join 演算子
各テーブルの指定した列の値を照合することにより、2 つのテーブルの行をマージして新しいテーブルを作成します。
Kusto 照会言語 (KQL) にはさまざまな種類の結合が用意されており、それぞれが結果テーブルのスキーマと行に異なる方法で影響を与えます。 たとえば、inner 結合を使用する場合、テーブルには、左側のテーブルと同じ列と、右側のテーブルの列が含まれます。 最適なパフォーマンスを得るために、一方のテーブルが他方よりも常に小さい場合は、それを join 演算子の左側として使用します。
次の図は、各結合によって実行される操作の視覚的な表現を示しています。
構文
LeftTable|join [ kind=JoinFlavor ] [ヒント] (RightTable)on"条件"
構文規則について詳しく知る。
パラメーター
| 名前 | 型 | 必須 | 説明 |
|---|---|---|---|
| LeftTable | string |
✔️ | 行をマージする左側のテーブルまたは表形式の式。外部テーブルとも呼ばれます。 $left と示されます。 |
| JoinFlavor | string |
実行する結合の種類: innerunique、inner、leftouter、rightouter、fullouter、leftanti、rightanti、leftsemi、rightsemi。 既定値は、innerunique です。 結合の種類の詳細については、「戻り値」を参照してください。 |
|
| [ヒント] | string |
行の照合操作と実行プランの動作を制御する、スペースで区切られた "名前 = 値" の形式の 0 個以上の結合のヒント。 詳細については、「ヒント」を参照してください。 |
|
| RightTable | string |
✔️ | 行をマージする右側のテーブルまたは表形式の式。内部テーブルとも呼ばれます。 $right と示されます。 |
| 条件 | string |
✔️ | LeftTable の行を RightTable の行と照合する方法を指定します。 照合する列の名前が両方のテーブルで同じである場合は、ONColumnName 構文を使用します。 それ以外の場合は、ON $left.LeftColumn==$right. RightColumn 構文を使用します。 複数の条件を指定するには、"and" キーワードを使用するか、コンマで区切ります。 コンマを使用する場合、条件は "and" 論理演算子を使用して評価されます。 |
ヒント
パフォーマンスを最高にするには、一方のテーブルが他より常に小さい場合は、それを結合の左側として使用します。
[ヒント]
| ヒント キー | 値 | 説明 |
|---|---|---|
hint.remote |
auto, left, local, right |
「クラスター間の結合」を参照してください |
hint.strategy=broadcast |
クラスター ノードでクエリ負荷を共有する方法を指定します。 | ブロードキャスト結合を参照してください。 |
hint.shufflekey=<key> |
shufflekey クエリは、データをパーティション化するキーで、クラスター ノードのクエリ負荷を共有します。 |
クエリ*のシャッフルを参照 |
hint.strategy=shuffle |
shuffle 戦略クエリは、クラスター ノードのクエリ負荷を共有します。各ノードで 1つずつ、データのパーティション化を処理します。 |
シャッフル クエリに関するページを参照してください |
| 名前 | 値 | 説明 |
|---|---|---|
hint.remote |
auto, left, local, right |
|
hint.strategy=broadcast |
クラスター ノードでクエリ負荷を共有する方法を指定します。 | ブロードキャスト結合を参照してください。 |
hint.shufflekey=<key> |
shufflekey クエリは、データをパーティション化するキーで、クラスター ノードのクエリ負荷を共有します。 |
クエリ*のシャッフルを参照 |
hint.strategy=shuffle |
shuffle 戦略クエリは、クラスター ノードのクエリ負荷を共有します。各ノードで 1つずつ、データのパーティション化を処理します。 |
クエリ*のシャッフルを参照 |
Note
結合のヒントによって join のセマンティックが変更されることはありませんが、パフォーマンスが影響を受ける可能性があります。
戻り値
戻り値のスキーマと行は、結合のフレーバーによって異なります。 結合フレーバーは、kind キーワードを使用して指定します。 サポートされている結合フレーバーを次の表に示します。 特定の結合フレーバーの例を表示するには、結合 フレーバー 列のリンクを選択します。
| 結合のフレーバー | 戻り値 | 図 |
|---|---|---|
| innerunique (既定値) | 左側の重複を除去する内部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 右側のテーブルの行と一致する左側のテーブルの重複除去されたすべての行 |

|
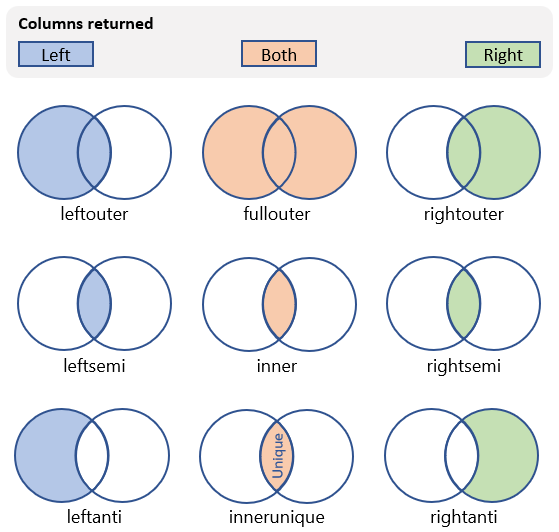
| inner | 標準の内部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 両方のテーブルで一致する行のみ |
|
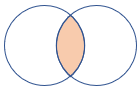
| leftouter | 左外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 左側のテーブルのすべてのレコードと、右側のテーブルの一致する行のみ |
|
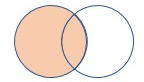
| rightouter | 右外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 右側のテーブルのすべてのレコードと、左側のテーブルの一致する行のみ |
|
| fullouter | 完全外部結合 スキーマ: 両方のテーブルのすべての列 (一致するキーを含む) 行: 一致しないセルに null が設定された、両方のテーブルのすべてのレコード |
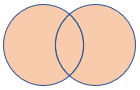
|
| leftsemi | 左半結合 スキーマ: 左側のテーブルのすべての列 行: 右側のテーブルのレコードと一致する左側のテーブルのすべてのレコード |
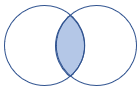
|
leftanti, anti, leftantisemi |
Left Anti Join と Semi Variant スキーマ: 左側のテーブルのすべての列 行: 右側のテーブルのレコードと一致しない左側のテーブルのすべてのレコード |
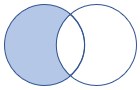
|
| rightsemi | 右半結合 スキーマ: 右側のテーブルのすべての列 行: 左側のテーブルのレコードと一致する右側のテーブルのすべてのレコード |
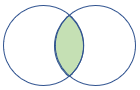
|
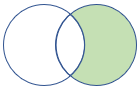
rightanti, rightantisemi |
Right Anti Join と Semi Variant スキーマ: 右側のテーブルのすべての列 行: 左側のテーブルのレコードと一致しない右側のテーブルのすべてのレコード |
|
クロス結合
KQL では、クロス結合フレーバーは提供されていません。 ただし、プレースホルダー キーのアプローチを使用して、クロス結合の効果を実現できます。
次の例では、プレースホルダー キーを両方のテーブルに追加してから内部結合操作に使用して、クロス結合のような動作を効果的に実現しています。
X | extend placeholder=1 | join kind=inner (Y | extend placeholder=1) on placeholder
関連コンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示