HDInsight on AKS での Apache Spark™ とは (プレビュー)
Note
Azure HDInsight on AKS は 2025 年 1 月 31 日に廃止されます。 2025 年 1 月 31 日より前に、ワークロードを Microsoft Fabric または同等の Azure 製品に移行することで、ワークロードの突然の終了を回避する必要があります。 サブスクリプション上に残っているクラスターは停止され、ホストから削除されることになります。
提供終了日までは基本サポートのみが利用できます。
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、「Microsoft HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティをフォローしてください。
Apache Spark™ は、ビッグデータ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする並列処理フレームワークです。
Apache Spark™ には、クラスターの計算処理をインメモリで行うための基本的な要素が備わっています。 Spark ジョブは、データをメモリに読み込んでキャッシュし、それを繰り返しクエリできます。 メモリ内計算は、Hadoop 分散ファイル システム (HDFS) 経由でデータを共有する Hadoop などのディスクベースのアプリケーションよりも高速です。 Apache Spark を使用すると、Scala および Python のプログラミング言語と統合して、分散データ セットをローカル コレクションのように扱うことができます。 計算内容をすべて map 処理と reduce 処理に分ける必要がありません。
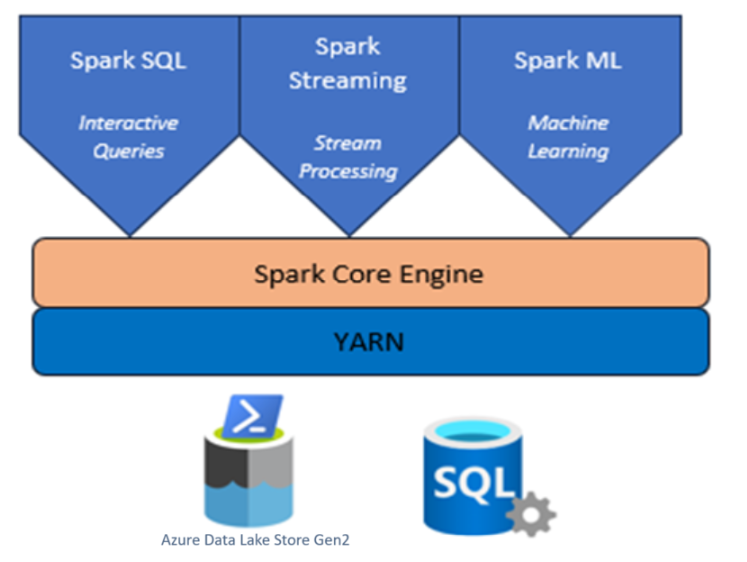
HDInsight on AKS を使用した Apache Spark クラスター
Azure HDInsight は、全範囲に対応した、オープンソースのエンタープライズ向けマネージド分析サービスです。
Azure HDInsight on AKS の Apache Spark™ は、Microsoft Azure のマネージド Spark サービスです。 Azure HDInsight on AKS で Apache Spark を使用すると、すべてのデータを Azure 内に格納して処理することができます。 HDInsight の Spark クラスターは、Azure Data Lake Storage Gen2 と互換性があり、既存のデータ ストアに Spark の処理を適用できます。
HDInsight on AKS の Apache Spark フレームワークにより、メモリ内処理を使用した、高速のデータ分析とクラスター コンピューティングが可能になります。 Jupyter Notebook を使用すると、データを対話的に操作したり、コードと Markdown テキストとを結合したり、簡単な視覚化を行ったりすることができます。
HDInsight での AKS 上の Apache Spark は、ポッドとして複数のコンポーネントで構成されています。
クラスター コントローラー
クラスター コントローラーは、それぞれのサービスのインストールと管理を担当します。 Spark クラスターにさまざまなコントローラーがインストールされて管理されます。
Apache Spark サービス コンポーネント
Zookeeper サービス: 3 ノードの Zookeeper クラスターは、他のサービスのための分散コーディネーターまたは高可用性ストレージとして機能します。
Yarn サービス: Hadoop Yarn クラスター、Spark ジョブは Yarn アプリケーションとしてクラスター内でスケジュールされます。
クライアント インターフェイス: HDInsight on AKS の Apache Spark クラスターには、さまざまなクライアント インターフェイスが用意されています。 Livy Server、Jupyter Notebook、Spark History Server では、HDInsight on AKS ユーザーに Spark サービスが提供されます。
リファレンス
- Apache、Apache Spark、Spark、および関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。