Azure HDInsight の Apache Phoenix
Apache Phoenix は、Apache HBase 上に構築されるオープンソースの超並列リレーショナル データベース レイヤーです。 Phoenix では、HBase に対して SQL のようなクエリを使うことができます。 Phoenix は基盤の JDBC ドライバーを使って、ユーザーが SQL テーブル、インデックス、ビュー、およびシーケンスを作成、削除、変更でき、行を個別または一括でアップサートできるようします。 Phoenix は、MapReduce ではなく noSQL ネイティブ コンパイルを使ってクエリをコンパイルして、HBase に基づく待機時間の短いアプリケーションを作成できるようにします。 Phoenix では、コプロセッサを追加して、クライアントが指定したコードの実行をサーバーのアドレス空間でサポートすることにより、データと共存したコードを実行します。 このアプローチにより、クライアント/サーバーのデータ転送が最小限に抑えられます。
Apache Phoenix を使うと、開発者でなくても、プログラミングではなく SQL に似た構文を使って、ビッグ データのクエリを実行できます。 Phoenix は、Apache Hive や Apache Spark SQL などの他のツールとは異なり、HBase 向けに高度に最適化されています。 開発者にとってのメリットは、高いパフォーマンスのクエリを、はるかに少ないコードで作成できることです。
SQL クエリを送信すると、Phoenix は HBase ネイティブの呼び出しにクエリをコンパイルし、最適化のためにスキャン (またはプラン) を並列で実行します。 この抽象化レイヤーにより、開発者は MapReduce ジョブを作成しなくて済み、Phoenix のビッグ データ ストレージに関するアプリケーションのビジネス ロジックとワークフローに集中できます。
クエリ パフォーマンスの最適化と他の機能
Apache Phoenix は、いくつかのパフォーマンス強化と機能を HBase クエリに追加します。
セカンダリ インデックス
HBase には、プライマリ行キーについて辞書式に並べ替えられた 1 つのインデックスがあります。 これらのレコードには、行キーを介してのみアクセスできます。 行キー以外の任意の列でレコードにアクセスするには、必要なフィルターを適用しながらすべてのデータをスキャンする必要があります。 セカンダリ インデックスでは、インデックス付きの列または式が代替行キーを形成し、そのインデックスで参照と範囲スキャンを行うことができます。
セカンダリ インデックスは CREATE INDEX コマンドで作成します。
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
この方法を使うと、単一インデックスでクエリを実行するより、パフォーマンスが大幅に向上します。 この種のセカンダリ インデックスはカバリング インデックスであり、クエリに含まれるすべての列を含みます。 したがって、テーブル参照は必要なく、インデックスがクエリ全体を満たします。
Views
Phoenix のビューは、作成された物理テーブルの数が約 100 個を超えるとパフォーマンスが低下し始める HBase の制限を克服する手段を提供します。 Phoenix のビューでは、基になる 1 つの物理 HBase テーブルを複数の "仮想テーブル" で共有できます。
Phoenix ビューの作成は、SQL の標準的なビュー構文の使用と似ています。 1 つの違いは、ベース テーブルから継承される列だけでなく、ビューの列を定義できることです。 新しい KeyValue 列を追加することもできます。
たとえば、次に示すのは product_metrics という名前の物理テーブルの定義です。
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
次に示すのはこのテーブルに対するビューの定義であり、列が追加されています。
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
後で列を追加するには、ALTER VIEW ステートメントを使います。
スキップ スキャン
スキップ スキャンは、複合インデックスの 1 つ以上の列を使って、個別の値を検索します。 範囲スキャンとは異なり、スキップ スキャンは行内スキャンを実装して、パフォーマンスの向上を実現します。 スキャンでは、最初に一致した値は、次の値が見つかるまで、インデックスと共にスキップされます。
スキップ スキャンでは、HBase フィルターの SEEK_NEXT_USING_HINT 列挙型が使われます。 スキップ スキャンは、SEEK_NEXT_USING_HINT を使うことで、各列で検索されているキーのセットまたはキーの範囲を追跡します。 その後、スキップ スキャンはフィルター評価の間に渡されたキーを取得して、組み合わせの 1 つかどうかを判定します。 該当しない場合、スキップ スキャンはジャンプする次の最上位キーを評価します。
トランザクション
HBase では行レベルのトランザクションが提供されますが、Phoenix は Tephra と統合して、完全な ACID セマンティクスを備えたクロス行トランザクションとクロステーブル トランザクションのサポートを追加します。
従来の SQL トランザクションと同様に、Phoenix トランザクション マネージャーによって提供されるトランザクションを使うと、データのアトミック単位が正常にアップサートされて、任意のトランザクション対応テーブルでアップサート操作が失敗した場合はトランザクションがロールバックすることが保証されます。
Phoenix のトランザクションを有効にする方法については、Apache Phoenix トランザクションのドキュメントをご覧ください。
トランザクションが有効な新しいテーブルを作成するには、CREATE ステートメントで TRANSACTIONAL プロパティを true に設定します。
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
既存のテーブルをトランザクション対応に変更するには、ALTER ステートメントで同じプロパティを使います。
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
注意
トランザクション対応のテーブルをトランザクション非対応に切り替えることはできません。
ソルティングされたテーブル
連続したキーでレコードを HBase に書き込むとき、リージョン サーバーのホットスポッティング が発生する可能性がある クラスターに複数のリージョン サーバーが存在する場合であっても、書き込みはすべてただ 1 つのサーバーで行われます。 この集中によってホットスポッティングが発生すると、使用可能なすべてのリージョン サーバーに書き込みワークロードが分散されるのではなく、1 台のサーバーだけが負荷を処理するようになります。 各リージョンには事前に定義された最大サイズがあるので、リージョンがそのサイズ上限に達すると、2 つの小さいリージョンに分割されます。 その場合、新しいリージョンの 1 つが新しいレコードをすべて引き受けて、新しいホットスポットになります。
この問題を軽減してパフォーマンスを向上させるには、すべてのリージョン サーバーが均等に使われるように、テーブルを事前に分割しておきます。 Phoenix では "ソルティングされたテーブル" が提供されており、特定のテーブルの行キーにソルティング バイトが透過的に追加されます。 テーブルはソルト バイトの境界で事前に分割され、テーブルの初期フェーズにおいてリージョン サーバー間に負荷が均等に分散されます。 この方法により、書き込みワークロードは使用可能なすべてのリージョン サーバーに分散され、書き込みと読み取りのパフォーマンスが向上します。 テーブルをソルティングするには、テーブルを作成するときに SALT_BUCKETS テーブル プロパティを指定します。
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Apache Ambari での Phoenix の有効化と調整
HDInsight HBase クラスターには、構成の変更を行うための Ambari UI が含まれます。
Phoenix を有効または無効にしたり、Phoenix のクエリ タイムアウトの設定を制御したりするには、Hadoop のユーザー資格情報を使って Ambari Web UI (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) にログインします。左側のメニューのサービス一覧から [HBase] を選び、[Configs](構成) タブを選びます。
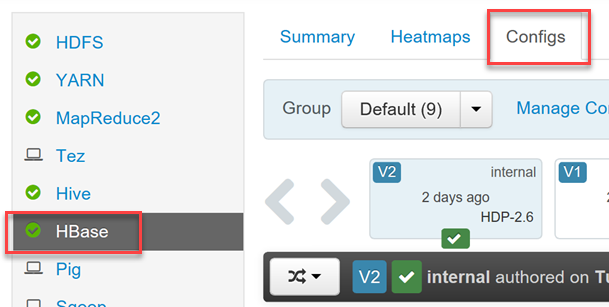
[Phoenix SQL] 構成セクションを探して、Phoenix を有効または無効にしたり、クエリのタイムアウトを設定します。