入力ウィジェットを使用すると、ノートブックとダッシュボードにパラメーターを追加できます。 Databricks UI またはウィジェット API を使用して、ウィジェットを追加できます。 ウィジェットを追加または編集するには、"編集可能" アクセス許可をノートブックに対して持っている必要があります。
Databricks Runtime 11.3 LTS またはそれ以上を実行している場合は、Databricks ノートブックで ipywidgets を使用することもできます。
Databricks ウィジェットは、次の場合に最適です。
- 異なるパラメーターを使用して再実行されるノートブックまたはダッシュボードの構築。
- パラメーターが異なる 1 つのクエリの結果に対するすばやい探索。
Scala、Python、または R でウィジェット API のドキュメントを表示するには、次のコマンドを使用します: dbutils.widgets.help()。 また、 widgets ユーティリティ (dbutils.widgets) のドキュメントを参照することもできます。
Databricks ウィジェットの種類
ウィジェットには次の 4 種類があります。
-
text: テキスト ボックスに値を入力します。 -
dropdown: 指定された値のリストから値を選択します。 -
combobox: テキストとドロップダウンの組み合わせ。 指定されたリストから値を選択するか、テキスト ボックスに値を入力します。 -
multiselect: 指定された値のリストから 1 つ以上の値を選択します。
ノートブック ツール バーの直後にウィジェットのドロップダウンとテキスト ボックスが表示されます。 ウィジェットでは文字列値のみが許可されます。

ウィジェットを作成する
このセクションでは、UI を使用するか、SQL マジックまたは Python、Scala、R 用ウィジェット API を使用してプログラムでウィジェットを作成する方法について説明します。
ヒント
Genie Code (エージェント モード) にこれを行うように指示します。
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
UI を使用してウィジェットを作成する
ノートブック UI を使ってウィジェットを作成します。 SQL ウェアハウスに接続している場合、これがウィジェットを作成できる唯一の方法です。 [ 編集] > [パラメーターの追加] を選択します。
ウィジェットの設定を編集するには、歯車アイコンをクリックします。
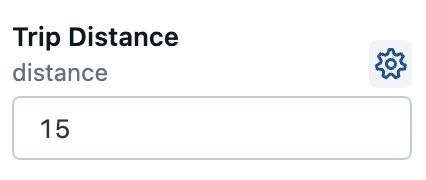
ウィジェット設定ダイアログで、ウィジェット名、省略可能なラベル、型、パラメーターの種類、使用可能な値、および省略可能な既定値を入力できます。 このダイアログの [パラメーター名] は、コード内のウィジェットを参照するために使用する名前です。 [Widget Label] (ウィジェット ラベル) は、UI のウィジェットに表示される省略可能な名前です。
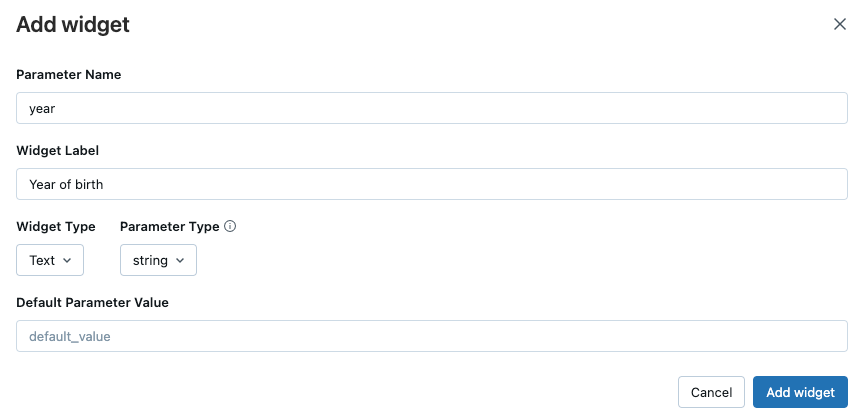
ウィジェットを作成したら、ウィジェット名をポイントすると、ウィジェットを参照する方法を説明するヒントを表示できます。

SQL、Python、R、Scala を使用してウィジェットを作成する
コンピューティング クラスターにアタッチされたノートブックに、プログラムでウィジェットを作成します。
ウィジェット API は、Scala、Python、R で一貫するように設計されています。SQL のウィジェット API は若干異なりますが、他の言語と同等です。 ウィジェットは、 Databricks Utilities (dbutils) 参照 インターフェイスを使用して管理します。
- すべての種類のウィジェットの最初の引数は
nameです。 これは、ウィジェットにアクセスするために使用する名前です。 - 2 番目の引数は、ウィジェットの既定の設定である
defaultValueです。 - すべてのウィジェットの種類 (
textを除きます) の 3 番目の引数は、ウィジェットが受け取ることができる値の一覧であるchoicesです。 この引数は、ウィジェットの種類textには使用されません。 - 最後の引数は
labelです。ウィジェットのテキスト ボックスまたはドロップダウンに表示されるラベルの省略可能な値です。
Python
dbutils.widgets.dropdown("state", "CA", ["CA", "IL", "MI", "NY", "OR", "VA"])
スカラ (プログラミング言語)
dbutils.widgets.dropdown("state", "CA", Seq("CA", "IL", "MI", "NY", "OR", "VA"))
R
dbutils.widgets.dropdown("state", "CA", list("CA", "IL", "MI", "NY", "OR", "VA"))
SQL
CREATE WIDGET DROPDOWN state DEFAULT "CA" CHOICES SELECT * FROM (VALUES ("CA"), ("IL"), ("MI"), ("NY"), ("OR"), ("VA"))
ウィジェット パネルからウィジェットを操作します。
ウィジェットの現在の値にアクセスしたり、すべてのウィジェットのマッピングを取得したりできます。
Python
dbutils.widgets.get("state")
dbutils.widgets.getAll()
スカラ (プログラミング言語)
dbutils.widgets.get("state")
dbutils.widgets.getAll()
R
dbutils.widgets.get("state")
SQL
SELECT :state
最後に、1 つのウィジェットまたはノートブック内のすべてのウィジェットを削除できます。
Python
dbutils.widgets.remove("state")
dbutils.widgets.removeAll()
スカラ (プログラミング言語)
dbutils.widgets.remove("state")
dbutils.widgets.removeAll()
R
dbutils.widgets.remove("state")
dbutils.widgets.removeAll()
SQL
REMOVE WIDGET state
ウィジェットを削除した場合、同じセルにウィジェットを作成することはできません。 別のセルでウィジェットを作成する必要があります。
Spark SQL と SQL ウェアハウスでウィジェットの値を使用する
Spark SQL と SQL ウェアハウスは、パラメーター マーカーを使ってウィジェットの値にアクセスします。 パラメーター マーカーは、指定された値を SQL ステートメントから明確に分離して、SQL インジェクション攻撃からコードを保護します。
ウィジェットのパラメーター マーカーは、Databricks Runtime 15.2 以降で使用できます。 以前のバージョンの Databricks Runtime では、 Databricks Runtime 15.1 以降の古い構文を使用する必要があります。
任意の言語で定義されたウィジェットには、ノートブックを対話的に実行しながら、Spark SQL からアクセスできます。 次のワークフローを考慮してください。
現在のカタログ内のすべてのデータベースのドロップダウン ウィジェットを作成します。
dbutils.widgets.dropdown("database", "default", [database[0] for database in spark.catalog.listDatabases()])テーブル名を手動で指定するテキスト ウィジェットを作成します。
dbutils.widgets.text("table", "")SQL クエリを実行して、データベース内のすべてのテーブルを表示します (ドロップダウン リストから選択)。
SHOW TABLES IN IDENTIFIER(:database)注
データベース、テーブル、ビュー、関数、列、フィールドの名前などのオブジェクト識別子として文字列を解析するには、SQL の
IDENTIFIER()句を使う必要があります。tableウィジェットにテーブル名を手動で入力します。フィルター値を指定するためのテキスト ウィジェットを作成します。
dbutils.widgets.text("filter_value", "")クエリの内容を編集せずに、テーブルの内容をプレビューします。
SELECT * FROM IDENTIFIER(:database || '.' || :table) WHERE col == :filter_value LIMIT 100
DDL 文字列句でウィジェット値を使用する
一部の DDL 句 (LOCATION の CREATE TABLE 句など) は、識別子ではなく文字列リテラルを受け入れます。 これらの句には IDENTIFIER() 句を使用できません。
適用対象: Databricks Runtime ![]() 18.0 以上" とマークされている
18.0 以上" とマークされている
Databricks Runtime 18.0 以降では、次の句でウィジェットを直接使用できます。
CREATE EXTERNAL TABLE my_table USING DELTA LOCATION :path
適用対象: Databricks Runtime ![]() 14.3 ~ 17.3 LTS
14.3 ~ 17.3 LTS
以前のバージョンでは、 EXECUTE IMMEDIATE を使用してステートメントを動的に構築します。 たとえば、 pathという名前のウィジェットがある場合は、次のようになります。
DECLARE table_location STRING;
SET VARIABLE table_location = CONCAT('abfss://container@account.dfs.core.windows.net/', :path);
EXECUTE IMMEDIATE 'CREATE EXTERNAL TABLE my_table USING DELTA LOCATION \'' || table_location || '\'';
注
文字列リテラル内にパラメーター マーカーを埋め込むことはできません (たとえば、 'abfss://:widget...')。 代わりに、文字列全体を 1 つのパラメーターとして渡すか、 CONCAT() を使用して変数に完全な文字列をビルドしてから、 EXECUTE IMMEDIATEに渡します。
DDL ステートメントでのパラメーター マーカーの使用の詳細については、「 DDL 文字列句でのパラメーター マーカー」を参照してください。
ウィジェットの設定を構成する
新しい値が選択された場合のウィジェットの動作、ウィジェット パネルが常にノートブックの上部にピン留めされるようにするかどうかを構成し、ノートブック内のウィジェットのレイアウトを変更できます。
[ウィジェット] パネルの右端にある
 アイコンをクリックします。
アイコンをクリックします。ポップアップウィジェットパネルの設定ダイアログで、ウィジェットの実行動作を選択します。
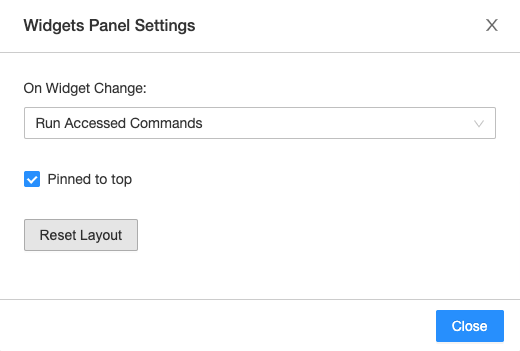
- ノートブックの実行: 新しい値を選択するたびにノートブック全体を再実行します。
- アクセスされたコマンドの実行: 新しい値を選択するたびに、その特定のウィジェットの値を取得するセルのみを再実行します。 これはウィジェットを作成するときの既定の設定です。 SQL セルは、この構成では再実行されません。
- 何もしない: 新しい値を選択しても、何も再実行しません。
ウィジェットをノートブックの上部にピン留めするか、最初のセルの上にウィジェットを配置するには、
 をクリックします。 設定はユーザーごとに保存されます。 サムタック アイコンをもう一度クリックして、既定の動作にリセットします。
をクリックします。 設定はユーザーごとに保存されます。 サムタック アイコンをもう一度クリックして、既定の動作にリセットします。ノートブックに対して "管理可能" のアクセス許可がある場合は、
 をクリックしてウィジェットのレイアウトを構成できます。 各ウィジェットの順序とサイズはカスタマイズできます。 変更を保存または破棄するには、
をクリックしてウィジェットのレイアウトを構成できます。 各ウィジェットの順序とサイズはカスタマイズできます。 変更を保存または破棄するには、 をクリックします。
をクリックします。ウィジェットのレイアウトはノートブックと一緒に保存されます。 ウィジェットのレイアウトを既定の構成から変更した場合、新しいウィジェットはアルファベット順に追加されなくなります。
ウィジェットのレイアウトを既定の順序とサイズにリセットするには、
をクリックして [Widget Panel Settings](ウィジェット パネル設定) ダイアログを開き、次に [レイアウトのリセット] をクリックします。
removeAll()コマンドでは、ウィジェット レイアウトをリセットしません。
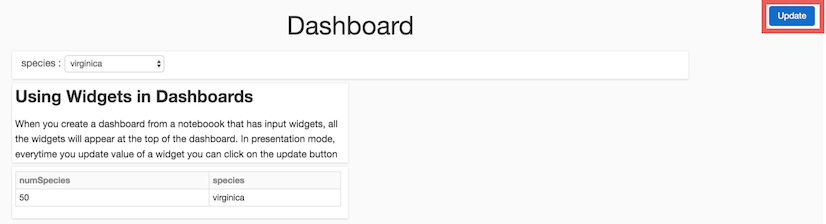
ダッシュボードの Databricks ウィジェット
入力ウィジェットがあるノートブックからダッシュボードを作成すると、すべてのウィジェットが上部に表示されます。 プレゼンテーション モードでは、ウィジェットの値を更新するたびに、[更新] ボタンをクリックしてノートブックを再実行し、ダッシュボードを新しい値で更新できます。
%run で Databricks ウィジェットを使用する
ウィジェットを含む ノートブックを実行 すると、指定したノートブックがウィジェットの既定値で実行されます。
ノートブックが (SQL ウェアハウスではなく) クラスターにアタッチされている場合は、ウィジェットに値を渡すこともできます。 次に例を示します。
%run /path/to/notebook $X="10" $Y="1"
この例では、指定したノートブックを実行し、ウィジェット X に 10 を渡し、ウィジェット Y に 1 を渡します。
制限事項
詳細については、「 Databricks ノートブックの既知の制限事項 」を参照してください。