この記事では、Gen AI アプリケーション用の非構造化データ パイプラインを構築する方法について説明します。 非構造化パイプラインは、Retrieval-Augmented 生成 (RAG) アプリケーションに特に役立ちます。
テキスト ファイルや PDF などの非構造化コンテンツを、AI エージェントや他のリトリーバーが照会できるベクター インデックスに変換する方法について説明します。 また、データのチャンク、インデックス作成、解析を最適化するためにパイプラインを実験および調整する方法についても説明します。これにより、パイプラインのトラブルシューティングと実験を行って、より良い結果を得られます。
非構造化データパイプラインノートブック
次のノートブックでは、この記事の情報を実装して非構造化データ パイプラインを作成する方法を示します。
Databricks の非構造化データ パイプライン
データ パイプラインの主要なコンポーネント
非構造化データを含む RAG アプリケーションの基盤は、データ パイプラインです。 このパイプラインは、RAG アプリケーションが効果的に使用できる形式で非構造化データをキュレーションおよび準備する役割を担います。

このデータ パイプラインはユース ケースによっては複雑になることがありますが、最初に RAG アプリケーションをビルドするときに考慮する必要がある主要なコンポーネントを次に示します。
- コーパスの構成とインジェスト: 特定のユース ケースに基づいて、適切なデータ ソースとコンテンツを選択します。
- データの前処理: 生データを埋め込みと取得に適したクリーンで一貫性のある形式に変換します。
- チャンク: 解析されたデータをより小さく管理しやすいチャンクに分割し、効率的に取得します。
- 埋め込み: チャンクされたテキスト データを、そのセマンティックな意味をキャプチャする数値ベクター表現に変換します。
- インデックス作成とストレージ: 効率的なベクター インデックスを作成して、検索のパフォーマンスを最適化します。
コーパスの構成と取り込み
RAG アプリケーションは、適切なデータ コーパスなしでユーザー クエリに応答するために必要な情報を取得できません。 正しいデータは、アプリケーションの特定の要件と目標に完全に依存するため、使用可能なデータの微妙な違いを理解するために時間を使う必要があります。 詳細については、 Generative AI アプリの開発者ワークフローに関する記事を参照してください。
たとえば、カスタマー サポート ボットを構築する場合は、次の点を考慮する必要があります。
- ナレッジ ベース ドキュメント
- よく寄せられる質問 (FAQ)
- 製品マニュアルと仕様
- トラブルシューティング ガイド
プロジェクトの最初からドメインの専門家や利害関係者と連携して、データ コーパスの品質とカバレッジを向上させる可能性のある関連コンテンツを特定してキュレーションします。 ユーザーが送信する可能性が高いクエリの種類に関する分析情報を提供し、含める最も重要な情報に優先順位を付けることができます。
Databricks では、スケーラブルで増分的な方法でデータを取り込うことをお勧めします。 Azure Databricks には、SaaS アプリケーション用のフル マネージド コネクタや API 統合など、データ インジェストのさまざまな方法が用意されています。 ベスト プラクティスとして、生のソース データを取り込んでターゲット テーブルに格納する必要があります。 このアプローチにより、データの保持、追跡可能性、監査が保証されます。 Lakeflow Connect の標準コネクタを参照してください。
データの前処理
データが取り込まれた後は、生データをクリーンアップして、埋め込みと取得に適した一貫性のある形式に書式設定することが不可欠です。
パージング
取得元アプリケーションに適したデータ ソースを特定した後、次の手順では生データから必要な情報を抽出します。 解析と呼ばれるこのプロセスでは、非構造化データを RAG アプリケーションで効果的に使用できる形式に変換します。
解析手法とツールに何を使用するかは、扱うデータの種類によって異なります。 次に例を示します。
- テキスト ドキュメント (PDF、Word ドキュメント):非構造化と PyPDF2 などの既製のライブラリは、さまざまなファイル形式を処理し、解析プロセスをカスタマイズするための選択肢を提供できます。
- HTML ドキュメント:BeautifulSoup や lxml などの HTML 解析ライブラリを使用して、Web ページから関連するコンテンツを抽出できます。 これらのライブラリは、HTML 構造のナビゲート、特定の要素の選択、目的のテキストまたは属性の抽出に役立ちます。
- 画像とスキャンされたドキュメント: 光学式文字認識 (OCR) 手法は、通常、画像からテキストを抽出するために必要です。 一般的な OCR ライブラリには、 Tesseract などのオープン ソース ライブラリや 、Amazon Textract、 Azure AI Vision OCR、 Google Cloud Vision API などの SaaS バージョンが含まれます。
データ解析のベスト プラクティス
解析により、データがクリーンで構造化され、生成とベクター検索を埋め込む準備が整います。 データを解析するときは、次のベスト プラクティスを検討してください。
- データのクリーニング: 抽出されたテキストを前処理して、ヘッダー、フッター、特殊文字などの無関係な情報やノイズの多い情報を削除します。 RAG チェーンで処理する必要がある不要な情報や形式が正しくない情報の量を減らします。
- エラーと例外の処理: 解析プロセス中に発生した問題を特定して解決するために、エラー処理とログ記録のための手段を実装します。 これにより、問題をすばやく特定して修正できます。 これを行うと、多くの場合に、ソース データの品質に関するアップストリームの問題が指摘されます。
- 解析ロジックのカスタマイズ: データの構造と形式によっては、解析ロジックをカスタマイズして、最も関連性の高い情報を抽出する必要がある場合があります。 追加の作業が事前に必要になる場合はありますが、多くのダウンストリーム品質の問題を防ぐことが多いため、必要に応じてこれを行うために時間を費やしてください。
- 解析品質の評価: 出力のサンプルを手動で確認することで、解析されたデータの品質を定期的に評価します。 これは、解析プロセスの改善に関する問題や領域を特定するのに役立ちます。
濃縮
追加のメタデータを使用してデータを強化し、ノイズを除去します。 エンリッチメントは省略可能ですが、アプリケーションの全体的なパフォーマンスを大幅に向上させることができます。
メタデータの抽出
ドキュメントのコンテンツ、コンテキスト、構造に関する重要な情報をキャプチャするメタデータを生成および抽出することで、RAG アプリケーションの取得品質とパフォーマンスを大幅に向上させることができます。 メタデータは、関連性を向上させ、高度なフィルター処理を有効にし、ドメイン固有の検索要件をサポートする追加のシグナルを提供します。
LangChain や LlamaIndex などのライブラリには、関連する標準メタデータを自動的に抽出できる組み込みのパーサーが用意されていますが、多くの場合、特定のユース ケースに合わせて調整されたカスタム メタデータでこれを補完すると便利です。 この方法により、重要なドメイン固有の情報が確実にキャプチャされ、ダウンストリームの取得と生成が向上します。 大規模な言語モデル (LLM) を使用して、メタデータの強化を自動化することもできます。
メタデータの種類は次のとおりです。
- ドキュメント レベルのメタデータ: ファイル名、URL、作成者情報、作成と変更のタイムスタンプ、GPS 座標、ドキュメントのバージョン管理。
- コンテンツ ベースのメタデータ: 抽出されたキーワード、概要、トピック、名前付きエンティティ、ドメイン固有のタグ (PII や HIPAA などの製品名とカテゴリ)。
- 構造メタデータ: セクション ヘッダー、目次、ページ番号、セマンティック コンテンツの境界 (章またはサブセクション)。
- コンテキスト メタデータ: ソース システム、インジェストの日付、データの秘密度レベル、元の言語、または国境を越えた命令。
最適なパフォーマンスを実現するためには、メタデータをチャンクされたドキュメントや対応する埋め込みと共に格納することが不可欠です。 また、取得した情報を絞り込み、アプリケーションの精度とスケーラビリティを向上させることもできます。 さらに、メタデータをハイブリッド検索パイプラインに統合することは、ベクトル類似性検索とキーワードベースのフィルター処理を組み合わせることを意味し、特に大規模なデータセットや特定の検索条件のシナリオで関連性を高めることができます。
重複排除
ソースによっては、ドキュメントが重複したり、ほぼ重複したりする場合があります。 たとえば、1 つ以上の共有ドライブからプルする場合、同じドキュメントの複数のコピーが複数の場所に存在する可能性があります。 これらのコピーの中には、微妙な変更を加えるものもあります。 同様に、ナレッジ ベースには、製品ドキュメントのコピーやブログ投稿の下書きコピーが含まれる場合があります。 これらの重複がコーパスに残っている場合は、最終的なインデックスに冗長性の高いチャンクが含まれる可能性があります。これにより、アプリケーションのパフォーマンスが低下する可能性があります。
メタデータのみを使用して重複を排除できます。 たとえば、アイテムのタイトルと作成日が同じでも、ソースや場所が異なる複数のエントリがある場合は、メタデータに基づいてフィルター処理できます。
ただし、これでは不十分な場合があります。 ドキュメントの内容に基づいて重複を特定して排除するために、ローカリティに依存するハッシュと呼ばれる手法を使用できます。 具体的には、 ここでは MinHash と呼ばれる手法が適切に機能し、Spark の実装は Spark ML で既に使用できます。 含まれている単語に基づいてドキュメントのハッシュを作成することで機能し、それらのハッシュで結合することで、重複またはほぼ重複を効率的に識別できます。 非常に高いレベルでは、これは 4 段階のプロセスです。
- 各ドキュメントの特徴ベクトルを作成します。 必要に応じて、単語の削除の停止、ステミング、レンマ化などの手法を適用して結果を改善し、n グラムにトークン化することを検討してください。
- MinHash モデルを適合させ、 ジャカール距離に MinHash を使用してベクトルをハッシュします。
- これらのハッシュを使用して類似性結合を実行し、重複するドキュメントまたはほぼ重複するドキュメントごとに結果セットを生成します。
- 保持したくない重複を除外します。
ベースライン重複除去の手順では、任意に保持するドキュメントを選択できます (各重複の結果の最初のドキュメントや、重複のランダムな選択など)。 他のロジック (最新の更新、パブリケーションの状態、最も権限のあるソースなど) を使用して、重複の "最適な" バージョンを選択することが改善される可能性があります。 また、一致する結果を改善するために、特徴付け手順と MinHash モデルで使用されるハッシュ テーブルの数を試す必要がある場合があることに注意してください。
詳細については、 ローカル性に依存するハッシュの Spark ドキュメントを参照してください。
フィルタリング
コーパスに取り込むドキュメントの中には、エージェントの目的とは無関係であるか、古すぎるか信頼性が低すぎるか、有害な言語などの問題のあるコンテンツが含まれているため、エージェントにとって役に立たないものもあります。 ただし、他のドキュメントには、エージェントを介して公開したくない機密情報が含まれている場合があります。
そのため、パイプラインに、フィルターとして使用できる予測を生成する毒性分類子をドキュメントに適用するなど、メタデータを使用してこれらのドキュメントをフィルター処理するステップを含める必要があります。 もう 1 つの例は、ドキュメントをフィルター処理するために、個人を特定できる情報 (PII) 検出アルゴリズムをドキュメントに適用することです。
最後に、エージェントにフィードするドキュメント ソースは、不適切なアクターがデータポイズニング攻撃を開始するための潜在的な攻撃ベクトルです。 検出とフィルター処理のメカニズムを追加して、それらを識別して排除することを検討することもできます。
チャンキング

生データをより構造化された形式に解析し、重複を削除し、不要な情報を除外した後、次の手順では、チャンクと呼ばれるより小さい管理可能な単位に分割します。 大きなドキュメントをセマンティックに集中した小さなチャンクに分割することで、取得したデータが LLM のコンテキストに収まり、煩わしい情報や無関係な情報が最小限に抑えられます。 チャンクの選択は、LLM が提供する取得されたデータに直接影響し、RAG アプリケーションの最適化の最初のレイヤーの 1 つになります。
データをチャンクに分割するときは、次の要因を考慮してください。
- チャンク戦略: 元のテキストをチャンクに分割するために使用する方法。 これには、文による分割、段落、特定の文字/トークン数、より高度なドキュメント固有の分割戦略などの基本的な手法が含まれる場合があります。
- チャンク サイズ: チャンクを小さくすると、特定の詳細に集中できますが、周囲のコンテキスト情報が失われる可能性があります。 チャンクが大きくなると、より多くのコンテキストがキャプチャされる可能性がありますが、無関係な情報が含まれる場合や、計算コストが高くなる可能性があります。
- チャンク間の重複: データのチャンクへの分割時に重要な情報が失われないようにするには、隣接するチャンク間に多少の重複を含めることを検討してください。 重複すると、チャンク間での継続性とコンテキストの保持が確保され、取得結果が向上します。
- セマンティック コヒーレンス: 可能であれば、関連する情報を含む意味的にコヒーレントなチャンクを作成することを目指しますが、意味のあるテキストの単位として独立して立つことができます。 これは、段落、セクション、トピックの境界など、元のデータの構造を考慮することで実現できます。
- メタデータ:ソース ドキュメント名、セクション見出し、製品名などの関連するメタデータを使用すると、取得を改善できます。 この追加情報は、取得クエリをチャンクと照合するのに役立ちます。
データのチャンクへの分割戦略
適切なチャンク方法を見つけることは、反復的でコンテキストに依存します。 万能アプローチはありません。 最適なチャンク サイズと方法は、特定のユース ケースと、処理されるデータの性質によって異なります。 大まかに言えば、チャンク戦略は次のように捉えることができます。
- 固定サイズのチャンク分割: 固定の文字数やトークン数 (たとえば、LangChain CharacterTextSplitter) などの前もって定めたサイズのチャンクにテキストを分割します。 任意の数の文字またはトークンで分割する方法は、すばやく簡単に設定できますが、一般にこの方法は、意味的に一貫性を持つチャンクに分割される結果にはなりません。 このアプローチは、運用環境レベルのアプリケーションではめったに機能しません。
- 段落ベースのチャンク分割: テキスト内の自然な段落境界を使用して、チャンクを定義します。 このメソッドは、多くの場合、段落に関連情報 ( LangChain RecursiveCharacterTextSplitter など) が含まれるため、チャンクのセマンティック コヒーレンスを維持するのに役立ちます。
- 形式固有のチャンク: Markdown や HTML などの形式には、チャンク境界 (マークダウン ヘッダーなど) を定義できる固有の構造があります。 この目的には、LangChain の MarkdownHeaderTextSplitter や HTML ヘッダー/section ベースのスプリッターなどのツールを使用できます。
- セマンティック チャンク: トピック モデリングなどの手法を適用して、テキスト内のセマンティックコヒーレント セクションを識別できます。 これらのアプローチでは、各ドキュメントのコンテンツまたは構造を分析し、トピックのシフトに基づいて最も適切なチャンク境界を決定します。 セマンティック チャンクは、基本的なアプローチよりも複雑ですが、テキスト内の自然なセマンティック分割に合わせたチャンクを作成するのに役立ちます (例: LangChain SemanticChunker を参照)。
例: 固定サイズのチャンク分割

LangChain の RecursiveCharacterTextSplitter を使用し、chunk_size=100 と chunk_overlap=20 でテキストを固定サイズに分割する例。 ChunkViz は、Langchain の文字スプリッターを使用して、さまざまなチャンク サイズとチャンクの重複値が結果のチャンクに与える影響を視覚化する対話型の方法を提供します。
埋め込み
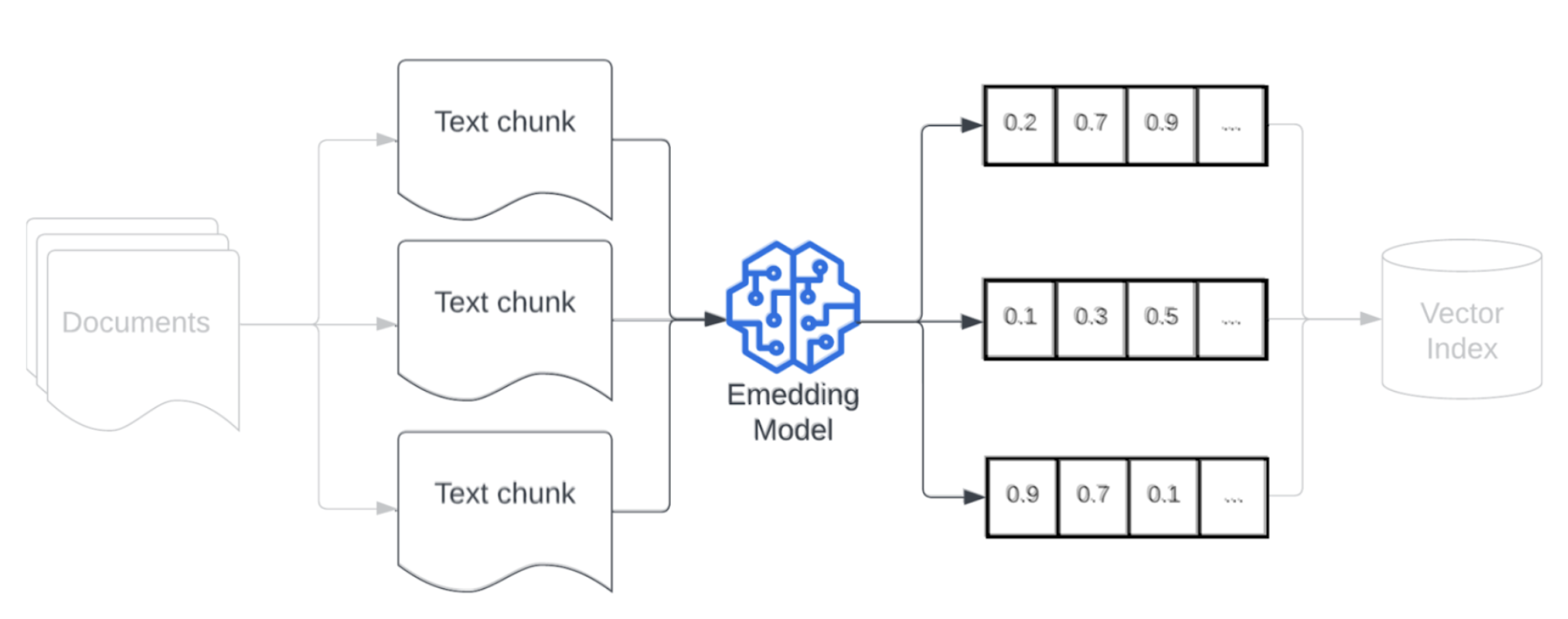
データをチャンクに分割した後は、次の手順は、埋め込みモデルを使用してテキスト チャンクをベクター表現に変換することです。 埋め込みモデルは、各テキスト チャンクをセマンティックな意味をキャプチャするベクター表現に変換します。 チャンクを密ベクトルとして表すことで、埋め込みでは、取得クエリとのセマンティック類似性に基づいて、最も関連性の高いチャンクをすばやく正確に取得できます。 取得クエリは、データ パイプラインにチャンクを埋め込むために使用されるのと同じ埋め込みモデルを使用して、クエリ時に変換されます。
埋め込みモデルを選択するときは、次の要因を考慮してください。
- モデルの選択: 各埋め込みモデルには微妙な違いがあり、使用可能なベンチマークによってデータの特定の特性がキャプチャされない場合があります。 同様のデータに対してトレーニングされたモデルを選択することが重要です。 また、特定のタスク用に設計された使用可能な埋め込みモデルを調べるのも有益な場合があります。 既製の埋め込みモデルは、MTEB などの標準ランキングでランクが低いものであっても、さまざまなモデルを試します。 考慮すべき例をいくつか次に示します。
- 最大トークン数: 選択した埋め込みモデルの最大トークン制限を把握します。 この制限を超えるチャンクを渡すと、超えた分は切り捨てられ、重要な情報が失われる可能性があります。 たとえば、bge-large-en-v1.5 の最大トークン制限は 512 個です。
- モデル サイズ: 一般に、埋め込みモデルが大きいほどパフォーマンスは向上しますが、より多くの計算リソースが必要です。 特定のユース ケースと使用可能なリソースに基づいて、パフォーマンスと効率のバランスを取る必要があります。
- 微調整: RAG アプリケーションがドメイン固有の言語 (社内の頭字語や用語など) を扱う場合は、ドメイン固有のデータに対して埋め込みモデルを微調整することを検討してください。 これは、モデルが特定のドメインの微妙な部分や用語をより適切に把握するのに役立ち、多くの場合、取得パフォーマンスが向上する可能性があります。
インデックス作成とストレージ
パイプラインの次の手順では、埋め込みと前の手順で生成されたメタデータにインデックスを作成します。 この段階では、高速で正確な類似性検索を可能にする効率的なデータ構造に高次元ベクター埋め込みを整理します。
モザイク AI ベクター検索では、ベクター検索エンドポイントとインデックスをデプロイするときに最新のインデックス作成手法を使用して、ベクター検索クエリの迅速かつ効率的な検索を実現します。 最適なインデックス作成手法のテストと選択について心配する必要はありません。
インデックスを構築してデプロイすると、スケーラブルで待ち時間の短いクエリをサポートするシステムに格納する準備が整います。 大規模なデータセットを含む運用 RAG パイプラインの場合は、ベクター データベースまたはスケーラブルな検索サービスを使用して、低待機時間と高スループットを確保します。 追加のメタデータを埋め込みと共に格納して、取得時の効率的なフィルター処理を可能にします。