このノートブックは、HDInsight 上の Apache Spark でカスタム ライブラリを使用してログ データを分析する方法を示します。 使用するカスタム ライブラリは、 iislogparser.pyと呼ばれる Python ライブラリです。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。
生データを RDD として保存する
このセクションでは、HDInsight の Apache Spark クラスターと関連付けられた Jupyter Notebook を使用して、生のサンプル データを処理して Hive テーブルとして保存するジョブを実行します。 サンプル データは、すべてのクラスターにおいて既定で使用できる .csv ファイル (hvac.csv) です。
データが Apache Hive テーブルとして保存されたら、次のセクションでは、Power BI や Tableau などの BI ツールを使用してその Hive テーブルに接続します。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.net/jupyterに移動します。ここで、CLUSTERNAMEはクラスターの名前です。新しい Notebook を作成します。 [新規] を選択し、 [PySpark] を選択します。
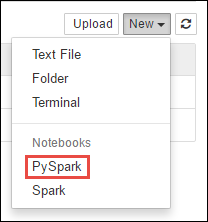 Notebook" border="true":::
Notebook" border="true":::Untitled.pynb という名前の新しい Notebook が作成されて開かれます。 上部のノートブック名を選択し、わかりやすい名前を入力します。
PySpark カーネルを使用して Notebook を作成したため、コンテキストを明示的に作成する必要はありません。 最初のコード セルを実行すると、Spark および Hive コンテキストが自動的に作成されます。 このシナリオに必要な種類をインポートすることから始めることができます。 次のスニペットを空のセルに貼り付けて、Shift + Enter キーを押します。
from pyspark.sql import Row from pyspark.sql.types import *クラスターにあらかじめ用意されているサンプル ログ データを使用して、RDD を作成します。
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.logのクラスターに関連付けられている既定のストレージ アカウントのデータにアクセスできます。 次のコードを実行します。logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')前の手順が正常に完了したことを確認するために、サンプル ログ セットを取得します。
logs.take(5)次のテキストのような出力が表示されます。
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
カスタム Python ライブラリを使用してログ データを分析する
上の出力の最初の数行にはヘッダー情報が含まれており、残りの各行は、そのヘッダーで説明されているスキーマと一致します。 このようなログの解析は、複雑である場合があります。 そこで、このようなログの解析を簡単にするために、カスタム Python ライブラリ (iislogparser.py) を使用します。 既定では、このライブラリは HDInsight 上の Spark クラスターに含まれます (
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py)。ただし、このライブラリは
PYTHONPATHに含まれていないため、import iislogparserのような import ステートメントで使用することはできません。 このライブラリを使用するには、すべてのワーカー ノードに配布する必要があります。 次のスニペットを実行します。sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserにはparse_log_line関数があり、この関数はログ行がヘッダー行である場合はNoneを返し、ログ行に到達するとLogLineクラスのインスタンスを返します。 次のようにLogLineクラスを使用して、RDD からログ行だけを抽出します。def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()手順が正常に完了したことを確認するために、いくつかの抽出されたログ行を取得します。
logLines.take(2)出力は次のテキストのようになります。
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]LogLineクラスには、いくつかの便利なメソッドもあります。たとえば、is_error()は、ログ エントリにエラー コードが含まれているかどうかを返します。 このクラスを使用して、抽出したログ行内のエラー数を計算し、別のファイルにすべてのエラーを記録します。errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')出力は
There are 30 errors and 646 log entriesのようになります。Matplotlib を使用して、データを視覚化することもできます。 たとえば、要求の実行が長時間になる原因を特定するために、平均して最も処理時間がかかっているファイルを見つけたい場合があります。 次のスニペットでは、要求を処理するために最も時間がかかっている上位 25 件のリソースを取得します。
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])次のテキストのような結果が表示されます。
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]また、この情報をプロットの形式で表示することもできます。 プロットを作成する最初の手順として、まず、一時テーブル AverageTimeを作成します。 テーブル グループは、特定の時間に異常な遅延の急増があったかどうかがわかるように、ログを時間でグループ化します。
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')次に、以下の SQL クエリを実行して、 AverageTime テーブル内のすべてのレコードを取得できます。
%%sql -o averagetime SELECT * FROM AverageTime%%sqlマジックの後に-o averagetimeと入力して、クエリの出力が Jupyter サーバー (通常はクラスターのヘッドノード) にローカルに保持されるようにします。 出力は、 Pandas データフレームとして、 averagetimeという名前で保持されます。次のイメージのような結果が表示されます。
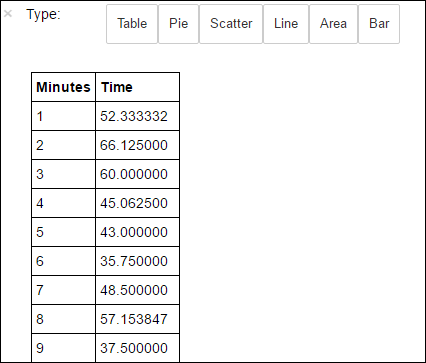 yter sql query output" border="true":::
yter sql query output" border="true":::%%sqlマジックについて詳しくは、「%%sql マジックでサポートされるパラメーター」をご覧ください。データの視覚効果の構築に使用するライブラリ、Matplotlib を使用して、プロットを作成できます。 プロットはローカルに保持された averagetime データフレームから作成する必要があるため、コード スニペットは
%%localマジックで始める必要があります。 これにより、コードは Jupyter サーバーでローカルに実行されます。%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')次のイメージのような結果が表示されます。
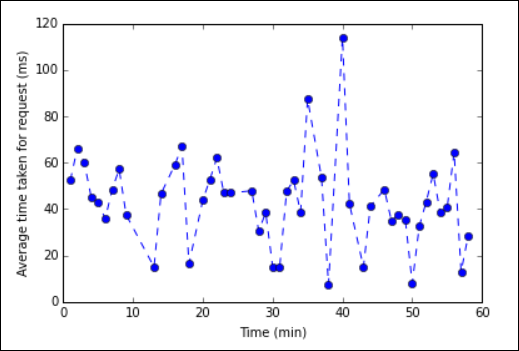 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::アプリケーションの実行が完了したら、Notebook をシャットダウンしてリソースを解放する必要があります。 そのためには、Notebook の [ファイル] メニューの [Close and Halt] (閉じて停止) をクリックします。 このアクションにより、Notebook がシャットダウンされ、閉じられます。
次のステップ
次の記事をご覧ください。