レイクハウスの基本原則
基本原則は、アーキテクチャを定義して影響を与えるレベル 0 のルールです。 現在および将来のビジネスの成功に役立つデータ レイクハウスを構築するには、組織内の利害関係者間のコンセンサスが重要です。
データをキュレーションし、信頼できる製品としてのデータを提供する
データのキュレーションは、BI と ML/AI の価値の高いデータ レイクを作成するために不可欠です。 明確な定義、スキーマ、ライフサイクルを使用して、データを製品のように扱います。 ビジネス ユーザーがデータを完全に信頼できるように、セマンティック整合性を確保し、データ品質をレイヤー間で向上させます。
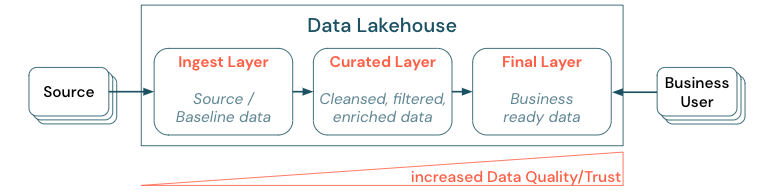
階層構造 (またはマルチホップ) アーキテクチャを確立してデータをキュレーションすることは、データ チームが品質レベルに従ってデータを構造化し、レイヤーごとの役割と責任を定義できるため、レイクハウスにとって重要なベスト プラクティスです。 一般的な階層型アプローチは次のとおりです。
- インジェスト レイヤー: ソース データはレイクハウスの最初のレイヤーに取り込まれ、そこで永続化します。 すべてのダウンストリーム データがインジェスト レイヤーから作成されていれば、必要に応じて、このレイヤーから後続のレイヤーを再構築できます。
- キュレーション レイヤー: 2 番目のレイヤーの目的は、クレンジング、精製、フィルター処理、集計されたデータを保持することです。 このレイヤーの目的は、役割と機能の全体について、分析とレポートのための正当で信頼性の高い基盤を提供することです。
- 最終レイヤー: 3 番目のレイヤーは、ビジネスやプロジェクトのニーズを中心に作成されます。データ製品としての他の事業単位やプロジェクトへの別のビューの提供、セキュリティのニーズに合わせたデータの準備 (匿名化されたデータなど)、(事前集計済みのビューで) パフォーマンスの最適化を行います。 このレイヤーのデータ製品は、ビジネスにとっての事実と見なされます。
すべてのレイヤーのパイプラインでは、データ品質の制約が満たされていることを確認する必要があります。つまり、同時の読み取りと書き込みの間も、データは常に正確、完全、アクセス可能で、一貫性があります。 新しいデータの検証は、キュレーションされたレイヤーへのデータ入力時に行われ、次の ETL の手順でこのデータの品質が向上します。 データの品質は、データがレイヤーを介して進行するにつれて向上する必要があります。その結果、ビジネスの観点からデータへの信頼が高まります。
データ サイロを排除し、データ移動を最小限に抑える
ビジネス プロセスがその異なるコピーに依存しているデータセットはコピーしないでください。 コピーはデータ サイロになり、同期が取れなくなり、データ レイクの品質が低下し、最終的に古い分析情報や不正な分析情報になるおそれがあります。 また、外部パートナーとのデータの共有には、セキュリティで保護された方法でデータに直接アクセスできるエンタープライズ共有メカニズムを使用します。
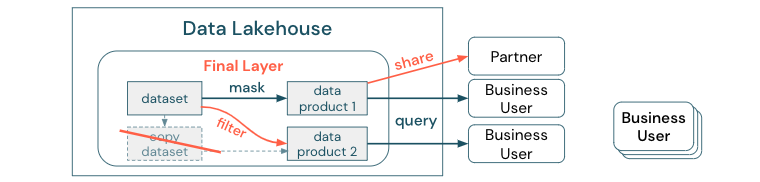
データ コピーとデータ サイロの違いを明らかにするため: データのスタンドアロンまたは使い捨てのコピーは単独では害を及ぼすものではありません。 機敏性、実験、イノベーションを促進するために必要な場合があります。 ただし、これらのコピーが、これらに依存するダウンストリーム ビジネス データ製品で動作するようになると、データ サイロになります。
データ サイロを防ぐために、データ チームは通常、すべてのコピーをオリジナルと同期させるメカニズムまたはデータ パイプラインを構築しようとします。 これが一貫して発生する可能性は低いため、データ品質は最終的に低下します。 これにより、コストが高くなり、ユーザーの信頼が大幅に失われるおそれもあります。 一方、一部のビジネス ユース ケースでは、パートナーやサプライヤーとのデータの共有が必要です。
重要な側面は、データセットの最新バージョンを安全かつ確実に共有することです。 多くの場合、データセットのコピーでは十分ではありません。すぐに同期しなくなる場合があるためです。 代わりに、エンタープライズ データ共有ツールを使用してデータを共有する必要があります。
セルフサービスによる価値創造の民主化
ユーザーが BI および ML/AI タスクのプラットフォームまたはデータに簡単にアクセスできない場合、最適なデータ レイクは十分な価値を提供できません。 すべての事業単位向けにデータとプラットフォームへのアクセスの障壁を下げます。 無駄のないデータ管理プロセスを検討し、プラットフォームと基になるデータにセルフサービス アクセスを提供します。
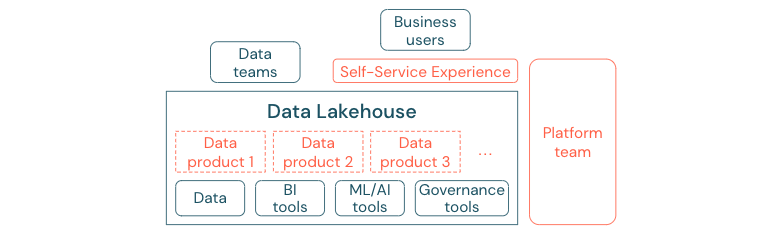
データ ドリブン カルチャに正常に移行した企業は成長します。 つまり、すべての事業単位は、分析モデル、または独自のデータか一元的に提供されたデータを分析して決定を導き出します。 コンシューマーの場合、データは簡単に検出でき、安全にアクセスできる必要があります。
データ プロデューサーの良い概念は、"製品としてのデータ" です。データは、1 つの事業単位またはビジネス パートナー (製品など) によって提供および管理され、適切なアクセス許可制御を持つ他の関係者によって使用されます。 これらのデータ製品は、中央のチームや低速になり得る要求プロセスに依存せずに、セルフサービス エクスペリエンスで作成、提供、検出、使用する必要があります。
ただし、重要なのはデータだけではありません。 データの民主化には、すべてのユーザーがデータを生成または使用して理解できるようにするための適切なツールが必要です。 このためには、データ レイクハウスが、別のツール スタックを設定する手間を重ねることなく、データ製品を構築するためのインフラストラクチャとツールを提供する最新のデータと AI プラットフォームである必要があります。
組織全体のデータ ガバナンス戦略を採用する
データは組織にとって重要な資産ですが、すべてのユーザーにすべてのデータへのアクセス権を付与することはできません。 データ アクセスを積極的に管理する必要があります。 アクセス制御、監査、系列追跡は、データを正しく安全に使用するための鍵です。
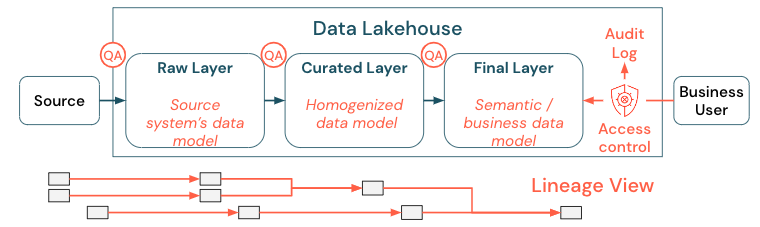
データ ガバナンスは広範なトピックです。 レイクハウスは次の側面を対象とします。
データ品質
正しく意味のあるレポート、分析結果、モデルの最も重要な前提条件は、高品質のデータです。 すべてのパイプライン ステップの周りに品質保証 (QA) が存在する必要があります。 これを実装する方法の例としては、データ コントラクトの用意、SLA への準拠、スキーマの安定性の維持、それらの制御された方法での進化などがあります。
データ カタログ
もう 1 つの重要な側面は、データ検出です。特にセルフサービス モデルでは、すべてのビジネス分野のユーザーが、関連するデータを簡単に検出できる必要があります。 そのため、レイクハウスには、ビジネスに関連するすべてのデータをカバーするデータ カタログが必要です。 データ カタログの主な目標は次のとおりです。
- 同じビジネス概念が一様に呼び出され、ビジネス全体で宣言されていることを確認します。 それを、キュレーションされた最終レイヤーにおけるセマンティック モデルと考えられるかもしれません。
- データ系列を正確に追跡して、これらのデータが現在の形態にどのように至ったかをユーザーが説明できるようにします。
- データの適切な使用のために、データ自体と同じくらい重要な高品質のメタデータを維持します。
アクセス制御
レイクハウス内のデータからの価値創造はすべてのビジネス分野で行われるため、レイクハウスはセキュリティを備えた第一級オブジェクトとして構築する必要があります。 企業は、よりオープンなデータ アクセス ポリシーを持っているか、最小限の特権の原則に厳密に従っている可能性があります。 それとは別に、データ アクセス制御は、すべてのレイヤーに配置する必要があります。 最初から細かいレベルのアクセス許可スキーム (列および行レベルのアクセス制御、ロールベースまたは属性ベースのアクセス制御) を実装することが重要です。 企業は、それほど厳しくない規則から始めることができる。 しかし、レイクハウス プラットフォームが成長するにつれて、より高度なセキュリティ体制のためのすべてのメカニズムとプロセスが既に整備されているはずです。 さらに、レイクハウス内のデータへのすべてのアクセスは、初めから監査ログによって管理される必要があります。
オープン インターフェイスとオープン形式を推奨する
オープン インターフェイスおよびデータ形式は、レイクハウスと他のツールの相互運用性に不可欠です。 これにより、既存のシステムとの統合が簡素化され、ツールをプラットフォームと統合したパートナーのエコシステムも開かれます。
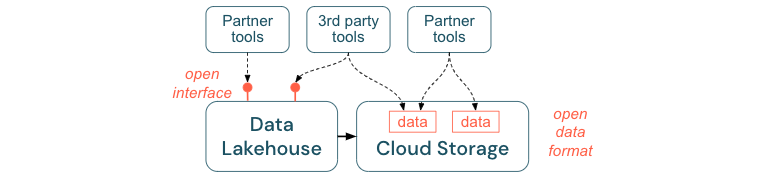
オープン インターフェイスは、相互運用性を有効にし、単一のベンダーへの依存関係を防ぐために不可欠です。 従来、ベンダーは独自のテクノロジーとクローズド インターフェイスを構築し、企業がデータを保存、処理、共有する方法を制限していました。
オープン インターフェイスを基に構築すると、次の点で将来のビルドに役立ちます。
- データの寿命と移植性が向上するため、より多くのアプリケーションやより多くのユース ケースで使用できます。
- オープン インターフェイスを迅速に活用してツールをレイクハウス プラットフォームに統合できるパートナーのエコシステムが開かれます。
最後に、データのオープン形式を標準化すると、総コストが大幅に削減されます。クラウド ストレージ上のデータに直接アクセスでき、高いエグレスおよび評価コストが発生するおそれがある独自のプラットフォームを介してパイプ処理する必要はありません。
パフォーマンスとコストに対しスケーリングおよび最適化するように構築する
データは必然的に増加し続け、複雑になります。 将来のニーズに合わせて組織を装備するには、レイクハウスをスケーリングできる必要があります。 たとえば、必要に応じて新しいリソースを簡単に追加できる必要があります。 コストは実際の消費量に限定する必要があります。
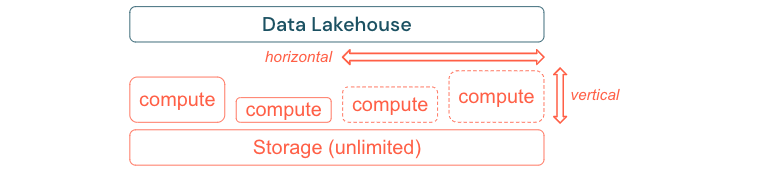
多くの場合、標準の ETL プロセス、ビジネス レポート、ダッシュボードには、メモリと評価の分析観点で予測可能なリソースのニーズがあります。 ただし、新しいプロジェクト、季節的なタスク、またはモデル トレーニング (チャーン、予測、メンテナンス) などの最新のアプローチにより、リソース ニーズのピークが生まれます。 企業がこれらすべてのワークロードを実行できるようにするには、メモリと評価用のスケーラブルなプラットフォームが必要です。 新しいリソースは必要に応じて簡単に追加する必要があり、実際の消費量のみによりコストが生じる必要があります。 ピークを過ぎたらすぐにリソースが再び解放され、それに応じてコストも削減できます。 多くの場合、これは水平スケーリング (ノードの数が少ないまたは多い) と、垂直スケーリング (ノードがより大きいまたは小さい) と呼ばれます。
また、スケーリングを使用すると、より多くのリソースを持つノード、またはより多くのノードを持つクラスターを選択することで、クエリのパフォーマンスを向上させることもできます。 ただし、大規模なマシンとクラスターを永続的に提供する代わりに、全体的なパフォーマンスとコストの比率を最適化するために必要な時間だけオンデマンドでプロビジョニングできます。 最適化のもう 1 つの側面は、ストレージとコンピューティング リソースです。 データの量とこのデータを使用するワークロードの間には明確な関係がない (たとえば、データの一部のみを使用したり、小さなデータに対して集中的な計算を行ったりすることがある) ため、ストレージとコンピューティング リソースを分離するインフラストラクチャ プラットフォームに決めることをお勧めします。