データ レイクハウスの信頼性
信頼性の柱のアーキテクチャ原則は、システムが障害から回復して機能を継続する能力に対応します。
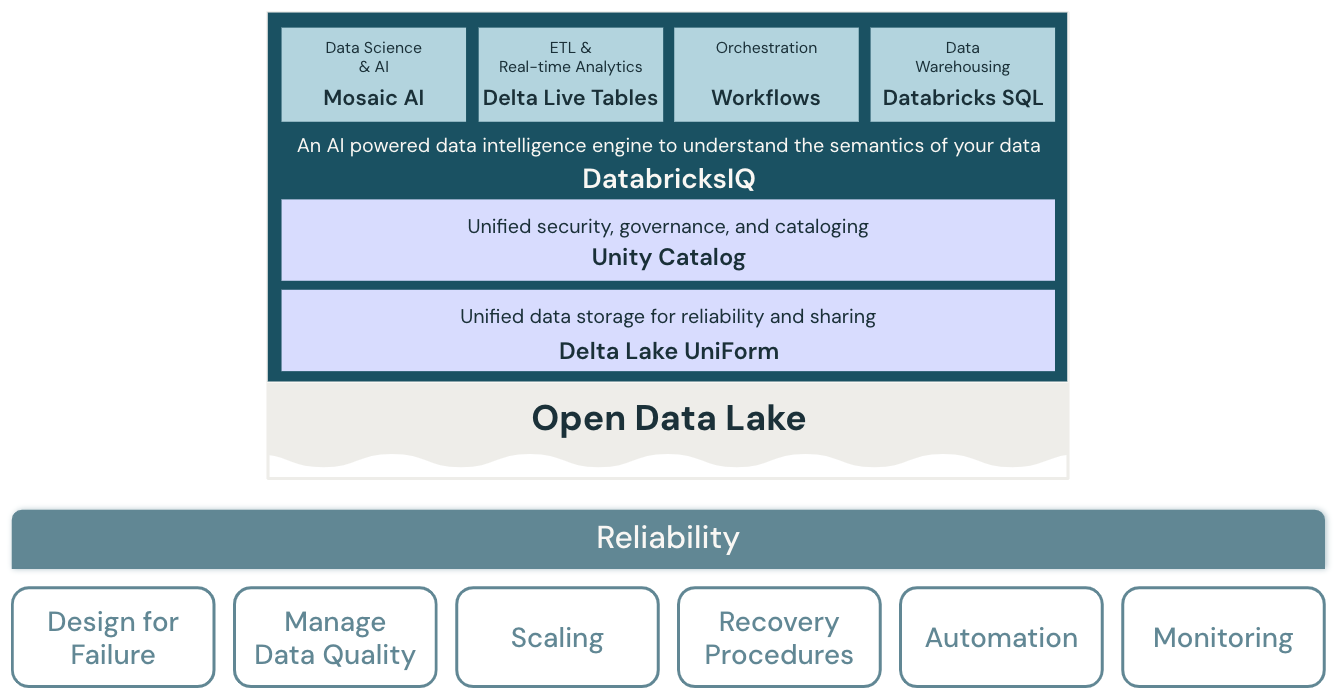
信頼性の原則
障害に備えた設計
高度に分散された環境でも停止が発生する可能性があります。 プラットフォームとさまざまなワークロード (ストリーミング ジョブ、バッチ ジョブ、モデル トレーニング、BI クエリなど) の両方について、障害を予測する必要があります。また、信頼性を高めるために回復性の高いソリューションを開発する必要があります。 焦点は、迅速に、またできれば自動的に回復するようにアプリケーションを設計することです。
データ品質を管理する
データ品質は、データから正確で意味のある分析情報を引き出すための基礎です。 データ品質には、完全性、正確性、有効性、整合性など、さまざまな側面があります。 ビジネス ユーザーにとってデータが信頼できる情報として機能するように、最終的なデータ セットの品質を向上させるために積極的に管理する必要があります。
自動スケーリングを設計する
多くの場合、標準の ETL プロセス、ビジネス レポート、ダッシュボードには、メモリとコンピューティングの点で予測可能なリソース要件があります。 ただし、新しいプロジェクト、季節的なタスク、またはモデル トレーニング (チャーン、予測、メンテナンス) などの高度なアプローチによって、リソース要件は急増します。 組織がこれらすべてのワークロードを処理するには、スケーラブルなストレージとコンピューティング プラットフォームが必要です。 必要に応じて簡単に新しいリソースを追加できるようにする必要があります。また、実際の使用量に対してのみ課金されるようにします。 ピークを過ぎるとリソースが解放され、それに応じてコストを削減することができます。 これは、よく水平スケーリング (ノード数)、垂直スケーリング (ノードのサイズ) とも呼ばれます。
復旧手順をテストする
ほとんどのアプリケーションとシステムに対する企業全体のディザスター リカバリー戦略には、優先順位、機能、制限、コストの評価が必要です。 信頼性の高いディザスター リカバリー アプローチでは、ワークロードがどのように失敗するかを定期的にテストし、復旧手順を検証します。 自動化を使うと、さまざまな障害をシミュレートすることや、過去に障害を引き起こしたシナリオを再現することができます。
デプロイとワークロードを自動化する
レイクハウスのデプロイとワークロードを自動化することで、これらのプロセスを標準化し、人為的ミスをなくし、生産性を向上させ、再現性を高めることができます。 これには、構成のずれを回避するための "コードとしての構成" と、必要なすべてのレイクハウスおよびクラウド サービスのプロビジョニングを自動化するための "コードとしてのインフラストラクチャ" の使用が含まれます。
監視、アラート、ログを設定する
レイクハウスのワークロードは、通常、Databricks プラットフォーム サービスと外部クラウド サービス (例えばデータ ソースやターゲットとして) を統合します。 正常な実行は、実行チェーン内の各サービスが正常に機能している場合にのみ発生します。 そうでない場合は、問題を検出して追跡し、システムの動作を理解するために、監視、アラート、ログ記録が重要です。
次: 信頼性のためのベスト プラクティス
「信頼性のためのベスト プラクティス」を参照してください。