この記事では、Azure Databricks のレガシ視覚化について説明します。 SQL エディターまたはノートブックで視覚化を作成するときの現在の視覚化のサポートについては、 Databricks ノートブック と SQL エディターの視覚化に関する説明を参照してください。 AI/BI ダッシュボードでの視覚化の操作については、 AI/BI ダッシュボードの視覚化の種類に関する説明を参照してください。
Azure Databricks は Python および R の視覚化ライブラリもネイティブでサポートしているため、サードパーティのライブラリをインストールして使用することができます。
レガシ視覚化の作成
結果セルからレガシ視覚化を作成するには、+ をクリックして [レガシ視覚化] 選択します。
レガシ視覚化では、豊富なプロットの種類がサポートされています。
レガシのグラフの種類を選択して構成する
棒グラフを選択するには、棒グラフ アイコン  をクリックします。
をクリックします。
別のプロットの種類を選択するには、棒グラフ ![]() の右側にある をクリックして、プロットの種類を選択します。
の右側にある をクリックして、プロットの種類を選択します。
レガシーグラフツールバー
折れ線グラフと棒グラフには両方とも、豊富なクライアント側の対話機能をサポートする組み込みのツールバーがあります。
グラフを構成するには、[プロット オプション...] をクリックします。
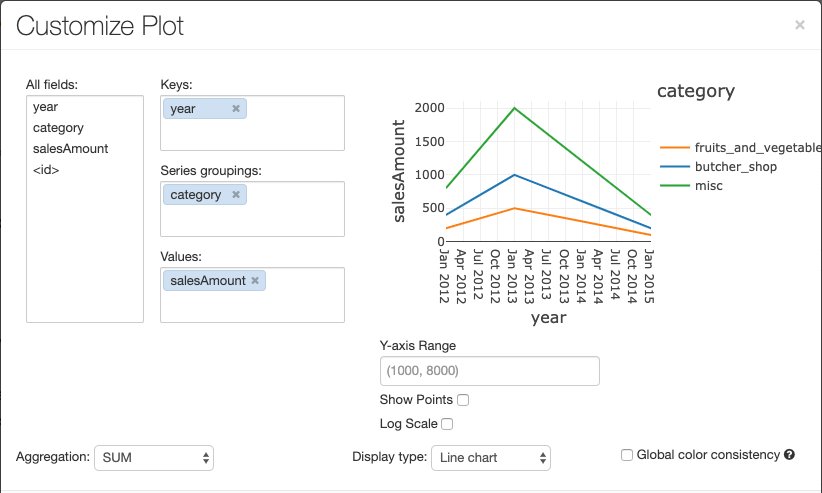
折れ線グラフには、いくつかのカスタム グラフ オプション (Y 軸の範囲の設定、点の表示と非表示、ログ スケールを使用した Y 軸の表示) があります。
レガシ グラフの種類の詳細については、以下を参照してください。
グラフ間の色の一貫性
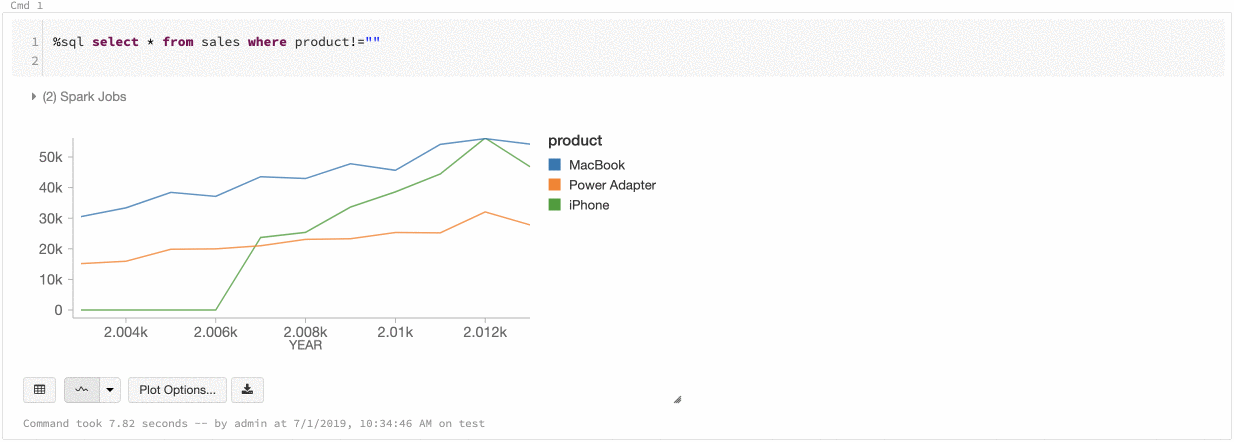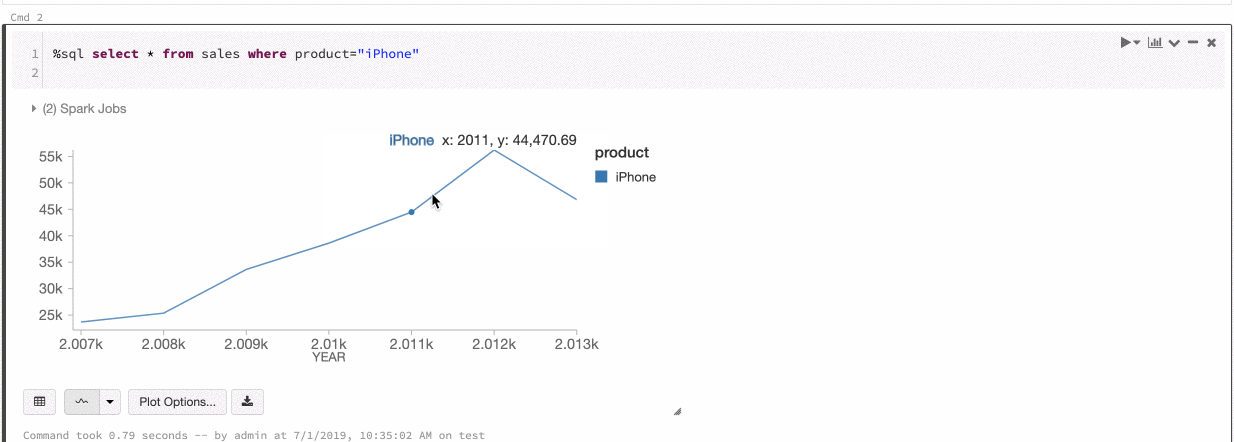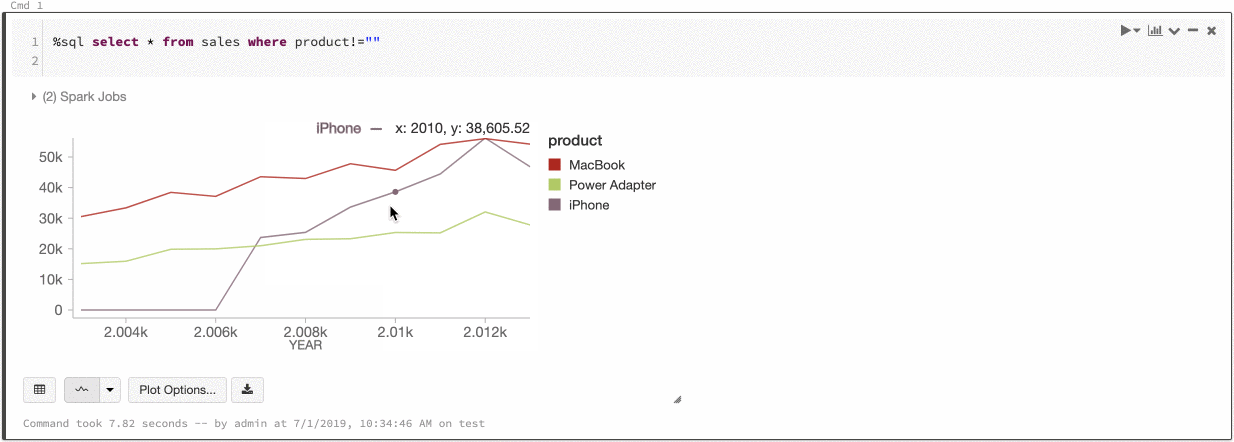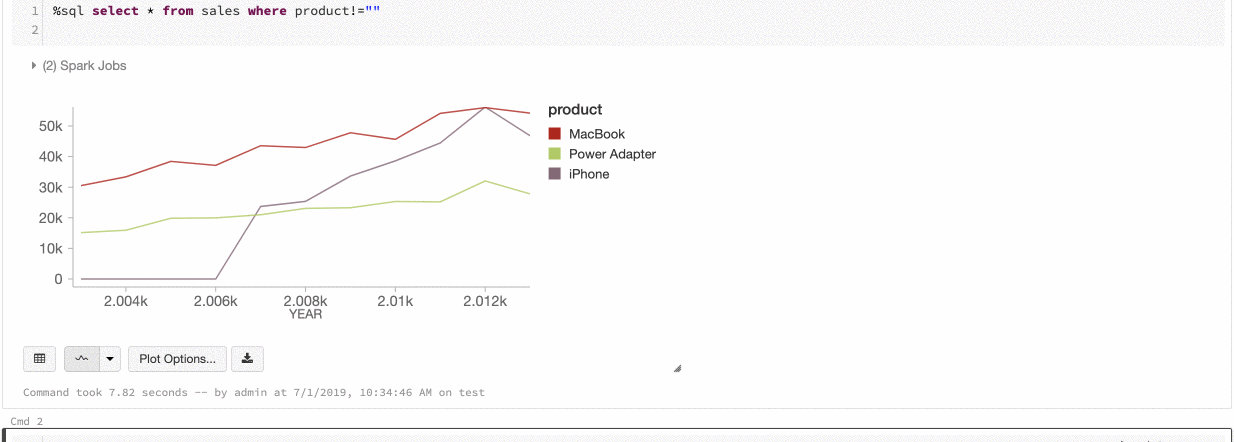
Azure Databricks では、レガシ グラフ間の色の一貫性として、系列セットとグローバルの 2 種類がサポートされています。
系列セットの色の一貫性によって、値は同じでも順番が異なる系列 (たとえば、A = ["Apple", "Orange", "Banana"] と B = ["Orange", "Banana", "Apple"]) がある場合、同じ値に同じ色が割り当てられます。 値はプロットの前に並べ替えられるので、どちらの凡例も同じ方法 (["Apple", "Banana", "Orange"]) で並べ替えられ、同じ値に同じ色が割り当てられます。 ただし、系列 C = ["Orange", "Banana"]がある場合は、セットが同じではないため、セット A との色の一貫性はありません。 並べ替えアルゴリズムは、最初の色をセット C の "Banana" に、2 番目の色をセット A の "Banana" に割り当てます。これらの系列の色を統一する場合は、グラフにグローバルな色の一貫性を持たせるように指定できます。
グローバルな色の一貫性では、どのような値が系列にあるかに関係なく、それぞれの値は常に同じ色にマップされます。 各グラフでこれを有効にするには、[Global color consistency] (グローバルの色の一貫性) チェック ボックスをオンにします。
注
この一貫性を実現するために、Azure Databricks は値から色に直接ハッシュ処理を行います。 競合 (2 つの値がまったく同じ色になる) を避けるために、色の大きなセットがハッシュ先になります。これには、見栄えの良い色、または簡単に区別できる色を保証できないという影響があります。色が多くなると、見た目が非常に似てくることは避けられません。
機械学習の視覚化
レガシ視覚化は、標準のグラフの種類に加えて、次の機械学習トレーニングのパラメーターと結果の視覚化もサポートしています。
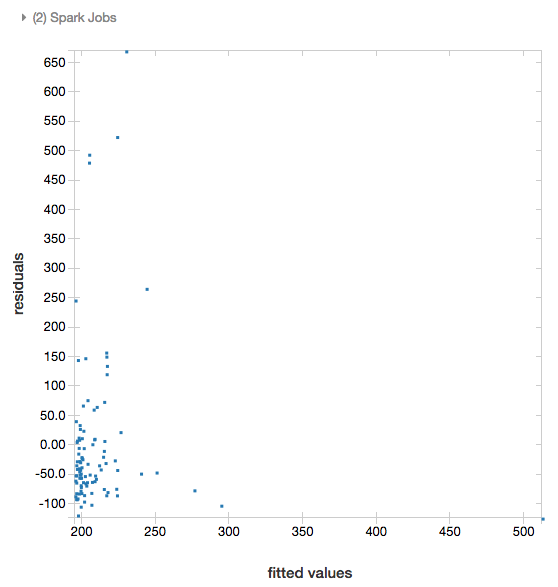
残差
線形回帰およびロジスティック回帰では、近似対残差プロットのレンダリングがサポートされています。 このプロットを取得するには、モデルと DataFrame を指定します。
次の例では、都市人口に対して住宅販売価格データへの線形回帰を実行した後、残差対近似データを表示します。
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
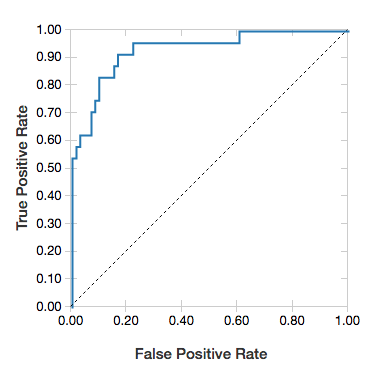
ROC 曲線
ロジスティック回帰の場合は、ROC 曲線をレンダリングできます。 このプロットを取得するには、モデル、fit メソッドに入力される準備されたデータ、およびパラメーター "ROC" を指定します。
次の例では、個人のさまざまな属性から、個人の収入が <5 万ドル>以下か、それとも 5 万ドルを超えるかを予測する分類子を開発します。 Adult データセットは国勢調査データに基づいており、48842 人の個人とその年収に関する情報で構成されています。
このセクションのサンプル コードには、ワンホット エンコードを使用しています。
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
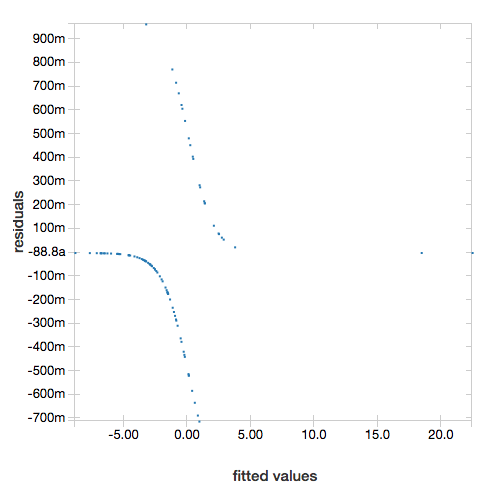
残差を表示するには、"ROC" パラメーターを省略します。
display(lrModel, preppedDataDF)
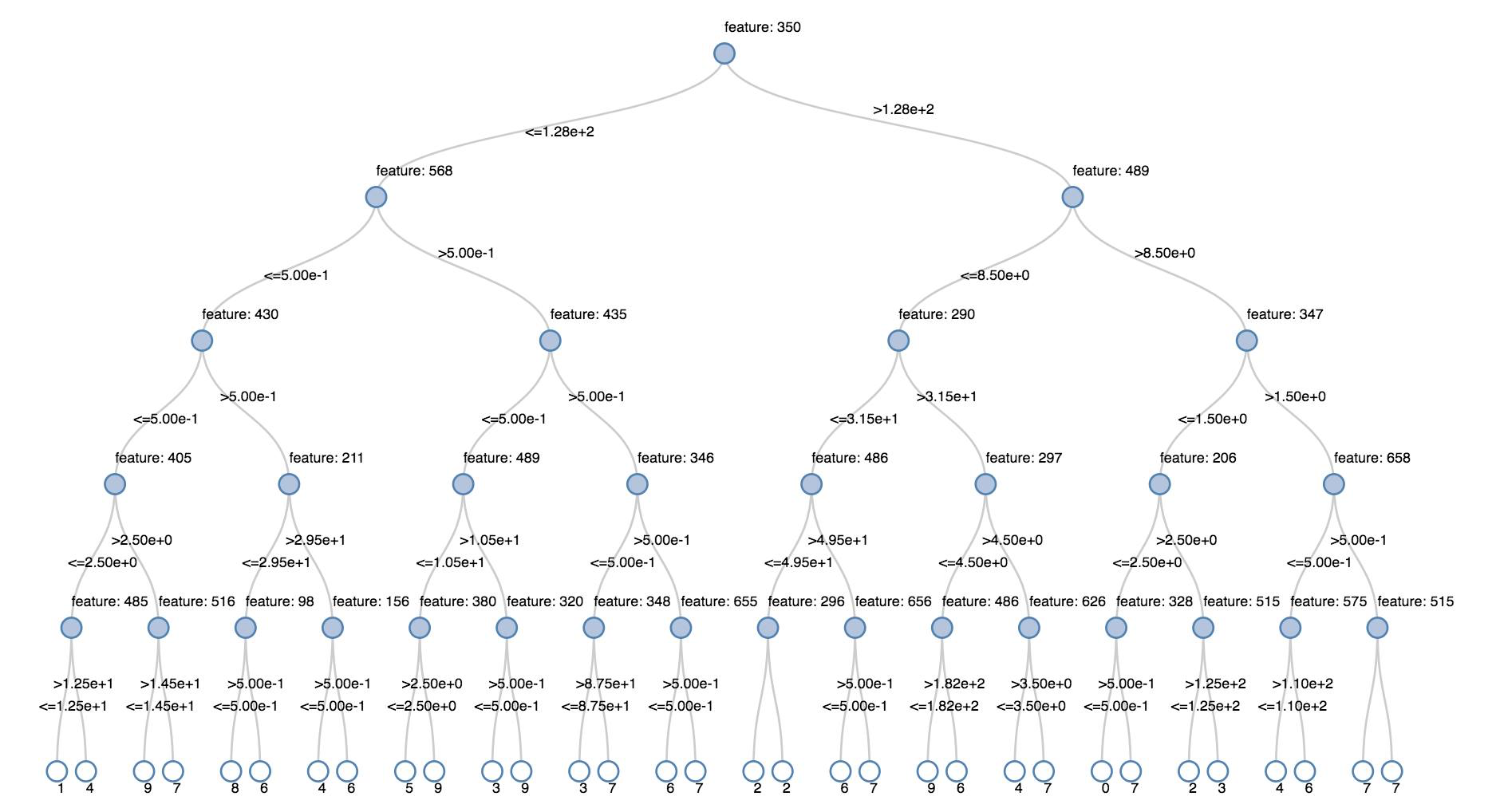
デシジョン ツリー
レガシ視覚化では、デシジョン ツリーのレンダリングがサポートされています。
この視覚化を取得するには、デシジョン ツリー モデルを指定します。
次の例では、手書き数字の画像の MNIST データセットから数字 (0 ~ 9) を認識するようにツリーをトレーニングした後、ツリーを表示します。
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
スカラ (プログラミング言語)
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
構造化ストリーミング DataFrames
ストリーミング クエリの結果をリアルタイムで視覚化するには、Scala および Python で構造化ストリーミング DataFrameを display します。
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
スカラ (プログラミング言語)
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display では次の省略可能なパラメーターがサポートされます。
-
streamName: ストリーミング クエリの名前。 -
trigger(Scale) とprocessingTime(Python): ストリーミング クエリの実行頻度を定義します。 指定しない場合、前の処理が完了するとすぐに、新しいデータが使用可能かどうかがシステムによって確認されます。 運用環境のコストを削減するために、Databricks では、常にトリガー間隔を設定することが推奨されています。 既定のトリガー間隔は 500 ミリ秒です。 -
checkpointLocation: システムがすべてのチェックポイント情報を書き込む場所。 指定されていない場合、システムは自動的に一時チェックポイントの場所を DBFS に生成します。 ストリームが中断された場所からデータの処理を続行するには、チェックポイントの場所を指定する必要があります。 Databricks では、運用環境では "常に"checkpointLocationオプションを指定することが推奨されています。
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
スカラ (プログラミング言語)
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
これらのパラメーターの詳細については、ストリーミング クエリの開始に関するセクションを参照してください。
displayHTML 関数
Azure Databricks プログラミング言語ノートブック (Python、R、Scala) は、displayHTML 関数を使用した HTML グラフィックスをサポートしており、関数に任意の HTML、CSS、または JavaScript コードを渡すことができます。 この関数は、D3 などの JavaScript ライブラリを使用した対話型グラフィックスをサポートします。
displayHTML の使用例については、以下を参照してください。
注
displayHTML iframe はドメイン databricksusercontent.com から提供され、iframe サンドボックスには allow-same-origin 属性が含まれます。
databricksusercontent.com はブラウザーからアクセスできる必要があります。 現在、企業ネットワークによってブロックされている場合、許可リストに追加する必要があります。
イメージ
画像データ型を含む列は、リッチ HTML としてレンダリングされます。 Azure Databricks は DataFrame 列に対して、Spark の ImageSchema に一致するように画像サムネイルレンダリングしようとします。
サムネイル レンダリングは、spark.read.format('image') 関数を使用して正常に読み込まれたすべての画像に対して機能します。 他の方法で生成された画像値の場合、Azure Databricks は 1、3、または 4 チャネルの画像 (各チャネルが 1 バイトで構成される) のレンダリングをサポートしますが、次の制約があります。
-
1 チャネル画像:
modeフィールドは 0 に等しくなければなりません。height、width、nChannelsの各フィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。 -
3 チャネル画像:
modeフィールドは 16 に等しくなければなりません。height、width、nChannelsの各フィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。dataフィールドには 3 バイトのチャンクでピクセル データを含める必要があり、各ピクセルのチャネルの順序は(blue, green, red)です。 -
4 チャネル画像:
modeフィールドは 24 に等しくなければなりません。height、width、nChannelsの各フィールドは、dataフィールドのバイナリ画像データを正確に記述する必要があります。dataフィールドには 4 バイトのチャンクでピクセル データを含める必要があり、各ピクセルのチャネルの順序は(blue, green, red, alpha)です。
例
いくつかの画像を含むフォルダーがあるとします。

画像を DataFrame に読み込んでから DataFrame を表示した場合、Azure Databricks では画像のサムネイルをレンダリングします。
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Python での視覚化
このセクションの内容は次のとおりです。
Seaborn
他の Python ライブラリを使用してプロットを生成することもできます。 Databricks Runtime には seaborn 視覚化ライブラリが含まれています。 seaborn プロットを作成するには、ライブラリをインポートし、プロットを作成して、プロットを display 関数に渡します。
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
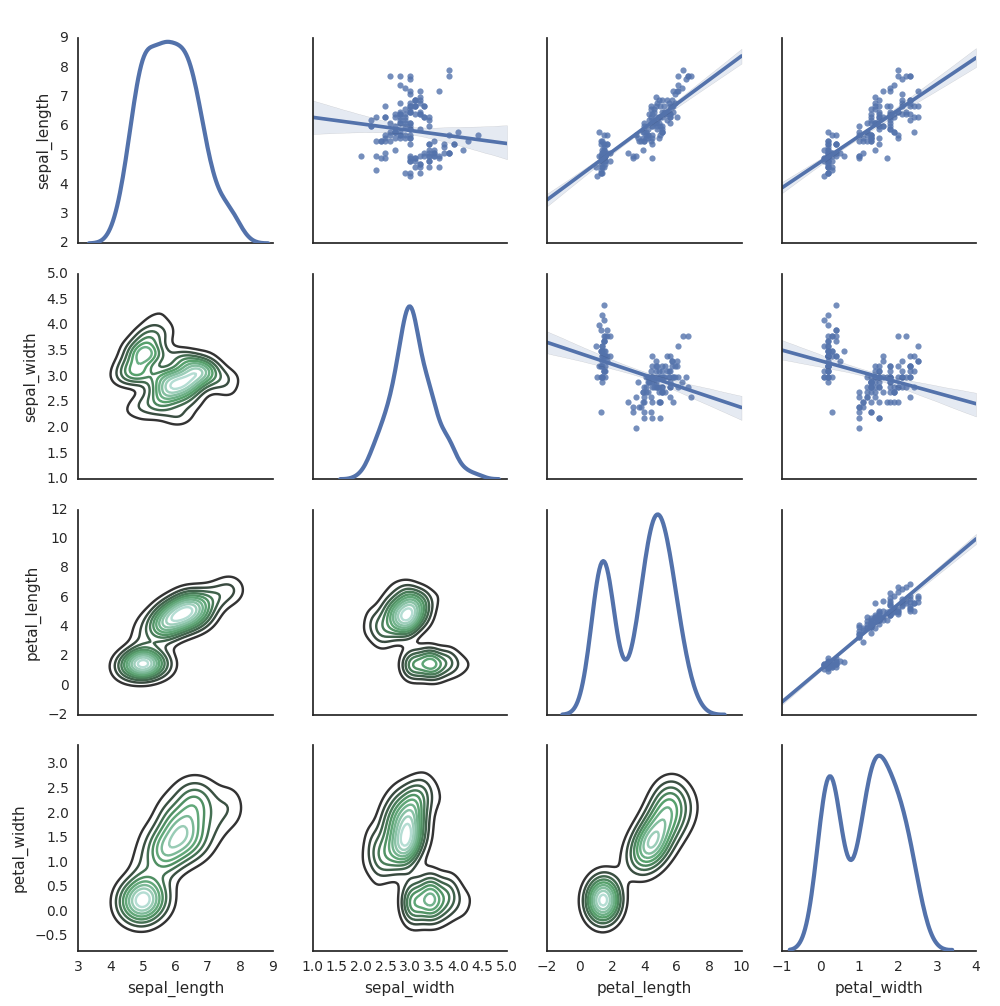
その他の Python ライブラリ
R での視覚化
R でデータをプロットするには、次のように display 関数を使用します。
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
既定の R の plot 関数を使用できます。
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
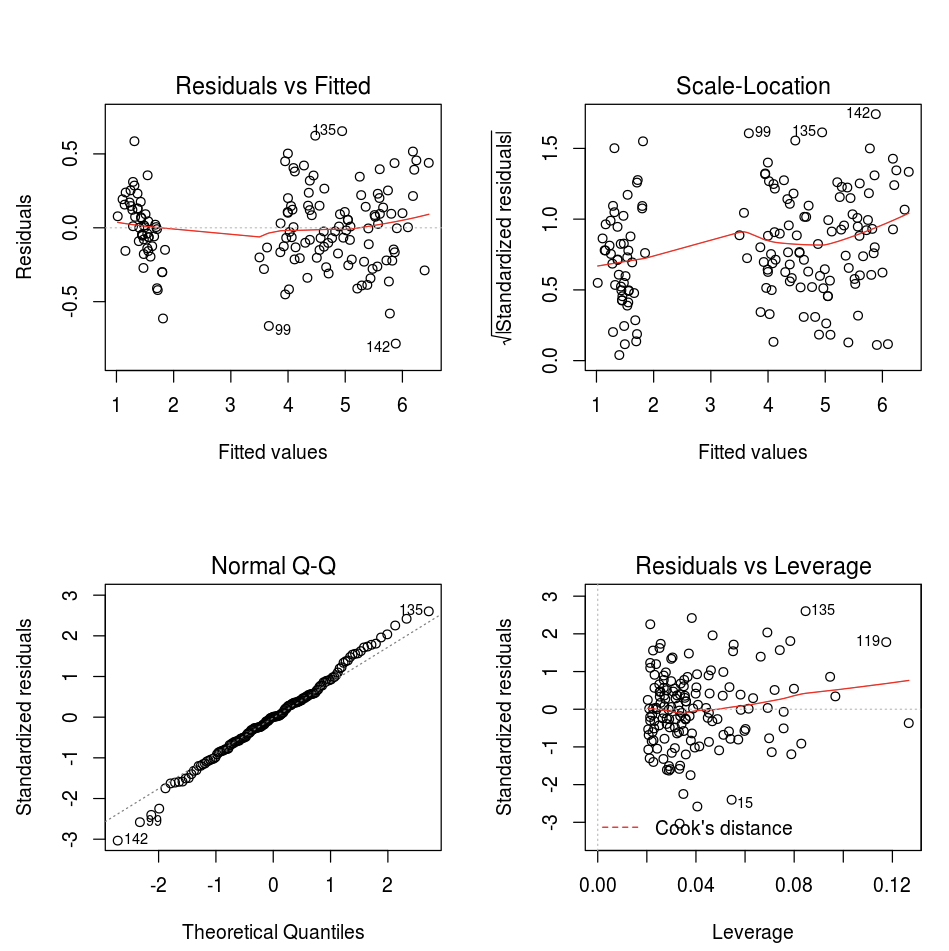
任意の R 視覚化パッケージを使用することもできます。 R ノートブックは結果のプロットを .png としてキャプチャし、インラインで表示します。
このセクションの内容は次のとおりです。
ラティス構造
Lattice パッケージは、トレリス グラフをサポートします。これは、変数または変数間のリレーションシップを 1 つ以上の変数に対する条件に応じて表示するグラフです。
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
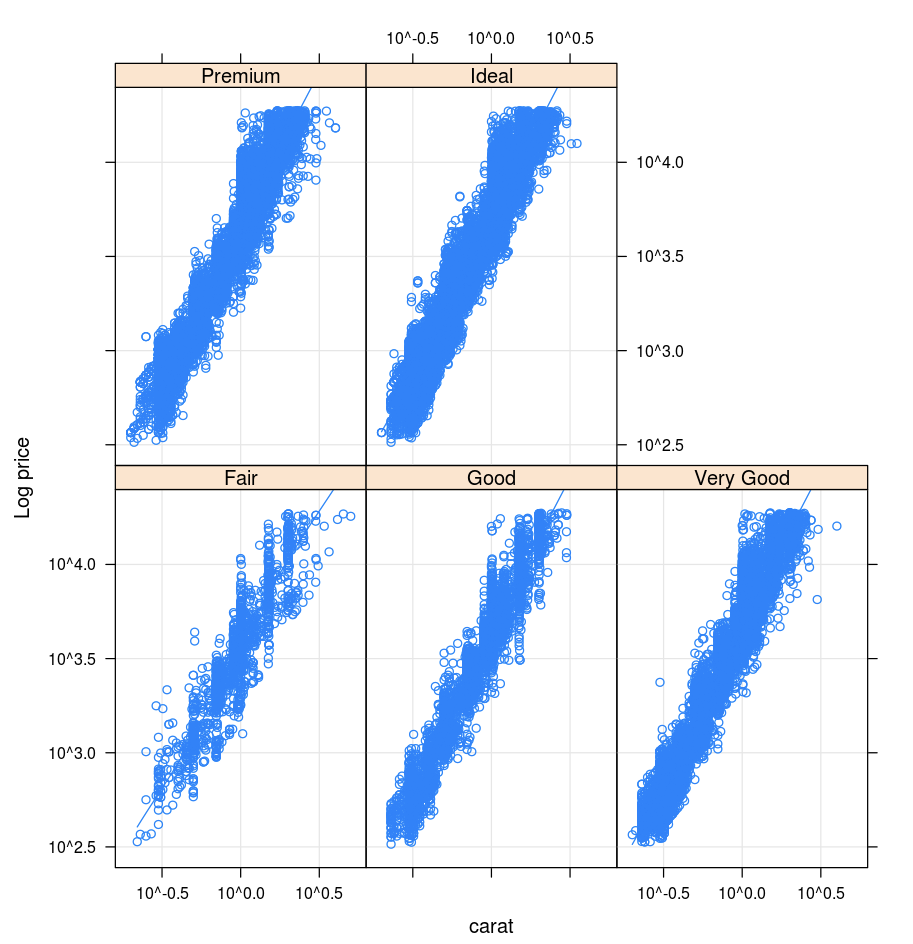
DandEFA
DandEFA パッケージでは、dandelion プロットがサポートされています。
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
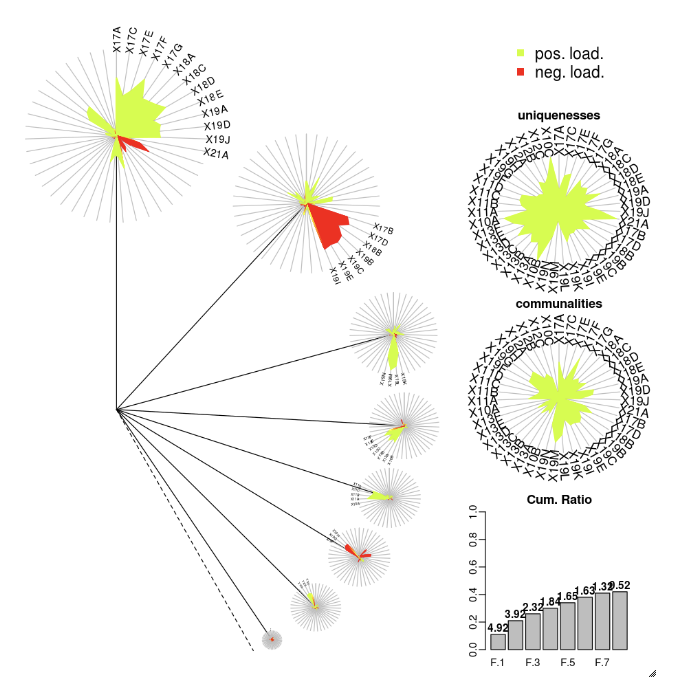
プロット
Plotly R パッケージは、htmlwidgets for R に依存しています。インストール手順とノートブックについては、「htmlwidgets」を参照してください。
その他の R ライブラリ
Scala での視覚化
Scala でデータをプロットするには、次のように display 関数を使用します。
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Python と Scala の徹底分析ノートブック
Python 視覚化の詳細については、次のノートブックを参照してください。
Scala 視覚化の詳細については、次のノートブックを参照してください。