モデルのトレーニング コンポーネント
この記事では Azure Machine Learning デザイナーのコンポーネントについて説明します。
分類または回帰モデルをトレーニングするには、このコンポーネントを使用します。 トレーニングは、モデルを定義してそのパラメーターを設定した後に行います。トレーニングには、タグ付けされたデータが必要です。 モデルのトレーニングを使用して、既存のモデルを新しいデータで再トレーニングすることもできます。
トレーニング プロセスのしくみ
通常、Azure Machine Learning における機械学習モデルの作成と使用は、3 つのステップから成るプロセスです。
特定の種類のアルゴリズムを選択し、そのパラメーターまたはハイパーパラメーターを定義してモデルを構成します。 次のいずれかの種類のモデルを選択します。
- 分類モデル: ニューラル ネットワーク、デシジョン ツリー、デシジョン フォレストなどのアルゴリズムに基づくモデルです。
- 回帰モデル: 標準線形回帰のほか、ニューラル ネットワークやベイジアン回帰といったアルゴリズムを使用できます。
ラベル付けされていて、かつアルゴリズムに適合したデータを含んだデータセットを指定します。 データとモデルの両方をモデルのトレーニングに接続してください。
トレーニングからは、データから学習した統計的パターンをカプセル化した特定のバイナリ形式 (iLearner) が生成されます。 この形式を直接変更したり読み取ったりすることはできません。ただし、このトレーニング済みのモデルは、他のコンポーネントから使用することができます。
モデルのプロパティを確認することもできます。 詳細については、「結果」セクションを参照してください。
トレーニングが完了したら、いずれかのスコアリング コンポーネントでトレーニング済みのモデルを使用し、新しいデータの予測を行います。
[モデルのトレーニング] の使用方法
モデルのトレーニング コンポーネントをパイプラインに追加します。 [Machine Learning] カテゴリの下でこのコンポーネントを見つけることができます。 [トレーニング] を展開し、モデルのトレーニング コンポーネントをパイプラインにドラッグします。
左側の入力に、トレーニングされていないモードをアタッチします。 モデルのトレーニングの右側の入力にトレーニング データセットをアタッチします。
トレーニング データセットには、ラベル列が含まれている必要があります。 ラベルのない行は無視されます。
[ラベル列] について、コンポーネントの右パネルの [列の編集] をクリックし、モデルがトレーニングに使用できる結果を含む 1 つの列を選択します。
分類問題の場合、ラベル列にはカテゴリ値または離散値が含まれている必要があります。 たとえば、Yes/No 評価や疾患分類コード (または名前)、所得層が該当します。 非カテゴリ列を選んだ場合、トレーニング中にコンポーネントからエラーが返されます。
回帰問題の場合、ラベル列には、応答変数を表す数値データが含まれている必要があります。 連続スケールを表す数値データが理想です。
たとえば、信用リスク スコアや、ハード ドライブの推定故障時間、特定の日時におけるコール センターの推定着信数が該当します。 数値列を選択しなかった場合、エラーが返されます。
- 使用するラベル列を指定しなかった場合、Azure Machine Learning は、データセットのメタデータを使用して適切なラベル列の推測を試みます。 間違った列が選択された場合は、列セレクターを使用して修正してください。
ヒント
列セレクターの使い方のヒントについては、「Select Columns in Dataset (データセットの列を選択する)」の記事を参照してください。 [WITH RULES](規則を使用) オプションと [名前別] オプションの使い方についてのヒントといくつかの一般的なシナリオが取り上げられています。
パイプラインを送信します。 データの量が多いと、しばらく時間がかかる場合があります。
重要
各行の ID となる ID 列がある場合、あるいは、テキスト列に含まれる一意の値が多すぎる場合、モデルのトレーニングが原因で、"列: "{column_name}" 内の一意の値の数が許可されている数を超えています" などのエラーが発生することがあります。
これは、列が一意の値のしきい値に達し、メモリが不足する場合があるためです。 メタデータの編集を使用してその列を [Clear feature](特徴のクリア) としてマークできます。テキスト列を事前処理する目的でトレーニングやテキストからの N-gram 特徴抽出コンポーネントで使用されることがありません。 エラーの詳細については、デザイナーのエラー コードに関する記事を参照してください。
モデルの解釈可能性
モデルの解釈可能性により、ML モデルを理解し、人間が理解できる方法で意思決定の基礎を提示する可能性が提供されます。
現在、モデルのトレーニング コンポーネントでは、ML モデルを説明するための解釈可能性パッケージの使用がサポートされています。 次の組み込みアルゴリズムがサポートされています。
- 線形回帰
- ニューラル ネットワーク回帰
- 増幅デシジョン ツリーの回帰
- デシジョン フォレスト回帰
- ポワソン回帰
- 2 クラスのロジスティック回帰
- 2 クラス サポート ベクター マシン
- 2 クラスの増幅デシジョン ツリー
- 2 クラス デシジョン フォレスト
- 多クラス デシジョン フォレスト
- 多クラス ロジスティック回帰
- 多クラス ニューラル ネットワーク
モデルの説明を生成するには、モデルのトレーニング コンポーネントでモデルの [モデルの説明] のドロップダウン リストから [True] を選択します。 モデルのトレーニング コンポーネントでは、これは既定で False に設定されています。 説明を生成するには、追加のコンピューティング コストが必要であることにご注意ください。

パイプラインの実行が完了したら、モデルのトレーニング コンポーネントの右側のウィンドウにある [説明] タブにアクセスし、モデルのパフォーマンス、データセット、および特徴量の重要度を調べることができます。
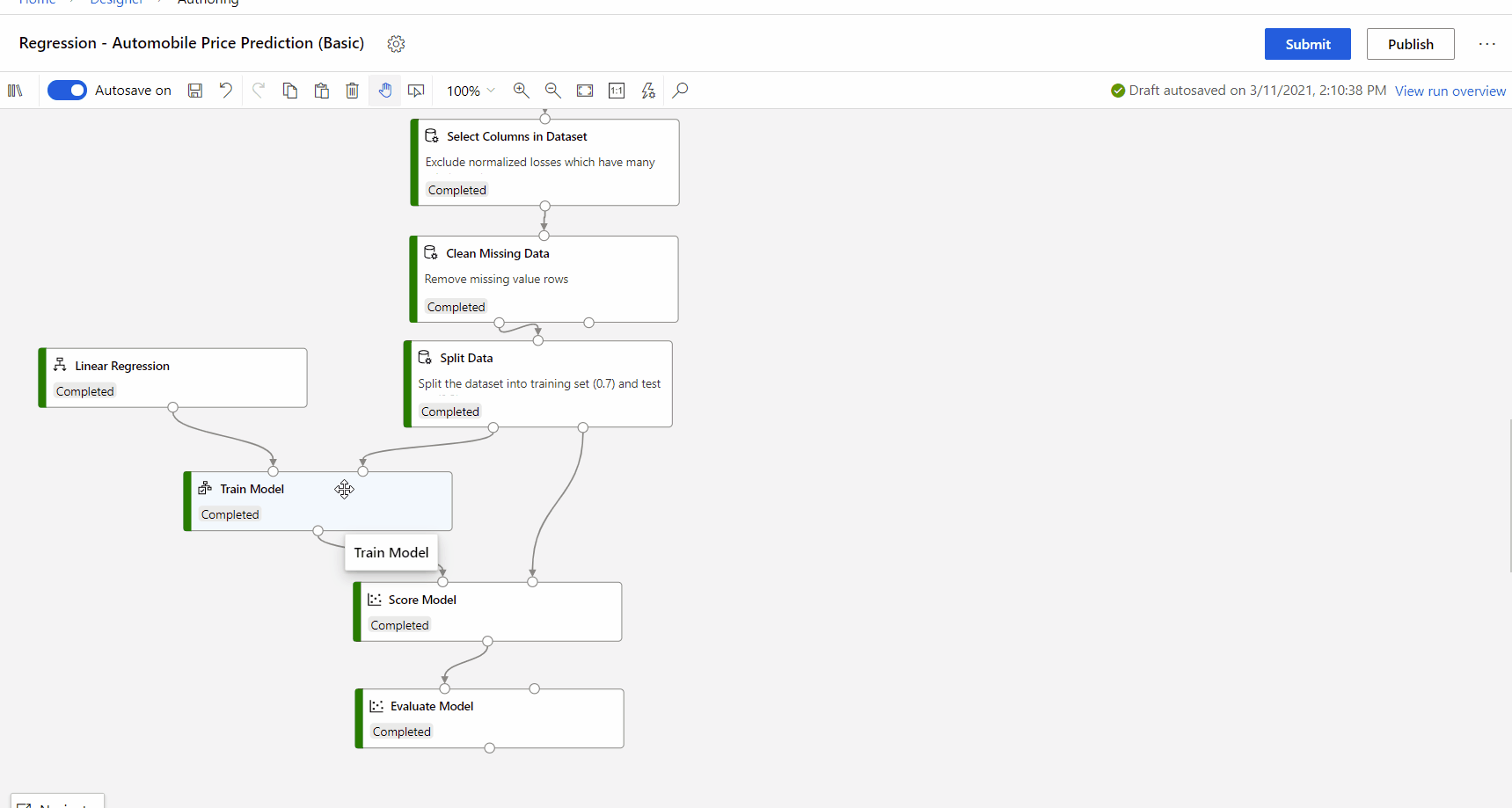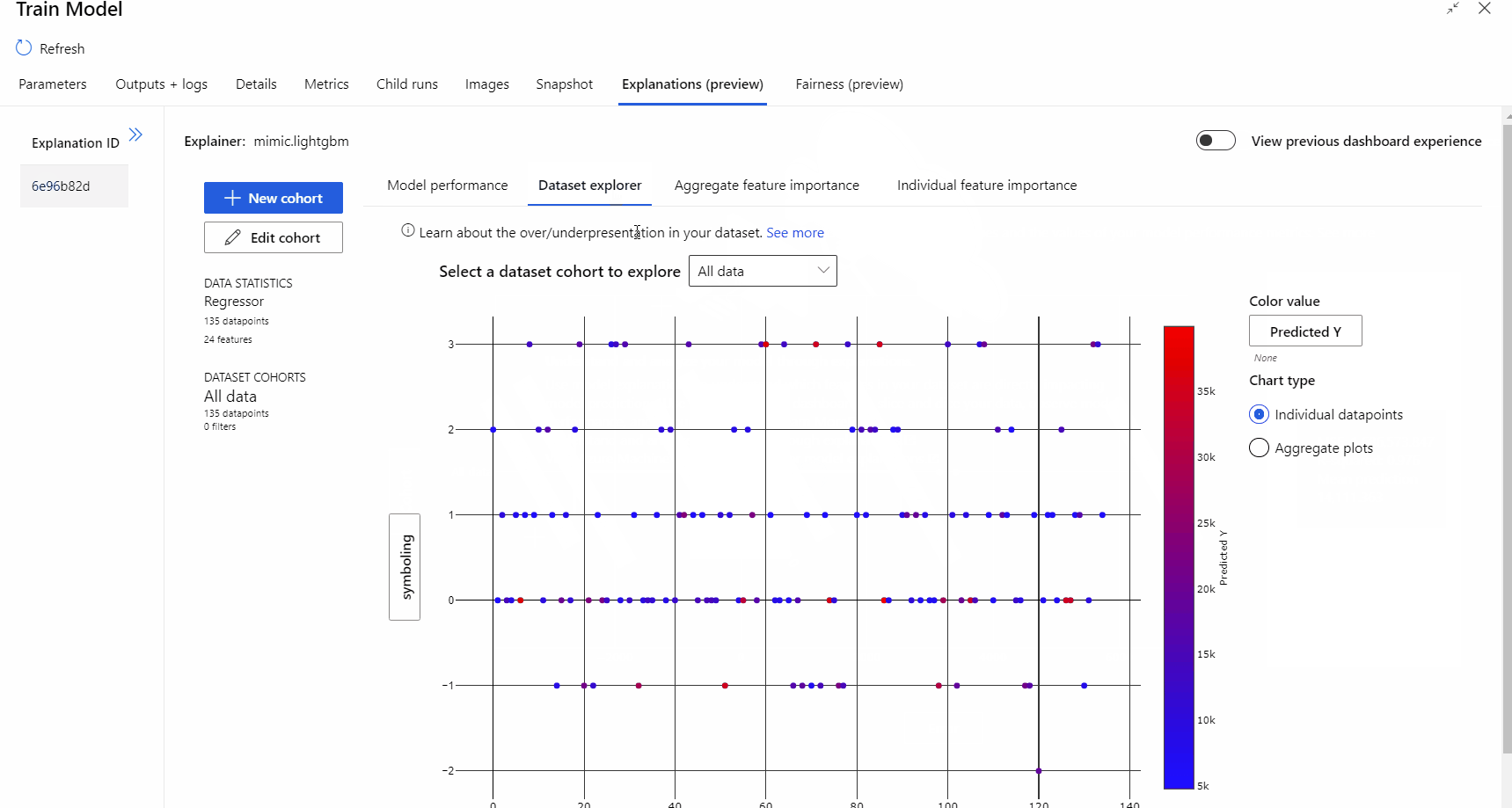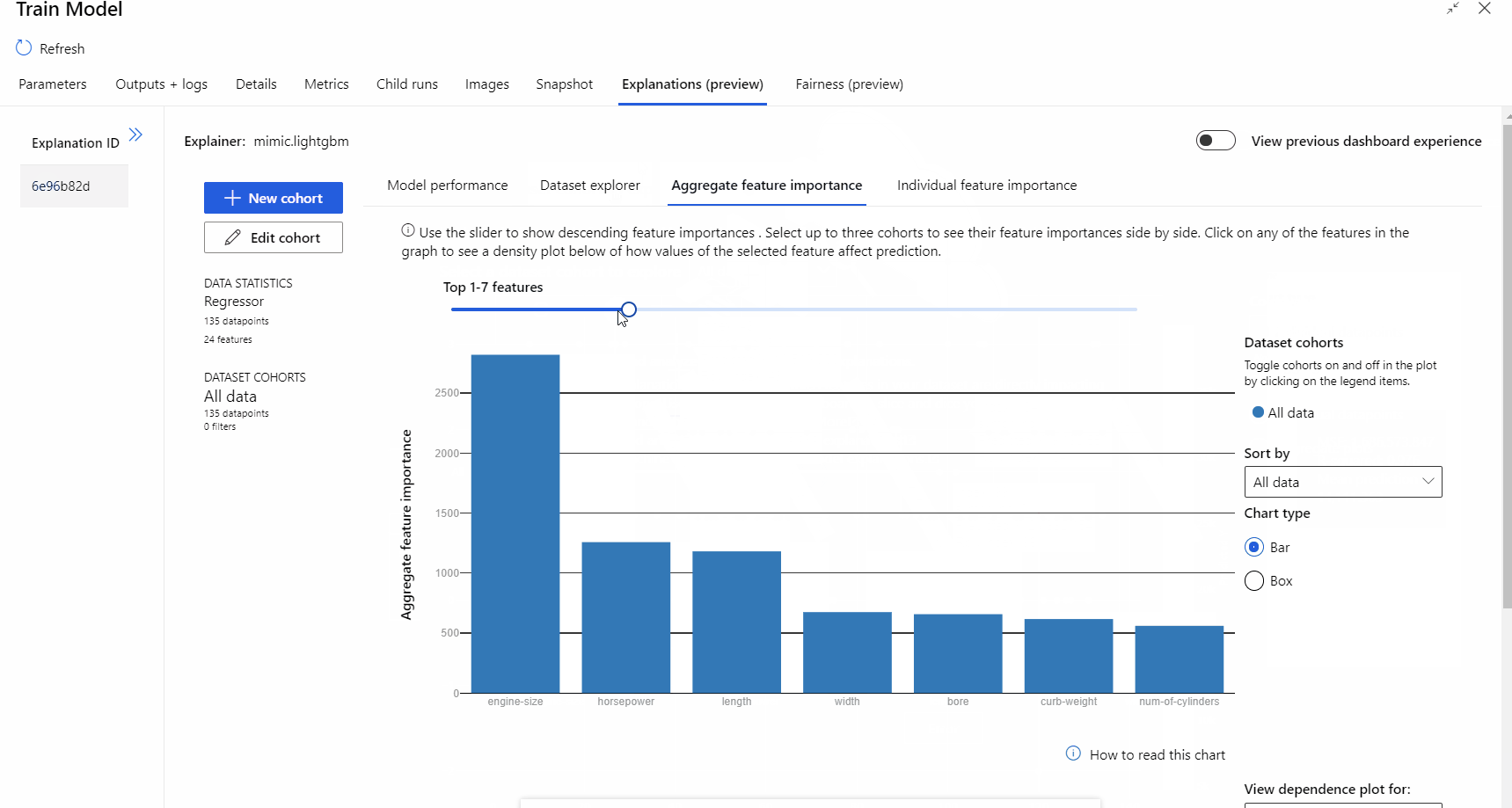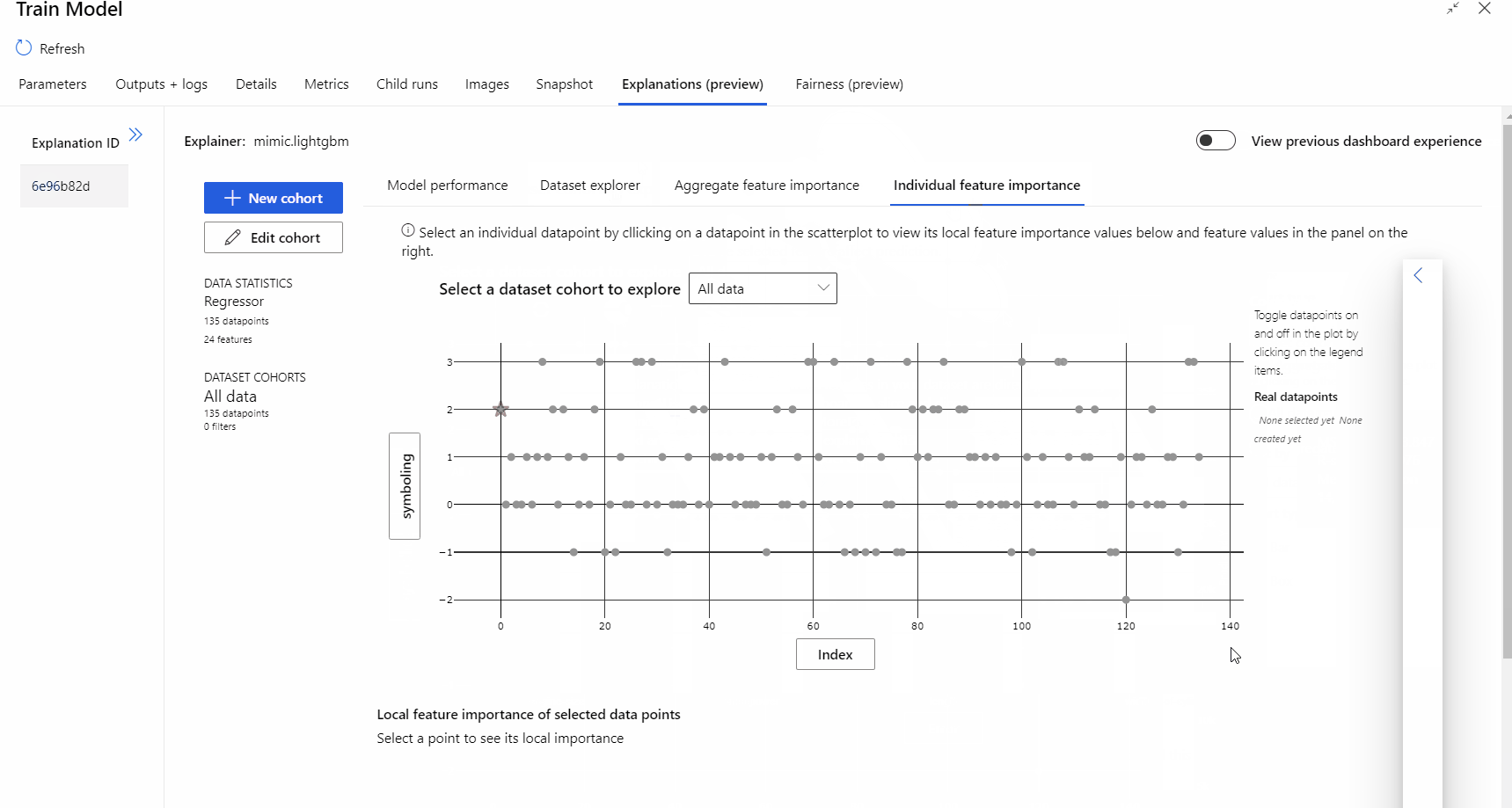
Azure Machine Learning におけるモデルの説明を使用する方法の詳細については、ML モデルの解釈に関するハウツー記事を参照してください。
結果
モデルのトレーニング後、次の作業を行います。
他のパイプラインでモデルを使用するには、コンポーネントを選択し、右側のパネルの [出力] タブの下にある [データセットの登録] アイコンをクリックします。 保存したモデルは、コンポーネント パレットの [データセット] からアクセスできます。
新しい値の予測にモデルを使用するには、それを新しい入力データと共にモデルのスコア付けコンポーネントに接続します。
次の手順
Azure Machine Learning で使用できる一連のコンポーネントを参照してください。