Azure HDInsight で Apache Hive を使用して JavaScript Object Notation (JSON) ファイルを処理および分析する方法について説明します。 この記事では、次の JSON ドキュメントを使用します。
{
"StudentId": "trgfg-5454-fdfdg-4346",
"Grade": 7,
"StudentDetails": [
{
"FirstName": "Peggy",
"LastName": "Williams",
"YearJoined": 2012
}
],
"StudentClassCollection": [
{
"ClassId": "89084343",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "High",
"Score": 93,
"PerformedActivity": false
},
{
"ClassId": "78547522",
"ClassParticipation": "NotSatisfied",
"ClassParticipationRank": "None",
"Score": 74,
"PerformedActivity": false
},
{
"ClassId": "78675563",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "Low",
"Score": 83,
"PerformedActivity": true
}
]
}
ファイルは、wasb://processjson@hditutorialdata.blob.core.windows.net/ で参照できます。 HDInsight での Azure BLOB ストレージの使用方法については、HDInsight の Apache Hadoop での HDFS と互換性のある Azure BLOB ストレージの使用に関する記事をご覧ください。 クラスターの既定のコンテナーにファイルをコピーできます。
この記事では、Apache Hive コンソールを使用します。 Hive コンソールを開く方法については、「HDInsight 上の Apache Hadoop で Apache Ambari Hive ビューを使用する」を参照してください。
注意
HDInsight 4.0 では、Hive ビューは使用できなくなります。
JSON ドキュメントの平坦化
次のセクションで一覧表示されているメソッドでは、JSON ドキュメントが 1 行で構成されている必要があります。 このため、JSON ドキュメントを文字列にフラット化する必要があります。 JSON ドキュメントがすでにフラット化されている場合、このステップをスキップして、JSON データの分析に関する次のセクションに直接進むことができます。 JSON ドキュメントをフラット化するには、次のスクリプトを実行します。
DROP TABLE IF EXISTS StudentsRaw;
CREATE EXTERNAL TABLE StudentsRaw (textcol string) STORED AS TEXTFILE LOCATION "wasb://processjson@hditutorialdata.blob.core.windows.net/";
DROP TABLE IF EXISTS StudentsOneLine;
CREATE EXTERNAL TABLE StudentsOneLine
(
json_body string
)
STORED AS TEXTFILE LOCATION '/json/students';
INSERT OVERWRITE TABLE StudentsOneLine
SELECT CONCAT_WS(' ',COLLECT_LIST(textcol)) AS singlelineJSON
FROM (SELECT INPUT__FILE__NAME,BLOCK__OFFSET__INSIDE__FILE, textcol FROM StudentsRaw DISTRIBUTE BY INPUT__FILE__NAME SORT BY BLOCK__OFFSET__INSIDE__FILE) x
GROUP BY INPUT__FILE__NAME;
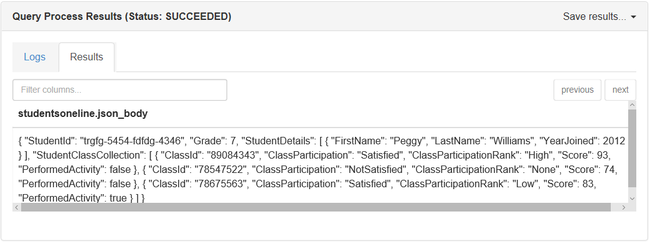
SELECT * FROM StudentsOneLine
未加工の JSON ファイルは wasb://processjson@hditutorialdata.blob.core.windows.net/ にあります。 StudentsRaw Hive テーブルは、未加工のフラット化されていない JSON ドキュメントを指しています。
StudentsOneLine Hive テーブルは、 /json/students/ パスの下にある HDInsight の既定のファイル システムにデータを保存します。
INSERT ステートメントは、StudentOneLine テーブルにフラット化された JSON データを取り込みます。
SELECT ステートメントは 1 行のみを返します。
SELECT ステートメントの出力を次に示します。
Hive での JSON ドキュメントの分析
Hive は、JSON ドキュメントに対してクエリを実行するための次の 3 つの異なるメカニズムを提供します。あるいは、独自に記述することもできます。
- get_json_object user-defined 関数 (UDF) を使用します。
- json_tuple UDF を使用します。
- カスタムのシリアライザー/デシリアライザー (SerDe) を使用します。
- Python またはその他の言語を使用して独自の UDF を作成します。 Hive で独自の Python コードを実行する方法の詳細については、Apache Hive および Apache Pig での Python UDF に関するページを参照してください。
get_json_object UDF を使用する
Hive には、実行時に JSON にクエリを実行する get_json_object という名前の組み込みの UDF が用意されています。 このメソッドは、テーブル名とメソッド名の 2 つの引数を受け取ります。 このメソッド名には、フラット化された JSON ドキュメントと解析する必要のある JSON フィールドが含まれています。 この UDF がどのように機能するかを示す例を見てみましょう。
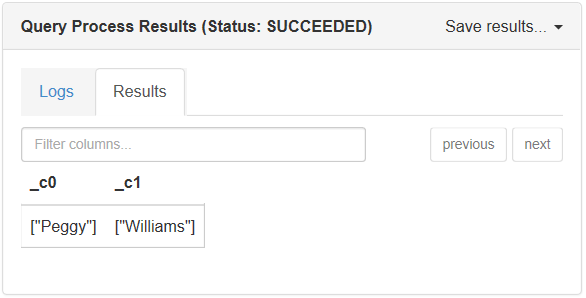
次のクエリは各学生の姓と名を返します。
SELECT
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.FirstName'),
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.LastName')
FROM StudentsOneLine;
このクエリをコンソール ウィンドウで実行したときの出力を次に示します。
get_json_object UDF には次の制限があります。
- クエリ内の各フィールドではクエリの再解析が必要なため、パフォーマンスに影響が出ます。
- GET_JSON_OBJECT() によって、配列の文字列表現が返されます。 これを Hive 配列に変換するには、正規表現を使用して、角括弧 "[" と "]" を置き換えてから、split を呼び出して配列を取得する必要があります。
この変換は、Hive Wiki で json_tuple の使用が推奨される理由になっています。
json_tuple UDF を使用する
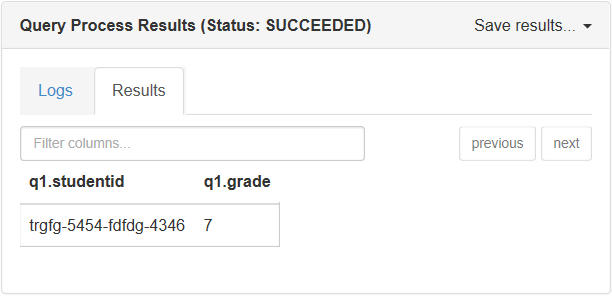
Hive によって提供されるもう 1 つの UDF は json_tuple と呼ばれ、get_ json _object より優れています。 このメソッドは、一連のキーと JSON 文字列を受け取ります。 その後、値のタプルを返します。 次のクエリでは、JSON ドキュメントから、学生 ID とグレードが返されます。
SELECT q1.StudentId, q1.Grade
FROM StudentsOneLine jt
LATERAL VIEW JSON_TUPLE(jt.json_body, 'StudentId', 'Grade') q1
AS StudentId, Grade;
Hive コンソールにおけるこのスクリプトの出力:
json_tuple UDF では、Hive で lateral view 構文を使用します。これにより、json_tuple で、元のテーブルの各行に UDT 関数を適用することによって仮想テーブルを作成できます。 複雑な JSON では LATERAL VIEW が繰り返し使用されるため、処理が難しくなります。 また、JSON_TUPLE では入れ子になった JSON を処理できません。
カスタム SerDe を使用する
SerDe は、入れ子になった JSON ドキュメントの解析に最適な選択肢です。 SerDe を使用して JSON スキーマを定義し、そのスキーマを使用してドキュメントを解析することができます。 手順については、How to use a Custom JSON Serde with Microsoft Azure HDInsight (Microsoft Azure HDInsight でのカスタム JSON Serde の使用方法) を参照してください。
まとめ
選択する Hive の JSON 演算子の種類は、シナリオによって異なります。 単純な JSON ドキュメントで 1 つのフィールドを検索する場合は、Hive UDF の get_json_object を選択します。 検索対象のキーが複数ある場合には、json_tuple を使用できます。 入れ子になったドキュメントの場合は、JSON SerDe を使用します。
次のステップ
関連記事については、次を参照してください。