このページでは、とreadStreamを使用して writeStreamのソースとシンクとして Delta テーブルを使用する方法について説明します。 Delta Lake は、ストリーミング システムとファイルのパフォーマンスと信頼性に関する一般的な問題を解決します。 利点は次のとおりです。
- 低待機時間の取り込みによって生成された小さなファイルを結合し、パフォーマンスを向上させます。
- 複数のストリーム (または同時に実行されるバッチジョブ) で「厳密に一度だけ」処理を維持します。
- ストリーム ソースとしてファイルを使用するときに、新しいファイルを効率的に検出します。
Databricks SQL でストリーミング テーブルを使用してデータを読み込む方法については、「 Databricks SQL でストリーミング テーブルを使用する」を参照してください。
Delta Lake でのストリーム静的結合については、「 Stream-static joins」を参照してください。
シンクとして Delta テーブルを使用する
構造化ストリーミングを使用して Delta テーブルにデータを書き込むことができます。 Delta Lake トランザクション ログでは、テーブルに対して他のストリームまたはバッチ クエリが同時に実行されている場合でも、正確に 1 回の処理が保証されます。
構造化ストリーミング シンクを使用して Delta テーブルに書き込むと、 epochId = -1で空のコミットが表示されることがあります。 これらは想定され、通常は次の場合に発生します。
- ストリーミング クエリの各実行の最初のバッチ (これは、
Trigger.AvailableNowのすべてのバッチで発生します)。 - スキーマが変更されたとき (列の追加など)。
これらの空のコミットは意図的なものであり、エラーを示すものではありません。 クエリの正確性やパフォーマンスに大きな影響はありません。
Note
Delta Lake の VACUUM 関数は、Delta Lake で管理されていないすべてのファイルを削除しますが、_ で始まるディレクトリはスキップします。
<table-name>/_checkpoints などのディレクトリ構造を使用して、Delta テーブルの他のデータおよびメタデータと共にチェックポイントを安全に保存できます。
メトリックを使用してバックログを監視する
ストリーミング クエリ プロセスのバックログを監視するには、次のメトリックを使用します。
-
numBytesOutstanding: バックログでまだ処理されていないバイト数。 -
numFilesOutstanding: バックログでまだ処理されていないファイルの数。 -
numNewListedFiles: このバッチのバックログを計算するために一覧表示された Delta Lake ファイルの数。 -
backlogEndOffset: バックログの計算に使用される Delta テーブルのバージョン。
ノートブックで、ストリーミング クエリの進行状況ダッシュボードの [ 生データ ] タブで次のメトリックを表示します。
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
追加モード
既定では、ストリームは追加モードで実行され、新しいレコードのみがテーブルに追加されます。
テーブルにストリーミングするときは、 toTable メソッドを使用します。
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
完全モード
完全モードで構造化ストリーミングを使用して、バッチごとにテーブル全体を置き換えます。 たとえば、顧客別に集計されたイベントの概要テーブルを継続的に更新できます。
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
厳密な待機時間要件のないアプリケーションの場合は、 AvailableNowなどの 1 回限りトリガーを使用してコンピューティング リソースとコストを節約できます。 たとえば、このトリガーを使用して、特定のスケジュールで集計テーブルを更新し、前回の更新以降に到着した新しいデータのみを処理します。
「AvailableNow: 増分バッチ処理」を参照してください。
ソース差分テーブルへの変更を処理する
構造化ストリーミングでは、Delta テーブルの増分読み取りが実行されます。 ストリーミング クエリが Delta テーブルから読み取る際、ソース テーブルに新しいテーブル バージョンがコミットされるたびに、新しいレコードがべき等的に処理されます。 構造化ストリーミングは追加入力のみを受け入れ、ソース Delta テーブルに変更が発生した場合は例外をスローします。 たとえば、 UPDATE、 DELETE、 MERGE INTO、または OVERWRITE 操作によってストリーミング クエリによって読み取られたソース Delta テーブルが変更された場合、ストリームはエラーで失敗します。
ユース ケースに応じて、ソース差分テーブルへのアップストリームの変更を処理する一般的な方法は 4 つあります。 参照テーブルとそれぞれの詳細を次に示します。
| 方法 | 利点 | デメリット |
|---|---|---|
skipChangeCommits |
単純です。複雑なロジックを記述する必要はありません。 アップストリームの変更が個別に処理される追加のみの処理や、不適切なレコードを一時的に処理する場合に便利です。 | 変更を適用せず、追加のみを処理します。 |
| 完全更新 | また、単純で、複雑なロジックを記述する必要はありません。 アップストリームの変更がまれな小規模なデータセットに便利です。 | 大規模なデータセットにはコストがかかります。 すべてのダウンストリーム テーブルを再処理する必要があります。 |
| データ フィードの変更 | すべての変更の種類 (挿入、更新、削除) を処理します。 Databricks では、可能な限りテーブルから直接ではなく、Delta テーブルの CDC フィードからストリーミングすることをお勧めします。 | 各変更の種類を処理するために、より複雑なロジックを記述する必要があります。 |
| マテリアライズド・ビュー | 自動変更伝達を備える構造化ストリーミングに代わるシンプルな方法。 | 待機時間が長くなります。 Lakeflow Spark 宣言パイプラインと Databricks SQL でのみ使用できます。 |
アップストリームの変更コミットをスキップする skipChangeCommits
既存のレコードを削除または変更するトランザクションを無視し、追加のみを処理するように skipChangeCommits を設定します。 これは、既存のデータに対する変更をストリーム経由で伝達する必要がない場合や、それらの変更を処理するために個別のロジックを使用する場合に便利です。 1 回限りの変更を一時的に無視する必要がある場合は、 skipChangeCommits のオンとオフを切り替えることができます。
Databricks では、変更データ フィードを使用しないほとんどのワークロードで skipChangeCommits を使用することをお勧めします。
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Delta テーブルに対してストリーミング読み取りが開始した後にテーブルのスキーマが変更された場合、クエリは失敗します。 ほとんどのスキーマ変更では、ストリームを再開してスキーマの不一致を解決し、処理を続行できます。
Databricks Runtime 12.2 LTS 以前では、列マッピングが有効になっており、列の名前変更や削除のように追加を伴わないスキーマの展開が行われた Delta テーブルからはストリーミングを行えません。 詳細については、「 列マッピングとストリーミング」を参照してください。
Note
Databricks Runtime 12.2 LTS 以降では、 skipChangeCommits によって ignoreChangesが置き換えられます。 Databricks Runtime 11.3 LTS 以前では、ignoreChanges のみがサポートされているオプションです。 詳細については、「 従来のオプション: ignoreChanges 」を参照してください。
従来のオプション: ignoreDeletes
ignoreDeletes は、パーティション境界でデータを削除するトランザクション (つまり、パーティションの完全な削除) のみを処理する従来のオプションです。 パーティション以外の削除、更新、またはその他の変更を処理する必要がある場合は、代わりに skipChangeCommits を使用します。
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
従来のオプション: ignoreChanges
ignoreChanges は、Databricks Runtime 11.3 LTS 以前で使用できます。 Databricks Runtime 12.2 LTS 以降では、 skipChangeCommitsに置き換えられます。
ignoreChangesを有効にすると、ソース テーブル内の書き換えられたデータ ファイルは、UPDATE、MERGE INTO、DELETE (パーティション内)、OVERWRITEなどのデータ変更操作の後に再出力されます。 変更されていない行は、多くの場合、新しい行と共に出力されるため、ダウンストリームのコンシューマーが重複を処理できる必要があります。 削除はダウンストリームには反映されません。
ignoreChanges は、ignoreDeletes よりも優先されます。
これに対し、 skipChangeCommits はファイル変更操作を完全に無視します。
UPDATE、MERGE INTO、DELETE、OVERWRITEなどのデータ変更操作により、ソース テーブル内の書き換えられたデータ ファイルは完全に無視されます。 ストリーム ソース テーブルの変更を反映するには、これらの変更を反映するための個別のロジックを実装する必要があります。
Databricks では、すべての新しいワークロードに skipChangeCommits を使用することをお勧めします。 ワークロードを ignoreChanges から skipChangeCommitsに移行するには、ストリーミング ロジックをリファクタリングします。
ダウンストリーム テーブルの完全更新
アップストリームの変更がまれで、データが再処理できるほど小さい場合は、ストリーミング チェックポイントと出力テーブルを削除してから、最初からストリームを再起動できます。 これにより、ストリームはソース テーブルのすべてのデータを再処理します。 また、この方法では、このストリームの出力に依存するすべてのダウンストリーム テーブルを再処理する必要があることに注意してください。
このアプローチは、アップストリームの変更がまれで、完全な更新のコストが許容される小規模なデータセットまたはワークロードに最適です。
変更データ フィードを使用する
すべての種類の変更 (挿入、更新、削除) を処理するワークロードでは、Delta Lake 変更データ フィードを使用します。 変更データ フィードでは、行レベルの変更を Delta テーブルに記録します。これにより、これらの変更をストリーミングし、ダウンストリーム テーブルの各変更の種類を処理するロジックを記述できます。 コードがすべての種類の変更イベントを明示的に処理するため、これは最も堅牢なアプローチです。 Azure Databricks で Delta Lake 変更データ フィードを使用する を参照してください。
Lakeflow Spark 宣言型パイプラインを使用している場合は、「 AUTO CDC API: パイプラインを使用して変更データ キャプチャを簡略化する」を参照してください。
Important
Databricks Runtime 12.2 LTS 以降では、列の名前変更や削除など、非加法スキーマの進化を受けた列マッピングが有効になっている Delta テーブルの変更データ フィードからストリーミングすることはできません。 列マッピングとストリーミングを参照してください。
具体化されたビューを使用する
具体化されたビューは、ソース データの変更時に結果を再計算することで、アップストリームの変更を自動的に処理します。 可能な限り短い待機時間を必要とせず、ストリーミングの複雑さの管理を回避したい場合は、具体化されたビューを使用してアーキテクチャを簡略化できます。 具体化されたビューは、Lakeflow Spark 宣言パイプライン パイプラインと Databricks SQL で使用できます。 具体化されたビューを参照してください。
Example
たとえば、user_events によってパーティション分割された date、user_email、action 列を持つテーブル date があるとします。
user_events テーブルからストリーム出力し、GDPR のためにテーブルからデータを削除する必要があります。
skipChangeCommits を使用すると、複数のパーティション内のデータを削除できます (この例では、 user_emailでのフィルター処理)。 次の構文を使用します。
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
user_email を UPDATE ステートメントで更新すると、問題の user_email を含むファイルが書き換えられます。 変更されたデータ ファイルを無視するには、skipChangeCommits を使用します。
Databricks では、削除が常に完全なパーティションドロップであると確信している場合を除き、skipChangeCommitsではなくignoreDeletesを使用することをお勧めします。
冪等テーブル書き込みに foreachBatch を使用する
Note
Databricks では、foreachBatchを使用する代わりに、更新するシンクごとに個別のストリーミング書き込みを構成することをお勧めします。
foreachBatch内の複数のシンクへの書き込みでは、複数のテーブルへの書き込みがforeachBatchでシリアル化されるため、並列処理が減り、全体的な待機時間が長くなります。
Delta テーブルでは、DataFrameWriter 内の複数のテーブルへの書き込みをべき等にする次の foreachBatch オプションがサポートされています。
-
txnAppId: 各 DataFrame 書き込み時に渡すことができる一意の文字列。 たとえば、StreamingQuery ID をtxnAppIdとして使用できます。txnAppIdは、ユーザーが生成する一意の文字列であり、ストリーム ID に関連付ける必要はありません。 -
txnVersion: トランザクション バージョンとして機能する単調に増加する数値。
Delta Lake では、 txnAppId と txnVersion を使用して、重複する書き込みを識別して無視します。 たとえば、エラーによってバッチ書き込みが中断された後、同じ txnAppId でバッチを再実行し、 txnVersion して重複を正しく識別して無視することができます。
foreachBatch を使用した任意のデータ シンクへの書き込みに関するページを参照してください。
Warning
ストリーミング チェックポイントを削除し、新しいチェックポイントでクエリを再起動する場合、別の txnAppIdを指定する必要があります。 新しいチェックポイントは、バッチ ID 0 で始まります。 Delta Lake では、バッチ ID と txnAppIdを一意のキーとして使用し、既に確認されている値を持つバッチをスキップします。
次のコード例は、このパターンを示しています。
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
foreachBatch を使用してストリーミング クエリからアップサートを行う
mergeとforeachBatchを使用して、ストリーミング クエリから Delta テーブルに複雑なアップサートを書き込むことができます。
foreachBatch を使用した任意のデータ シンクへの書き込みに関するページを参照してください。
このアプローチには、多くのアプリケーションがあります。
-
update出力モードで書き込みパフォーマンスを向上させるのに対し、complete出力モードではマイクロバッチごとに結果テーブル全体を書き換える必要があります。 - マージ クエリを使用して変更データを
foreachBatchに書き込むことで、差分テーブルに変更のストリームを継続的に適用します。 Delta Lake での緩やかに変化するデータ (SCD) と変更データ キャプチャ (CDC) を参照してください。 - ストリーム処理中に重複除去を処理します。
foreachBatchで挿入専用のマージ クエリを使用すると、自動重複除去を使用して差分テーブルにデータを継続的に書き込むことができます。 差分テーブルへの書き込み時のデータ重複除去に関するページを参照してください。
Note
merge内のforeachBatchステートメントが冪等であることを確認してください。 それ以外の場合、ストリーミング クエリを再起動すると、同じデータ バッチに対して操作を複数回適用できます。 「foreachBatch」を使用してべき等テーブルを書き込む方法について参照してください。mergeがforeachBatchで使用されている場合、入力データ レート メトリックは、ソースでデータが生成される実際のレートの倍数を返す可能性があります。mergeは、入力データを複数回読み取り、メトリックを乗算します。 メトリックの乗算を防ぐには、mergeする前にバッチ DataFrame をキャッシュし、merge後にキャッシュを解除します。入力データレートは、
StreamingQueryProgressとノートブックストリーミングレートグラフで利用できます。 Azure Databricks のMonitoring Structured Streaming クエリを参照してください。
たとえば、MERGE内foreachBatch SQL ステートメントを使用できます。
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
また、アップサートのストリーミングに Delta Lake API を使用することもできます。
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
変更を処理するようにテーブルの初期バージョンを設定する
既定では、ストリームは利用可能な最新の Delta テーブル バージョンで始まります。 これには、その時点のテーブルの完全なスナップショットと、今後のすべての変更が含まれます。 Databricks では、ほとんどのワークロードで既定の初期テーブル バージョンを使用することをお勧めします。
必要に応じて、次のオプションを使用して、テーブル全体を処理せずに Delta Lake ストリーミング ソースの開始点を指定できます。
startingVersion: 読み取りを開始する差分テーブルのバージョン。 指定したバージョン以降にコミットされたすべてのテーブル変更は、ストリームによって読み取られます。 指定したバージョンが使用できない場合、ストリームの開始に失敗します。使用可能なコミット バージョンを見つけるには、
DESCRIBE HISTORY実行し、versionを確認します。 最新の変更のみを返すには、latestを指定します。 Delta テーブルのバージョンについては、「 テーブル履歴の操作」を参照してください。startingTimestamp: 読み取りを開始するタイムスタンプ。 指定したタイムスタンプ以降にコミットされたすべてのテーブル変更は、ストリームによって読み取られます。 指定されたタイムスタンプがすべてのテーブル コミットよりも前である場合、ストリーミングの読み取りは、取得可能な最も古いタイムスタンプから始まります。 次のいずれかを設定します。- タイムスタンプ文字列。 たとえば、「
"2019-01-01T00:00:00.000Z"」のように入力します。 - 日付文字列。 たとえば、「
"2019-01-01"」のように入力します。
- タイムスタンプ文字列。 たとえば、「
startingVersionとstartingTimestampの両方を同時に設定することはできません。 これらの設定は、新しいストリーミング クエリにのみ適用されます。 ストリーミング クエリが開始され、そのチェックポイントに進行状況が記録されている場合、これらの設定は無視されます。
Important
指定したバージョンまたはタイムスタンプからストリーミング ソースを開始することもできますが、ストリーミング ソースのスキーマは常に Delta テーブルの最新のスキーマです。 指定したバージョンまたはタイムスタンプの後に Delta テーブルに対する互換性のないスキーマ変更がないことを確認する必要があります。 そうしないと、スキーマが正しくないデータを読み取るときに、ストリーミング ソースから正しくない結果が返される可能性があります。
Example
たとえば、user_events というテーブルがあるとします。 バージョン 5 以降の変更を読み取る場合は、次を使用します。
spark.readStream
.option("startingVersion", "5")
.table("user_events")
2018-10-18 以降の変更を読み取る場合は、次を使用します。
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
データを削除せずに初期スナップショットを処理する
この機能は、Databricks Runtime 11.3 LTS 以降で使用できます。
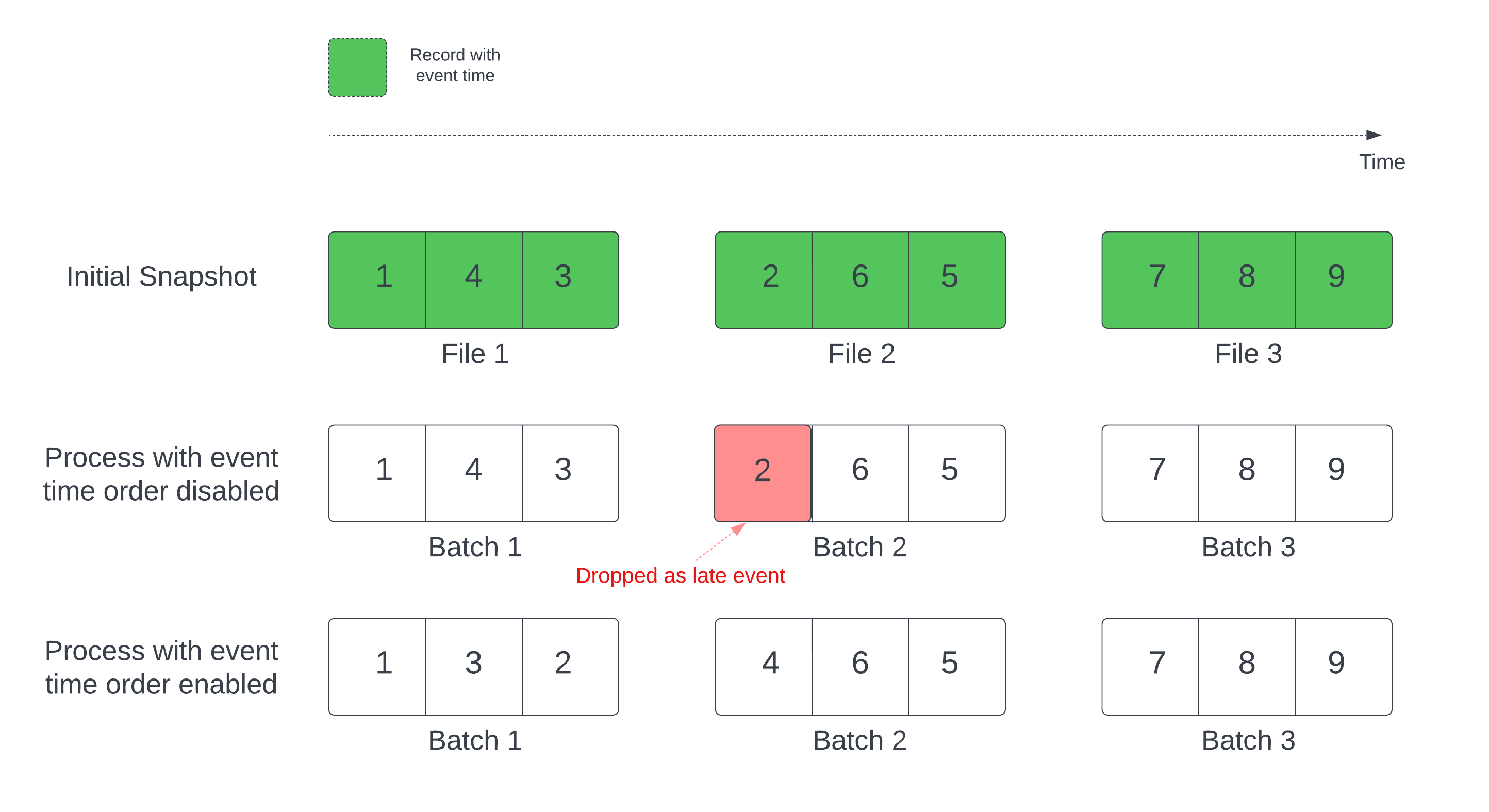
ウォーターマークが定義されたステートフル ストリーミング クエリでは、変更時間によってファイルを処理すると、レコードが間違った順序で処理される可能性があります。 これにより、ウォーターマークがレコードを遅延イベントとして誤ってマークし、ドロップする可能性があります。 これは、初期差分スナップショットが既定の順序で処理される場合にのみ発生します。
デルタ ソース テーブルを含むストリームの場合、クエリは最初にテーブルに存在するすべてのデータを処理し、 初期スナップショットと呼ばれるバージョンを作成します。 既定では、Delta テーブルのデータ ファイルは、最後に変更されたファイルに基づいて処理されます。 ただし、最後の変更時刻は、必ずしもレコードのイベント時間順序を表すわけではありません。
初期スナップショット処理中にデータが削除されないようにするには、 withEventTimeOrder オプションを有効にします。
withEventTimeOrder は、初期スナップショット データのイベント時間範囲をタイム バケットに分割します。 各マイクロバッチは、時間範囲内のデータをフィルター処理してバケットを処理します。
maxFilesPerTriggerオプションとmaxBytesPerTriggerオプションは、マイクロバッチサイズを制御するために適用できますが、処理方法がほぼ原因です。
次の図は、このプロセスを示しています。
制約
- ストリーム クエリが開始され、初期スナップショットがアクティブに処理されている場合、
withEventTimeOrderを変更することはできません。withEventTimeOrder変更された状態で再起動するには、チェックポイントを削除する必要があります。 -
withEventTimeOrderが有効になっている場合、初期スナップショット処理が完了するまで、この機能をサポートしていない Databricks Runtime バージョンにストリームをダウングレードすることはできません。 ダウングレードするには、初期スナップショットが完了するのを待つか、チェックポイントを削除してクエリを再起動します。 - この機能は、次のシナリオではサポートされていません。
- イベント時間列が生成された列であり、Delta ソースとウォーターマークの間に非プロジェクション変換が存在する。
- ストリーム クエリに複数の Delta ソースを含むウォーターマークがある。
パフォーマンス
withEventTimeOrderが有効になっている場合、初期スナップショット処理のパフォーマンスが低下する可能性があります。 各マイクロバッチは、初期スナップショットをスキャンして、対応するイベント時間範囲内のデータをフィルター処理します。 フィルター処理のパフォーマンスを向上させるには:
- データのスキップを適用できるように、イベント時間として Delta ソース列を使用します。 「データのスキップ」を参照してください。
- イベント時刻列に沿ってテーブルをパーティション分割します。
Spark UI を使用して、特定のマイクロバッチに対してスキャンされたデルタ ファイルの数を確認します。
Example
user_events 列を含むテーブル event_time があるとします。 ストリーミング クエリは集計クエリです。 初期スナップショットの処理中にデータが削除されないようにする場合は、次を使用できます。
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
クラスター上の Spark 構成で withEventTimeOrder を設定して、すべてのストリーミング クエリ ( spark.databricks.delta.withEventTimeOrder.enabled true) に適用できます。
入力レートを制限して処理パフォーマンスを向上させる
既定では、構造化ストリーミングは、各マイクロバッチで可能な限り多くのファイルを処理します。 バッチごとに処理されるデータの量を制限し、メモリ使用量を管理したり、待機時間を安定させたり、クラウド ストレージ コストを削減したりするには、次のオプションを使用します。
-
maxFilesPerTrigger: すべてのマイクロバッチで考慮される新しいファイルの数。 既定値は 1000 です。 -
maxBytesPerTrigger: 各マイクロバッチで処理されるデータの量。 このオプションは"ソフト max" を設定します。つまり、最小の入力単位がこの制限を超える場合にストリーミング クエリを進めるために、バッチで約この量のデータが処理され、制限を超える処理が行われる可能性があります。 これは既定では設定されません。
maxBytesPerTriggerとmaxFilesPerTriggerの両方を使用する場合、マイクロバッチは、maxFilesPerTriggerまたはmaxBytesPerTriggerの制限に達するまでデータを処理します。
Note
既定では、 logRetentionDuration ソース テーブル内のトランザクションをクリーンアップし、ストリーミング クエリがそれらのバージョンを処理しようとすると、クエリはデータ損失を防ぐのに失敗します。 オプション failOnDataLoss を false に設定すると、失われたデータを無視して処理を続行できます。 「タイム トラベル クエリのデータ保持を構成する」を参照してください。
クラウド ストレージ コストを制御する
ストリーミング クエリには、 processingTime、 availableNow、 realTimeなど、コストと待機時間のバランスを取るために使用できるトリガー モードがいくつかあります。
クラウド ストレージ コストの制御に関するページを参照してください。