大規模な予測: 多くのモデルと分散型トレーニング
この記事では、大量の履歴データに対する予測モデルのトレーニングについて説明します。 AutoML で予測モデルをトレーニングする手順と例については、時系列予測用に AutoML を設定するの記事を参照してください。
時系列データは、データ内の系列の数、履歴観測値の数、またはその両方が原因で大きくなる可能性があります。 多数モデルと階層型時系列 (HTS) は、データが多数の時系列で構成される、かつてのシナリオ向けのスケーリング ソリューションです。 このような場合、データをグループに分割し、グループ上で多数の独立したモデルを並行してトレーニングすると、モデルの正確性とスケーラビリティに役立つことがあります。 反対に、1 つまたは少数の大容量モデルのほうが適しているシナリオもあります。 分散型 DNN トレーニングは、このケースをターゲットにします。 この記事では、これらのシナリオに関する概念を確認します。
多数モデル
AutoML の多数モデル コンポーネントを使用すると、数百万モデルを並行してトレーニングおよび管理できます。 たとえば、多数の店舗の販売履歴データがあるとします。 次の図のように、多数モデルを使用して、店舗ごとの AutoML トレーニング ジョブを並行して起動できます。

多数モデル トレーニング コンポーネントは、AutoML のモデル スイープと選択をこの例の各店舗に個別に適用します。 このモデルの独立性は、スケーラビリティに役立ち、販売動態が店舗ごとに異なる場合は特に、モデルの正確性にメリットをもたらすことがあります。 ただし、販売動態が共通している場合は、1 つのモデル アプローチのほうが正確な予測を得られる場合があります。 そのようなケースの詳細については、「分散型 DNN トレーニング」セクションを参照してください。
データ パーティション分割、モデルの AutoML 設定、および多数モデルトレーニング ジョブの並列処理の程度を構成できます。 例については、多数モデル コンポーネントに関するガイド セクションを参照してください。
階層型時系列予測
ビジネス アプリケーションの時系列には、階層を形成する入れ子になった属性が含まれることが一般的です。 たとえば、地理的および製品カタログの属性は入れ子になっていることがよくあります。 階層に 2 つの地理的属性 (州と店舗 ID)、および 2 つの製品属性 (カテゴリと SKU) がある例を考えてみましょう。

この階層を示したのが次の図です。

重要なのは、リーフ (SKU) レベルでの販売数量が、州レベルと販売合計レベルの集計販売数量に加算される点です。 階層型予測メソッドは、階層の任意のレベルで販売数量を予測するときに、これらの集計プロパティを保持します。 このプロパティを使用した予測は、階層に関して一貫性があります。
AutoML では、階層型時系列 (HTS) に対して次の機能がサポートされています。
- 階層の任意のレベルでのトレーニング。 場合によっては、リーフ レベルのデータはノイズが多い場合がありますが、集計は予測により適している場合があります。
- 階層の任意のレベルでのポイント予測の取得。 予測レベルがトレーニング レベルを "下回っている" 場合、トレーニング レベルからの予測は過去比率の平均または過去値平均の比率によって分解されます。 予測レベルがトレーニング レベルを "上回る" 場合、トレーニング レベルの予測は集計構造に従って合計されます。
- トレーニング レベルまたはトレーニング レベルを "下回る" 分位点/確率予測の取得。 現在のモデリング機能では、確率予測の分解がサポートされています。
AutoML の HTS コンポーネントは多数モデル上に構築されているため、HTS は多数モデルのスケーラブルなプロパティを共有します。 例については、HTS コンポーネントに関するガイド セクションを参照してください。
分散型 DNN トレーニング (プレビュー)
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンはサービス レベル アグリーメントなしで提供されており、運用環境のワークロードに使用することは推奨されません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
大量の履歴観察値や多数の関連時系列を特徴とするデータ シナリオには、スケーラブルな単一モデル アプローチが役立つ可能性があります。 したがって、AutoML では、時系列データのディープ ニューラル ネットワーク (DNN) の一種である時間畳み込みネットワーク (TCN) モデルで分散型トレーニングとモデル検索がサポートされます。 AutoML の TCN モデル クラスの詳細については、DNN に関する記事を参照してください。
分散型 DNN トレーニングでは、時系列の境界を考慮したデータ パーティション分割アルゴリズムを使用してスケーラビリティを実現します。 次の図は、2 つのパーティションを持つ簡単な例を示しています。
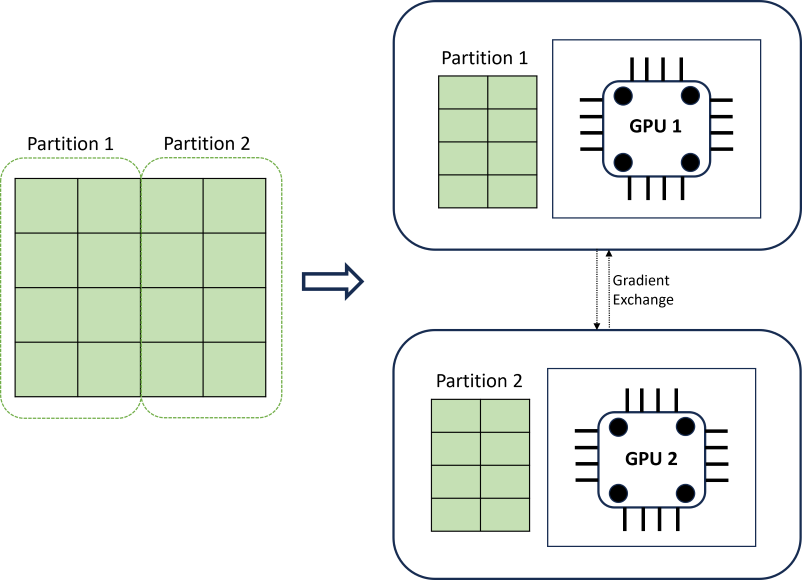
トレーニング中、各コンピューティングでの DNN データ ローダーは、誤差逆伝播法の繰り返しを完了するために必要なもののみを読み込みます。データセット全体がメモリに読み込まれることはありません。 パーティションは、トレーニングを高速化するために、複数のノード上の複数のコンピューティング コア (通常は GPU) にわたってさらに分散されます。 コンピューティング間の調整は、Horovod フレームワークによって提供されます。
次のステップ
- 時系列予測モデルをトレーニングするように AutoML を設定する方法の詳細について確認します。
- AutoML が機械学習を使用して予測モデルを構築する方法について確認します。
- AutoML での予測のためのディープ ラーニング モデルについて学習する
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示