このチュートリアルでは、Azure HDInsight で Apache HBase クラスターを作成する方法、HBase テーブルを作成する方法、Apache Hive を使用してテーブルのクエリを実行する方法について説明します。 HBase に関する一般的な情報については、HDInsight HBase の概要に関するページを参照してください。
このチュートリアルでは、以下の内容を学習します。
- Apache HBase クラスターを作成する
- HBase テーブルを作成してデータを挿入する
- Apache Hive を使用して Apache HBase を照会する
- Curl を使用して HBase REST API を使用する
- クラスターの状態の確認
前提条件
SSH クライアント 詳細については、SSH を使用して HDInsight (Apache Hadoop) に接続する方法に関するページを参照してください。
Bash。 この記事の例では、curl コマンドのために Windows 10 上で Bash シェルを使用します。 インストール手順については、「Windows Subsystem for Linux Installation Guide for Windows 10 (Windows 10 用 Windows Subsystem for Linux インストール ガイド)」をご覧ください。 他の Unix シェルも動作します。 これらの curl の例は、少し変更すれば、Windows コマンド プロンプトで動作できます。 または、Windows PowerShell コマンドレット Invoke-RestMethod を使用できます。
Apache HBase クラスターを作成する
以下の手順では、Azure Resource Manager テンプレートを使って HBase クラスターを作成します。 また、依存する既定の Azure Storage アカウントもこのテンプレートで作成されます。 この手順で使用するパラメーターとその他のクラスター作成方法について理解するには、「 HDInsight での Linux ベースの Hadoop クラスターの作成」を参照してください。
次の画像を選択して Azure Portal でテンプレートを開きます。 テンプレートは、Azure クイック スタート テンプレートのページにあります。
![新しいクラスターの [Azure へのデプロイ] ボタン](media/apache-hbase-tutorial-get-started-linux/hdi-deploy-to-azure1.png)
[カスタム デプロイ] ダイアログで以下の値を入力します。
プロパティ 説明 サブスクリプション クラスターの作成に使用する Azure サブスクリプションを選択します。 Resource group Azure リソース管理グループを作成するか、または既存のグループを使用します。 場所 リソース グループの [場所] を指定します。 ClusterName HBase クラスターの名前を入力します。 クラスター ログイン名とパスワード 既定のログイン名は adminです。SSH ユーザー名とパスワード 既定のユーザー名は sshuserです。その他のパラメーターは省略可能です。
各クラスターには Azure ストレージ アカウントとの依存関係があります。 クラスターを削除すると、データはストレージ アカウントに保持されます。 クラスターの既定のストレージ アカウント名は、クラスター名に "store" が追加されたものです。 これは、テンプレートの variables セクションでハードコードされます。
[上記の使用条件に同意する] を選択し、 [購入] を選択します。 クラスターの作成には約 20 分かかります。
HBase クラスターを削除した後、同じ既定の BLOB コンテナーを使って別の HBase クラスターを作成できます。 新しいクラスターでは、元のクラスターで作成した HBase テーブルを選択します。 不整合を回避するために、クラスターを削除する前に HBase テーブルを無効にしておくことをお勧めします。
テーブルを作成してデータを挿入する
SSH を使用して HBase クラスターに接続し、Apache HBase シェルを使用して HBase テーブルの作成、データの挿入、データのクエリを行うことができます。
多くの場合、データは次のような表形式で表示されます。

HBase (クラウド BigTable の実装) では、同じデータが次のように表示されます。

HBase シェルを使用するには
sshコマンドを使用して HBase クラスターに接続します。 次のコマンドを編集してCLUSTERNAMEを実際のクラスターの名前に置き換えた後、そのコマンドを入力します。ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.nethbase shellコマンドを使用して、HBase 対話型シェルを起動します。 SSH 接続で次のコマンドを入力します。hbase shellcreateコマンドを使って、2 列のファミリを含む HBase テーブルを作成します。 テーブル名と列名は大文字と小文字が区別されます。 次のコマンドを入力します。create 'Contacts', 'Personal', 'Office'listコマンドを使用して、HBase 内のすべてのテーブルを一覧表示します。 次のコマンドを入力します。listputコマンドを使用して、特定のテーブルの指定行の指定列に値を挿入します。 次のコマンドを入力します。put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'scanコマンドを使用して、Contactsテーブルのデータをスキャンして返します。 次のコマンドを入力します。scan 'Contacts'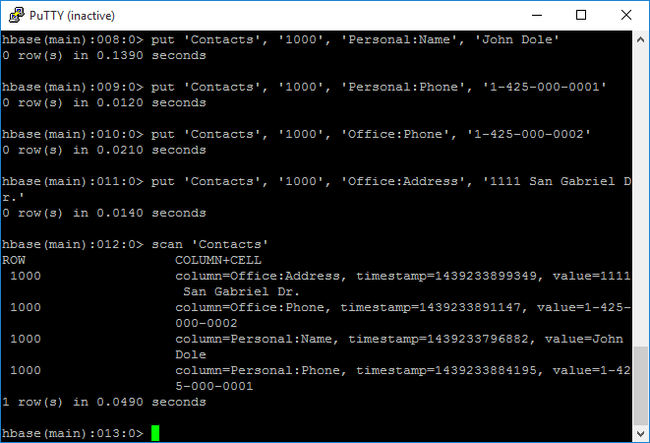
getコマンドを使用して、行のコンテンツを取り込みます。 次のコマンドを入力します。get 'Contacts', '1000'1 行しかないので、
scanコマンドを使用したときと同じような結果が表示されます。HBase テーブル スキーマの詳細については、Apache HBase スキーマの設計の概要に関するページを参照してください。 HBase コマンドの詳細については、「Apache HBase のリファレンス ガイド」を参照してください。
exitコマンドを使用して、HBase 対話型シェルを停止します。 次のコマンドを入力します。exit
Contacts HBase テーブルにデータを一括で読み込むには
HBase では、いくつかの方法でテーブルにデータを読み込ことができます。 詳細については、 一括読み込みに関するページを参照してください。
サンプルのデータ ファイルは、パブリック BLOB コンテナー wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt にあります。 このデータ ファイルの内容は次のとおりです。
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
必要に応じて、自分でテキスト ファイルを作成し、そのファイルを自分のストレージ アカウントにアップロードできます。 手順については、「HDInsight で Apache Hadoop ジョブのデータをアップロードする」を参照してください。
この手順では、前回の手順で作成した Contacts HBase テーブルを使用します。
開いている ssh 接続から、次のコマンドを実行してデータ ファイルを StoreFile に変換し、
Dimporttsv.bulk.outputで指定された相対パスに格納します。hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt次のコマンドを実行して、データを
/example/data/storeDataFileOutputから HBase テーブルにアップロードします。hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsHBase シェルを開き、
scanコマンドを使用してテーブルの内容を一覧表示することができます。
Apache Hive を使用して Apache HBase を照会する
Apache Hive を使用して HBase テーブルのデータを照会できます。 このセクションでは、HBase テーブルにマッピングする Hive テーブルを作成し、作成した Hive テーブルを使用して HBase テーブルのデータを照会します。
開いている ssh 接続から、次のコマンドを使用して Beeline を開始します。
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminBeeline の詳細については、「Beeline による HDInsight での Hive と Hadoop の使用」を参照してください。
次の HiveQL スクリプトを実行して、HBase テーブルにマップする Hive テーブルを作成します。 この記事で、HBase シェルを使用して、先ほど参照したサンプル テーブルが作成されたことを確認してから、このステートメントを実行してください。
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');次の HiveQL スクリプトを実行して、HBase テーブルのデータを照会します。
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Beeline を終了するには、
!exitを使用します。ssh 接続を終了するには、
exitを使用します。
Hive クラスターと HBase クラスターを分離する
HBase データにアクセスする Hive クエリは、HBase クラスターから実行する必要はありません。 次の手順が完了していれば、Hive に付属する任意のクラスター (Spark、Hadoop、HBase、Interactive Query など) を使用して、HBase データに対するクエリを実行できます。
- 両方のクラスターが同じ仮想ネットワークとサブネットに接続されている必要があります
- HBase クラスターのヘッドノードから Hive クラスターのヘッドノードとワーカー ノードに、
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlをコピーします。
クラスターをセキュリティで保護する
HBase データには、ESP 対応の HBase を使用している Hive からクエリを実行することもできます。
- マルチクラスター パターンに従う場合、両方のクラスターで ESP が有効になっている必要があります。
- Hive で HBase データに対するクエリを実行できるようにするには、Hbase Apache Ranger プラグインを介して HBase データにアクセスするためのアクセス許可が
hiveユーザーに付与されていることを確認します - 別の ESP 対応クラスターを使う場合は、HBase クラスターのヘッドノードの
/etc/hostsの内容を、Hive クラスターのヘッドノードとワーカー ノードの/etc/hostsに追加する必要があります。
Note
いずれかのクラスターをスケーリングした後、/etc/hosts を再度追加する必要があります
Curl を使用して HBase REST API を使用する
HBase REST API のセキュリティは、基本認証を通じて保護されています。 資格情報をサーバーに安全に送信するには、必ずセキュア HTTP (HTTPS) を使用して要求を行う必要があります。
HDInsight クラスターで HBase REST API を有効にするには、次のカスタム スタートアップ スクリプトを Script Action セクションに追加します。 クラスターを作成するとき、またはクラスターを作成した後に、スタートアップ スクリプトを追加できます。 [ノードの種類] では、 [Region Servers](リージョン サーバー) を選択して、HBase リージョン サーバーだけでスクリプトが実行されるようにします。 スクリプトにより、リージョン サーバーの 8090 ポートで HBase REST プロキシが開始されます。
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fi使いやすさのために環境変数を設定します。 次のコマンドを編集して、
MYPASSWORDをクラスター ログイン パスワードに置き換えます。MYCLUSTERNAMEを HBase クラスターの名前に置き換えます。 その後、これらのコマンドを入力します。export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAME次のコマンドを使用して、既存の HBase テーブルを一覧表示します。
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/次のコマンドを使用して、2 つの列ファミリを含む新しい HBase テーブルを作成します。
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vスキーマは、JSON 形式で提供されます。
次のコマンドを使用して、一部のデータを挿入します。
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -v-d スイッチで指定する値は、Base64 でエンコードする必要があります。 この例では次のとおりです。
MTAwMA==:1000
UGVyc29uYWw6TmFtZQ==:Personal:名前
Sm9obiBEb2xl:John Dole
false-row-key を使用すると、複数の (バッチ処理された) 値を挿入できます。
次のコマンドを使用して、1 行を取得します。
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Note
クラスター エンドポイントを通したスキャンは、まだサポートされていません。
HBase Rest の詳細については、「 Apache HBase reference guide (Apache HBase リファレンス ガイド)」をご覧ください。
Note
Thrift は、HDInsight での HBase ではサポートされていません。
Curl、または WebHCat を使う他の REST 通信を使う場合は、HDInsight クラスター管理者のユーザー名とパスワードを指定して、要求の認証を行う必要があります。 また、サーバーへの要求の送信に使用する Uniform Resource Identifier (URI) にクラスター名を含める必要があります。
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
次のような応答が返されます。
{"status":"ok","version":"v1"}
クラスターの状態の確認
HDInsight の HBase には、クラスターを監視するための Web UI が付属します。 この Web UI を使用すると、統計情報やリージョンに関する情報を要求できます。
HBase Master UI にアクセスするには
https://CLUSTERNAME.azurehdinsight.netの Ambari Web UI にサインインします。このCLUSTERNAMEは HBase クラスターの名前です。左側のメニューで [HBase] を選択します。
ページの上部にある [Quick links](クイック リンク) を選択し、アクティブな Zookeeper ノード リンクをポイントして、 [HBase Master UI] を選択します。 UI は別のブラウザー タブで開かれます。
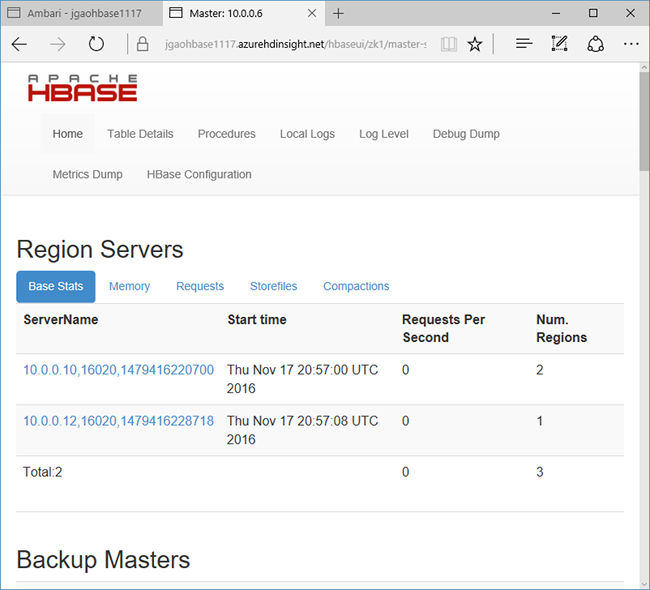
HBase Master UI には次のセクションがあります。
- リージョン サーバー
- バックアップ マスター
- 表
- tasks
- ソフトウェア属性
クラスターの再作成
HBase クラスターを削除した後、同じ既定の BLOB コンテナーを使って別の HBase クラスターを作成できます。 新しいクラスターでは、元のクラスターで作成した HBase テーブルを選択します。 ただし、不整合を回避するために、クラスターを削除する前に HBase テーブルを無効にしておくことをお勧めします。
HBase コマンド disable 'Contacts' を使用できます。
リソースをクリーンアップする
このアプリケーションを引き続き使用しない場合は、次の手順で作成した HBase クラスターを削除します。
- Azure portal にサインインします。
- 上部の検索ボックスに「HDInsight」と入力します。
- [サービス] の下の [HDInsight クラスター] を選択します。
- 表示される HDInsight クラスターの一覧で、このチュートリアル用に作成したクラスターの横にある [...] をクリックします。
- [削除] をクリックします。 [はい] をクリックします。
次のステップ
このチュートリアルでは、Apache HBase クラスターの作成方法を学習しました。 また、テーブルを作成してそのテーブルのデータを HBase シェルから表示する方法についても学習しました。 Hive を使用して HBase テーブルのデータを照会する方法や、 HBase C# REST API を使用して HBase テーブルを作成し、テーブルからデータを取得する方法についても学習しました。 詳細については、次を参照してください。