Azure Databricks の既定のデプロイでは、Databricks によって管理される新しい仮想ネットワークが作成されます。 このクイック スタートでは、その代わりに自分の仮想ネットワーク内に Azure Databricks ワークスペースを作成する方法について説明します。 そのワークスペース内に Apache Spark クラスターも作成します。
自分の仮想ネットワーク内に Azure Databricks ワークスペースを作成することを選択する理由の詳細については、「Azure Virtual Network (VNet インジェクション) で Azure Databricks をデプロイする」を参照してください。
前提条件
Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。 Azure 無料試用版サブスクリプションを使用してこのチュートリアルを実行することはできません。 無料アカウントをお持ちの場合は、お使いのプロファイルにアクセスし、サブスクリプションを [従量課金制] に変更します。 詳細については、Azure 無料アカウントに関するページをご覧ください。 次に、リージョン内の vCPU について使用制限を削除し、クォータの増加を依頼します。 Azure Databricks ワークスペースを作成するときに、 [Trial (Premium - 14-Days Free DBUs)](試用版 (Premium - 14 日間の無料 DBU)) の価格レベルを選択し、ワークスペースから 14 日間無料の Premium Azure Databricks DBU にアクセスできるようにします。
Azure 共同作成者または所有者になっているか、Microsoft.ManagedIdentity リソース プロバイダーがサブスクリプションに登録されている必要があります。 手順については、「リソース プロバイダーの登録」を参照してください。
Azure portal にサインインします
Azure portal にサインインします。
注
FedRAMP High などの米国政府のコンプライアンス認定資格を保持する Azure 商用クラウド内に Azure Databricks ワークスペースを作成する場合は、Microsoft または Databricks アカウント チームに連絡して、このエクスペリエンスへのアクセスを取得してください。
仮想ネットワークの作成
Azure portal メニューから [リソースの作成] を選択します。 次に、[ネットワーク] > [仮想ネットワーク] を選択します。
[仮想ネットワークの作成] で、次の設定を適用します。
設定 提案された値 説明 サブスクリプション <該当するサブスクリプション> 使用する Azure サブスクリプションを選択します。 リソースグループ databricks-quickstart(データブリックス・クイックスタート) [新規作成] を選択し、アカウントの新しいリソース グループ名を入力します。 名前 databricks-quickstart(データブリックス・クイックスタート) 仮想ネットワークの名前を選択します。 リージョン <ユーザーに最も近いリージョンを選択> お客様の仮想ネットワークをホストできる地理的な場所を選択します。 お客様のユーザーに最も近い場所を使用します。 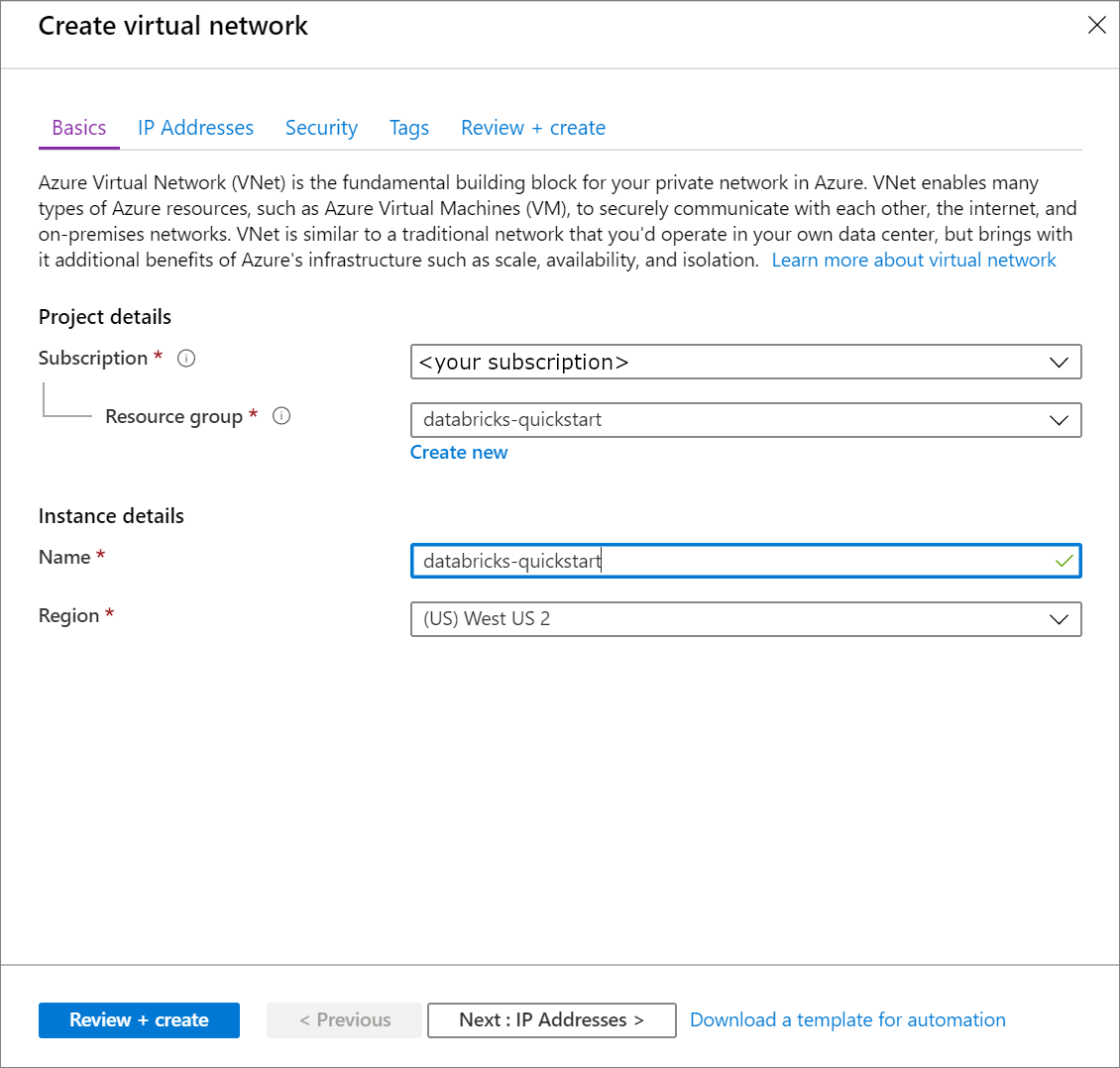
[次へ: IP アドレス >] を選択し、次の設定を適用します。 次に、[Review + create](確認と作成) を選択します。
設定 提案された値 説明 IPv4 アドレス空間 10.2.0.0/16 CIDR 表記の仮想ネットワークのアドレス範囲。 CIDR の範囲は /16 から /24 の間である必要があります サブネット名 デフォルト 仮想ネットワークの既定のサブネットの名前を選択します。 サブネットのアドレス範囲 10.2.0.0/24 サブネットのアドレス範囲 (CIDR 表記)。 仮想ネットワークのアドレス空間に含まれている必要があります。 使用中のサブネットのアドレス範囲を編集することはできません。 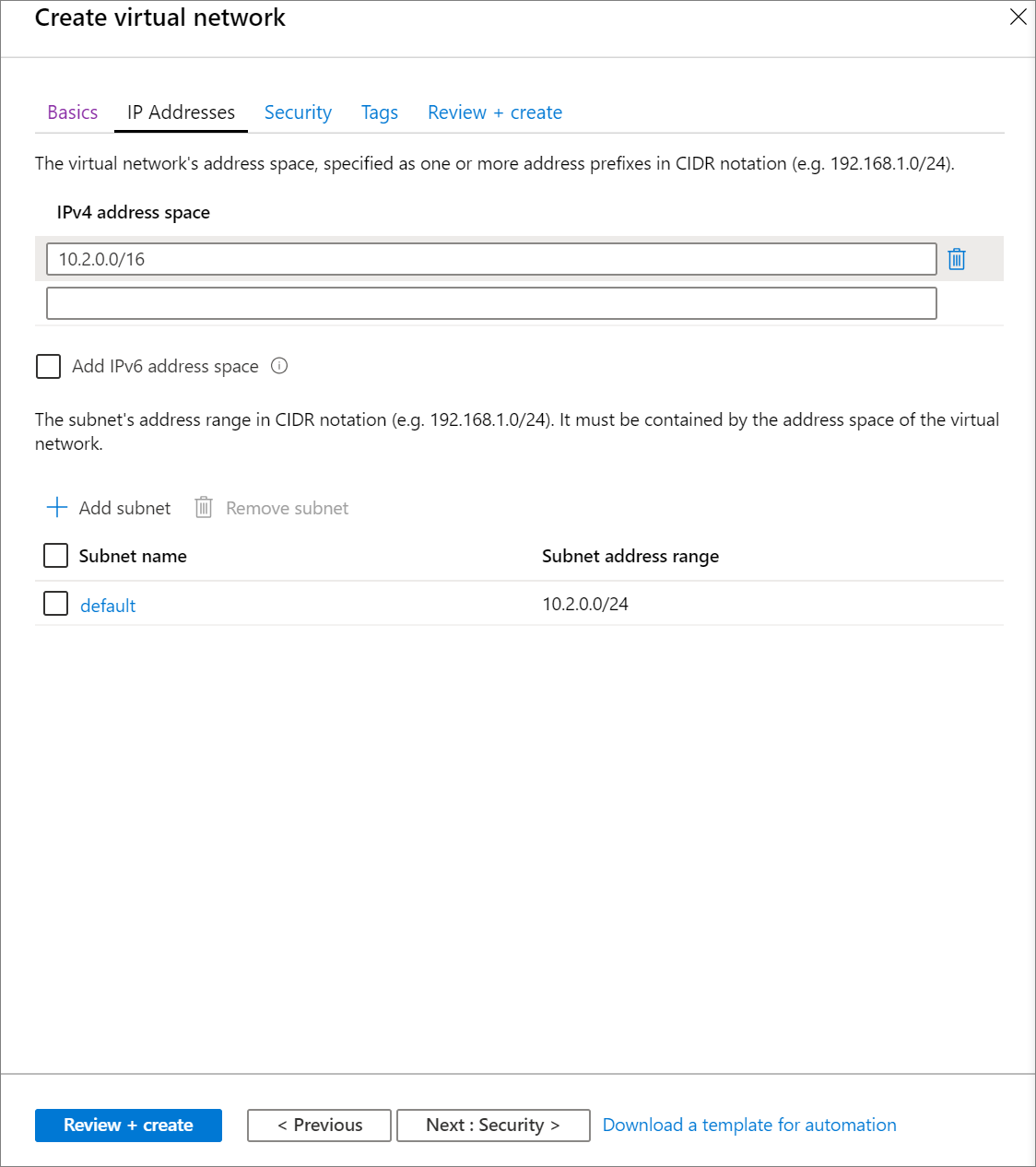
[Review + create](確認と作成) タブで、[作成] を選択して仮想ネットワークをデプロイします。 デプロイが完了したら、仮想ネットワークに移動し、 [設定] で [アドレス空間] を選択します。 [その他のアドレス範囲の追加] というボックスをオンにし、
10.179.0.0/16を挿入して [保存] を選択します。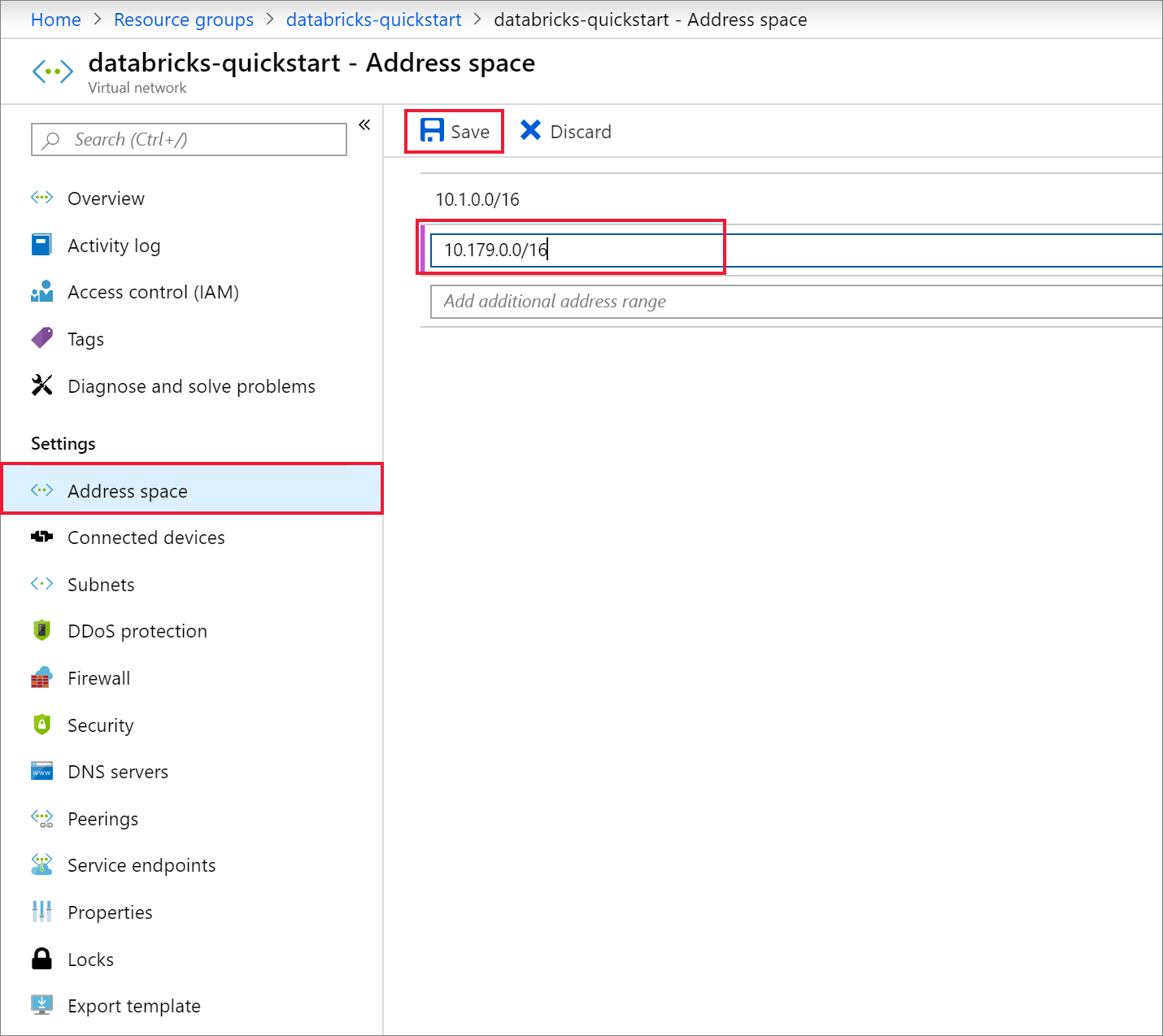
Azure Databricks ワークスペースを作成する
Azure portal メニューから [リソースの作成] を選択します。 次に、[分析] > [Databricks] を選択します。
[Azure Databricks サービス] で、次の設定を適用します。
設定 提案された値 説明 ワークスペース名 databricks-quickstart(データブリックス・クイックスタート) Azure Databricks ワークスペースの名前を選択します。 サブスクリプション <該当するサブスクリプション> 使用する Azure サブスクリプションを選択します。 リソースグループ databricks-quickstart(データブリックス・クイックスタート) 仮想ネットワークに使用したものと同じリソース グループを選択します。 ロケーション <ユーザーに最も近いリージョンを選択> 仮想ネットワークと同じ場所を選択します。 価格レベル Standard と Premium のいずれかを選択します。 価格レベルの詳細については、Databricks の価格に関するページを参照してください。 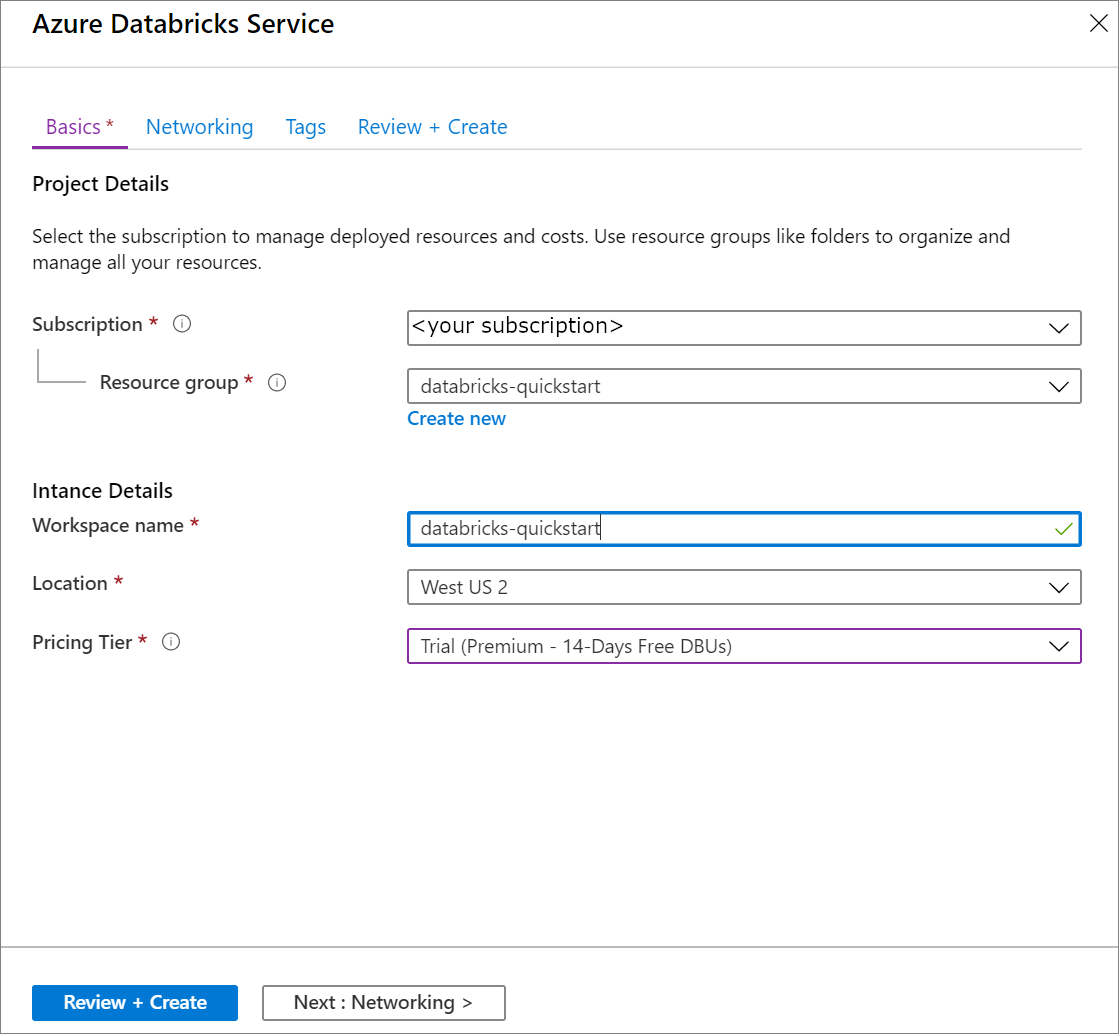
[基本] ページで設定の入力を完了したら、[次へ: ネットワーク >] を選択して、次の設定を適用します。
設定 提案された値 説明 自分の仮想ネットワーク (VNet) に Azure Databricks ワークスペースをデプロイする はい この設定により、仮想ネットワークに Azure Databricks ワークスペースをデプロイすることができます。 仮想ネットワーク databricks-quickstart(データブリックス・クイックスタート) 前のセクションで作成した仮想ネットワークを選択します。 パブリック サブネット名 パブリックサブネット 既定のパブリック サブネット名を使用します。 パブリック サブネットの CIDR 範囲 10.179.64.0/18 /26 までの CIDR 範囲を使用します (26 も含まれます)。 プライベート サブネット名 プライベートサブネット 既定のプライベート サブネット名を使用します。 プライベート サブネットの CIDR 範囲 10.179.0.0/18 /26 までの CIDR 範囲を使用します (26 も含まれます)。 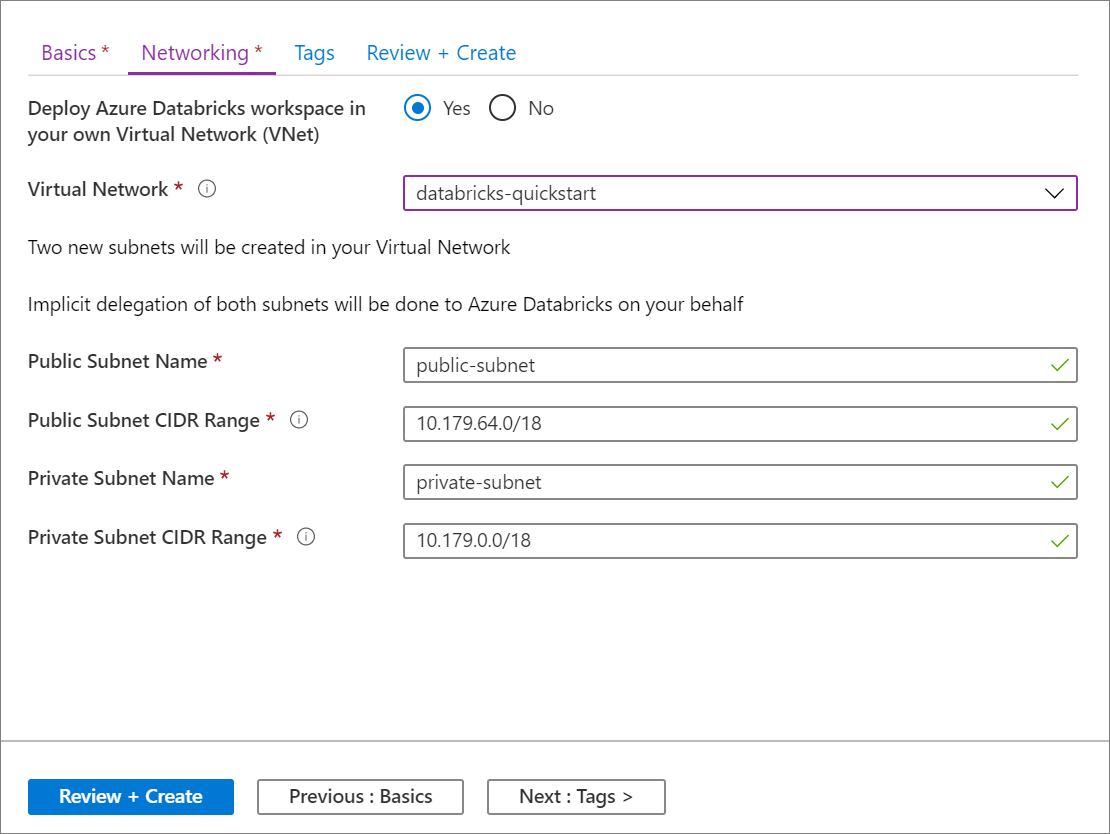
デプロイが完了したら、Azure Databricks リソースに移動します。 仮想ネットワーク ピアリングが無効になっていることに注意してください。 また、概要ページのリソース グループとマネージド リソース グループにも注目してください。
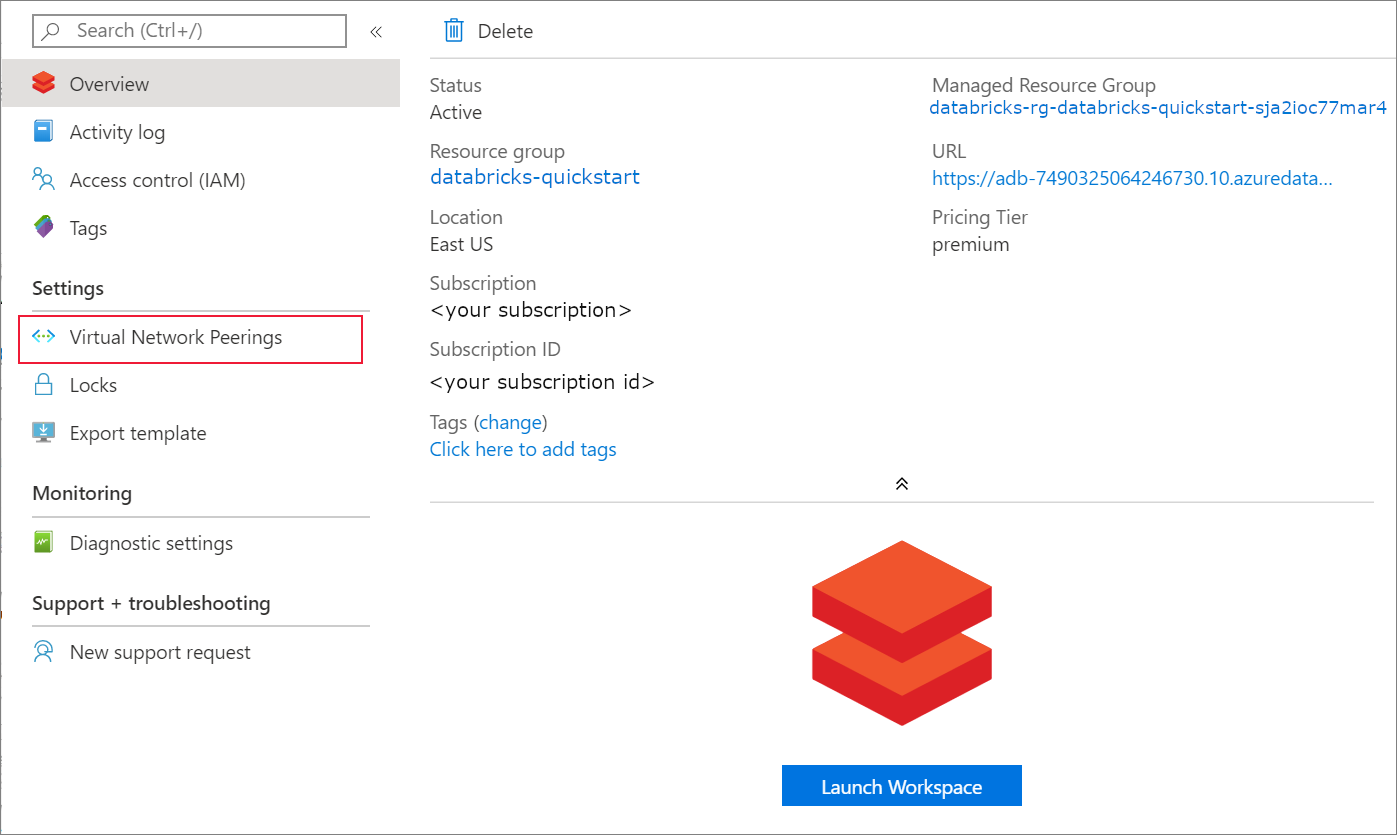
マネージド リソース グループは変更可能ではありません。また、仮想マシンの作成には使用されません。 自分で管理しているリソース グループ内に仮想マシンを作成するだけです。
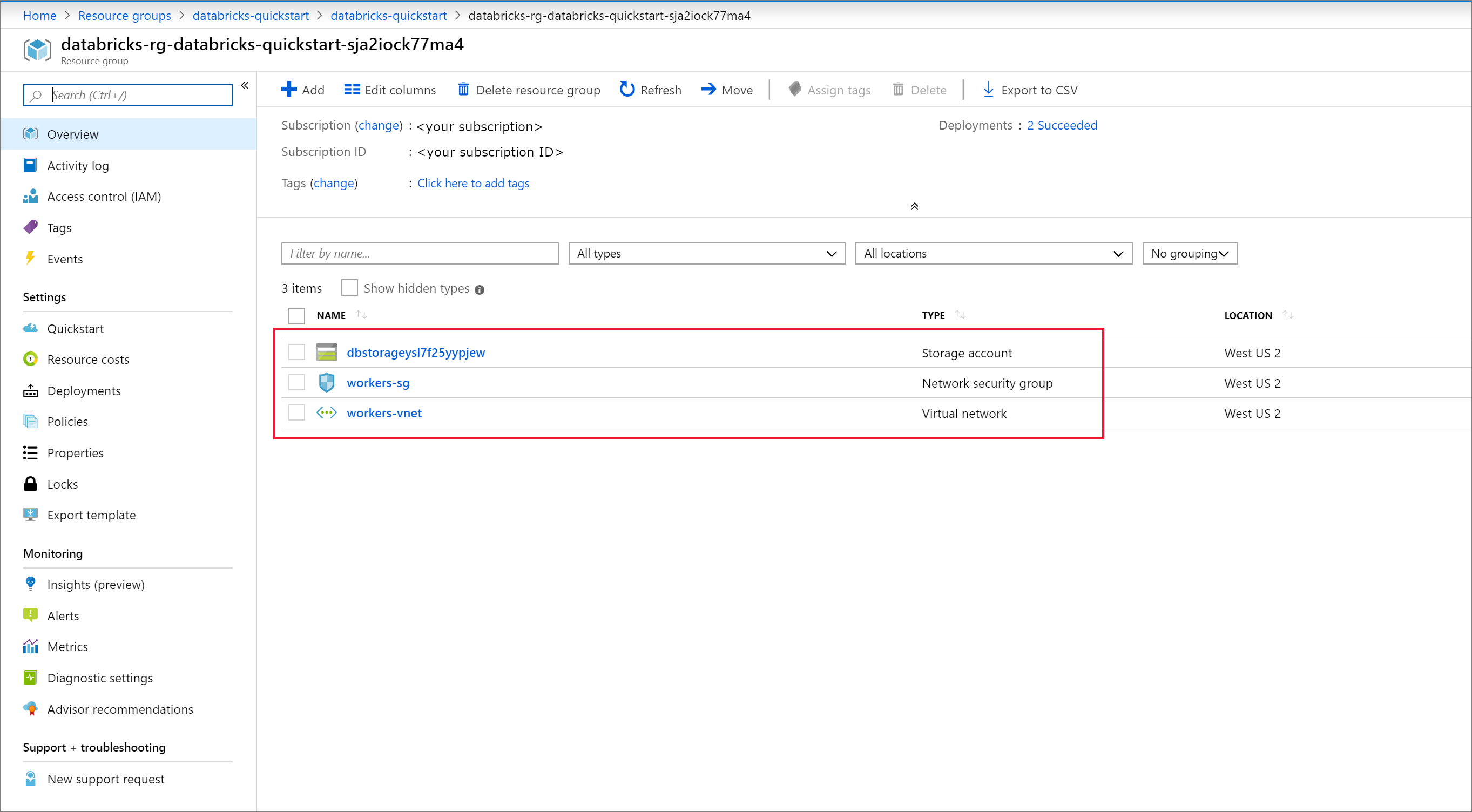
ワークスペースのデプロイが失敗した場合でも、ワークスペースはエラー状態で作成されます。 失敗したワークスペースを削除し、デプロイ エラーのない新しいワークスペースを作成します。 失敗したワークスペースを削除すると、管理対象リソース グループと、正常にデプロイされたリソースもすべて削除されます。
クラスターの作成
注
無料アカウントを使用して Azure Databricks クラスターを作成するには、クラスターを作成する前に、プロファイルにアクセスし、サブスクリプションを従量課金制に変更します。 詳細については、Azure 無料アカウントに関するページをご覧ください。
Azure Databricks サービスに戻り、 [概要] ページで [ワークスペースの起動] を選択します。
[クラスター]>[+ クラスターの作成] の順に選択します。 次に、databricks-quickstart-cluster のようなクラスター名を作成し、残りの既定の設定を受け入れます。 [クラスターの作成] を選択します。
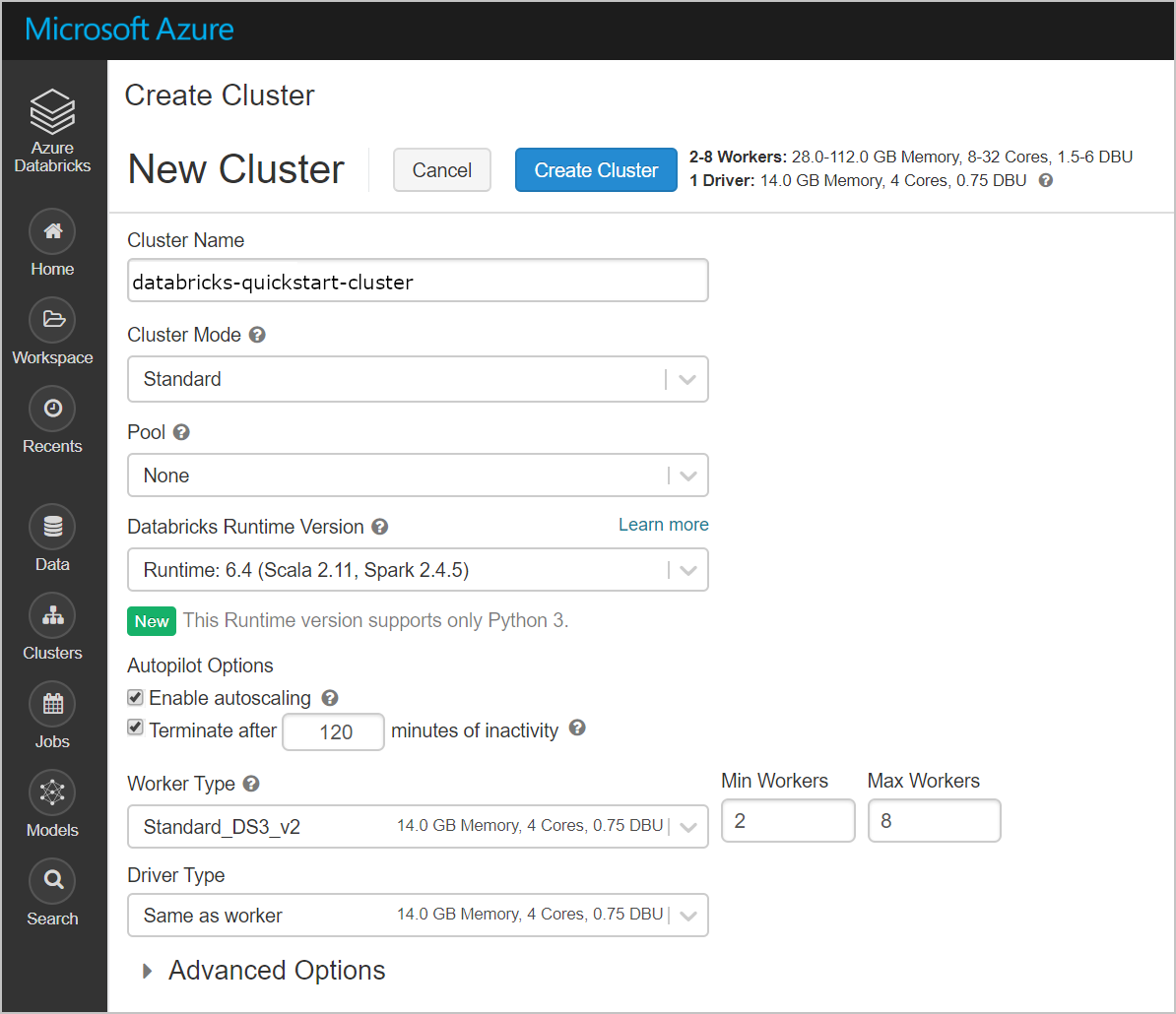
クラスターが実行中になったら、Azure portal でマネージド リソース グループに戻ります。 新しい仮想マシン、ディスク、IP アドレス、およびネットワーク インターフェイスに注目してください。 ネットワーク インターフェイスは、IP アドレスを持つパブリックとプライベートの各サブネットに作成されます。
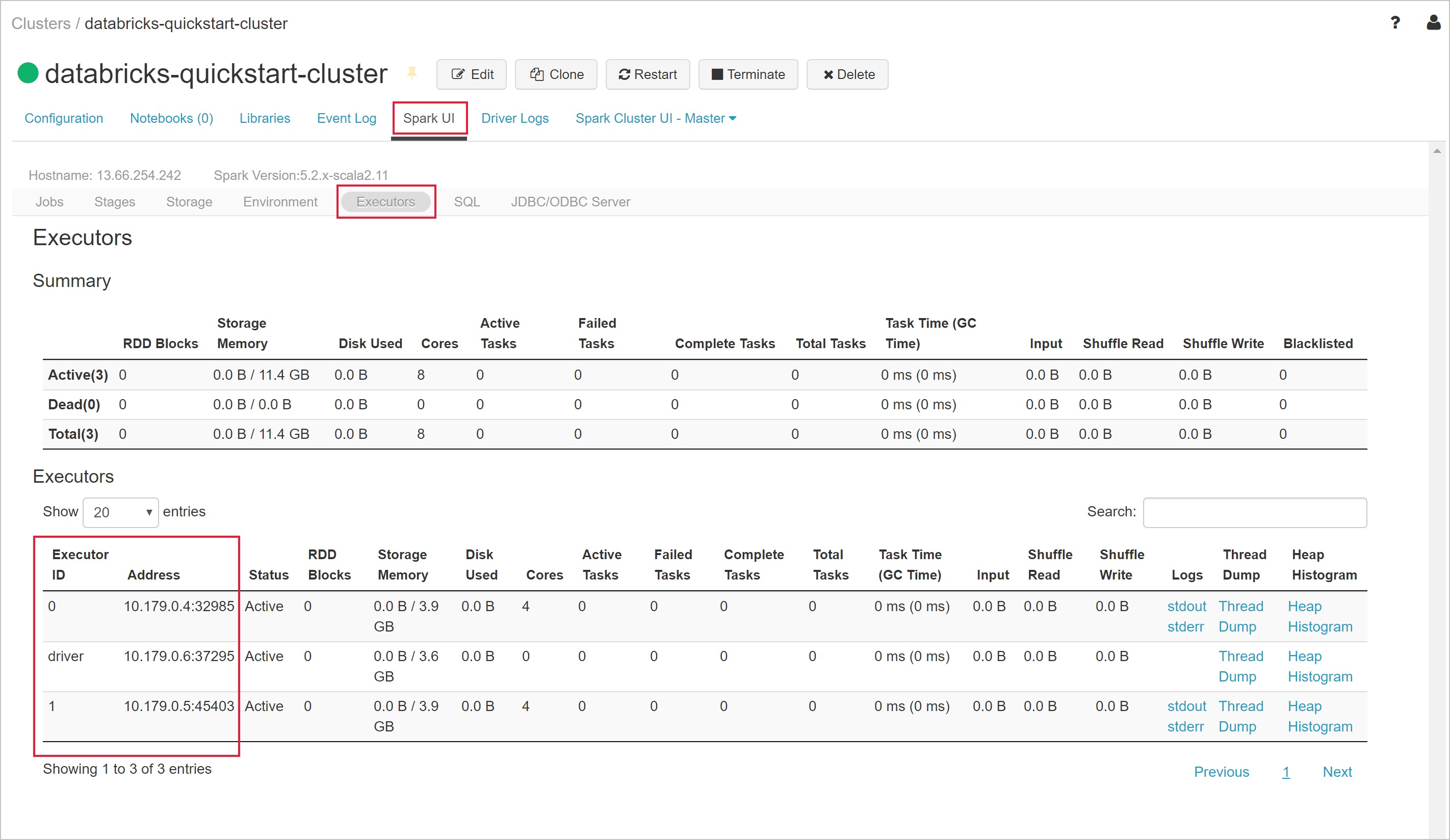
Azure Databricks ワークスペースに戻り、作成したクラスターを選択します。 次に、 [Spark UI] ページの [エグゼキュータ] タブに移動します。 ドライバーとエグゼキュータのアドレスがプライベート サブネットの範囲内にあることに注意してください。 この例では、ドライバーは 10.179.0.6 で、エグゼキュータは 10.179.0.4 と 10.179.0.5 です。 IP アドレスは異なる場合があります。
リソースのクリーンアップ
記事を完了したら、クラスターを終了できます。 そのためには、Azure Databricks ワークスペースの左側のウィンドウで、 [クラスター] を選択します。 終了するクラスターで、 [アクション] 列の下にある省略記号をポイントし、 [終了] アイコンを選択します。 これによりクラスターが停止します。
クラスター作成時に [Terminate after __ minutes of inactivity](アクティビティが __ 分ない場合は終了する) チェック ボックスをオンにしていた場合、手動で終了しなくともクラスターは自動で停止します。 このような場合、クラスターは、一定の時間だけ非アクティブな状態が続くと自動的に停止します。
クラスターを再利用しない場合は、Azure portal で作成したリソース グループを削除できます。
次の手順
この記事では、仮想ネットワークにデプロイした Azure Databricks に Spark クラスターを作成しました。 次の記事に進み、Azure Databricks ノートブックから JDBC を使用して仮想ネットワーク内の SQL Server Linux Docker コンテナーのクエリを実行する方法を学習してください。
Azure Databricks ノートブックから仮想ネットワーク内の SQL Server Linux Docker コンテナーのクエリを実行する