独自の LLM エンドポイント ベンチマークの実施
この記事では、LLM エンドポイントをベンチマークするための Databricks 推奨ノートブックの例を示します。 また、Databricks が LLM 推論を実行し、エンドポイントのパフォーマンス メトリックとして待機時間とスループットを計算する方法についても簡単に説明します。
Databricks の LLM 推論により、Foundation Model API のプロビジョニング済みスループット モードの 1 秒あたりのトークン数が測定されます。 「プロビジョニング スループットにおける 1 秒あたりのトークンの範囲は何を意味しますか?」をご覧ください。
ベンチマークのノートブックの例
次のノートブックを Databricks 環境にインポートし、ロード テストを実行する LLM エンドポイントの名前を指定できます。
LLM エンドポイントのベンチマーク
LLM 推論の概要
LLM は、次の 2 段階のプロセスで推論を実行します。
- プレフィルは、入力プロンプトのトークンが並列で処理されます。
- デコードは、テキストが自己回帰の方法で一度に 1 つのトークンが生成されます。 生成された各トークンが入力に追加され、モデルにフィードバックされて次のトークンが生成されます。 LLM が特別な停止トークンを出力するか、またはユーザー定義の条件が満たされると、生成が停止します。
ほとんどの運用アプリケーションには待機時間の予算があり、Databricks では、待機時間の予算を考慮してスループットを最大化することをお勧めします。
- 入力トークンの数は、要求を処理するために必要なメモリに大きな影響を与えます。
- 出力トークンの数は、全体的な応答待機時間に影響を及ぼします。
Databricks では、LLM 推論が次のサブメトリックに分割されます。
- 最初のトークンまでの時間 (TTFT): これは、ユーザーがクエリを入力した後、モデルの出力の表示が始まる速度です。 リアルタイムの対話では、応答の待機時間が短いことが不可欠ですが、オフライン ワークロードでは重要度が低くなります。 このメトリックは、プロンプトを処理し、最初の出力トークンを生成するために必要な時間によって駆動されます。
- 出力トークンあたりの時間 (TPOT): システムに対してクエリを実行している各ユーザーの出力トークンを生成する時間。 このメトリックは、各ユーザーがモデルの "速度" を認識する方法に対応します。 たとえば、トークンあたり 100 ミリ秒の TPOT は、1 秒あたり 10 トークン、つまり 1 分あたり最大 450 ワードに相当し、これは一般的な人が読み取るよりも高速です。
これらのメトリックに基づいて、合計待機時間とスループットを次のように定義できます。
- 待機時間 = TTFT + (TPOT) * (生成されるトークンの数)
- スループット = すべてのコンカレンシー要求にわたる 1 秒あたりの出力トークンの数
Databricks では、LLM サービス エンドポイントは、複数の同時要求を持つクライアントによって送信された負荷に合わせてスケーリングできます。 待機時間とスループットにはトレードオフがあります。 これは、エンドポイントを提供する LLM では、同時要求の可能性があり、同時に処理されるためです。 同時要求の負荷が低い場合、待機時間は可能な限り低くなります。 ただし、要求の負荷を増やすと待機時間が長くなる場合がありますが、スループットも上がる可能性があります。 これは、1 秒間に 2 つのトークンに相当する要求を 2 倍未満の時間で処理できるためです。
そのため、待機時間とスループットのバランスを取るために、システムへの並列要求の数を制御することが重要です。 待機時間の短いユース ケースがある場合は、待機時間を短く保つために、同時要求をエンドポイントに送信する数を減らしたいことがあります。 スループットのユース ケースが高い場合は、待機時間を犠牲にしても高いスループットは価値があるため、多くのコンカレンシー要求でエンドポイントを飽和させたい場合があります。
Databricks ベンチマーク ハーネス
以前共有したベンチマークのノートブックの例は、Databricks のベンチマーク ハーネスです。 ノートブックには、待機時間とスループットのメトリックが表示され、さまざまな並列要求の数にわたるスループットと待機時間の曲線がプロットされます。 Databricks エンドポイントの自動スケーリングは、待機時間とスループットの間の "バランスの取れた" 戦略に基づいています。 ノートブックでは、より多くの同時実行ユーザーが同時にエンドポイントに対してクエリを実行すると、待機時間が増加し、スループットも上がっていることがわかります。
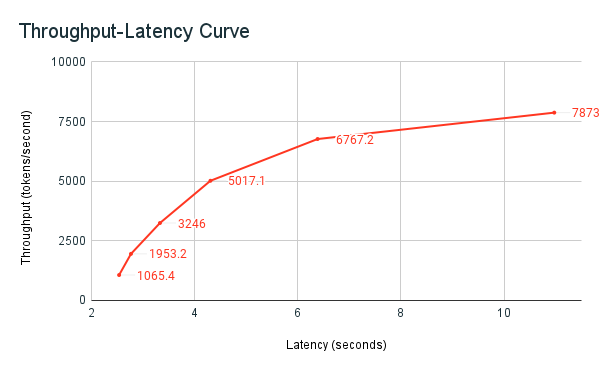
LLM パフォーマンス ベンチマークに関する Databricks の哲学の詳細については、「LLM 推論パフォーマンス エンジニアリング: ベスト プラクティスのブログ」に説明されています。