HDInsight 上の Apache Kafka® と AKS 上の HDInsight 上の Apache Flink® の使用
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 この発表 で、についてさらに知ってください。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、AskHDInsight に詳細を記載したリクエストを送信し、Azure HDInsight Communityをフォローして最新情報を受け取ってください。
Apache Flink のよく知られているユース ケースは、ストリーム分析です。 多くのユーザーが一般的に選ぶのは、Apache Kafka を使用して取り込まれるデータストリームです。 Flink と Kafka の一般的なインストールは、Flink ジョブで使用できるイベント ストリームが Kafka にプッシュされることから始まります。
この例では、Flink 1.17.0 を実行する AKS クラスターで HDInsight を使用して、Kafka トピックを使用して生成するストリーミング データを処理します。
手記
FlinkKafkaConsumer は非推奨となり、Flink 1.17 で削除されます。代わりに KafkaSource を使用してください。 FlinkKafkaProducer は非推奨となり、Flink 1.15 で削除されます。代わりに KafkaSink を使用してください。
前提 条件
Kafka と Flink の両方が同じ VNet 内にある必要があります。または、2 つのクラスター間に vnet ピアリングが存在する必要があります。
VNetの作成。
同じ VNetに Kafka クラスターを作成します。 現在の使用状況に基づいて、HDInsight で Kafka 3.2 または 2.4 を選択できます。
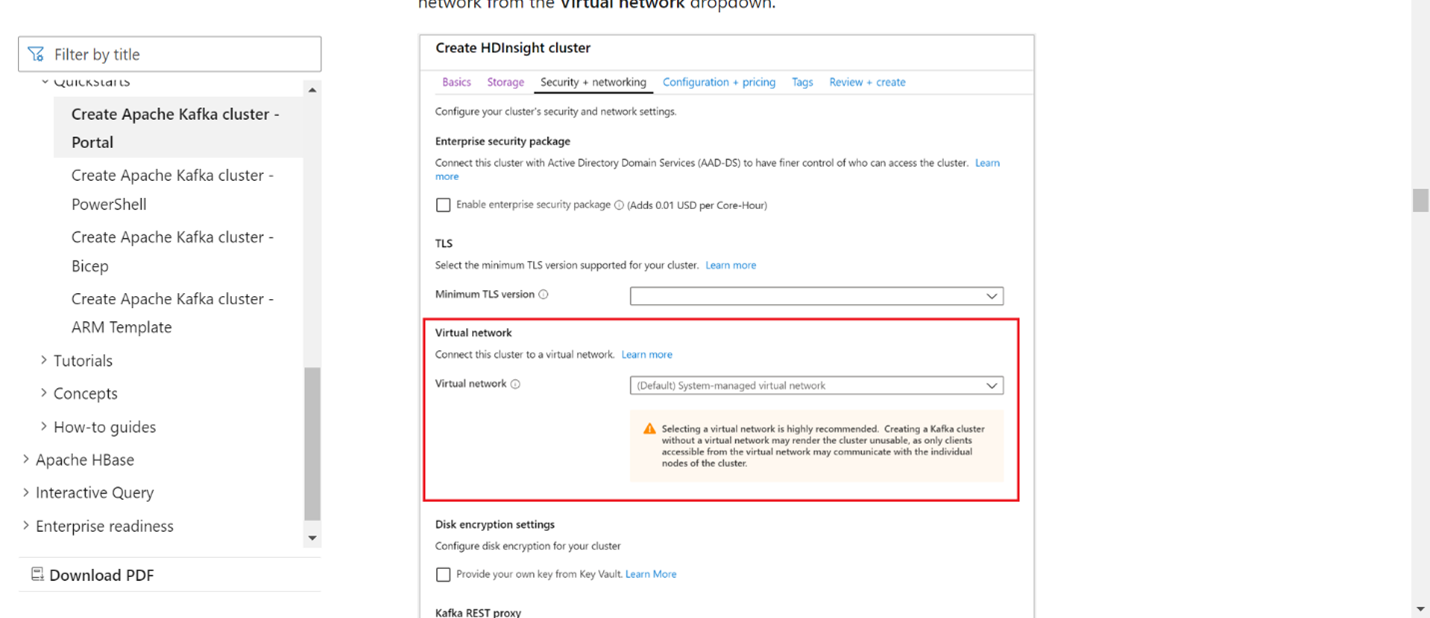
仮想ネットワーク セクションに VNet の詳細を追加します。
同じ VNet を使用して AKS クラスター プール に HDInsight を作成します。
作成したクラスター プールへの Flink クラスターを作成します。

Apache Kafka コネクタ
Flink には、Apache Kafka Connector が用意されており、Kafka トピックからのデータの読み取りと Kafka トピックへのデータの書き込みを 1 回だけ保証します。
Maven 依存関係
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Kafka シンクの構築
Kafka シンクには、KafkaSink のインスタンスを構築するためのビルダー クラスが用意されています。 これを使用してシンクを構築し、AKS 上の HDInsight で実行されている Flink クラスターと共に使用します
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Java プログラム Event.javaの作成
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
jar をパッケージ化し、Flink にジョブを送信する
Webssh で jar をアップロードし、jar を送信します

Flink ダッシュボード UI の場合

トピックを作成する - Kafka をクリックします

トピックを消費する - Kafkaのイベントを処理する

参考
- Apache Kafka コネクタ
- Apache、Apache Kafka、Kafka、Apache Flink、Flink、および関連するオープンソースプロジェクト名は、Apache Software Foundation (ASF) の商標 です。