Data Lake Tools for Visual Studio を使用して Apache Hive クエリを実行する
Data Lake Tools for Visual Studio を使って Apache Hive のクエリを実行する方法について説明します。 Data Lake Tools を使うと、Azure HDInsight 上の Apache Hadoop に対する Hive クエリを簡単に作成、送信、および監視できます。
前提条件
HDInsight の Apache Hadoop クラスター。 この項目の作成については、「Resource Manager テンプレートを使用して Azure HDInsight で Apache Hadoop クラスターを作成する」を参照してください。
Visual Studio. この記事の手順では、Visual Studio 2019 を使用します。
HDInsight Tools for Visual Studio または Azure Data Lake Tools for Visual Studio ツールのインストールと構成の詳細については、「Data Lake Tools for Visual Studio のインストール」を参照してください。
Visual Studio を使用して Apache Hive クエリを実行する
Hive クエリを作成して実行するためのオプションは 2 つあります。
- アドホック クエリを作成する。
- Hive アプリケーションを作成する。
アドホック Hive クエリを作成する
アドホック クエリは [バッチ] または [対話型] モードで実行できます。
Visual Studio を起動し、[コードなしで続行] を選択します。
[サーバーエクスプローラー] で、[Azure] を右クリックし[Microsoft Azureサブスクリプションに接続..] を選択し、サインイン処理を完了します。
[HDInsight] を展開し、クエリを実行するクラスターを右クリックして、[Hive クエリの作成] を選択します。
次の Hive クエリを入力します。
SELECT * FROM hivesampletable;[実行] を選択します。 実行モードの既定値は [対話型] です。
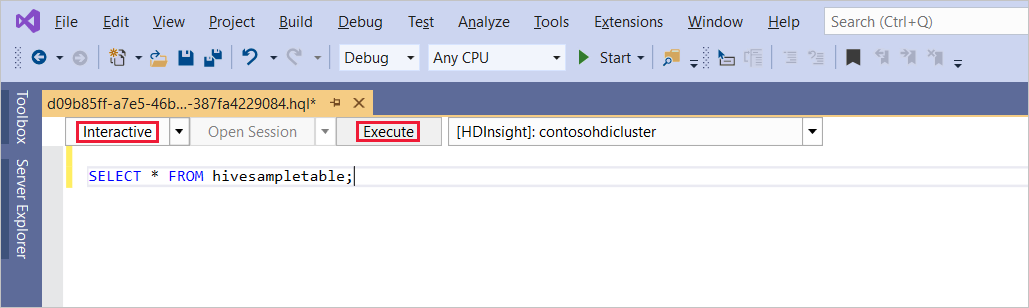
同じクエリを [バッチ] モードで実行するには、ドロップダウン リストを [対話型] から [バッチ] に切り替えます。 実行ボタンが [実行] から [送信] に変わります。

Hive エディターは IntelliSense をサポートしています。 Data Lake Tools for Visual Studio では、Hive スクリプトの編集時にリモート メタデータの読み込みをサポートします。 たとえば、
SELECT * FROMと入力すると、IntelliSense によってテーブル名の候補が一覧表示されます。 テーブル名を指定すると、Intellisense によって列名が一覧表示されます。 このツールは、Hive の DML ステートメント、サブクエリ、および組み込みの UDF の大半をサポートします。 IntelliSense は、HDInsight のツール バーで選択されているクラスターのメタデータのみを推奨します。クエリ ツール バー (クエリ タブとクエリ テキストにはさまれた領域) で、[送信] を選択するか、[送信] の横にあるプルダウン矢印を選択して、プルダウン リストから [詳細] を選択します。 後者のオプションを選択した場合は、次の手順を実行します。
詳細送信オプションを選択した場合は、[スクリプトの送信] ダイアログ ボックスで、[ジョブ名]、[引数]、[追加の構成]、[状態ディレクトリ] を構成します。 次に [送信] を選択します。
![[スクリプトの送信] ダイアログ ボックス、HDInsight Hadoop Hive クエリ。](media/apache-hadoop-use-hive-visual-studio/vs-tools-submit-jobs-advanced.png)
Hive アプリケーションを作成する
Hive アプリケーションを作成して Hive クエリを実行するには、次の手順に従います。
Visual Studio を開きます。
[開始] ウィンドウで、 [新しいプロジェクトの作成] を選択します。
[新しいプロジェクトの作成] ウィンドウの [テンプレートの検索] ボックスで「Hive」と入力します。 次に [Hive アプリケーション] を選択し、 [次へ] を選択します。
[新しいプロジェクトの構成] ウィンドウで、[プロジェクト名] を入力し、新しいプロジェクトの [場所] を選択または作成し、[作成] を選択します。
このプロジェクトで作成した Script.hql ファイルを開き、次の HiveQL ステートメントを貼り付けます。
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;これらのステートメントによって次のアクションが実行されます。
DROP TABLE: テーブルが存在する場合は削除します。CREATE EXTERNAL TABLE: Hive に新しい "外部" テーブルを作成します。 外部テーブルは Hive にテーブル定義のみを格納します。 (データは元の場所に残されます。)Note
基になるデータが、MapReduce ジョブや Azure サービスなどの外部ソースによって更新されると考えられる場合は、外部テーブルを使用する必要があります。
外部テーブルを削除しても、データは削除されません。テーブル定義のみが削除されます。
ROW FORMAT: データの形式を Hive に伝えます。 ここでは、各ログのフィールドは、スペースで区切られています。STORED AS TEXTFILE LOCATION: データの格納先 (example/data ディレクトリ) と、データがテキストとして格納されていることを Hive に伝えます。SELECT:t4の値が[ERROR]であるすべての行の数を選択します。 この値を含む行が 3 行あるため、このステートメントでは値3が返されます。.
INPUT__FILE__NAME LIKE '%.log': .log で終わるファイルのデータだけを返すことを Hive に伝えます。 この句により、検索はデータを含む sample.log ファイルに制限されます。
クエリ ファイル ツール バー (アドホック クエリ ツール バーと外観が似ています) で、このクエリに使用する HDInsight クラスターを選択します。 次に [対話型] を [バッチ] に変更し (必要な場合)、[送信] を選択して、ステートメントを Hive ジョブとして実行します。
[Hive ジョブの概要] に実行しているジョブに関する情報が表示されます。 [更新] リンクを使用して、[ジョブのステータス] が [完了] に変更されるまで、ジョブの情報を更新します。
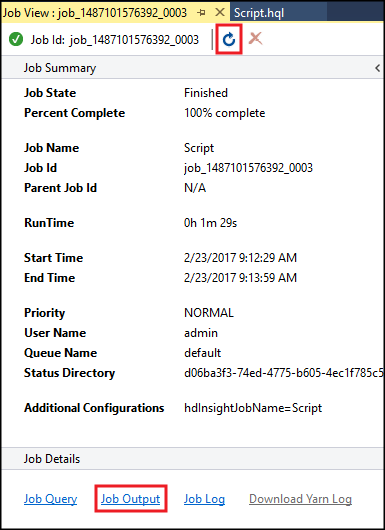
[ジョブ出力] を選択して、このジョブの出力を表示します。 このクエリによって返された値である
[ERROR] 3が表示されます。
その他の例
次の例では、前の手順「Hive アプリケーションを作成する」で作成した log4jLogs テーブルを使用します。
サーバー エクスプローラーから、クラスターを右クリックして [Hive クエリの作成] を選択します。
次の Hive クエリを入力します。
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';これらのステートメントによって次のアクションが実行されます。
CREATE TABLE IF NOT EXISTS: テーブルがまだ存在しない場合はテーブルを作成します。EXTERNALキーワードが使用されていないため、このステートメントでは内部テーブルが作成されます。 内部テーブルは Hive データ ウェアハウスに格納され、Hive によって管理されます。Note
EXTERNALテーブルとは異なり、内部テーブルを削除すると、基になるデータも削除されます。STORED AS ORC: Optimized Row Columnar (ORC) 形式でデータを格納します。 ORC は、Hive データを格納するための高度に最適化された効率的な形式です。INSERT OVERWRITE ... SELECT:[ERROR]を含むlog4jLogsテーブルの列を選択し、データをerrorLogsテーブルに挿入します。
必要に応じて [対話型] を [バッチ] に変更し、[送信] を選択します。
ジョブによってテーブルが作成されたことを確認するには、サーバー エクスプローラーに移動し、[Azure]>[HDInsight] を展開します。 HDInsight クラスターを展開し、 [Hive データベース]>[既定値] を展開します。 errorLogs テーブルと Log4jLogs テーブルが表示されます。
次のステップ
おわかりのように、Visual Studio の HDInsight ツールを使用すると、HDInsight で Hive クエリを簡単に操作できます。
HDInsight の Hive に関する一般情報については、「Azure HDInsight における Apache Hive と HiveQL」を参照してください。
HDInsight で Hadoop のその他の使用する方法の詳細については、「HDInsight 上の Apache Hadoop での MapReduce の使用」を参照してください。
HDInsight tools for Visual Studio の詳細については、「Data Lake Tools for Visual Studio を使用して Azure HDInsight に接続し Apache Hive クエリを実行」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示