Azure Databricks ジョブ設定の構成
この記事では、ジョブ UI で Azure Databricks ジョブと個々のジョブ タスクを構成する方法について詳しく説明します。 Databricks CLI を使用してジョブの設定を編集する方法を確認するには、CLI コマンド databricks jobs update -h を実行します。 Jobs API の使用方法については、「Jobs API」をご覧ください。
一部の構成オプションはジョブで使用でき、その他のオプションは個々のタスクで使用できます。 たとえば、最大同時実行数はジョブに対してのみ設定できますが、再試行ポリシーはタスクごとに定義します。
ジョブを編集する
ジョブの構成を変更するには:
- サイドバーの
![[ワークフロー] アイコン](../../_static/images/icons/workflows-icon.png) [ワークフロー] をクリックします。
[ワークフロー] をクリックします。 - [名前] 列で、ジョブ名をクリックします。
サイド パネルにジョブの詳細が表示されます。 ジョブのトリガー、コンピューティング構成、通知、同時実行の最大数、期間のしきい値の構成、タグの追加または変更を行うことができます。 ジョブのアクセス制御が有効になっている場合は、ジョブのアクセス許可を編集することもできます。
すべてのジョブ タスクにパラメーターを追加する
キーワード引数を受け入れるように構成された Python ホイール ファイルなど、キー値パラメーターを受け入れるジョブのタスクに渡されるパラメーターをジョブに対して構成できます。 ジョブ レベルで設定されたパラメーターは、タスクレベルで構成されたパラメーターに追加されます。 タスクに渡されたジョブ パラメーターは、タスクに対して構成されたすべてのパラメーターと共に、タスク構成に表示されます。
また、JAR や Spark Submit タスクのようなキー値パラメーターを使って構成されていないタスクにジョブ パラメーターを渡すこともできます。 これらのタスクにジョブ パラメーターを渡すには、引数を {{job.parameters.[name]}} という形式にして、[name] をパラメーターを特定する key に置き換えます。
ジョブ パラメーターはタスク パラメーターよりも優先されます。 ジョブ パラメーターとタスク パラメーターのキーが同じ場合、ジョブ パラメーターがタスク パラメーターをオーバーライドします。
異なるパラメーターでジョブを実行するとき、またはジョブの実行を修復するときに、構成されたジョブ パラメーターをオーバーライドすることや、新しいジョブ パラメーターを追加することができます。
また、動的値参照のセットを使って、ジョブとタスクに関するコンテキストを共有することもできます。
ジョブ パラメーターを追加するには、[ジョブの詳細] サイド パネルで [パラメーターの編集] をクリックし、各パラメーターのキーと既定値を指定します。 使用可能な動的値参照を一覧表示するには、[Browse dynamic values] (動的値の参照) をクリックします。
ジョブにタグを追加する
ジョブにラベルまたは key:value 属性を追加するには、ジョブを編集するときに "タグ" を追加できます。 タグを使用して、[ジョブ] リストのジョブをフィルター処理できます。たとえば、department タグを使用して、特定の部署に属するすべてのジョブをフィルター処理できます。
Note
ジョブ タグは、個人を特定できる情報やパスワードなどの機密情報を格納するようには設計されていないため、Databricks では機密以外の値にのみタグを使用することをお勧めします。
タグはジョブの実行時に作成されたジョブ クラスターにも反映されるため、既存のクラスター監視でタグを使用できます。
タグを追加または編集するには、[ジョブの詳細] サイド パネルで [+ タグ] をクリックします。 タグは、キーと値、またはラベルとして追加できます。 ラベルを追加するには、"キー" フィールドにラベルを入力し、"値" フィールドは空のままにします。
共有クラスターを構成する
クラスターに関連付けられているタスクを表示するには、[タスク] タブをクリックし、サイド パネルでクラスターをポイントします。 関連するすべてのタスクのクラスター構成を変更するには、クラスターの [構成] をクリックします。 関連するすべてのタスクに新しいクラスターを構成するには、クラスターの [スワップ] をクリックします。
ジョブへのアクセスを制御する
ジョブのアクセス制御により、ジョブの所有者と管理者は、ジョブに対してきめ細かいアクセス許可を付与できます。 ジョブの所有者は、ジョブの結果を表示できる他のユーザーまたはグループを選択できます。 所有者は、ジョブの実行 (今すぐ実行と実行の取り消しのアクセス許可) を管理できるユーザーを選択することもできます。
ジョブ権限レベルについては、「ジョブ ACL」を参照してください。
ジョブに対するアクセス許可を管理するには、それに対する管理可能または所有者アクセス許可が必要です。
サイドバーで [ジョブ実行] をクリックします。
ジョブの名前をクリックします。
[ジョブの詳細] パネルで [アクセス許可の編集] をクリックします。
[アクセス許可の設定] で、[ユーザー、グループ、またはサービス プリンシパルの選択] ドロップダウン メニューをクリックし、ユーザー、グループ、またはサービス プリンシパルを選択します。
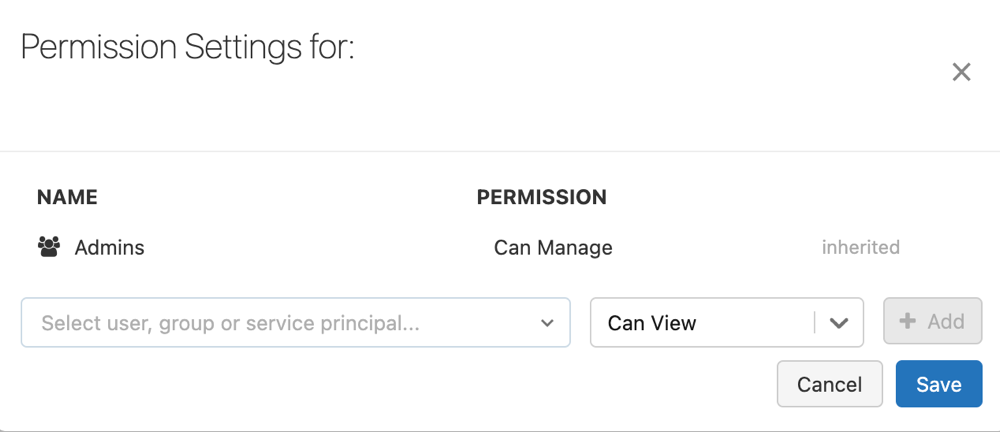
[追加] をクリックします。
[保存] をクリックします。
ジョブ所有者を管理する
既定では、ジョブ作成者には所有者アクセス許可があり、そのジョブの実行者設定内にあるユーザーです。 ジョブは、[実行するアカウント名] 設定のユーザーの ID として実行されます。 [実行するアカウント名] 設定の詳細については、「ジョブをサービス プリンシパルとして実行する」を参照してください。
ワークスペース管理者は、ジョブの所有者を自分自身に変更できます。 所有権が譲渡されると、前の所有者に、管理可能アクセス許可が付与されます
Note
ワークスペースの RestrictWorkspaceAdmins 設定が ALLOW ALL に設定されている場合、ワークスペース管理者はジョブ所有者をワークスペース内の任意のユーザーまたはサービス プリンシパルに変更できます。 ワークスペース管理者がジョブ所有者を自分自身にのみ変更できるように制限するには、「ワークスペース管理者を制限する」を参照してください。
同時実行の最大数を構成する
[詳細設定] の下にある [同時実行の編集] をクリックして、このジョブの並列実行の最大数を設定します。 新しい実行を開始しようとしているときに、ジョブがアクティブな実行の最大数に既に達している場合は、Azure Databricks によって実行がスキップされます。 複数の同じジョブを同時実行するには、この値を既定値の 1 より大きい値に設定します。 これは通常、たとえば、頻繁に実行されるスケジュールでジョブをトリガーし、連続した実行を互いにオーバーラップさせたい場合や、入力パラメーターが異なる複数の実行をトリガーしたい場合などに便利です。
ジョブ実行のキューを有効にする
コンカレンシーの制限のためにすぐに実行できないジョブの実行をキューに配置して、後で実行できるようにするには、[詳細設定] の下にある [キュー] トグルを クリックします。 「同時実行の制限によりジョブを実行できない場合の対処方法」を参照してください。
Note
キューは、2024 年 4 月 15 日以降に UI を使用して作成されたジョブに対して既定で有効になっています。
ジョブの予想される完了時間またはタイムアウトを構成する
ジョブの予想完了時間やジョブの最大完了時間など、ジョブの省略可能な期間しきい値を構成できます。 期間のしきい値を構成するには、[期間のしきい値の設定] をクリックします。
ジョブの予想完了時間を構成するには、[警告] フィールドに予想期間を入力します。 ジョブがこのしきい値を超えた場合は、実行速度の遅いジョブの通知を構成できます。 「実行時間の遅いジョブまたは遅延ジョブの通知を構成する」を参照してください。
ジョブの最大完了時間を構成するには、[タイムアウト] フィールドに最大期間を入力します。 この時間内にジョブが完了しなかった場合、Azure Databricks によって状態が "タイムアウト" に設定され、ジョブが停止します。
タスクを編集する
タスク構成オプションを設定するには:
- サイドバーの [ワークフロー] をクリックします。
- [名前] 列で、ジョブ名をクリックします。
- [タスク] タブをクリックし、編集するタスクを選択します。
タスクの依存関係を定義する
[依存先] ドロップダウン メニューを使用して、ジョブ内のタスクの実行順を定義できます。 このフィールドは、ジョブ内の 1 つ以上のタスクに設定できます。
Note
ジョブが 1 つのタスクのみで構成されている場合は、[依存先] は表示されません。
タスクの依存関係を構成すると、ジョブ スケジューラで実行順序を表す一般的な方法である、タスク実行の有向非巡回グラフ (DAG) が作成されます。 たとえば、次の 4 つのタスクで構成されるジョブについて考えてみます。
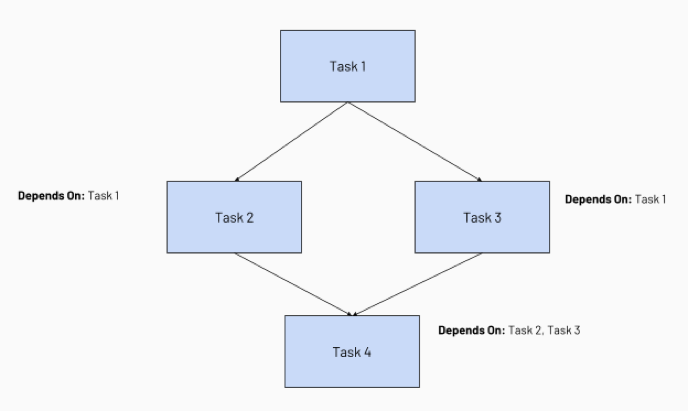
- タスク 1 はルート タスクで、他のどのタスクにも依存しません。
- タスク 2 とタスク 3 は、最初に完了するタスク 1 に依存します。
- 最後に、タスク 4 は、正常に完了するタスク 2 とタスク 3 に依存します。
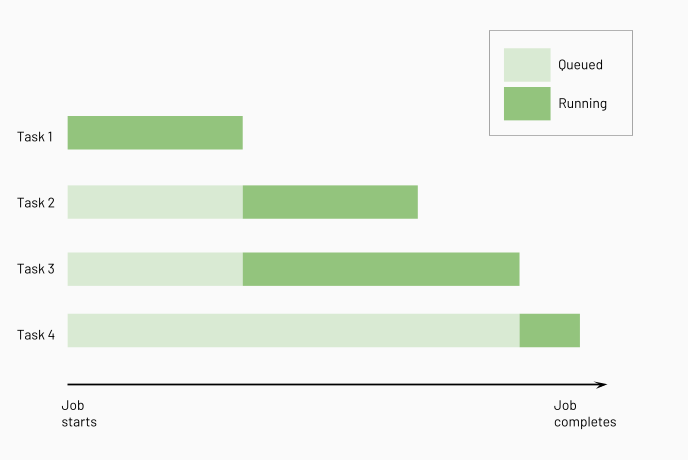
Azure Databricks は、下流のタスクを実行する前に上流のタスクを実行して、できるだけ多くのタスクを並列処理で実行します。 次の図は、これらのタスクの処理の順序を示しています。
タスクのクラスターを構成する
タスクが実行されるクラスターを構成するには、[クラスター] ドロップダウン メニューをクリックします。 共有ジョブ クラスターを編集することはできますが、共有クラスターが他のタスクでまだ使用されている場合は、それを削除することはできません。
タスクを実行するためのクラスターの選択と構成の詳細については、「ジョブで Azure Databricks コンピューティングを使用する」を参照してください。
依存ライブラリを構成する
タスクを実行する前に、依存ライブラリがクラスターにインストールされます。 すべてのタスクの依存関係を設定して、実行を開始する前にそれらが確実にインストールされるようにする必要があります。 依存関係を指定するには、「ライブラリの依存関係を管理する」の推奨事項に従います。
タスクの予想される完了時間またはタイムアウトを構成する
タスクの予想完了時間やジョブの最大完了時間など、タスクの省略可能な期間しきい値を構成できます。 期間のしきい値を構成するには、[期間のしきい値] をクリックします。
タスクの予想完了時間を構成するには、[警告] フィールドに期間を入力します。 タスクがこのしきい値を超えると、イベントがトリガーされます。 このイベントを使用して、タスクの実行速度が遅い場合に通知できます。 「実行時間の遅いジョブまたは遅延ジョブの通知を構成する」を参照してください。
タスクブの最大完了時間を構成するには、[タイムアウト] フィールドに最大期間を入力します。 この時間内にタスクが完了しなかった場合、Azure Databricks によって状態が "タイムアウト" に設定されます。
タスクの再試行ポリシーを構成する
タスクの実行が失敗したときに再試行するタイミングと回数を決定するポリシーを構成するには、[再試行] の横にある [+ 追加] をクリックします。 再試行間隔は、失敗した実行の開始からその後の再試行実行までで計算されます (ミリ秒単位)。
Note
タイムアウトと再試行の両方を構成すると、タイムアウトは再試行ごとに適用されます。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示