クイックスタート: Azure HDInsight で Apache Zeppelin を使用して Apache Hive クエリを実行する
このクイックスタートでは、Azure HDInsight で Apache Zeppelin を使用して Apache Hive クエリを実行する方法について説明します。 HDInsight 対話型クエリ クラスターには、対話型 Hive クエリを実行するために使用できる Apache Zeppelin ノートブックが含まれています。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
HDInsight 対話型クエリ クラスター。 HDInsight クラスターの作成については、クラスターの作成に関するセクションを参照してください。 クラスターの種類では、[インタラクティブ クエリ] を必ず選択してください。
Apache Zeppelin Note を作成する
URL
https://CLUSTERNAME.azurehdinsight.net/zeppelinのCLUSTERNAMEをお使いのクラスターの名前に置き換えます。 Web ブラウザーに URL を入力します。クラスターのログイン ユーザー名とパスワードを入力します。 Zeppelin ページで、新しいノートを作成するか、既存のノートを開きます。 HiveSample には、サンプル Hive クエリが含まれています。
[Create new note]\(新しいノートの作成\) を選択します。
[Create new note]\(新しいノートの作成\) ダイアログで、次の値を入力または選択します。
- [Note Name](ノート名): ノートの名前を入力します。
- [Default interpreter]\(既定のインタープリター\): ドロップダウンリストから [jdbc] を選択します。
[Create Note]\(ノートの作成\)を選択します。
次の Hive クエリをコード セクションに入力し、Shift + Enter キーを押します。
%jdbc(hive) show tables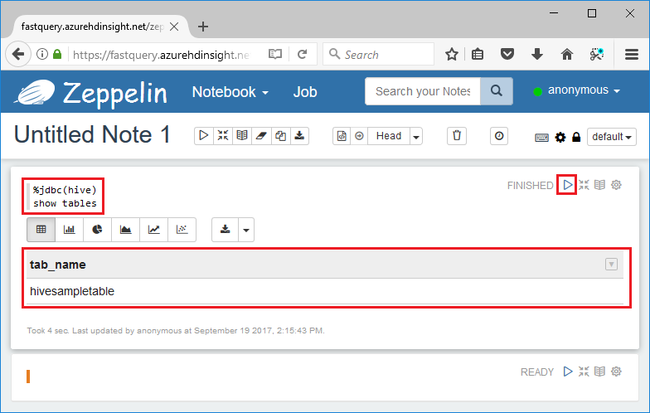
最初の行の %jdbc(hive) ステートメントは、Hive JDBC インタープリターを使用するようにノートブックに指示します。
クエリは hivesampletable という名前の Hive テーブルを返します。
hivesampletable に対して実行できるその他の Hive クエリを 2 つ次に示します。
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}従来の Hive と比較すると、クエリ結果が返されるまでの時間が短くなりました。
追加の例
テーブルを作成します。 Zeppelin Notebook で次のコードを実行します。
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;新しいテーブルにデータを読み込みます。 Zeppelin Notebook で次のコードを実行します。
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;レコードを 1 件挿入します。 Zeppelin Notebook で次のコードを実行します。
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
その他の構文については、Hive 言語マニュアルを参照してください。
リソースをクリーンアップする
このクイックスタートを完了したら、必要に応じてクラスターを削除できます。 HDInsight を使用すると、データは Azure Storage に格納されるため、クラスターは、使用されていない場合に安全に削除できます。 また、HDInsight クラスターは、使用していない場合でも課金されます。 クラスターの料金は Storage の料金の何倍にもなるため、クラスターを使用しない場合は削除するのが経済的にも合理的です。
クラスターを削除するには、「ブラウザー、PowerShell、または Azure CLI を使用して HDInsight クラスターを削除する」を参照してください。
次のステップ
このクイックスタートでは、Azure HDInsight で Apache Zeppelin を使用して Apache Hive クエリを実行する方法について学習しました。 Hive クエリの詳細について、次の記事で Visual Studio を使用してクエリを実行する方法を紹介します。