分散された物理パーティションにどのようにマップされるかを示しています。 画像の [パーティション セット] は、複数のリージョンにまたがって同じ論理パーティション キーを管理している物理パーティションのグループを表しています。
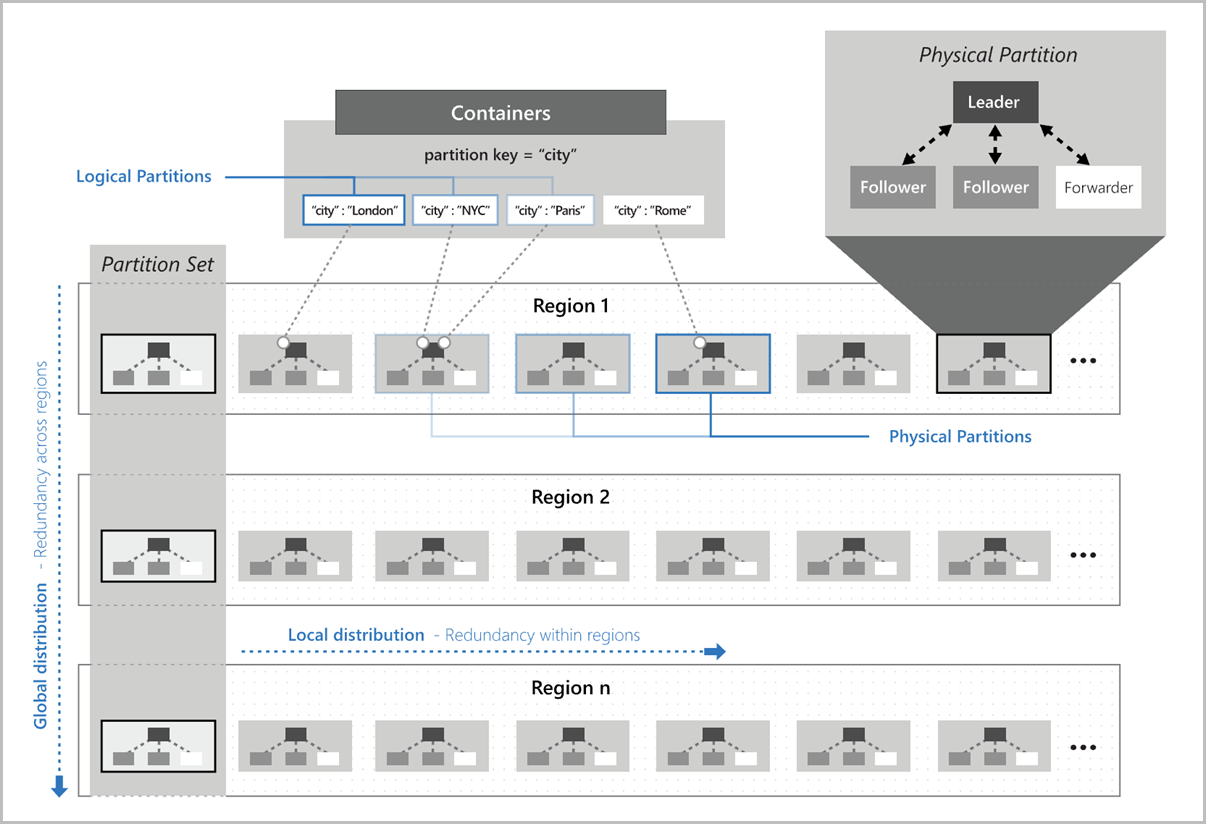
パーティション キーを選択する
パーティション キーには、パーティション キーのパスとパーティション キーの値の 2 つのコンポーネントがあります。 たとえば、パーティション キーとして "userId" を選択した場合、項目 { "userId" : "Andrew", "worksFor": "Microsoft" } について考えてみます。2 つのパーティション キー コンポーネントは次のとおりです。
パーティション キーのパス (例: "/userId")。 パーティション キーのパスには、英数字とアンダースコア (_) 文字を使用できます。 また、標準パス表記 (/) を使用して、入れ子になったオブジェクトを使用することもできます。
パーティション キーの値 (例:"Andrew")。 パーティション キーの値には、文字列型または数値型を使用できます。
スループット、ストレージ、パーティション キーの長さの制限については、Azure Cosmos DB サービス クォータに関する記事を参照してください。
パーティション キーの選択は、Azure Cosmos DBでのシンプルで重要な設計上の選択です。 パーティション キーを選択すると、そのパーティション キーを適切に変更することはできません。 パーティション キーを変更する必要がある場合は、必要なパーティション キーを使用して、新しいコンテナーにデータを移動する必要があります。 コンテナー コピー ジョブ は、このプロセスに役立ちます。 または、 グローバル セカンダリ インデックス (プレビュー) を追加して、特定のクエリ パターン用に最適化されたさまざまなパーティション キーを使用してデータのコピーを作成することもできます。
すべてのコンテナーで、パーティション キーが次のようになっている必要があります。
値が変更されないプロパティであること。 プロパティがパーティション キーの場合、そのプロパティの値を更新することはできません。
Important
パーティション キーの値は変更できません。 項目が作成されると、そのパーティション キーの値をその場で変更することはできません。 項目の置換操作では、パーティション キーが既存の項目と一致する必要があります。パーティション間で項目を移動するために使用することはできません。 項目を "移動" するには、新しいパーティション キー値を持つ新しい項目を作成し、元の項目を削除する必要があります。 これら 2 つの操作は、異なる論理パーティション間でアトミックに実行することはできません。
String値のみを含むか、Stringに従って倍精度数値の境界を超える可能性がある場合は、数値を に変換します。 Json 仕様では、相互運用性の問題が原因で、この境界外の数値を使用するのが不適切なやり方である理由が説明されています。 パーティション キー列は変更不可能であり、後で変更するにはデータ移行が必要になるため、これらの懸念は特にパーティション キー列に関係します。高いカーディナリティがあること。 言い換えると、プロパティには、有効な値が広範囲に及ぶことが必要です。
要求ユニット (RU) の消費量とデータ ストレージをすべての論理パーティションに均等に分散すること。 この分散により、物理パーティション全体でも RU の消費とストレージの分散が保証されます。
通常は 2048 バイト以下の値、または大きなパーティション キーが有効になっていない場合は 101 バイトの値があること。 詳細については、大きいパーティション キーに関する記事を参照してください。
Azure Cosmos DBで multi-item ACID トランザクションが必要な場合は、 ストアド プロシージャまたはトリガーを使用する必要があります。 すべての JavaScript ベースのストアド プロシージャとトリガーのスコープは、1 つの論理パーティションに限定されます。
注
物理パーティションが 1 つだけの場合、またはパーティションの数が小さい場合 (たとえば、 <= 5)、パーティション キーの値が関係しない可能性があります。 クエリの場合、パーティション キーが含まれていない場合に追加の各物理パーティションをチェックするオーバーヘッドは、物理パーティションあたり 2 から 3 RU です。 物理パーティションの詳細を確認する。
パーティション キーの種類
| パーティション分割戦略 | いつ使用するか | 長所 | 短所 |
|---|---|---|---|
| 通常のパーティション キー (CustomerId、OrderId など) | パーティション キーのカーディナリティが高く、クエリ パターン (CustomerId によるフィルター処理など) に合わせて使用します。 クエリが主に 1 人の顧客のデータを対象とするワークロードに適しています (たとえば、顧客のすべての注文を取得する)。 | 管理が簡単です。 アクセス パターンがパーティション キーと一致する場合の効率的なクエリ (CustomerId によるすべての注文のクエリなど)。 アクセス パターンに一貫性がある場合は、クロスパーティション クエリを防止します。 | 一部の値 (トラフィックの多い顧客など) が他の値よりも多くのデータを生成する場合に、ホット パーティションが発生するリスク。 特定のキーのデータ ボリュームが急速に増加すると、論理パーティションあたり 20 GB の制限に達する可能性があります。 |
| 合成パーティション キー (CustomerId + OrderDate など) | カーディナリティが高く、クエリ パターンに一致するフィールドが 1 つもない場合に使用します。 データを物理パーティション間で均等に分散する必要がある書き込み負荷の高いワークロードに適しています (たとえば、同じ日付に多数の注文が行われます)。 | パーティション間でデータを均等に分散し、ホット パーティションを減らすのに役立ちます (CustomerId と OrderDate の両方による注文の分散など)。 複数のパーティションに書き込みを分散し、スループットを向上させます。 | 1 つのフィールドでのみフィルター処理するクエリ (CustomerId のみなど) では、パーティション間クエリが発生する可能性があります。 パーティション間クエリにより、RU 消費量が増加し (存在するすべての物理パーティションに対して 2 ~ 3 RU/秒の追加料金)、待機時間が増加する可能性があります。 |
| 階層パーティション キー (HPK) (CustomerId/OrderId、StoreId/ProductId など) | 大規模なデータセットをサポートするために複数レベルのパーティション分割が必要な場合に使用します。 クエリが階層の第 1 レベルと第 2 レベルでフィルター処理する場合に最適です。 | 複数のレベルのパーティション分割を作成することで、20 GB の制限を回避するのに役立ちます。 両方の階層レベルに対する効率的なクエリ (たとえば、最初に CustomerID でフィルター処理し、次に OrderID でフィルター処理するなど)。 最上位レベルを対象とするクエリ (たとえば、特定の CustomerID からすべてのデータを取得する) のクロスパーティション クエリを最小限に抑えます。 | 第 1 レベルのキーのカーディナリティが高く、ほとんどのクエリに含まれるように、慎重な計画が必要です。 通常のパーティション キーよりも管理が複雑です。 クエリが階層に合わない場合 (たとえば、CustomerID が第 1 レベルの場合は OrderID によるフィルター処理のみ)、クエリのパフォーマンスが低下する可能性があります。 |
| グローバル セカンダリ インデックス (GSI) - プレビュー (たとえば、ソースは CustomerId を使用し、GSI は OrderId を使用) | すべてのクエリ パターンで機能する 1 つのパーティション キーが見つからない場合に使用します。 複数の独立したプロパティで効率的にクエリを実行する必要があり、多数の物理パーティションを持つワークロードに最適です。 | GSI パーティション キーを使用する場合のクロスパーティション クエリを排除します。 ソース コンテナーからの自動同期を使用して、同じデータに対して複数のクエリ パターンを許可します。 ワークロード間のパフォーマンスの分離。 | 各 GSI には、追加のストレージと RU コストがあります。 GSI 内のデータは、最終的にはソース コンテナーと一致します。 |
読み取り負荷の高いコンテナーのパーティション キー
ほとんどのコンテナーでは、パーティション キーを選択するときに考慮する必要があるのは、これらの条件だけです。 ただし、大規模な読み取り負荷の高いコンテナーの場合は、クエリでフィルターとして頻繁に表示されるパーティション キーを選択することができます。 フィルターの述語にパーティション キーを含めることにより、クエリ呼び出しを関係する物理パーティションにだけ効率的にルーティングできます。
ワークロードの要求のほとんどがクエリで、ほとんどのクエリが同じプロパティに対する等値フィルターを使用している場合、このプロパティが適切なパーティション キーの選択になります。 たとえば、UserID に対してフィルター処理を行うクエリを頻繁に実行する場合、パーティション キーとして UserID を選択するとクロスパーティション クエリの数が減少します。
コンテナーが小さい場合は、クロスパーティション クエリのパフォーマンスについて心配するような量の物理パーティションがない可能性が高いといえます。 Azure Cosmos DBのほとんどの小さなコンテナーでは、1 つまたは 2 つの物理パーティションのみが必要です。
コンテナーがいくつかの物理パーティションに拡張される可能性がある場合は、クロスパーティション クエリを最小化するパーティション キーを選択する必要があります。 次のいずれかのシナリオに該当する場合、コンテナーには複数の物理パーティションが必要です。
コンテナーに 30,000 を超える要求ユニットがプロビジョニングされている
コンテナーが 100 GB を超えるデータを格納する
クロスパーティション クエリのグローバル セカンダリ インデックス
アプリケーションで複数の異なるプロパティを効率的に使用してデータのクエリを実行する必要がある場合、 グローバル セカンダリ インデックス (プレビュー) は、データセットに対して 1 つのパーティション キー戦略を使用する代わりに使用できます。 グローバル セカンダリ インデックスは、異なるパーティション キーを持つ追加のコンテナーであり、ソース コンテナーのデータと自動的に同期されます。
次の場合は、グローバル セカンダリ インデックスを検討してください。
- 1 つのパーティション キー戦略では満たされない複数のクエリ パターンがある
- 既存のパーティション キーを変更すると、中断が発生する
- 分析ワークロードまたは検索ワークロードをトランザクション操作から分離する必要がある
グローバル セカンダリ インデックスは、特定のクエリ パターン用に最適化された異なるパーティション キーを持つ同じデータを格納することで、クロスパーティション クエリを回避するのに役立ちます。 この方法では、パーティション キーの最適化だけでは不十分なシナリオでは、RU の消費量を大幅に削減し、クエリのパフォーマンスを向上させることができます。
パーティション キーとして項目 ID を使用する
注
このセクションは主に、NoSQLの API に適用されます。 Gremlin 用 API などの他の API では、パーティション キーとしての一意識別子はサポートされていません。
コンテナーに、有効な値が広範囲にわたるプロパティがある場合は、パーティション キーの選択肢として優れている可能性があります。 このようなプロパティの 1 つの例として、項目 ID があります。 サイズが小さく読み取り負荷の高いコンテナー、または、あらゆるサイズの書き込みの多いコンテナーの場合、項目 ID (/id) は、必然的にパーティション キーに適しています。
"項目 ID" のシステム プロパティは、コンテナー内のすべての項目に存在します。 項目の論理 ID を表す他のプロパティがある場合があります。 多くの場合、これら一意の識別子は 項目 ID と同じ理由で、パーティション キーとして選択することに適しています。
項目 ID は、次のような理由でパーティション キーの選択肢として適しています。
- 有効な値の範囲が幅広い (項目ごとに 1 つの一意の 項目 ID)。
- 項目ごとに一意の "項目 ID" があるため、"項目 ID" は、RU の消費量とデータ ストレージを均等に分散する上で非常に役立ちます。
- "項目 ID" がわかっている場合は、項目のパーティション キーが常にわかっているため、効率的なポイント読み取りを簡単に行うことができます。
パーティション キーとして 項目 ID を選択する場合は、次の注意事項を考慮してください。
- 項目 ID がパーティション キーの場合は、コンテナー全体に対して一意識別子になります。 重複する識別子を持つ項目を作成することはできません。
- 多数の物理パーティションを含む読み取り負荷の高いコンテナーがある場合、"項目 ID" を持つ等値フィルターを使用するクエリの方が効率的になります。
- ストアド プロシージャまたはトリガーは、複数の論理パーティションを対象とすることができません。
関連コンテンツ
- Azure Cosmos DB のプロビジョニング済みスループット
- Azure Cosmos DB でのグローバルな分散
トレーニング: Azure Cosmos DB